2024-7-30 18:19:42 Author: securityboulevard.com(查看原文) 阅读量:3 收藏
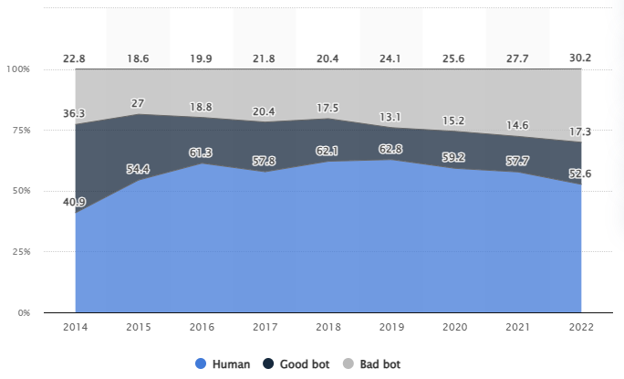
Bots make up roughly half of all web traffic worldwide. Statista estimated that bot traffic accounted for 47.5% of all traffic in 2022. But not all bots are made equal. While the majority of bots are programmed with bad intentions, a significant number of good bots exist that are essential for the internet and indeed for your business.

Most of these good bots are web crawlers. It’s important that you understand which good web crawlers exist, so you understand what they do and so you can adjust your sitemap and robots.txt files appropriately.
In this article, we will explain what web crawlers are, what they do, and how they work. We will provide you with a list of the most common crawlers. At the end of the article, we will also explain how you can protect your website from the crawlers you don’t want.
What is a web crawler?
A web crawler is an automated program designed to systematically browse the internet. These digital explorers follow links from one website to another, collecting information about each page they visit. This data is then used for various purposes, most notably by search engines to index content and provide relevant results to user queries.
What are crawlers used for?
Web crawlers serve multiple purposes:
- Search Engine Indexing: The primary use of web crawlers is to help search engines like Google, Bing, and Yahoo create and update their search indexes.
- Data Mining: Researchers and businesses use crawlers to gather specific types of data from websites for analysis or market research.
- Web Archiving: Organizations like the Internet Archive use crawlers to preserve snapshots of websites over time.
- Website Maintenance: Webmasters use crawlers to check for broken links, monitor site performance, and ensure content is up-to-date.
- Content Aggregation: News aggregators and price comparison sites use crawlers to collect and compile information from multiple sources. This is an example of a crawler you may not want on your website.
How does a web crawler work?
A web crawler typically follows a series of steps that look like this:
- Starting Point: The crawler begins with a list of URLs to visit, often called the “seed” list.
- Fetching: It downloads the web pages associated with these URLs.
- Parsing: The crawler analyzes the downloaded page’s content, looking for links to other pages.
- Link Extraction: It identifies and extracts new URLs from the parsed content.
- Adding to the Queue: New URLs are added to the list of pages to visit.
- Rinse and Repeat: The process continues with the crawler following new links and revisiting known pages to check for updates.
- Indexing: The collected data is processed and added to the search engine’s index or other relevant database.
The Most Common Web Crawlers
Let’s now dig into the web crawler lists, starting with some of the most frequently encountered web crawlers. Understanding these can help you optimize your site for better visibility and manage your server resources more effectively.
List here all the ones here below and hashtag link to each one like this example
Googlebot
- User agent: Googlebot
- Full user agent string for Googlebot Desktop: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Googlebot/2.1; +http://www.google.com/bot.html) Chrome/W.X.Y.Z Safari/537.36
Where would any of us be without Google? As you can imagine, Google crawls a lot and, as a result, they have a few crawlers. There’s Googlebot-Image, Googlebot-News, Storebot-Google, Google-InspectionTool, GoogleOther, GoogleOther-Video, and Google-Extended. But Googlebot is the primary web crawler for the Google search engine. It constantly scans the web to discover new and updated content, helping Google maintain its search index.
