XML 指可扩展标记语言(eXtensible Markup Language),被设计用来传输和存储数据。
最典型的xml文件是像这样的格式的
<?xml version="1.0" encoding="UTF-8"?> <note> <to>Tove</to> <from>Jani</from> <heading>Reminder</heading> <body>Don't forget me this weekend!</body> </note>
看起来就是很像html的东西,但他们还是不同的
- XML 被设计用来传输和存储数据,其焦点是数据的内容。
- HTML 被设计用来显示数据,其焦点是数据的外观。
更多详细有关xml可参考 https://www.runoob.com/xml
libxml2呢,就是用来处理的xml格式文件的一个c语言libc库和工具包
挖掘这种三方件,是比较适合用afl-fuzz的,因为他是属于处理格式化文件类的,有套固定的文件格式,比较适合用来fuzz
我这里按照 afl-training中的来操作,afl-training是一个很不错的afl-fuzz入门使用的github项目,从教你fuzz简单的c程序,到fuzz libc函数,再到fuzz一些三方件,算是比较具体细致的实战指引
挖掘2.9.2版本,存在一些历史cve,康康能不能挖掘出来
需要先安装一波东西
sudo apt install autoconf
sudo apt install libtool-bincd libxml2根目录,执行以下
./autogen.sh --prefix=/home/zeref/AFl-fuzz_project/afl-training/challenges/libxml2/build/ --with-python-install-dir=/home/zeref/AFl-fuzz_project/afl-training/challenges/libxml2/build/ CC=afl-clang-fast
这里的--prefix指定安装目录,包括libc和include头文件那些
这里的--with-python-install-dir指定安装python的目录
ps:
这里的afl-clang-fast在默认安装的afl中是没有的,需要你机器上安装了clang,然后切换到afl的llvm_mode目录再进行
make,然后再切回afl根目录进行make install,详细可见 https://xz.aliyun.com/t/1541使用afl-clang-fast的好处是可以减小更多性能开支,使用
__AFL_LOOP(1000)这样的东西减少不断fork 目标程序的次数
继续,通过configure 生成了一波Makefile,接着仍然在libxml2根目录
