2024-6-20 01:0:25 Author: hackernoon.com(查看原文) 阅读量:9 收藏
Authors:
(1) Michael Moor, Department of Computer Science, Stanford University, Stanford, USA and these authors contributed equally to this work;
(2) Qian Huang, Department of Computer Science, Stanford University, Stanford, USA and these authors contributed equally to this work;
(3) Shirley Wu, Department of Computer Science, Stanford University, Stanford, USA;
(4) Michihiro Yasunaga, Department of Computer Science, Stanford University, Stanford, USA;
(5) Cyril Zakka, Department of Cardiothoracic Surgery, Stanford Medicine, Stanford, USA;
(6) Yash Dalmia, Department of Computer Science, Stanford University, Stanford, USA;
(7) Eduardo Pontes Reis, Hospital Israelita Albert Einstein, Sao Paulo, Brazil;
(8) Pranav Rajpurkar, Department of Biomedical Informatics, Harvard Medical School, Boston, USA;
(9) Jure Leskovec, Department of Computer Science, Stanford University, Stanford, USA.
Table of Links
6 Discussion, Acknowledgments, and References
4 EVALUATION
4.1 AUTOMATIC EVALUATION
Baselines To compare generative VQA abilities against the literature, we consider different variants of the following baselines:
-
MedVINT Zhang et al. (2023b), a visual instruction-tuned VLM based on Llama. As this model was not designed to do few-shot learning (e.g. the image information is prepended to the overall input), we report two modes for MedVINT: zero-shot and fine-tuned, where the model was fine-tuned on the training split of the VQA dataset. Since the rather small Visual-USMLE dataset has no separate training split, we ommit the fine-tuned baseline for that dataset. We used the MedVInT-TD model with PMC-LLaMA and PMC-CLIP backbones.
-
OpenFlamingo Awadalla et al. (2023), a powerful VLM which was trained on generaldomain data, and which served as the base model to train Med-Flamingo. We report both zero-shot and few-shot performance. We expect Flamingo-type models to shine in the fewshot setting which they are designed for (as already the pre-training task includes multiple interleaved image-text examples).
Evaluation datasets To evaluate our model and compare it against the baselines, we leverage two existing VQA datasets from the medical domain (VQA-RAD and PathVQA). Upon closer inspection of the VQA-RAD dataset, we identified severe data leakage in the official train / test splits, which is problematic given that many recent VLMs fine-tune on the train split. To address this, we created a custom train / test split by seperately splitting images and questions (each 90% / 10%) to ensure that no image or question of the train split leaks into the test split. On these datasets, 6 shots were used for few-shot.
Furthermore, we create Visual USMLE, a challenging multimodal problem set of 618 USMLE-style questions which are not only augmented with images but also with a case vignette and potentially tables of laboratory measurements. The Visual USMLE dataset was created by adapting problems from the Amboss platform (using licenced user access). To make the Visual USMLE problems more actionable and useful, we rephrased the problems to be open-ended instead of multiple-choice. This makes the benchmark harder and more realistic, as the models have to come up with differential diagnoses and potential procedures completely on their own—as opposed to selecting the most reasonable answer choice from few choices. Figure 8 gives an overview of the broad range of specialties that are covered in the dataset, greatly extending existing medical VQA datasets which are narrowly focused on radiology and pathology. For this comparatively small dataset, instead of creating a training split for finetuning, we created a small train split of 10 problems which can be used for few-shot prompting. For this dataset (with considerably longer problems and answers), we used only 4 shots to fit in the context window.
Evaluation metrics Previous works in medical vision-language modelling typically focused scoring all available answers of a VQA dataset to arrive at a classification accuracy. However, since we are interested in generative VQA (as opposed to post-hoc scoring different potential answers), for sake of clinical utility, we employ the following evaluation metrics that directly assess the quality of the generated answer:
-
Clinical evaluation score, as rated by three medical doctors (including one board-certified radiologist) using a human evaluation app that we developed for this study. More details are provided in Section 4.2.