Bingbot
- User agent: Bingbot
- Full user agent string for Bingbot Desktop: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) Chrome/W.X.Y.Z Safari/537.36
Do not underestimate Microsoft Bing. As of 2024, Bing has a global market share of 10.5%. Given the billions of people who use the internet, 10.5% is still a really large number of users. Bingbot is Microsoft’s web crawler for the Bing search engine. It performs similar functions to Googlebot, indexing web pages to improve Bing’s search results.
YandexBot
- User agent: YandexBot
- Full user agent string for YandexBot 3.0: Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots)
Yandex Bot is the crawler for Yandex, a popular search engine primarily in Russia, Kazakhstan, Belarus, Turkey, and countries with many Russian speakers. YandexBot helps Yandex index web content and provide relevant search results.
Applebot
- User agent: Applebot
- Full user agent string for Applebot: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/600.2.5
Applebot is Apple’s web crawler, used for Siri and Spotlight suggestions. It helps improve Apple’s search capabilities within its ecosystem of devices and services.
LinkedIn Bot
- User agent: LinkedInBot
- Full user agent string for LinkedInBot: LinkedInBot/1.0 (compatible; Mozilla/5.0; Jakarta Commons-HttpClient/4.3 +http://www.linkedin.com)
Just like the other social media bots further down the list, LinkedIn’s bot crawls shared links to create previews on the professional networking platform. It helps LinkedIn display informative snippets when users share content.
Twitterbot
- User agent: Twitterbot
- Full user agent string for Twitterbot: Twitterbot/1.0 Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) QtWebEngine/5.12.3 Chrome/69.0.3497.128 Safari/537.36
Same as the LinkedIn bot, Twitter’s (now X) bot crawls links shared on the platform to generate previews. It helps X display rich media cards when users share links in tweets.
Pinterestbot
- User agent: Pinterestbot
- Full user agent string for the Pinterest bot: Mozilla/5.0 (compatible; Pinterestbot/1.0; +https://www.pinterest.com/bot.html)
Pinterest’s bot crawls the web to gather information about images and content shared on Pinterest. It helps create rich pins and improve the user experience when pinning content from external websites.
Facebook External Hit
- User agent: Facebook External Hit, Facebook Crawler
- Full user agent string for Facebook External Hit: facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php)
If an app or website is shared on Facebook, the Facebook crawler indexes wherever the links lead. Because of this bot, Facebook can gather metadata to generate link previews when users share content on Facebook.
GPTBot
- User agent: GPTBot
- User agent string for GPTBot: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.0; +https://openai.com/gptbot)
GPTBot is OpenAI’s (somewhat controversial) crawler for gathering data to train and improve their AI models, including the GPT series. It navigates the web to collect information and ensure the models are well-informed and up-to-date.
DuckDuckBot
- User agent: DuckDuckBot
- Full user agent string for DuckDuckBot: DuckDuckBot/1.1; (+http://duckduckgo.com/duckduckbot.html)
DuckDuckBot is the crawler for DuckDuckGo, a privacy-focused search engine. It helps index web pages while also sticking to DuckDuckGo’s privacy-centric principles. Savvy web users who are concerned about their privacy and data may use DuckDuckGo over any other search engine.
Baiduspider
- User agent: Baiduspider
- Full user agent string for Baiduspider 2.0: Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)
Baiduspider is the main web crawler for Baidu, China’s largest search engine. It indexes web content primarily in Chinese but it also crawls international websites. If you market in China, it’s a good idea to allow Baiduspider to crawl your website.
Sogou Spider
- User agent: sogou spider
- Full user agent string for Sogou Spider Desktop: Sogou web spider/4.0 (+http://www.sogou.com/docs/help/webmasters.htm#07)
Sogou Spider is the web crawler for Sogou, a Chinese search engine and a product of the Chinese Internet company Sohu. The Sogou Spider indexes web content to improve Sogou’s search results, focusing primarily on Chinese language websites.
