2024-7-18 16:30:54 Author: securityboulevard.com(查看原文) 阅读量:2 收藏
Generative AI (GenAI) relies on training Large Language Models (LLMs) with huge volumes of data. To do this, scrapers ongoingly sift through the Internet, automating the extraction of information that train LLMs. They scour the web across different domains – news sites, forums, and a lot more – to provide coherent responses when prompted.
GenAI Intercepting Web Traffic
For decades, businesses have mostly embraced crawlers and web scrapers from search engines. Who wouldn’t want their content to rise to the top of search engine results? But the dynamics have shifted with the introduction of LLMs. Instead of helping direct users from search engine results to websites, output from GenAI prompts often intercepts web traffic.
For example, according to a recent WSJ study, publishers have determined they’ll lose 20% to 40% of Google-generated traffic due to AI. Additionally, there are potential legal implications as LLMs often intake content and then disseminate it in their responses without proper payment, attribution, or licensing agreements to those who created it.
The publishing industry has been the first to openly speak out about the impact and legality of unauthorized scraping to train GenAI. Recently, Time Magazine teamed-up with OpenAI with a multiyear content licensing deal. Similarly, Reddit is trying to stop AI providers from scraping its forums without paying-up first after striking deals with OpenAI and Google.
It’s highly unlikely AI data scraping permissions will get settled any time soon, if ever. New licensing deals will arise. Others will collapse. A long list of new and established GenAI providers will be thirsty for training their models with the latest and greatest data. Some will pay, many will not.
AI Data Scraping Attempts on Kasada’s Customers
We’ve been analyzing AI data scraping bots and detecting billions of their requests since LLMs first arrived on the scene. Most recently, we are observing even more aggressive scraping by Bytespider. Bytespider is a web crawler operated by ByteDance, the Chinese owner of TikTok. It’s allegedly used to download training data for its LLMs. Across our entire customer base, we’ve seen a 20x increase in Bytespider requests compared to a few months ago (which we’re able to block successfully). The reason for the increase is unknown, although one could speculate they are being more aggressive before AI scraping legislation inevitably escalates.
In addition to Bytespider, we see daily activity from OpenAI and Anthropic as the next two largest AI data scrapers respectively. To put the volume of Bytespider activity in perspective, we observe more than 25 Bytespider requests per OpenAI request – and over 3,000 Bytespider requests per Anthropic request.
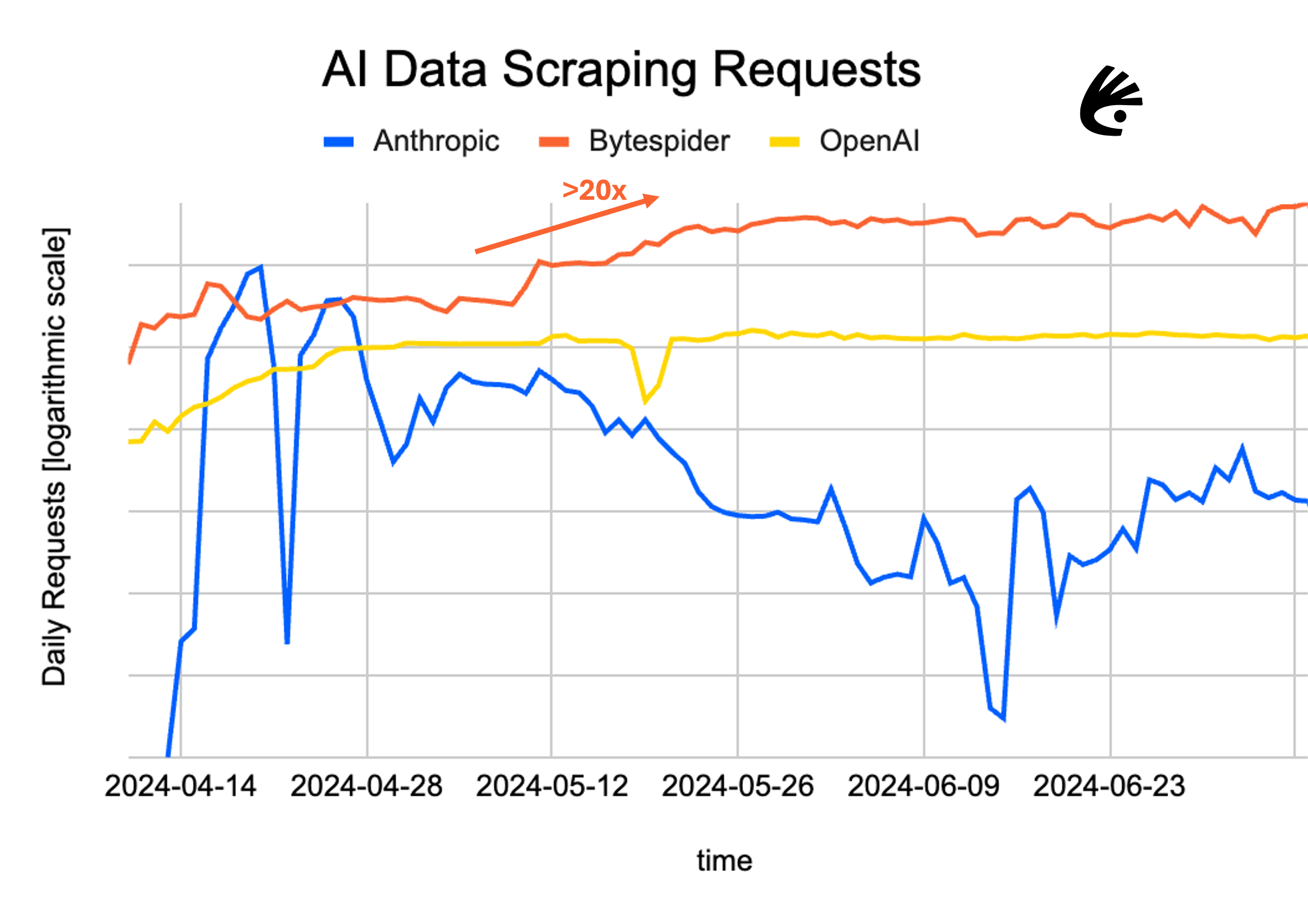
AI data scraping requests against Kasada customers over the past 90-days. Around mid-May, Kasada observed more than a 20x sustained increase in Bytespider requests. The data is charted on a logarithmic scale as the scraping observed from Bytespider is now much larger than both OpenAI and Anthropic combined.
