06/26/2024
12 min read

On Thursday, June 20, 2024, two independent events caused an increase in latency and error rates for Internet properties and Cloudflare services that lasted 114 minutes. During the 30-minute peak of the impact, we saw that 1.4 - 2.1% of HTTP requests to our CDN received a generic error page, and observed a 3x increase for the 99th percentile Time To First Byte (TTFB) latency.
These events occurred because:
- Automated network monitoring detected performance degradation, re-routing traffic suboptimally and causing backbone congestion between 17:33 and 17:50 UTC
- A new Distributed Denial-of-Service (DDoS) mitigation mechanism deployed between 14:14 and 17:06 UTC triggered a latent bug in our rate limiting system that allowed a specific form of HTTP request to cause a process handling it to enter an infinite loop between 17:47 and 19:27 UTC
Impact from these events were observed in many Cloudflare data centers around the world.
With respect to the backbone congestion event, we were already working on expanding backbone capacity in the affected data centers, and improving our network mitigations to use more information about the available capacity on alternative network paths when taking action. In the remainder of this blog post, we will go into more detail on the second and more impactful of these events.
As part of routine updates to our protection mechanisms, we created a new DDoS rule to prevent a specific type of abuse that we observed on our infrastructure. This DDoS rule worked as expected, however in a specific suspect traffic case it exposed a latent bug in our existing rate-limiting component. To be absolutely clear, we have no reason to believe this suspect traffic was intentionally exploiting this bug, and there is no evidence of a breach of any kind.
We are sorry for the impact and have already made changes to help prevent these problems from occurring again.
Background
Rate-limiting suspicious traffic
Depending on the profile of an HTTP request and the configuration of the requested Internet property, Cloudflare may protect our network and our customer’s origins by applying a limit to the number of requests a visitor can make within a certain time window. These rate limits can activate through customer configuration or in response to DDoS rules detecting suspicious activity.
Usually, these rate limits will be applied based on the IP address of the visitor. As many institutions and Internet Service Providers (ISPs) can have many devices and individual users behind a single IP address, rate limiting based on the IP address is a broad brush that can unintentionally block legitimate traffic.
Balancing traffic across our network
Cloudflare has several systems that together provide continuous real-time capacity monitoring and rebalancing to ensure we serve as much traffic as we can as quickly and efficiently as we can.
The first of these is Unimog, Cloudflare’s edge load balancer. Every packet that reaches our anycast network passes through Unimog, which delivers it to an appropriate server to process that packet. That server may be in a different location from where the packet originally arrived into our network, depending on the availability of compute capacity. Within each data center, Unimog aims to keep the CPU load uniform across all active servers.
For a global view of our network, we rely on Traffic Manager. Across all of our data center locations, it takes in a variety of signals, such as overall CPU utilization, HTTP request latency, and bandwidth utilization to instruct rebalancing decisions. It has built-in safety limits to prevent causing outsized traffic shifts, and also considers the expected resulting load in destination locations when making any decisions.
Incident timeline and impact
All timestamps are UTC on 2024-06-20.
- 14:14 DDoS rule gradual deployment starts
- 17:06 DDoS rule deployed globally
- 17:47 First HTTP request handling process is poisoned
- 18:04 Incident declared automatically based on detected high CPU load
- 18:34 Service restart shown to recover on a server, full restart tested in one data center
- 18:44 CPU load normalized in data center after service restart
- 18:51 Continual global reloads of all servers with many stuck processes begin
- 19:05 Global eyeball HTTP error rate peaks at 2.1% service unavailable / 3.45% total
- 19:05 First Traffic Manager actions recovering service
- 19:11 Global eyeball HTTP error rate halved to 1% service unavailable / 1.96% total
- 19:27 Global eyeball HTTP error rate reduced to baseline levels
- 19:29 DDoS rule deployment identified as likely cause of process poisoning
- 19:34 DDoS rule is fully disabled
- 19:43 Engineers stop routine restarts of services on servers with many stuck processes
- 20:16 Incident response stood down
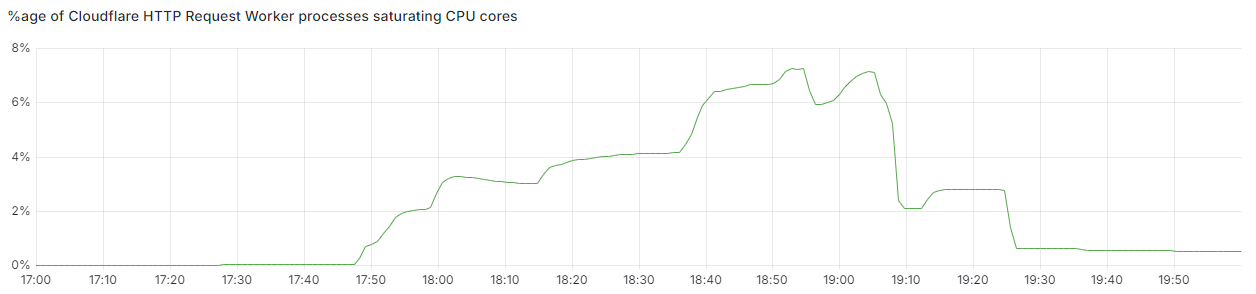
Below, we provide a view of the impact from some of Cloudflare’s internal metrics. The first graph illustrates the percentage of all eyeball (inbound from external devices) HTTP requests that were served an error response because the service suffering poisoning could not be reached. We saw an initial increase to 0.5% of requests, and then later a larger one reaching as much as 2.1% before recovery started due to our service reloads.