Slurp
- User agent: Slurp
- Full user agent string for Slurp: Mozilla/5.0 (compatible; Yahoo! Slurp; http://help.yahoo.com/help/us/ysearch/slurp)
This isn’t a joke. The name for Yahoo’s web crawler is indeed called Slurp. Although Yahoo is only a shadow of what it once was, Slurp still crawls websites to gather information for Yahoo’s search engine and related services.
CCBot
- User agent: CCbot
- Full user agent string for CCBot: Mozilla/5.0 (compatible; CCbot/2.0; +http://commoncrawl.org/faq/)
CCbot is the web crawler of Common Crawl, a non-profit organization that crawls the web to build and maintain an open repository of web data. This data is freely accessible and used by researchers, companies, and developers to advance technology, understand the web, and build new applications.
Yeti
- User agent: Yeti
- Full user agent string for Yeti: Mozilla/5.0 (compatible; Yeti/1.1; +https://naver.me/spd)
Yeti is the crawler used by Naver, South Korea’s leading search engine. Do not underestimate Naver, as it has 42 million enrolled users and is considered the Google of South Korea. Naver uses Yeti to index web pages and update its search engine results.
Top SEO Crawlers
Apart from the web crawlers listed above, there are also plenty of SEO web crawlers that could potentially visit your website. These automated bots systematically browse the internet, gathering data that helps SEO professionals identify technical issues, optimize site structure, and improve search engine visibility.
List here all the ones here below and hashtag link to each one like this example
AhrefsBot
- User agent: AhrefsBot
- Full user agent string for AhrefsBot: Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/)
AhrefsBot is the crawler used by the marketing suite Ahrefs for SEO analysis and backlink checking. It helps Ahrefs users analyze their websites’ SEO performance and track their backlink profiles.
SemrushBot
- User agent: SemrushBot
- Full user agent string for SemrushBot: Mozilla/5.0 (compatible; SemrushBot/7~bl; +http://www.semrush.com/bot.html)
The Semrush bot is the crawler used by Semrush for competitive analysis and keyword research. It gathers data on website rankings, traffic, and keywords to provide insights for SEMrush users.
Rogerbot
- User agent: Rogerbot
- Full user agent string for Rogerbot: Mozilla/5.0 (compatible; Moz.com; rogerbot/1.0; +http://moz.com/help/pro/what-is-rogerbot-)
Rogerbot is the web crawler used by marketing suite Moz. It gathers data on website performance, backlink profiles, and keyword rankings. By collecting and analyzing this information, Rogerbot helps SEO professionals optimize their websites, improve search engine rankings, and improve the online visibility of their websites.
Screaming Frog SEO Spider
- User agent: Screaming Frog SEO Spider
- User agent string: Mozilla/5.0 (compatible; Screaming Frog SEO Spider/20.2; +https://www.screamingfrog.co.uk/seo-spider/)
Screaming Frog SEO Spider is, you guessed it, Screaming Frog’s spider. Screaming Frog is a robust SEO tool designed for analyzing website structure and content. It helps webmasters identify critical issues such as broken links, duplicate content, and other SEO-related problems.
Lumar
- User agent: Lumar, DeepCrawl
- User agent string: Mozilla/5.0 (Linux; Android 7.0; SM-G892A Build/NRD90M; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/60.0.3112.107 Mobile Safari/537.36 https://deepcrawl.com/bot
Lumar, previously known as DeepCrawl, is an SEO tool that focuses on website health and performance analysis. It provides detailed insights into site structure and technical SEO issues. Its crawler helps identify and rectify site performance and search engine problems.
MJ12bot
- User agent: MJ12Bot
- Full user agent string for MJ12Bot: Mozilla/5.0 (compatible; MJ12bot/v1.2.4; http://www.majestic12.co.uk/bot.php?+)
MJ12bot is a web crawler used by the Majestic SEO link intelligence tool. It helps gather data on backlinks and other SEO-related metrics to provide insights for digital marketers and SEO professionals.