执行AFL_USE_ASAN=1 make -j 4
-j 4,是开四个进程进行处理
这里的AFL_USE_ASAN=1 ,是指开启ASAN辅助,这个玩意是基于clang的一个内存错误检测器,可以检测到常见的内存漏洞,如栈溢出,堆溢出,double free,uaf等等
由于afl呢是基于崩溃报错来反馈漏洞的,但很多时候,少量的字节 堆溢出是不会引起崩溃报错的,这样就需要额外开启ASAN来辅助挖掘漏洞
最后sudo make -j 4 install,安装过程中可能会报一些小错误,但不用管它,我们只需要用到安装好的libc库和include文件头
按照afl-training中的写成如下harness.c,主要测试几个简单的函数
#include "libxml/parser.h" #include "libxml/tree.h" int main(int argc, char **argv) { if (argc != 2){ return(1); } xmlInitParser(); while (__AFL_LOOP(1000)) { xmlDocPtr doc = xmlReadFile(argv[1], NULL, 0); if (doc != NULL) { xmlFreeDoc(doc); } } xmlCleanupParser(); return(0); }
AFL_USE_ASAN=1 afl-clang-fast ./harness.c -I ./build/include/libxml2/ -L ./build/lib -lxml2 -lz -lm -g -o harness
如果是写测试libxml2的程序,可以使用上述动态链接的方式,如果写直接用于afl-fuzz的程序,我们就需要使用静态链接的方式把libxml2加载进程序中,这是为了asan或afl编译插桩的时候能直接在libxml2源码中进行操作
AFL_USE_ASAN=1 afl-clang-fast ./harness.c -I ./build/include/libxml2/ ./build/lib/libxml2.a -lz -lm -g -o harness
-I(大写i)指定include头文件的目录,然后接上libxml2的静态链接库,(小写L)-lm 使用math库,-lz 使用zlib库
然后启动afl
afl-fuzz -m none -i in -o out -x ~/afl-2.52b/dictionaries/xml.dict ./harness @@
-m 表示给fuzz子进程的内存限制,这里为了更好体现asan效果,使用none不进行限制
-x 表示设置xml文件格式的字典,也就是设置一些xml里面的关键词token,便于fuzz找到更多的路径
