2024-7-13 04:30:15 Author: hackernoon.com(查看原文) 阅读量:6 收藏
I built a pipeline of Dagger modules sending my wife and me SMSs twice a week with personalized budgeting advice generated by AI to help us build healthier spending habits.
If you just want to watch a video presentation of this, here’s the link
Let's Start With the Context Behind This...
My wife and I have been trying to make a more concerted effort to build better spending habits. Even with a plethora of budgeting apps, we often fall into two traps. We either don't look at our finances frequently enough or we build elaborate systems to plan our finances that quickly become bloated and impractical.
Much like the goal of becoming fit, you can break down most goals into habits. Instead of installing more apps we will not use, or creating more spreadsheets, we need to build the habit of getting personalized financial advice with actionable advice that would help start more conversations about our spending. The channel most likely to catch both of our attention is SMS.
Let's Break Down This Pipeline Into Multiple Steps...

Get Bank Transactions
-
I need to regularly and securely retrieve data from multiple bank accounts.
Between my wife and I, we have multiple bank accounts. I needed a system that would retrieve transactions from each account regularly. I am prioritizing cost-effectiveness; I ideally don't want to spend anything. I want something that is easy to set up and transparent. I want to easily share this data with my wife, who is non-technical. I opted to use
Tiller .They offer a free trial and the price is relatively low. Most importantly, the data is populated to a Google Sheet which I could more easily share with my wife.
-
I need to fetch data from the spreadsheet twice a week. To complete this task, I built and published a Dagger module;
FetchSpreadsheetData. This module fetches bank transaction data from a spreadsheet populated by Tiller, requiring a sheetID and a Google Sheets API Key to authenticate data retrieval.Optimizing container...
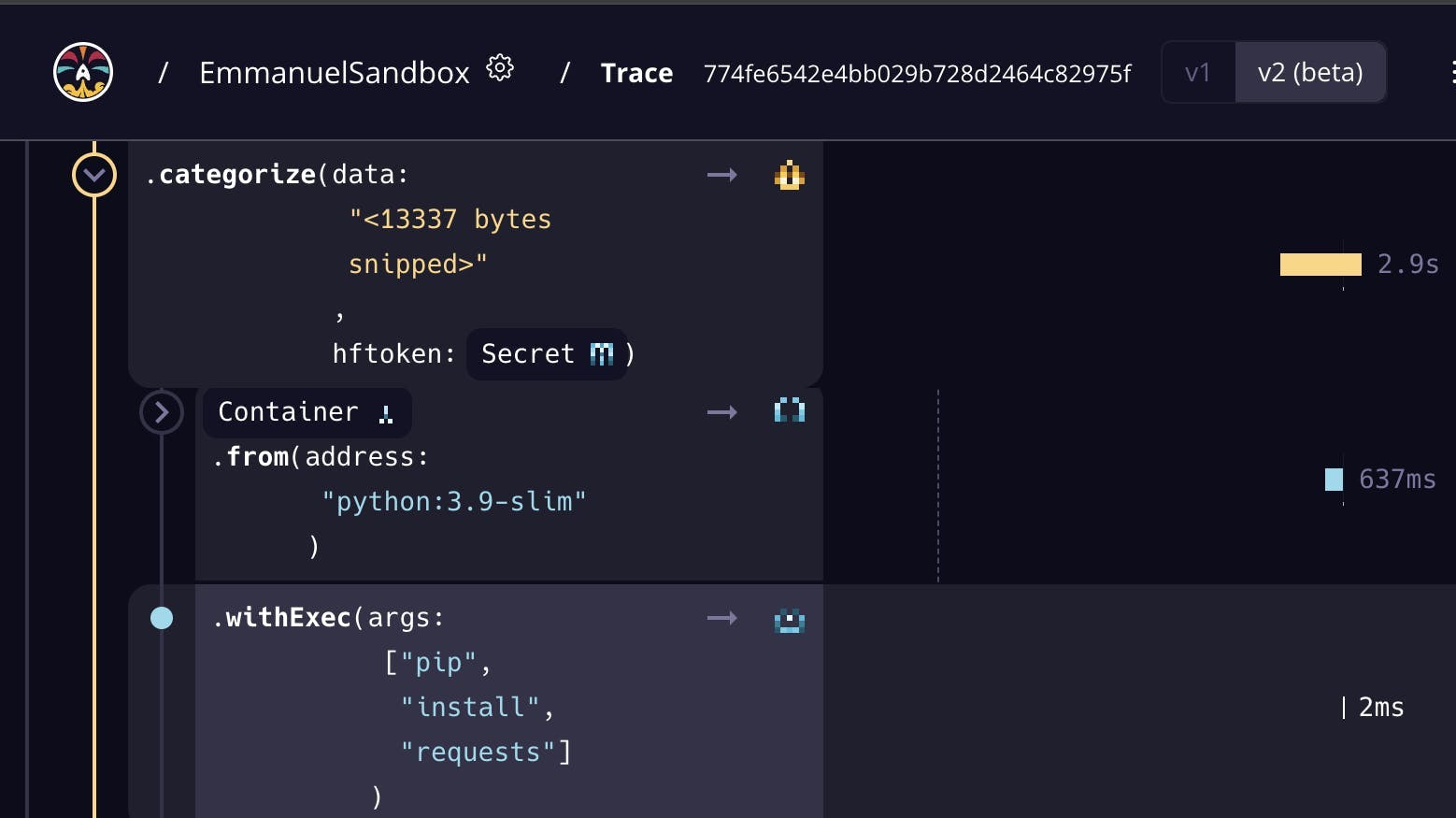
Dagger runs everything in containers, with multiple layers. Each layer is cached if the contents don't change, speeding up builds by re-using cached layers. The process of retrieving data involves a few steps. I first need to install the requests library, which I will use within the Python script to fetch data.
I will fetch the data from Google Sheets and then process the data. I split these into separate steps executing using with_exec within the container. Caching the response from retrieving the data and reusing this cached data to process and output the data.
This function structures the data and outputs a JSON-formatted string consisting of all bank transactions. This outputs a JSON containing a list of all transactions.
