
2024-7-25 03:7:15 Author: securityboulevard.com(查看原文) 阅读量:7 收藏
This blog series was written jointly with Amine Besson, Principal Cyber Engineer, Behemoth CyberDefence and one more anonymous collaborator.
In this blog (#9 in the series), we will cover a few higher level elements for moving to detection engineering approaches
- Detection Engineering is Painful — and It Shouldn’t Be (Part 1)
- Detection Engineering and SOC Scalability Challenges (Part 2)
- Build for Detection Engineering, and Alerting Will Improve (Part 3)
- Focus Threat Intel Capabilities at Detection Engineering (Part 4)
- Frameworks for DE-Friendly CTI (Part 5)
- Cooking Intelligent Detections from Threat Intelligence (Part 6)
- Blueprint for Threat Intel to Detection Flow (Part 7)
- Testing in Detection Engineering (Part 8)
Throughout our blog series, we explored the domain of Detection Engineering from technical and tactical perspectives. Today, we’ll explore select strategic components that leadership would need to acquire to build and steer a good SOC into an intricate land of detection engineering. This should lead to the world where precise, intention- and intel-driven detections are key to timely and effective SOC operations — without analyst burnout!
Define a Detection Lifecycle Management
In many cases, a SOC didn’t even consider their detection library from the angle of content management. Lack of such thinking may lead to decrease in detection coverage over time, and related decay in efficiency — provided they even started with good coverage.
To start, naïve ATT&CK coverage reporting practices may sometimes be counterproductive — or at least lead in a less than useful direction — as it may give the impression of a healthy SOC (“we use EDR that claims 100% ATT&CK coverage!”), hiding more complex dimensions like log source coverage, detection upkeep, asset management updates, periodic threat coverage review, detection decay and so on. Furthermore, the process of creating a detection can be very messy, with undefined processes, full of frustration and untracked work, while claiming “we got 100%” presents a binary, simplistic view.
The purpose of a Detection Lifecycle is to establish a standardized process that responds consistently to new inputs received by the SOC. These inputs are primarily normalized threat signals derived from intelligence sources. By implementing a Detection Lifecycle, organizations can ensure a systematic approach to detecting and responding to potential security threats, enhancing their overall security posture.
Define Detection Lifecycle States
Detections being developed flow through various stages, while at some organizations, a few steps are implied, ad hoc or missing. Once the confidence in detection effectiveness is high enough, we consider the rule to be Production. This means it will trigger some form of SOC response if an alert is raised from this detection trigger — and human beings may be woken up at 3AM as a result.
Intermediate stages from Development to Production help further refine the detection flow, allowing for more effective alert-raising workflows throughout the flow of the DE process. This may cover things like raising alerts to a common development triage queue during testing before switching to a production queue, better reporting over the state of the detection coverage, and consistent tracking (for both reporting and tuning).

Backlogging, Detection As-Code and DevOps-ish Ideas
Defining a lifecycle that fits your organization is often tied to available tooling and project management practices. Detection Engineers have (re)discovered that a lot of work achieved in the Software Engineering communities is reusable, once we switch into the DevOps mindset.
This included developing rules, testing them, and rolling them out to detection platforms. Adopting version control, issue tracking, sprint/iterations and backlog management will have compounding benefits over time, allowing the DE team to mature processes in a well documented field of expertise. This is especially true since infrastructure-as-code is now a common practice with many concepts and tooling available for usage or inspiration. CI/CD concepts bring process automation and QA validation to security operations, ensuring a well managed and tracked detection library. As we said in some presentation, security needs to both live with modern IT (adapt to its realities) and learn from modern IT (steal and adopt its ideas).
Building your detection engineering lifecycle on top of DevOps concept abstracts underlying technologies and process complexity into a more manageable platform, with possibility for growth and a lot of customization opportunities. At least, in theory! Your organization practice may well deviate, hence YMMV.
Get Vendor and Community Detections under Control
This is admittedly a simpler task, so good news! You may or may not cook, but you definitely eat. Detection tooling often comes with vendor written (or community created) detections, which sometimes have a breezy side-effect of giving a false sense of coverage, short-circuiting the detection engineering process (“what… we now have 200% ATT&CK coverage?”).
While they can provide a useful starting off point, they also may create a vast volume of false alarms, drowning IR processes and ultimately preventing further maturity improvements. The DE team should aim at quickly getting them under control in favor of refined external detections and internally developed detections where necessary.