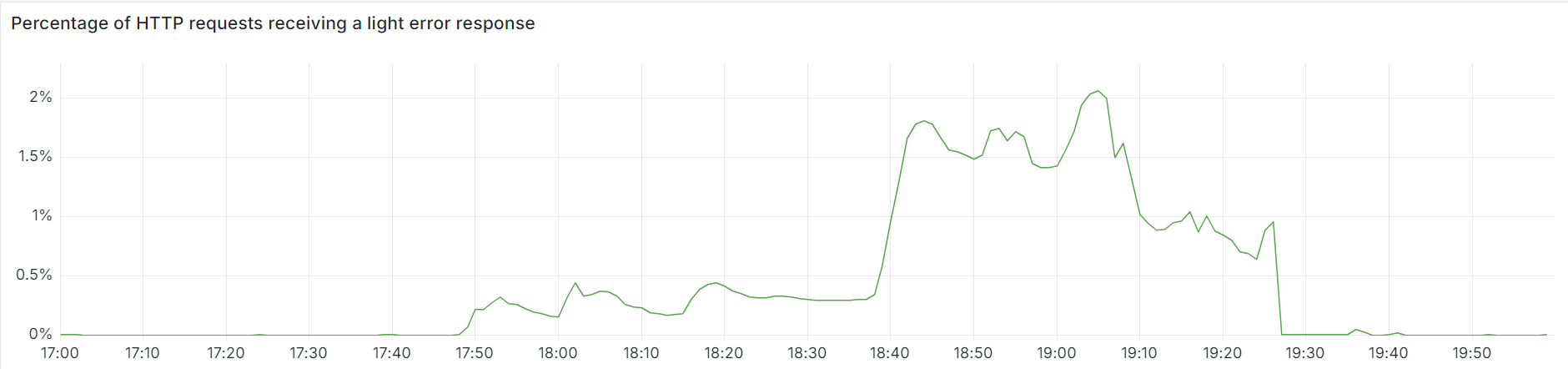
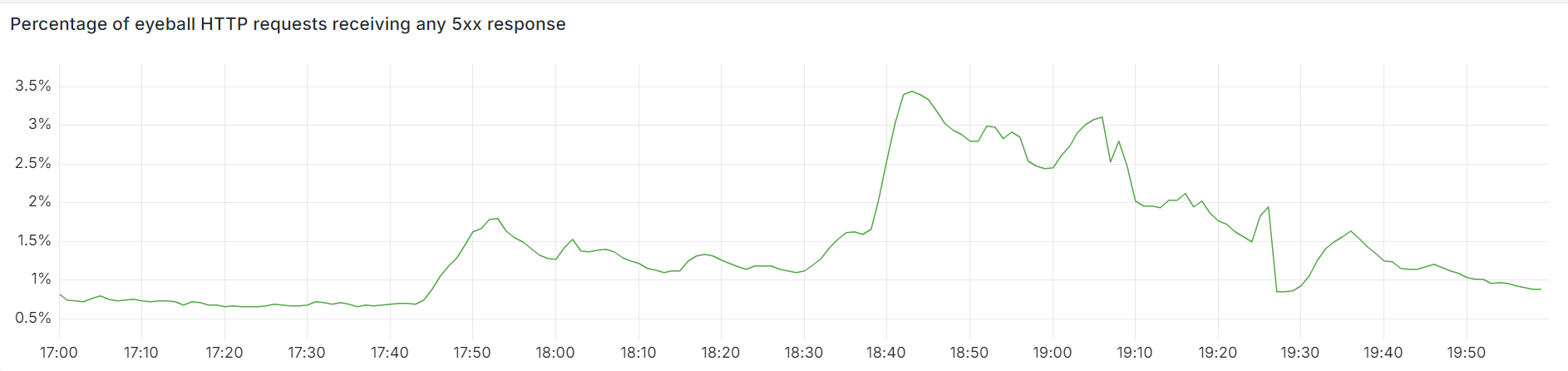
For a broader view of errors, we can see all 5xx responses our network returned to eyeballs during the same window, including those from origin servers. These peaked at 3.45%, and you can more clearly see the gradual recovery between 19:25 and 20:00 UTC as Traffic Manager finished its re-routing activities. The dip at 19:25 UTC aligns with the last large reload, with the error increase afterwards primarily consisting of upstream DNS timeouts and connection limits which are consistent with high and unbalanced load.