CognitiveSEO
- User agent: CognitiveSEO Site Explorer
- Full user agent string for CognitiveSEO: Mozilla/5.0 (compatible; CognitiveSEO Site Explorer; +https://cognitiveseo.com/bot.html)
CognitiveSEO Site Explorer is a sophisticated web crawler designed to provide deep insights into a website’s SEO performance. It analyzes backlink profiles, site architecture, and on-page SEO factors to help identify strengths and weaknesses.
OnCrawl
- User agent: OnCrawl
- User agent string: Mozilla/5.0 (compatible; OnCrawl/2.0; +https://www.oncrawl.com)
OnCrawl is a technical SEO crawler and data analysis tool. It provides detailed reports on various aspects of a website, including its architecture, content, and performance.
Google-InspectionTool
- User agent: Google-InspectionTool
- Full user agent string for Google-InspectionTool: Mozilla/5.0 (compatible; Google-InspectionTool/1.0;)
One of Google’s many crawlers, Google-InspectionTool is used to analyze and inspect web pages for issues related to indexing and SEO. It provides insights into how Google views a site, helping webmasters identify and resolve issues that might affect their site’s visibility in search results. This tool is essential for ensuring that web pages are properly indexed and optimized for search engines.
BLEXBot
- User agent: BLEXBot
- Full user agent string for BLEXBot: Mozilla/5.0 (compatible; BLEXBot/1.0; +http://webmeup-crawler.com/)
BLEXBot is associated with the WebMeUp project and is used for various SEO-related tasks, including backlink analysis and website indexing for SEO PowerSuite. It’s becoming increasingly common in web server logs and is recognized by many webmasters and SEO professionals.
MegaIndex.ru
- User agent: MegaIndex.ru
- Full user agent string for MegaIndex.ru: Mozilla/5.0 (compatible; MegaIndex.ru/2.0; +http://megaindex.com/crawler)
MegaIndex.ru Bot is used by the Russian SEO and analytics platform MegaIndex to crawl websites for data collection and analysis to provide insights and competitive intelligence.
Sitebulb Crawler
- User agent: Sitebulb Crawler
- Full user agent string for Sitebulb Crawler: Mozilla/5.0 (compatible; Sitebulb/3.3; +https://sitebulb.com)
Sitebulb is a desktop application that performs in-depth SEO audits. It provides detailed insights into site performance, structure, and health, helping users identify and fix technical SEO issues. Its crawler enables you to enhance your website’s visibility by making sure that all technical elements are optimized for search engines.
Botify
- User agent: Botify
- Full user agent string for Botify: Mozilla/5.0 (compatible; Botify/2.0; +http://www.botify.com/bot.html)
Botify is a comprehensive site crawler designed for SEO optimization. It helps analyze website performance and identify areas for improvement by providing actionable insights. Its crawler helps ensure that your website is fully optimized for search engines.
JetOctopus
- User agent: JetOctopus
- Full user agent string for JetOctopus: Mozilla/5.0 (compatible; JetOctopus/1.0; +http://www.jetoctopus.com)
JetOctopus is a high-speed cloud-based SEO crawler. It provides detailed analyses of website structures, helping identify and fix technical SEO issues quickly.
Netpeak Spider
- User agent: Netpeak Spider
- Full user agent string for Netpeak Spider: Mozilla/5.0 (compatible; NetpeakSpider/1.0; +https://netpeak.net)
Netpeak Spider is a desktop tool for comprehensive site audits. It helps identify SEO issues such as broken links, duplicate content, and page load speeds. Its crawler helps improve site health and SEO performance.
ContentKing
- User agent: ContentKing
- Full user agent string for ContentKing: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36 (+https://whatis.contentkingapp.com)
ContentKing is a real-time SEO auditing and monitoring crawler. It continuously scans websites to detect and report issues immediately.
Top Crawler Tools
Web crawlers are important tools for more than just SEO and social media. The following bots systematically browse the internet to monitor website uptime, to get data into spreadsheets, to learn what technologies a website uses, and more.
