浩鲸科技 2003 年创建,为运营商提供高质量信息服务,在全球有多个研发中心。浩鲸科技正在进行业务全球化的布局,目前海外市场占比已接近 50%。国外运营商的用户规模小,用户业务量不高,运营商主机数量少。由于业务特点,其对独立小型部署需求较多。ByConity 给浩鲸科技提供了对应产品能力,帮助其解决了产品痛点,更好地满足了客户需求。本文将介绍浩鲸科技在电信运营商场景下使用 ByConity 进行实时数据分析的实践经验。
作者|叶禧辉,浩鲸科技大数据底座团队负责人
01 运营商的实时数据分析挑战
浩鲸科技以往一直深度使用大数据 Hadoop 技术,它基于离线方式发展而来,尽管现在也有实时组件 Flink 的支持,但在运营商场景中仍会遇到一些瓶颈。查询与分析场景复杂多变的情况,在运营实施过程中存在因大数据量、业务复杂度高,导致较多的处理性能问题。
实时分析能力难:较难支持对实时数据的分析,因为它无法对实时数据进行增量聚合计算。不能够支持实时数据的增量聚合计算,不支持实时数据的分析。
查询分析性能慢:数据分析在相同硬件条件下,相对于新型 MPP 数据库要有 5-10 倍的性能劣势,其中当数据分布倾斜时,会导致整体性能的大幅下降;数据分布由表分区方式决定,通常在表创建时指定。
写入瓶颈:当多个节点同时进行写入操作时,节点的性能可能会成为瓶颈,无法支持高并发写入。
集群规模受限:由于集群规模受物理 Master 限制,在实际应用中可能很难超过一定数量的物理节点。限制了其扩展性和可伸缩性。传统的 MPP 的数据库很困难扩缩容,例如 ClickHouse 和 GP,如果扩展主机,则会导致数据的重新分布,造成生产环境业务中断。这种客户难以接受的情况。
并发能力有限:受物理 Master 限制,并发性能相对较低。在实际应用中,可能无法支持超过一定数量的并发请求。
数据加载性能较低:对于大量小型数据表,数据加载性能相对较低,加载速的度较慢。
> 为什么需要使用 ByConity
为了解决 Hadoop 生态应对实时性场景能力不足的难题,一开始我们引用了 ClickHouse,其有着强劲的单表汇聚能力,也解决了 Flink 实时组件难以解决多表关联的问题。通过两者结合,我们会把一些关联运算引入 ClickHouse 处理。然而实际使用中依然遇到很多挑战。如 使用复杂,需多种表引擎;多表关联困难,需要定义好分布键;分布式表的方案很复杂,高频数据写入会存在数据分布和重复性问题。
虽然场景性能可用,但面对如此多的痛点,很难大规模推广使用,因为它确实对业务开发的要求很高。去年 ByConity 开源后我们发现它基本上解决了使用 ClickHouse 的痛点。ByConity 的方案包括以下特点:
统一的表引擎(统一的 cnchMergetree),业务切换简单,开发人员不用再纠结我们该用哪种 Mergetree
多表关联性能有了质的提升,不再需要定义分布式键,可以简单进行多表关联汇总
扩展简单,存算分离的模式,扩展不会涉及到数据的重新分布,可以很容易进行主机的扩缩容
具体业务中,从下图中可以看到,通过从 OLTP 数据库、事件流、文件存储、日志文件等汇集来的数据,进到 ByConity 完成数据计算之后,可以很容易地进行各种清单分析、即席分析跟实时分析。
> 运营商实时分析场景简介
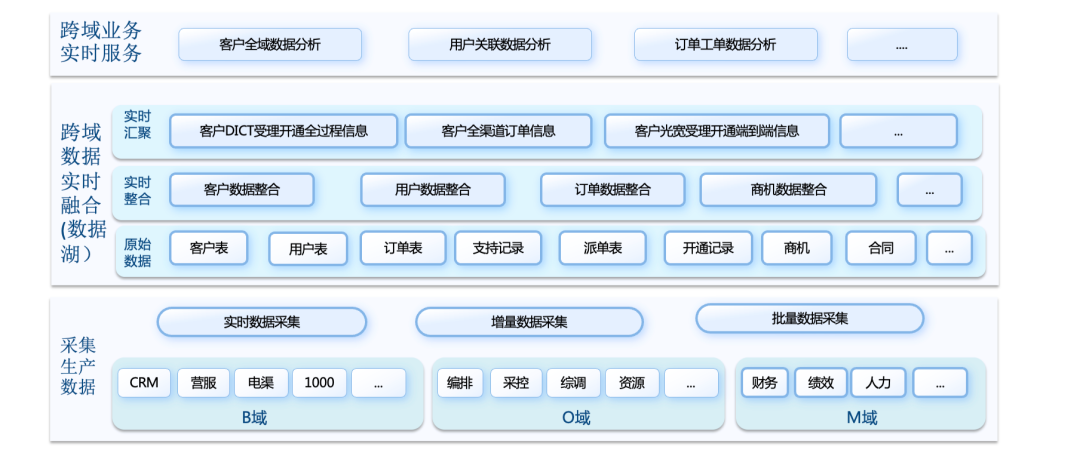