We can look at 3 types of vendor content:
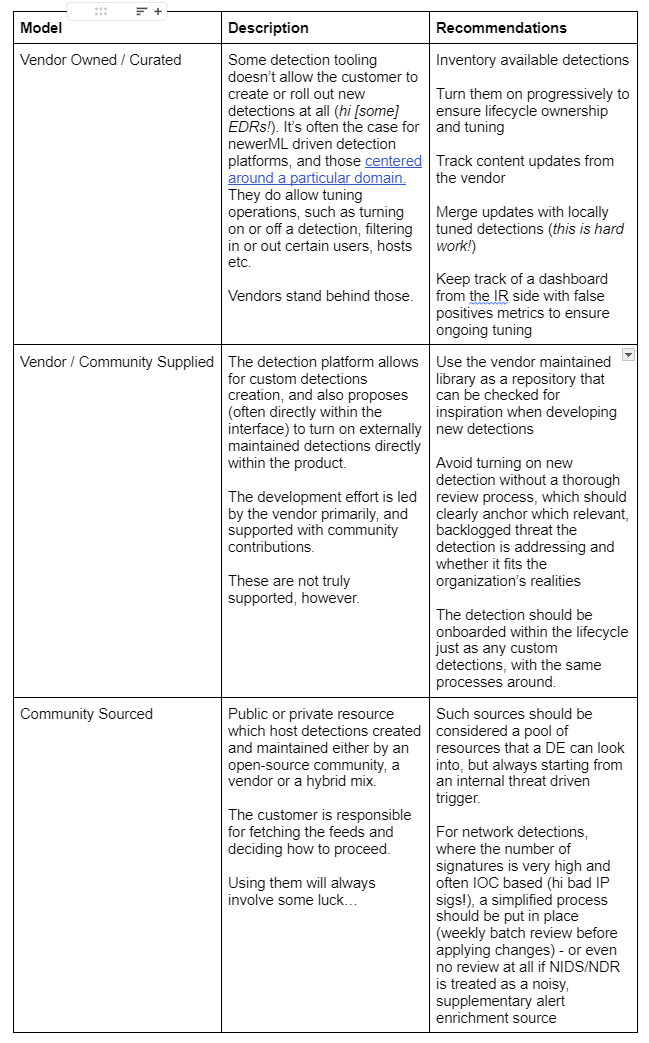
MSSPs/MDRs as Detection Content Sources
Shocking surprise! There are some MSSPs and MDRs that are … well … mediocre. And with mediocre MSSPs and MDRs, a lot of detection-related things are shots in the dark. For example, you’d send emails with detection requirements, only for them to get forgotten, implemented without notice, enabled in prod with high false positives in the middle of the night, deployed on the wrong sensors, etc. Or, your “sort of OK” MSSP may not do enough to proactively improve detection coverage at all. And, frankly, sometimes reactively too.
With good MSSP, tracking detection coverage may be sufficient, but in the case the operating model requires you to be more involved in coverage review or increase processes, structuring a hybrid setup, with project management on your end may prove to be the missing piece in getting the most out of your contract. Depending on the engagement model, you may have access to the detections deployed on your MSSP/MDR-connected detection systems (view access and/or edit access, as discussed here). Who owns the content is another question to ponder — not discussed here in detail.
Previous blog posts of this series:
- Detection Engineering is Painful — and It Shouldn’t Be (Part 1)
- Detection Engineering and SOC Scalability Challenges (Part 2)
- Build for Detection Engineering, and Alerting Will Improve (Part 3)
- Focus Threat Intel Capabilities at Detection Engineering (Part 4)
- Frameworks for DE-Friendly CTI (Part 5)
- Cooking Intelligent Detections from Threat Intelligence (Part 6)
- Blueprint for Threat Intel to Detection Flow (Part 7)
- Testing in Detection Engineering (Part 8)
Guide your SOC Leaders to More Engineering Wisdom for Detection(Part 9) was originally published in Anton on Security on Medium, where people are continuing the conversation by highlighting and responding to this story.
*** This is a Security Bloggers Network syndicated blog from Stories by Anton Chuvakin on Medium authored by Anton Chuvakin. Read the original post at: https://medium.com/anton-on-security/guide-your-soc-leaders-to-more-engineering-wisdom-for-detection-part-9-a46319bd362c?source=rss-11065c9e943e------2
如有侵权请联系:admin#unsafe.sh