[
{
"": "",
"Date": "5/20/2024",
"Description": "Twilio Inc",
"Category": "",
"Amount": "-$20.00",
"Account": "*****",
"Account #": "*****",
"Institution": "Capital One",
"Month": "5/1/24",
"Week": "5/19/24",
"Transaction ID": "********",
"Account ID": "*****",
"Check Number": "",
"Full Description": "TWILIO INC",
"Date Added": "5/20/24"
},
...
]
Filter for New Transactions
I need to filter for new transactions.
Why...
I want to keep the pipeline optimized. If I merely fetch transactions and write them to a database, I would be sending redundant data and constantly re-writing the database. I built and published the filterForNewTransactions module. This module fetches transactions from a MongoDB database and filters the transactions retrieved from my spreadsheet by a unique identifier, the transaction ID.
In order to fetch transactions, the module takes in a MongoDB connection string and the name of the database and collection where this data is stored.
Categorizing Transactions Using AI
As a next step, I need to categorize each transaction.
Why...
Each transaction can be grouped based on what the spend relates to. After discussing with my wife, we settled on defining our transactions according to these categories:
- Grocery
- Snacks
- Takeouts
- Entertainment
- Transportation
- Credit Card Payment
- Shopping
- Personal Care
- Healthcare
We defined these as our 'variable costs.' These are the categories of expenses that would benefit most from us developing better habits in monitoring our weekly spending. Grouping transactions according to these categories will give AI more insights into our spending habits and offer better advice.
How Do I Categorize My Data...
In making this decision I had two priorities;
-
Simplicity: The simpler the solution, the more likely I am to get a better understanding of what it does. I want to do minimal fine-tuning even if it means sacrificing a degree of accuracy for simplicity.
-
I want a module that will run relatively quickly.
Based on this, I chose the facebook/bart-large-mnli. This model is a zero-shot text classification model. Zero-shot refers to the process of getting "
Dealing With HuggingFace API Rate Limits...
Since I am accessing the model through HuggingFace's API, even though I am filtering for new transactions, I found myself hitting the API rate limit frequently when categorizing data
Optimizing Module...
To optimize this module, I needed to break down the transactions into batches. If I send the data sequentially, assuming I have 10 batches, I would send one batch, hit the API rate limit, wait for the rate limit reset period, send another batch, and so on. If a batch encounters an error, the entire process would need to wait until this batch is resolved.