传统的 CRM 客户关系管理系统,客服订单受理中心,电渠等,属于 B 域;手机号码开通和记录流程、采控、资源等属于 O 域;涉及到绩效、人力等方面则属于 M 域。
首先采集这三个域的数据进行原始数据加工。原始数据包含数以千计的表。我们需要从每一个域中做实时整合,如客户数据整合、用户数据整合、订单数据整合等;整合后每一个域还要各自进行实时汇聚,将每个域中的数据打成各种大宽表及各种复杂的指标表。
之后将进行三个域的统一,即跨域数据实时融合服务,包括客户全域数据分析、用户关联数据分析、订单工单数据分析等。
从下图中可以看出,运营商场景中实时是一个非常复杂的情况,它涉及到多张表不停变化的实时信息的聚合。
> 融合 Hadoop 和 ByConity 的即席查询方案
为了解决此问题,我们技术上做了批流一体的方案,即融合 Hadoop 底座的 MPP 数据库方案。分成实时计算层与批量计算层两部分。实时计算层中 Kafka 接收实时信息流,如话单数据、订单数据,不停的实时订单数据汇总;针对一些复杂的情况,比如说之前提到的多个域的多种表、多维度关联,则会在 Hadoop 体系进行,通常使用小时级别进行资料汇总。
之后这两部分数据将汇总到 ByConity,定时进行实时数据与批量数据的整合,通常每 5 分钟整合一次,最终通过大屏显示。由于最复杂的计算在数据工厂中已经完成,利用 ByConity 多表关联能力可以很快得出结果。
02 ByConity 的深度引入和封装
ByConity 开源之后,我们进行了快速的测试,发现其很满足业务场景,基于 ByConity 进行了深入引用和封装,并形成了可直接对外提供服务的 Walehouse。按照业务场景跟客户需求,所做工作包括:
基于物理机的部署方案:解决很多客户习惯使用非容器化和 K8s 部署运维问题。在 ToB 场景,很多客户习惯于使用非容器化的 K8s 去做部署运维,希望只利用数据库能力,而不用引入 K8s 的运维;
支持任意数量的主机部署:不限定主机数量的安装配置,允许最低一台主机的安装部署,降低使用门槛;
可视化组件管理:包括数据库的所有管理和工作实例,依赖的 HDFS 存储系统,foundationdb 的安装管理都支持可视化安装运维;
弹性伸缩运维启停:得益于 ByConity 弹性伸缩能力,允许动态添加工作节点,具备在线弹性伸缩的能力和工作实例的启停;
在线升级:能够很方便通过界面进行版本的更新,避免了大量繁琐的手工升级步骤。
03 后续规划
快速数据迁移:快速实现从 Oracle/Greenplum 等数据库的库表迁移功能很多客户有一些存量系统需要进行系统升级,比如之前在 Oracle 或者 GP 系统进行了数据开发,我们可以提供可视化的组件帮助用户快速完成整库的搬迁。
离线备份与恢复:后续将 ByConity 离线备份恢复能力集成到我们的产品,实现界面化的数据备份与恢复能力
数据湖分析:我们广泛使用 Hudi 数据库的能力,并且还有大量的 Hive 表,利用外部物化视图,有效进行多数据源的整合分析
物化视图的分析应用:利用物化视图的能力,实时进行数据的整合
时序分析性能:利用 ByConity 快速写入、超高的 TPS 能力跟聚合能力,有效提升时序数据写入与数据统计分析的性能
- END -
添加小助手加入 ByConity 社区交流群
如有侵权请联系:admin#unsafe.sh