可以看到,不出一个小时,就出现了crash
最后俺整整跑了一天,出现了8个uniq crash,然而本质上这八个都是一样的报错:

疑似产生了 一个字节的 堆空间溢出读操作,这8个crash都是由asan报错产生的
下面来分析一下这8个crash到底是怎么产生的
这里asan的报错信息提醒非常的到位,很容易就定位到漏洞所在的地方
打开source insight,查看源码
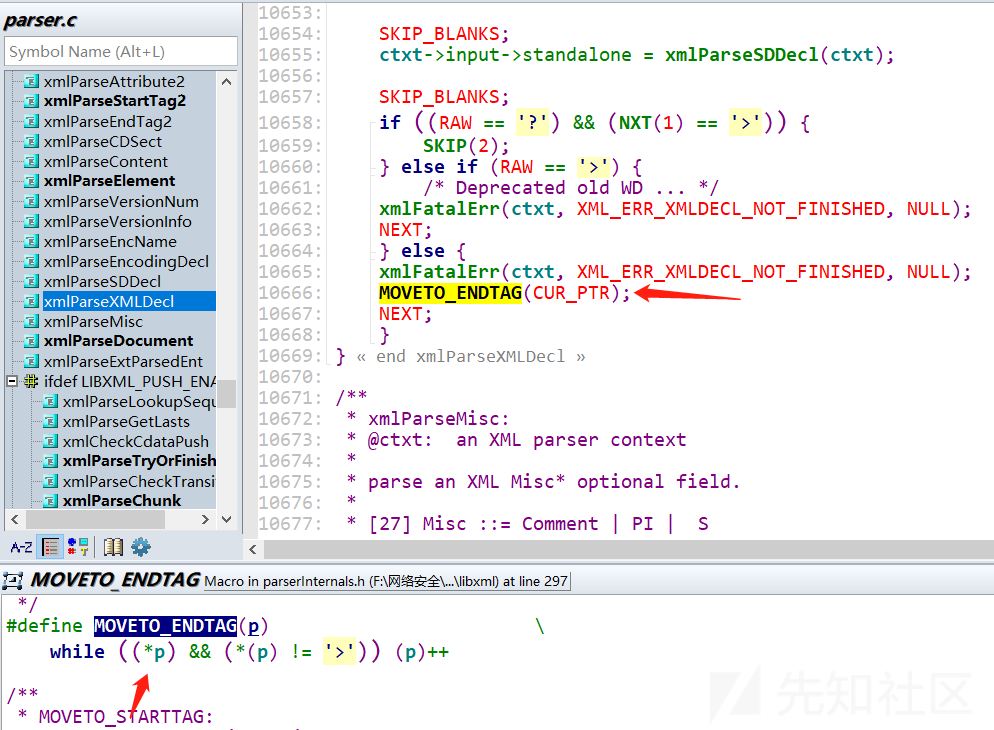
这里很容易就找到了这个所谓的 一个字节的堆溢出读,其实就是这个while循环结束时,最后一次判断*p的值的时候发生的,本来一开始我还不信是这个原因导致的crash,于是我把MOVETO_ENDTAG(CUR_PTR);这句给注释掉再重新编译一次,然后跑一遍一样的crash 输入样本,结果一点报错都没有。。。。。
这么看来,这压根就不算是漏洞orz,纯粹asan误报
更无语的是,这8个crash中,7个都是在同一个地方的产生的
最后,来康康第8个crash
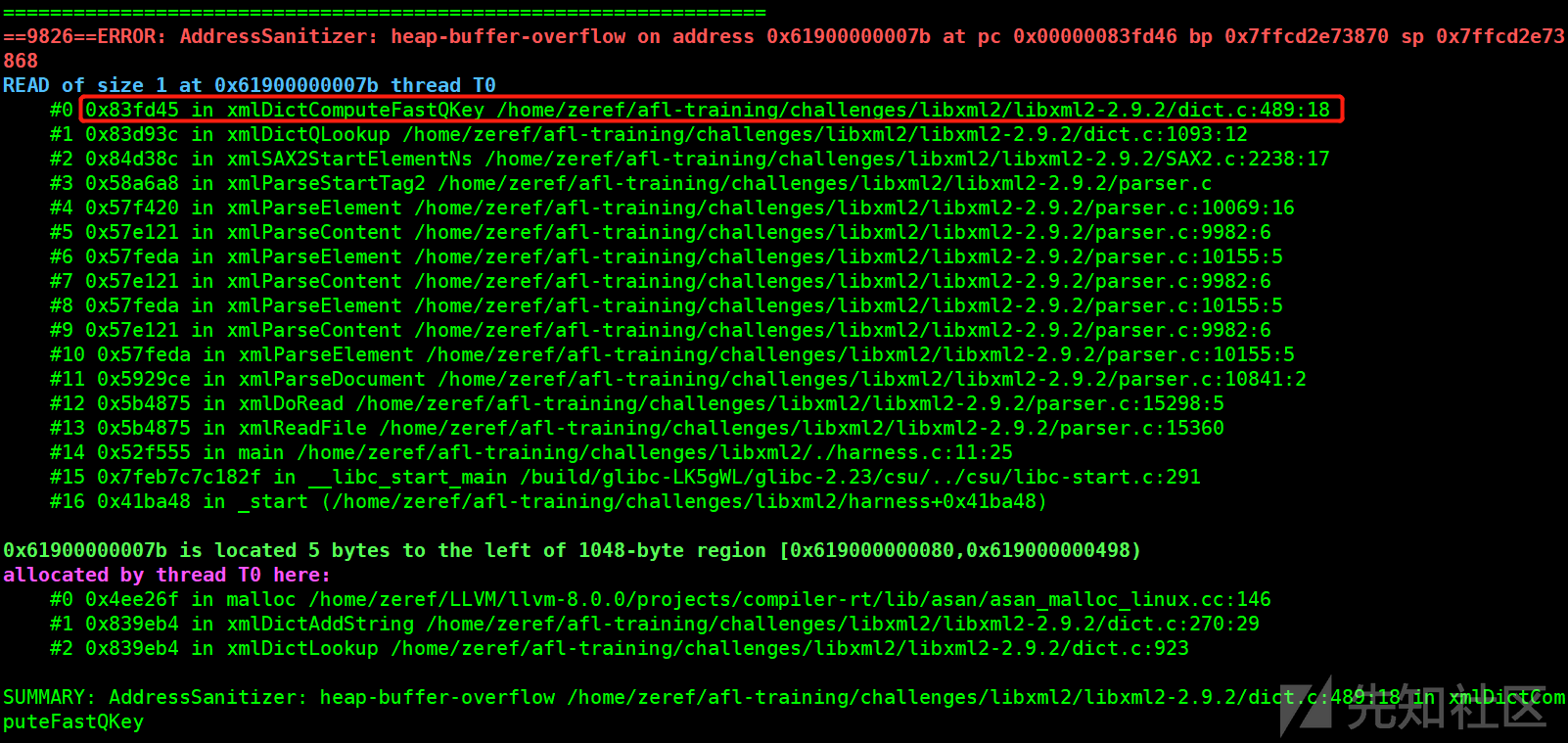
同样是一个字节的堆空间溢出读操作,这个就勉勉强强算个漏洞了
不过值得注意的是,这里的asan报错信息是不完全正确的,根据gdb的调试结果
backtrace中#1说是#1 0x83d93c in xmlDictQLookup ..../libxml2-2.9.2/dict.c:1093:12
而实际1093行是不对的,1118行才是产生漏洞的地方,这可能是因为xmlDictQLookup函数调用了两次的xmlDictComputeQKey函数,导致误报为第一次调用xmlDictComputeQKey的地方
来看看源码

很明显这里的漏洞点是,下标越界的问题,没有对len - (plen + 1 + 1)进行足够的判断,产生了下标越界的漏洞
gdb调试一波,在即将call xmlDictComputeQKey的时候:

可以看到,这里plen=0x71,len=0xc,len - (plen + 1 + 1)= -0x67
这样就产生了下标越界了
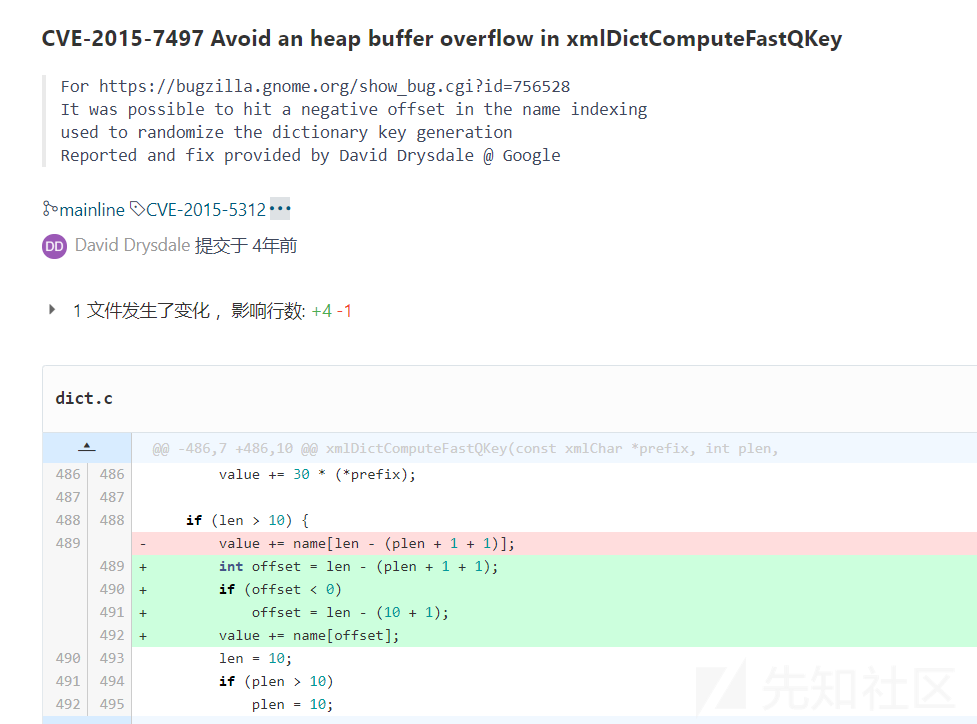
这个漏洞正是CVE-2015-7497
在2.9.3的版本中就有如下patch修改
到这里,基本上算是完成了afl-training的第一个challenge,可以发现,使用afl并不复杂,挖掘出历史cve也是可行的,但是上面的操作还可以进一步改善,例如harness中只fuzz了几个简单的函数,还可以继续增加新的函数加入测试,以探索出更多的路径;上述fuzz中只用到了xml的格式字典,还可以通过增加大量xml文件来提高输入样本的质量
改进方法分三步:
- 首先patch解决产生之前crash的源代码
- 改进harness.c,提高程序覆盖率
- 增加输入样本,并对样本进行精简
patch已知bug
首先解决第一个误报问题,patch方法是在parse.c文件中进行如下修改

创建一个自定义函数MOVETO_ENDTAG_patch替换原来的宏定义功能

加上关键词 __attribute__((no_sanitize_address))表示添加asan白名单,该函数就会被asan忽略检查
然后是patch CVE-2015-7497,根据官方patch,修改dict.c即可
patch完毕后重新编译libxml2,编译完成后可测试之前产生crash的样本是否还会继续crash报错,如果无报错且程序运行正常,则说明patch成功
改进harness.c
前面的harness.c中,主要使用了以下函数
xmlInitParser(); xmlDocPtr doc = xmlReadFile(argv[1], NULL, 0); xmlFreeDoc(doc); xmlCleanupParser();
最主要的,还是xmlReadFile函数,因此我们需要增加测试的函数
#include <stdio.h> #include <libxml/parser.h> #include <libxml/tree.h> static void print_element_names(xmlNode * a_node) { xmlNode *cur_node = NULL; for (cur_node = a_node; cur_node; cur_node = cur_node->next) { if (cur_node->type == XML_ELEMENT_NODE) { printf("node name: %s\n", cur_node->name); } print_element_names(cur_node->children); } } int main(int argc, char **argv) { xmlDoc *doc = NULL; xmlNode *root_element = NULL; if (argc != 2) return(1); doc = xmlReadFile(argv[1], NULL, 0); if (doc == NULL) { printf("error: could not parse file %s\n", argv[1]); xmlFreeDoc(doc); xmlCleanupParser(); return(-1); } while (__AFL_LOOP(1000)) { root_element = xmlDocGetRootElement(doc); print_element_names(root_element); } xmlFreeDoc(doc); xmlCleanupParser(); return 0; }