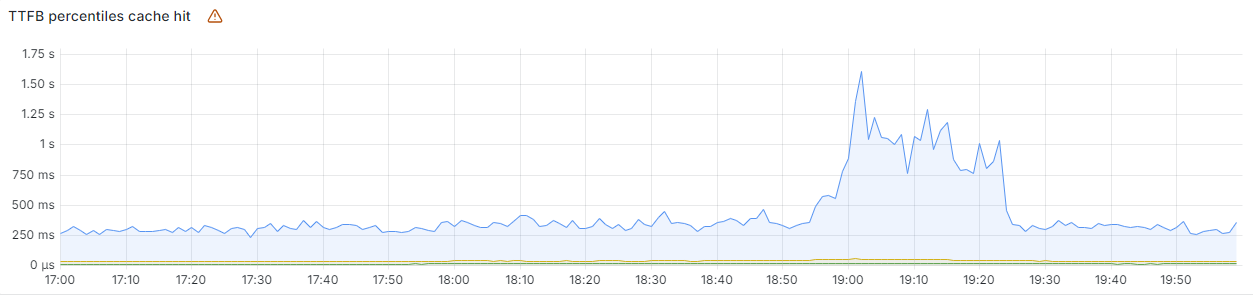
And here’s what our TTFB measurements looked like at the 50th, 90th and 99th percentiles, showing an almost 3x increase in latency at p99:
Technical description of the error and how it happened
Earlier on June 20, between 14:14 - 17:06 UTC, we gradually activated a new DDoS rule on our network. Cloudflare has recently been building a new way of mitigating HTTP DDoS attacks. This method is using a combination of rate-limits and cookies in order to allow legitimate clients that were falsely identified as being part of an attack to proceed anyway.
With this new method, an HTTP request that is considered suspicious runs through these key steps:
- Check for the presence of a valid cookie, otherwise block the request
- If a valid cookie is found, add a rate-limit rule based on the cookie value to be evaluated at a later point
- Once all the currently applied DDoS mitigation are run, apply rate-limit rules
We use this "asynchronous" workflow because it is more efficient to block a request without a rate-limit rule, so it gives a chance for other rule types to be applied.
So overall, the flow can be summarized with this pseudocode:
for (rule in active_mitigations) {
// ... (ignore other rule types)
if (rule.match_current_request()) {
if (!has_valid_cookie()) {
// no cookie: serve error page
return serve_error_page();
} else {
// add a rate-limit rule to be evaluated later
add_rate_limit_rule(rule);
}
}
}
evaluate_rate_limit_rules();
When evaluating rate-limit rules, we need to make a key for each client that is used to look up the correct counter and compare it with the target rate. Typically, this key is the client IP address, but other options are available, such as the value of a cookie as used here. We actually reused an existing portion of the rate-limit logic to achieve this. In pseudocode, it looks like:
function get_cookie_key() {
// Validate that the cookie is valid before taking its value.