By turning this into an asynchronous process, I can send multiple batches concurrently. This means when one batch hits the API rate limit, the module can continue processing other batches simultaneously. This more evenly distributes the API requests over time, reducing the likelihood of hitting the rate limit too frequently. This is important because whenever I hit the rate limit, I have to manually delay the next run to refresh my rate limit.
For added fault tolerance, I parse all transactions into a processed and unprocessed list. In the event some of the categorization fails, these transactions will be pushed to the unprocessed list. I built retry mechanisms ensuring these transactions are isolated and retried upon failure.
Dynamic Batching
When I am sending batches to the HuggingFace API, I could send batches with a fixed size. However, I could be underutilizing the API’s capacity. I used Dagger Cloud to measure this entire process with a fixed batch

I optimized this by implementing a dynamic batching strategy, letting the HuggingFace API
initial_batch_size = 50
current_batch_size = initial_batch_size
api_call_times = []
response_times = []
@function
async def categorize(self, data: str, hftoken: Secret) -> str:
"""Processes transactions using an AI model from Hugging Face with retry logic for API limits."""
retry_delay = 5
processed = []
unprocessed = json.loads(data)
while unprocessed:
batch_size = self.adjust_batch_size()
batch = unprocessed[:batch_size]
unprocessed = unprocessed[batch_size:]
start_time = time.time()
batch_processed, batch_unprocessed = await self.process_batch(batch, hftoken)
end_time = time.time()
self.api_call_times.append(end_time)
self.response_times.append(end_time - start_time)
self.cleanup_api_call_times()
processed.extend(batch_processed)
unprocessed = batch_unprocessed + unprocessed
if unprocessed:
await asyncio.sleep(retry_delay)
return json.dumps(processed, indent=4)
def adjust_batch_size(self):
"""Adjust the batch size based on the response times and API rate limits."""
if len(self.api_call_times) > 1 and (self.api_call_times[-1] - self.api_call_times[0] < 60):
self.current_batch_size = max(1, self.current_batch_size - 1)
elif self.response_times and len(self.response_times) >= 5 and sum(self.response_times[-5:]) / 5 < 1:
self.current_batch_size += 1
return self.current_batch_size
def cleanup_api_call_times(self):
"""Clean up the API call times to keep track within the last minute."""
current_time = time.time()
self.api_call_times = [call_time for call_time in self.api_call_times if current_time - call_time < 60]
Observing an improvement in the time it took to run this process.

Future Considerations...
I intend to expose the data written into the database after this categorization. This will allow my wife and I to have an access point to retrieve all transactions by the week, showing how they have been categorized. We will then send particular arguments to change/correct categorizations where necessary. This information will be used to fine-tune the model to more accurately categorize future transactions.
Write Transactions to Database
I chose MongoDB as my database. I wanted schema flexibility as I intend to add more categorizations to my data. I built and published a module; writeToMongo that accepts a connection string, database and collection name, and data as a string and writes this data to a MongoDB database.
Aggregate Data by Week and Category
I need to send the data to AI. To increase the odds of getting responses, I wanted to aggregate the data, returning a breakdown of all transactions carried out in a given week broken down by category. I would return a list of all transactions and an aggregated amount. Since the data sits in MongoDB, it would be faster to carry out the aggregation within MongoDB due to its proximity to the data. I specifically opted to use
I built and published the getFromMongoDB module which outputs a JSON with the aggregated data
COPY
{"Week: 2024-05-05": {"Categories": {"Transportation": {"Transactions": [{"Description": "Mta Lirr Etix Ticket", "Amount": -12.5}, {"Description": "Lyft", "Amount": -24.16}, ....], "Total": -181.76999999999998}, "Takeouts": {"Transactions": [...], "Total": -44.55}, "Grocery": {"Transactions": [...], "Total": -109.03},...... "TotalWeek": -**.49}, "Week: 2024-04-28": .....
Generate Financial Advice Using AI
For this task, I need to do two things. I need to use the transaction data to generate insights from AI. I also need AI to learn from our feedback so it gradually improves its responses and personalizes the feedback based on our changing financial goals.
This meant designing the getAdvice module with two exposed functions; one where the AI would be given a system role to generate advice while factoring in feedback from a second function that would enable the send user to send a response to AI.