该程序的功能是先读取xml文件,然后遍历输出节点的内容
精简样本
首先是样本,这里找到一个专门收集各类样本的项目:https://github.com/MozillaSecurity/fuzzdata
但这个库实在太大了,用github下载得好久,我这里就把他先导入到gitee,然后再下载,这速度就快的一批了
根据afl中的使用指南,建议输入样本最好不要超过1kb,因此需要先筛选样本
find ./xml/ -size -1024c > tmp.txt
mkdir less1k
把小于1kb的找出来存储在less1k文件夹
for l in `cat ./tmp.txt`;do cp $l ./less1k/ ;done;
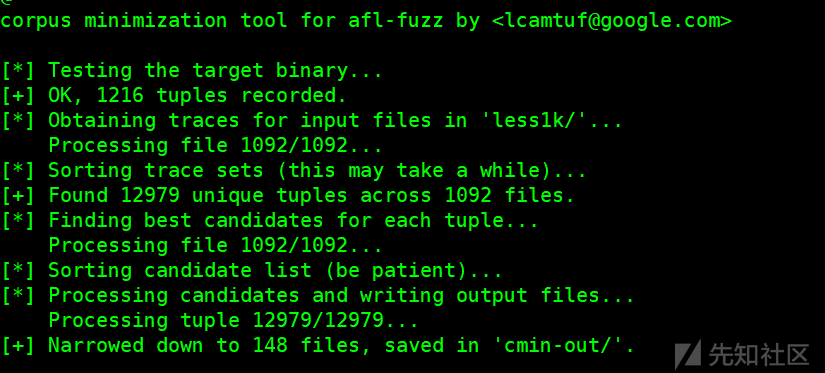
然后使用afl-cmin进行精简样本,把执行相同路径的给去重,留下 具有相同覆盖范围的最小子集
afl-cmin -i less1k/ -o cmin-out/ -m none ./harness1 @@
这样一波精简,从1092个样本精简到148个
然后再使用afl-tmin,对单个文件进行精简,由于文件众多,这里可以用这样的命令循环执行
先mkdir tmin-out,然后cd进入 cmin-out目录
for i in *; do afl-tmin -i $i -o ../tmin-out/$i -m none -- ../harness @@; done;
这是一个很长执行过程,需要对文件逐个精简,大概执行了几十分钟
其实感觉这个tmin的效果还是比较有限的,精简的效果并不是那么显著,第一步的直接大范围筛选效果更好一点
重新fuzz
screen afl-fuzz -m none -i ./tmin-out/ -o out2 -x ./libxml_xml_read_memory_fuzzer.dict -- ./harness @@
这里不再使用afl自带的xml关键词字典,而是在github上面找了一个,token比afl自带的更多
这里使用screen,是为了防止长时间挂着xshell的时候意外断开了,俺经常跑了几个小时由于网络问题就断掉了,害的我又得重新跑,用上screen就不用担心这种问题了
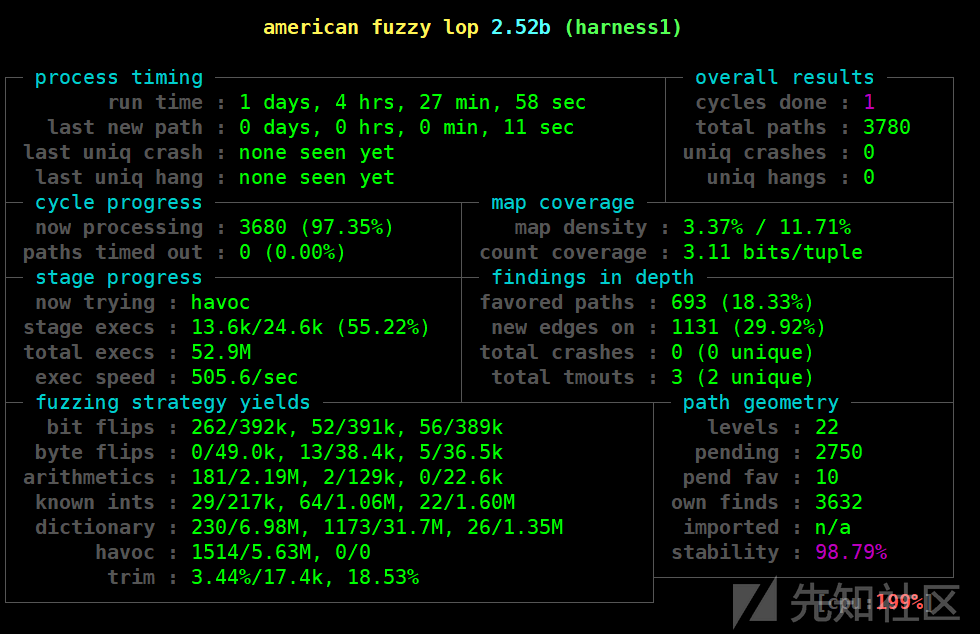
可以发现,同样是跑一天,路径明显变多,但执行速度就慢了很多,这是因为harness.c程序的逻辑也复杂了一点,经过的libxml2函数也更多,然而就是没有出crash,这、、这说明patch打的很成功啊。。。。Orz
如有侵权请联系:admin#unsafe.sh