// Here the cookie has been checked before already, but this code is
// also used for "standalone" rate-limit rules.
if (!has_valid_cookie_broken()) { // more on the "broken" part later
return cookie_value;
} else {
return parent_key_generator();
}
}
This simple key generation function had two issues that, combined with a specific form of client request, caused an infinite loop in the process handling the HTTP request:
- The rate-limit rules generated by the DDoS logic are using internal APIs in ways that haven't been anticipated. This caused the
parent_key_generatorin the pseudocode above to point to theget_cookie_keyfunction itself, meaning that if that code path was taken, the function would call itself indefinitely - As these rate-limit rules are added only after validating the cookie, validating it a second time should give the same result. The problem is that the
has_valid_cookie_brokenfunction used here is actually different and both can disagree if the client sends multiple cookies where some are valid but not others
So, combining these two issues: the broken validation function tells get_cookie_key that the cookie is invalid, causing the else branch to be taken and calling the same function over and over.
A protection many programming languages have in place to help prevent loops like this is a run-time protection limit on how deep the stack of function calls can get. An attempt to call a function once already at this limit will result in a runtime error. When reading the logic above, an initial analysis might suggest we were reaching the limit in this case, and so requests eventually resulted in an error, with a stack containing those same function calls over and over.
However, this isn’t the case here. Some languages, including Lua, in which this logic is written, also implement an optimization called proper tail calls. A tail call is when the final action a function takes is to execute another function. Instead of adding that function as another layer in the stack, as we know for sure that we will not be returning execution context to the parent function afterwards, nor using any of its local variables, we can replace the top frame in the stack with this function call instead.
The end result is a loop in the request processing logic which never increases the size of the stack. Instead, it simply consumes 100% of available CPU resources, and never terminates. Once a process handling HTTP requests receives a single request on which the action should be applied and has a mixture of valid and invalid cookies, that process is poisoned and is never able to process any further requests.
Every Cloudflare server has dozens of such processes, so a single poisoned process does not have much of an impact. However, then some other things start happening:
- The increase in CPU utilization for the server causes Unimog to lower the amount of new traffic that server receives, moving traffic to other servers, so at a certain point, more new connections are directed away from servers with a subset of their processes poisoned to those with fewer or no poisoned processes, and therefore lower CPU utilization.
- The gradual increase in CPU utilization in the data center starts to cause Traffic Manager to redirect traffic to other data centers. As this movement does not fix the poisoned processes, CPU utilization remains high, and so Traffic Manager continues to redirect more and more traffic away.
- The redirected traffic in both cases includes the requests that are poisoning processes, causing the servers and data centers to which this redirected traffic was sent to start failing in the same way.
Within a few minutes, multiple data centers had many poisoned processes, and Traffic Manager had redirected as much traffic away from them as possible, but was restricted from doing more. This was partly due to its built-in automation safety limits, but also because it was becoming more difficult to find a data center with sufficient available capacity to use as a target.
The first case of a poisoned process was at 17:47 UTC, and by 18:09 UTC – five minutes after the incident was declared – Traffic Manager was re-routing a lot of traffic out of Europe:
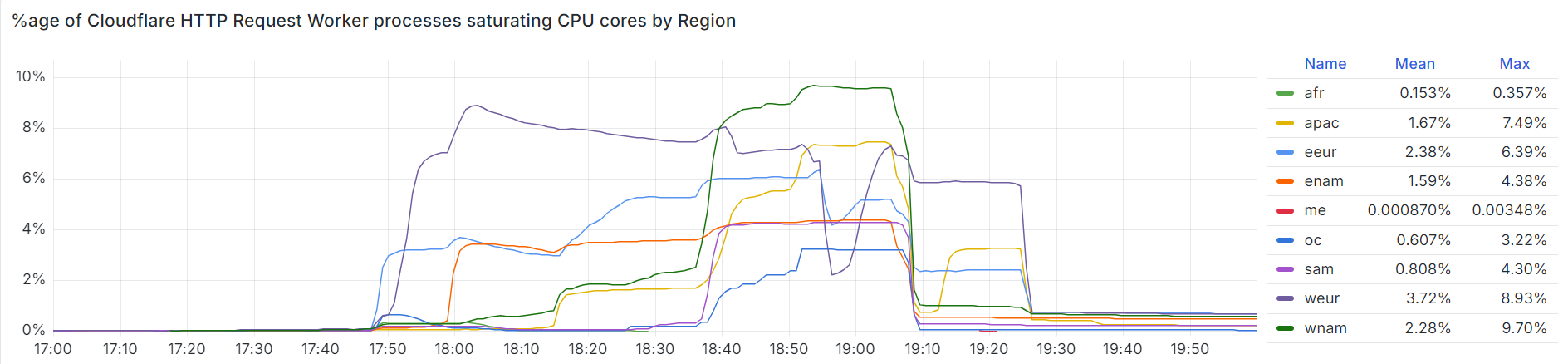
It’s obvious to see why, if we look at the percentage of the HTTP request service’s processes that were saturating their CPUs. 10% of our capacity in Western Europe was already gone, and 4% in Eastern Europe, during peak traffic time for those timezones:
Partially poisoned servers in many locations struggled with the request load, and the remaining processes could not keep up, resulting in Cloudflare returning minimal HTTP error responses.