To be able to do this, I needed to implement a history that would persist between pipeline runs. I used LangChain to maintain the AI interaction, leveraging its prebuilt tools to implement a memory for AI. I stored the history of the conversation in its own document in a MongoDB database. In designing the storage of the memory, I made a few considerations.
I didn't want the memory to be filled with data from previous weeks as this might result in inconsistent and inaccurate responses. I instead stored the memory related to the data separately from the feedback given to AI. Each time new data is received, I re-write the portion of the database containing references to the data.
Orchestrating the Pipeline
I needed to think of a simple way to orchestrate these tasks. I thought of the entire process of running the pipeline like a CI pipeline. Each task is a reusable module forming part of a pipeline where each task is dependent on the preceding step.
However, there is one of the CI pipelines that can be triggered independently (receiving messages from an end user to provide AI with feedback to adapt its responses). To orchestrate each task, I built a 'parent method' that runs each task. This module leverages
This 'parent module' sends SMSs with the output generated by AI using
COPY
@function
async def send(self, encoded_message: str, textBelt: Secret) -> str:
"""Returns lines that match a pattern in the files of the provided Directory"""
phone_numbers = ['****', '****']
text_belt_key = await textBelt.plaintext()
for phone_number in phone_numbers:
curl_cmd = (
f"curl -X POST https://textbelt.com/text "
f"--data-urlencode phone='{phone_number}' "
f"--data-urlencode message='{encoded_message}' "
f"-d key='{text_belt_key}'"
)
try:
result = await (
dag.container()
.from_("curlimages/curl:latest")
.with_exec(["sh", "-c", curl_cmd])
.stdout()
)
if "success" not in result:
raise ValueError(f"Failed to send message to {phone_number}: {result}")
except Exception as e:
raise RuntimeError(f"Error sending message to {phone_number}: {e}")
return result
Triggering Dagger Workflow Using GitHub Actions
My pipeline had to be scheduled to run every few days. I expect to receive an SMS twice a week. I opted to use GitHub Actions to trigger the pipeline, primarily choosing GHA for its simplicity. I could save all sensitive data as GitHub Secrets and pass them down to relevant parts of my pipeline.
According to GitHub Docs, "thescheduleevent allows you to trigger a workflow at a scheduled time. You can schedule a workflow to run at specific UTC times using POSIX cron syntax. Scheduled workflows run on the latest commit on the default or base branch."
on:
schedule:
- cron: '0 0 */3 * *'
I used the schedule event to trigger my workflow every 3 days.
Why Is This a Dagger Pipeline...
Modularity
I want to break this build down into multiple steps. This helps me isolate failure points. I want it to be as easy as possible to catch errors, know where they come from, and read code that is easy enough to enable me to fix the error quicker. I have built enough projects to know that I could look at my code from two months ago and be confused if it isn't optimized for modularity.
Cache, Speed, and Consistency
This pipeline will run twice a week, sometimes, it could run more frequently. Not only do we get advice from AI, but we can respond to this advice to better tailor the responses from AI ensuring the advice improves based on user feedback. In practical terms, this means we could be running some steps of this pipeline multiple times a day.
Since Dagger caches every operation, for example, in instances where the underlying data hasn't changed (the transactions), this data will be fetched from the cache. The speed benefits add up.
Beyond speed, there is added consistency. If something fails, the pipeline can fetch results from the cache of the last non-failing function. I want a robust system that is predictable.
Simplified and Consistent Orchestration
I envisioned building this like a CI pipeline, using Dagger to orchestrate each step in the pipeline. By using Dagger, I could 'Daggerize' not only the methods in the pipeline but the entire pipeline, using Dagger to orchestrate the pipeline of Dagger methods.
Future Considerations...
While these priorities might change as we continue to use this tool, currently I would like to:
- Ensure our model gives us useful, personalized, and actionable advice. This will involve giving the AI more feedback to modify responses.
- Building an autonomous agent that will factor in our goals (i.e. how we want to spend per month/week while prioritizing health and wellness and spending on things that either help us build more money or skills) and construct its own optimal budget (i.e. how it would spend money in a given week). This will be sent to us weekly (along with actionable advice), to give us ideas on how we can spend our money to optimize our goals
GitHub Repository: https://github.com/EmmS21/daggerverse
Dagger Modules: https://daggerverse.dev/search?q=EmmS21
如有侵权请联系:admin#unsafe.sh