Stopping Unauthorized AI Data Scraping
Whether AI data scraping should be blocked or not is a personal choice for each business. For those wishing to stop unauthorized scraping, there are a variety of measures and challenges in doing so.
Update robots.txt – No Trespassing Sign
If you want to prevent people from trespassing in your yard, hanging a “no trespassing” sign is a first step. The online equivalent to this is disallowing a bot within a website’s robots.txt file. Reading it specifies whether you are or aren’t allowed to scrape. Just like the sign, people can still trespass if they choose to do so. The legal implications of being caught vary based on websites’ terms of use policies.
It’s easy to add AI scrapers such as Anthropic, Bytespider, Google-Extended, and GPTBot to your site’s robots.txt and any other deny lists to disallow them access to your website. But it’s not very effective in practice as the sign is often ignored. Plus, GenAI companies can always purchase the data outright from a third party.

GPTBot is an example of a LLM crawler that’s used to help improve future OpenAI models by scraping website content to possibly aid in model training.
Bot Defense – Beware of Dog
How can you better enforce no trespassing in your yard? If robots.txt is your sign, an anti-bot solution should be your menacing guard dog ready to pounce on trespassers. They detect the bots and prevent them from scraping your website and APIs.
AI scrapers (and web scrapers overall), however, are especially difficult to stop. Even more so than other automated threats. They can be highly evasive. Why is this?
- Harvested device fingerprints fool most classification decisions – many anti-bot solutions use techniques such as client-side device fingerprinting to detect AI scrapers. However, bot operators use a technique called “harvesting” where they obtain stolen digital fingerprints (copies of real user sessions and browser data) which can be loaded into bot frameworks to almost exactly imitate a real user who is using a browser. This fools the data collection and classification process of many bot mitigation providers.
- Most machine learning (ML) based detection takes too long – scraping is unlike other automated threats as you must classify a request as bot or human without any chance to observe and analyze the session interactions. Behavioral analysis, including ML, is often inadequate for detecting scrapers as a result.
- Specialized 3rd party APIs and services are readily available – for those with less technical savvy, or simply want someone else to do the work for them, there are cost efficient scraper APIs such as those sold by BrightData that evade many anti-bot detections. Or GenAI companies can simply buy the data outright from turnkey services and claim “it wasn’t us”.
Scraping API and turnkey services offered by BrightData and many others are used to collect massive volumes of data for many use cases including LLM training. They evolve regularly to circumvent the anti-bot detections protecting desired websites and APIs .
Bottom line – stopping motivated web scrapers fScraping Arom GenAI companies and the growing ecosystem of third party services can be especially difficult. Be sure your guard dog isn’t all bark, and no bite.
Kasada – Well Trained K-9 in Your Yard
We continue to learn about web scrapers and their ecosystem by analyzing trillions of bot interactions, infiltrating botting communities, and reverse engineering their methods. We are actively stopping billions of unauthorized AI data scraping requests for our customers ever since LLMs arrived on the scene.
There’s a lot involved, but Kasada’s approach to stopping scrapers is grounded in
- Collecting client-side telemetry to detect the tell-tale signs that all bots must exhibit – their use of automation, from the very first request.
- Ensuring the authenticity of all data we collect with a “proof of execution” system to thwart harvesting attempts. This system forces the bots into our own controlled environment, where they have to answer our challenges on our terms.
Our customers don’t need to create any customized policies to stop AI based web scraping. Scraping protection, AI and otherwise, is built into the core product. Customers can choose which AI data scrapers they do wish to allow, and those that should be blocked.

We work hard to make sure Kasada’s defenses remain ahead of persistent web scrapers. Deploying Kasada bot defense is akin to having a well trained, loyal K-9 in your own yard. Don’t let trespassers violate your property – if you think you might have unauthorized data scraping that needs to be addressed, contact us.
The post No Trespassing: Challenges In Stopping Unauthorized AI Data Scraping appeared first on Kasada.
*** This is a Security Bloggers Network syndicated blog from Kasada authored by Neil Cohen. Read the original post at: https://www.kasada.io/stopping-unauthorized-ai-data-scraping/
如有侵权请联系:admin#unsafe.sh