List here all the ones here below and hashtag link to each one like this example
Exabot
- User agent: Exabot
- Full user agent string for Exabot: Mozilla/5.0 (compatible; Exabot/3.0; +http://www.exabot.com/go/robot)
Exabot is a web crawler operated by Exalead, a French search engine company. It systematically indexes web pages to support Exalead’s search engine services, gathering data on site content and structure. Exabot helps improve search engine capabilities by providing updated and comprehensive web data for better search results.
Swiftbot
- User agent: Swiftbot
- Full user agent string for Swiftbot: Mozilla/5.0 (compatible; Swiftbot/1.0; +http://swiftbot.com)
Swiftbot is a versatile web crawler designed to collect data for various applications, including market research, competitive analysis, and content aggregation. It efficiently scans and indexes web pages, enabling businesses to access up-to-date information and insights. Swiftbot supports the software by providing reliable and comprehensive data.
UptimeRobot
- User agent: UptimeRobot
- Full user agent string for UptimeRobot: Mozilla/5.0+(compatible; UptimeRobot/2.0; http://www.uptimerobot.com/)
UptimeRobot is a monitoring service that uses its bot to check websites’ uptime and performance, ensuring they are available and responsive for users.
Import.io
- User agent: Import.io
- Full user agent string for Import.io: Mozilla/5.0 (compatible; Import.io/2.0; +https://www.import.io)
Import.io provides a platform for extracting data from websites. It allows users to turn any website into a table of data or an API with no coding required, making it easy to gather structured web data for various purposes.
Webhose.io
- User agent: Webhose.io
- Full user agent string for Webhose.io: Mozilla/5.0 (compatible; Webhose.io/1.0; +https://webhose.io)
Webhose.io is a data-as-a-service provider that offers access to structured web data through its API. It collects data from millions of websites, forums, blogs, and online news sources, providing valuable insights for businesses and researchers.
Dexi.io
- User agent: Dexi.io
- Full user agent string for Dexi.io: Mozilla/5.0 (compatible; Dexi.io/1.0; +https://www.dexi.io)
Dexi.io is a web scraping tool that allows users to extract data from websites and transform it into structured datasets. It offers automation features and integrates with various data sources, enabling efficient data extraction and analysis.
Zyte (formerly Scrapinghub)
- User agent: Zyte
- Full user agent string for Zyte: Mozilla/5.0 (compatible; Zyte/1.0; +https://www.zyte.com)
Zyte provides web scraping and data extraction services through its platform, Scrapy Cloud. It offers tools for managing and deploying web crawlers at scale, helping businesses collect and analyze web data for competitive intelligence and market research.
Outwit Hub
- User agent: Outwit Hub
- Full user agent string for Outwit Hub: Mozilla/5.0 (compatible; Outwit Hub; +https://www.outwit.com)
Outwit Hub is a web scraping tool that allows users to extract data from websites using a visual interface. It supports automation and extraction of various data types, making it suitable for both beginners and advanced users in data mining tasks.
Getleft
- User agent: Getleft
- Full user agent string for Getleft: Getleft/1.2 (+http://getleft.sourceforge.net)
Getleft is a website downloader that recursively downloads websites for offline browsing. It allows users to specify which files to download and includes options for customizing the depth of the download.
HTTrack
- User agent: HTTrack
- Full user agent string for HTTrack: HTTrack Website Copier/3.x.x archive (https://www.httrack.com)
HTTrack is a free and open-source website copier and offline browser utility. It allows users to download websites and browse them offline, preserving the original site structure and links.
Cyotek WebCopy
- User agent: Cyotek WebCopy
- Full user agent string for Cyotek WebCopy: Mozilla/5.0 (compatible; Cyotek WebCopy/1.0; +https://www.cyotek.com)
Cyotek WebCopy is a website crawler and offline browser that downloads entire websites for offline browsing. It supports advanced features like URL rewriting and custom rules for site download and mirroring.