-
BERT similarity score (BERT-sim), the F1 BERT score between the generated answer and the correct answer Zhang et al. (2020).
-
Exact-match, the fraction of generated answers that exactly match (modulo punctuation) the correct answer. This metric is rather noisy and conservative as useful answers may not lexically match the correct answer.
4.2 HUMAN EVALUATION
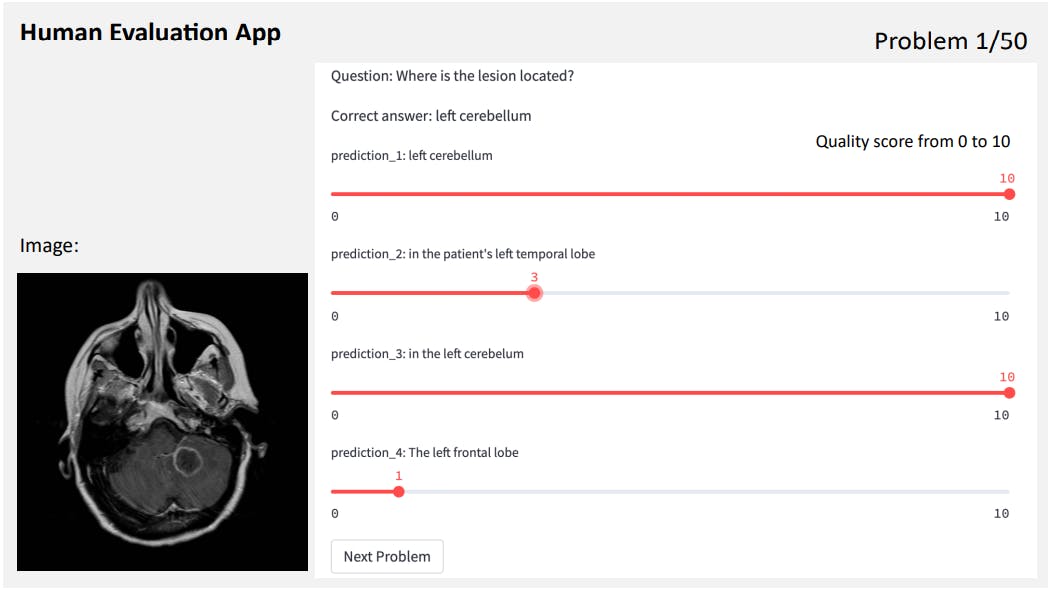
We implemented a human evaluation app using Streamlit to visually display the generative VQA problems for clinical experts to rate the quality of the generated answers with scores from 0 to 10. Figure 4 shows an examplary view of the app. For each VQA problem, the raters are provided with the image, the question, the correct answer, and a set of blinded generations (e.g., appearing as ”prediction 1” in Figure 4), that appear in randomized order.

4.3 DEDUPLICATION AND LEAKAGE
During the evaluation of the Med-Flamingo model, we were concerned that there may be leakage between the pre-training datasets (PMC-OA and MTB) and the down-stream VQA datasets used for evaluation; this could inflate judgements of model quality, as the model could memorize image-question-answer triples.
To alleviate this concern, we performed data deduplication based upon pairwise similarity between images from our pre-training datasets and the images from our evaluation benchmarks. To detect similar images, in spite of perturbations due to cropping, color shifts, size, etc, we embedded the images using Google’s Vision Transformer, preserving the last hidden state as the resultant embedding Dosovitskiy et al. (2021). We then found the k-nearest neighbors to each evaluation image from amongst the pre-training images (using the FAISS library) Johnson et al. (2019). We then sorted and visualized image-image pairs by least euclidean distance; we found that images might be duplicates until a pairwise distance of around 80; beyond this point, there were no duplicates.
This process revealed that the pretraining datasets leaked into the PVQA evaluation benchmark. Out of 6700 total images in PVQA test set, we judged 194 to be highly similar to images in the pretraining datasets, and thus, we removed them from our down-stream evaluation.
如有侵权请联系:admin#unsafe.sh