2024-8-31 01:0:31 Author: hackernoon.com(查看原文) 阅读量:1 收藏
Authors:
(1) Suzanna Sia, Johns Hopkins University;
(2) David Mueller;
(3) Kevin Duh.
Table of Links
- Abstract and 1. Background
- 2. Data and Settings
- 3. Where does In-context MT happen?
- 4. Characterising Redundancy in Layers
- 5. Inference Efficiency
- 6. Further Analysis
- 7. Conclusion, Acknowledgments, and References
- A. Appendix
3. Where does In-context MT happen?
3.1. Layer-from Context Masking
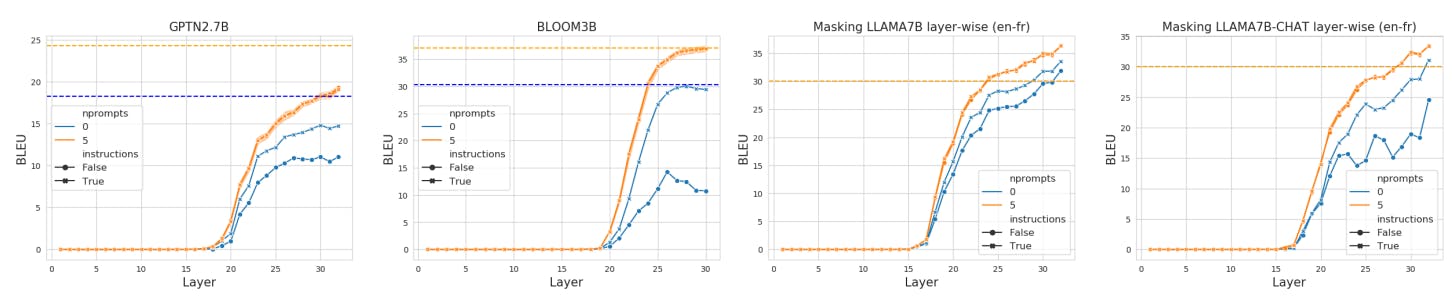
In-context learning differs from task-specific supervised learning in that, during test time, the desired task must be identified from the context first, then executed. At what stage in the feed-forward computation does a GPT-style model transition from an in-context learner to a translation model? To explore this question, we introduce layer-from context-masking which masks out all attention weights to the context (instructions or prompts) from a certain layer onwards (see Figure 1 for a graphical description).

Under this causal masking treatment masking from layer ℓ, the model must rely on the representations of the target input sentence from layer ℓ + 1 only to complete the task; if the target sentence representations do not already encode the target task (translation into a specific language) then the model will fail to generate translations.

3.2. Results
We discuss the central findings of the paper: Models do not need to maintain attention over all of the context across every layer to perform the task.

Different models reach this plateau point at different layers. In GPTNEO this point occurs around layer 25, in BLOOM this point occurs around layer 15-20, and in LLAMA models this occurs around layer 13-15. As English is the dominant language, as expected models can successfully perform translation into English upon earlier layers of masking, than translation out of English.

At this point, the models benefits only marginally, if at all, from attending to the context, suggesting most of the task "location" has already occurred.
There exists critical layers for task location. Prior to the task recognition point, around the middle layers of the models, moving the context mask up a layer results in a significant increase to performance. We consider these critical layers, as instead of a gradual increase in performance, we observe we can observe very steep jumps of over 20 bleu points across the different models. We conjecture that the model is locating the correct task during processing in these middle layers, after which the context is no longer necessary to perform the translation task.
Overall, our findings suggest a 3-phase process to in-context learning: in the first phase, moving the mask up makes little difference in performance, which is close to 0. This suggests that the context has not influenced task location at all. In the second phase, shifting the mask upwards makes a large difference in MT performance, suggesting that the model has started to locate the task but can improve significantly with more processing of the context. Finally, in the third phase, shifting the mask upwards again has little-to-no effect on MT performance, suggesting that the model has fully recognized the task as translation and no longer requires the context to interpret the task.
We provide further observations and ablations in the following sections.
3.3. Instruction-tuned vs Non-instruction Tuned Models

Overall we find that the observation of task recognition layers and a task recognition point is present across both non-instruction tuned and instruction tuned models, and that this presents itself similarly in both types of models.
3.4. The Role of Instructions vs Examples


3.5. Attention to the Context vs Attention to the Input
One possible explanation for the results in Figure 2 is that, rather than identifying the point at which the task is recognized, we have identified the point at which the model no longer requires attending to any other input tokens. To explore this, we run experiments in the en → fr direction where we mask attention to all inputs from a certain layer onwards. This does not include masking over the text the model has generated.
We plot the results in Figure 3; we find that for all models, the layer at which attention can be fully removed is much higher than the layer at which we can remove attention to the context. For GPTNEO and LLAMA, translation performance is never comparable to the baseline with no masking. Conversely, when masking only the context, translation performance improves as early as layer 10 and plateaus at the no-mask baseline much earlier. This supports the interpretation that the curves we observe in Figure 2 are due to the model still requiring attention to the source sentence input.
[2] Readers should note that there is a Wk and Wq weight matrix for each layer and each attention head, but we omit the notation on this for readability.
如有侵权请联系:admin#unsafe.sh