Cloudflare engineers were automatically notified at 18:04 UTC, once our global CPU utilization reached a certain sustained level, and started to investigate. Many of our on-duty incident responders were already working on the open incident caused by backbone network congestion, and in the early minutes we looked into likely correlation with the network congestion events. It took some time for us to realize that locations where the CPU was highest is where traffic was the lowest, drawing the investigation away from a network event being the trigger. At this point, the focus moved to two main streams:
- Evaluating if restarting poisoned processes allowed them to recover, and if so, instigating mass-restarts of the service on affected servers
- Identifying the trigger of processes entering this CPU saturation state
It was 25 minutes after the initial incident was declared when we validated that restarts helped on one sample server. Five minutes after this, we started executing wider restarts – initially to entire data centers at once, and then as the identification method was refined, on servers with a large number of poisoned processes. Some engineers continued regular routine restarts of the affected service on impacted servers, whilst others moved to join the ongoing parallel effort to identify the trigger. At 19:36 UTC, the new DDoS rule was disabled globally, and the incident was declared resolved after executing one more round of mass restarts and monitoring.
At the same time, conditions presented by the incident triggered a latent bug in Traffic Manager. When triggered, the system would attempt to recover from the exception by initiating a graceful restart, halting its activity. The bug was first triggered at 18:17 UTC, then numerous times between 18:35 and 18:57 UTC. During two periods in this window (18:35-18:52 UTC and 18:56-19:05 UTC) the system did not issue any new traffic routing actions. This meant whilst we had recovered service in the most affected data centers, almost all traffic was still being re-routed away from them. Alerting notified on-call engineers of the issue at 18:34 UTC. By 19:05 UTC the Traffic team had written, tested, and deployed a fix. The first actions following restoration showed a positive impact on restoring service.
To resolve the immediate impact to our network from the request poisoning, Cloudflare instigated mass rolling restarts of the affected service until the change that triggered the condition was identified and rolled back. The change, which was the activation of a new type of DDoS rule, remains fully rolled back, and the rule will not be reactivated until we have fixed the broken cookie validation check and are fully confident this situation cannot recur.
We take these incidents very seriously, and recognize the magnitude of impact they had. We have identified several steps we can take to address these specific situations, and the risk of these sorts of problems from recurring in the future.
- Design: The rate limiting implementation in use for our DDoS module is a legacy component, and rate limiting rules customers configure for their Internet properties use a newer engine with more modern technologies and protections.
- Design: We are exploring options within and around the service which experienced process poisoning to limit the ability to loop forever through tail calls. Longer term, Cloudflare is entering the early implementation stages of replacing this service entirely. The design of this replacement service will allow us to apply limits on the non-interrupted and total execution time of a single request.
- Process: The activation of the new rule for the first time was staged in a handful of production data centers for validation, and then to all data centers a few hours later. We will continue to enhance our staging and rollout procedures to minimize the potential change-related blast radius.
Conclusion
Cloudflare experienced two back-to-back incidents that affected a significant set of customers using our CDN and network services. The first was network backbone congestion that our systems automatically remediated. We mitigated the second by regularly restarting the faulty service whilst we identified and deactivated the DDoS rule that was triggering the fault. We are sorry for any disruption this caused our customers and to end users trying to access services.
The conditions necessary to activate the latent bug in the faulty service are no longer possible in our production environment, and we are putting further fixes and detections in place as soon as possible.
We protect entire corporate networks, help customers build Internet-scale applications efficiently, accelerate any website or Internet application, ward off DDoS attacks, keep hackers at bay, and can help you on your journey to Zero Trust.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you're looking for a new career direction, check out our open positions.