Helium Scraper
- User agent: Helium Scraper
- Full user agent string for Helium Scraper: Mozilla/5.0 (compatible; Helium Scraper; +https://www.heliumscraper.com)
Helium Scraper is a web scraping software that allows users to extract data from websites using a visual interface. It supports advanced scraping techniques and automation features for extracting structured data from web pages.
Sequentum
- User agent: Sequentum
- Full user agent string for Sequentum: Mozilla/5.0 (compatible; Sequentum/1.0; +https://www.sequentum.com)
Sequentum provides a platform for web data extraction and robotic process automation (RPA). It offers tools for building and deploying web crawlers to extract structured data from websites for business intelligence and automation purposes.
WebHarvy
- User agent: WebHarvy
- Full user agent string for WebHarvy: Mozilla/5.0 (compatible; WebHarvy; +https://www.webharvy.com)
WebHarvy is a visual web scraping software that allows users to extract data from websites using a point-and-click interface. It supports scraping of text, images, and other content from web pages, making it suitable for non-programmers.
Visual Scraper
- User agent: Visual Scraper
- Full user agent string for Visual Scraper: Mozilla/5.0 (compatible; Visual Scraper; +https://www.visualscraper.com)
Visual Scraper is a web scraping tool that allows users to extract data from websites through a visual interface. It supports automation and customization of data extraction tasks, making it accessible for users without programming skills.
ParseHub
- User agent: ParseHub
- Full user agent string for ParseHub: Mozilla/5.0 (compatible; ParseHub; +https://www.parsehub.com)
ParseHub is a web scraping tool that allows users to extract data from websites using a visual interface or by writing custom scripts. It offers features for scraping dynamic content and APIs for integrating scraped data into other applications.
80legs
- User agent: 80legs
- Full user agent string for 80legs: 80legs/2.0 (+http://www.80legs.com/spider.html)
80legs is a web crawling service that provides scalable and customizable web data extraction solutions. It allows users to create and deploy web crawlers to gather large amounts of data from the web for various applications, including market research and competitive analysis.
Octoparse
- User agent: Octoparse
- Full user agent string for Octoparse: Mozilla/5.0 (compatible; Octoparse/7.0; +https://www.octoparse.com)
Octoparse is a web scraping tool that allows users to extract data from websites using a visual workflow designer. It supports automation and scheduling of scraping tasks, making it suitable for both beginners and advanced users in data extraction.
How to Protect Your Website from Malicious Crawlers
The above are some of the crawlers you may encounter, but there are many more. And those are crawlers that don’t have malicious intent. There are exponentially more crawlers that have bad intentions when they crawl your website, that do not respect your robots.txt file. It’s in the best interests of your business to block bots like those, because they can overload your servers, illegally scrape your content, or attempt to find vulnerabilities to exploit.
You can safeguard your website with the following security measures:
- Rate limiting and access controls: Implement limits on how frequently bots can access your site and restrict access to sensitive areas.
- Monitoring and logging: Regularly monitor bot activity and log requests to detect any unusual patterns or suspicious behavior.
- Regular updates and patches: Keep your web server and applications up to date with the latest security patches to protect against known vulnerabilities exploited by malicious crawlers.
But the most effective way for how to stop bot traffic is with robust bot detection and management software. DataDome is that software. It uses behavioral analysis to identify all kinds of crawlers, letting through legitimate bots like search engine crawlers while blocking malicious bots in real-time.
DataDome has customizable rules and policies, so you can block even good crawlers that you may not want on your website (for example, the crawlers of marketing tools you don’t use). It also integrates seamlessly within your existing tech architecture and has detailed dashboards to help you understand instantaneously what threats you are being protected from.
DataDome has a 30-day free trial that gives you a good idea of its capabilities. Alternatively, you can book a live demo to see how it works.
*** This is a Security Bloggers Network syndicated blog from DataDome authored by DataDome. Read the original post at: https://datadome.co/bot-management-protection/crawlers-list/
如有侵权请联系:admin#unsafe.sh