2024-6-11 23:16:14 Author: hackernoon.com(查看原文) 阅读量:9 收藏
Table of Links
Parrot Training: Feasibility and Evaluation
PT-AE Generation: A Joint Transferability and Perception Perspective
Optimized Black-Box PT-AE Attacks
IV. PT-AE GENERATION: A JOINT TRANSFERABILITY AND PERCEPTION PERSPECTIVE
In this section, we aim to evaluate whether the PT-AEs are as effective as GT-AEs against a black-box GT model. We first summarize AE generation methods that use different types of audio waveforms (i.e., carriers). Next, we quantify the human perceptual quality of AEs with different carriers, then use the match rate to measure the transferability of PT-AEs to GT models. Finally, we define the unified metric, transferability-perception ratio (TPR), to evaluate PT-AEs.
A. Carriers in Audio AE Generation
Recent audio attack studies have considered different audio perturbation carriers to generate AEs via specific generation algorithms. We summarize three main types of carriers.
Noise carriers: Traditional methods [29], [74] usually adopt a gradient estimation method to generate audio AEs in the unrestricted Lp space with the initial perturbation signal set commonly as a Gaussian noise. This leads to a noisy sound despite some psychoacoustic methods [95], [52], [74] that can be used to alleviate the noisy effect.
Feature-twisted carriers: Directly manipulating the auditory feature of a speech signal could make a classifier sensitive but stealthy to the human ears. Existing works [17], [113] have found that modifying the phonemes or changing the prosody of the speech can also spoof the audio classifier while preserving the perception quality.
Environmental sound carriers: The enrollment phase attack [39] employed environmental sounds (e.g., traffic) to create the perturbation signal to poison a speaker recognition model.
B. Quantifying Perceptual Quality of Speech AEs
We first need to find an appropriate perception metric to accurately measure the human perceptual quality of AEs based on different carriers. Recent studies [44], [113] have pointed out that traditional metrics, such as signal-to-noise ratio (SNR) [32] and the Lp norm [114], [29], [118], cannot directly reflect the human perception. They have used different human study-based metrics to measure the perceptual quality of AEs with certain types of carriers (i.e., qDev for music AEs in [44] and NISQA for feature-twisted AEs [113]). In addition, we also notice that the harmonics-to-noise ratio (HNR) [115] is a common metric adopted in speech science to measure the quality of a speech signal. Given these potential perception metrics, we aim at conducting a human study to find out the best metric to measure the perceptual quality across a diversity of AE carriers that we are interested in.
Dataset generation for human study: We create the human study dataset with noise carriers [28], [95], [52], [29], [118], [74], feature-twisted carriers [113], and environmental carriers [39]. We choose 30 original speech signals (with length from 5 to 15 seconds) from the existing speech dataset [82]. We modify these original signals by adding different types of carriers to form perturbed speech signals for the human study. We use the signal-to-carrier ratio (SCR) to control the energy of a perturbation carrier added to an original signal. For example, an SCR of 0dB means that the carrier and the original signal have the same energy level. We consider the following carriers to be added to the original signals.
i) Noise carriers: The dataset [82] provides a wide range of noisy speech signals. The noise is Gaussian-distributed and can be generated with different SNRs. We generated 30 speech samples whose SNRs are uniformly distributed in 0-30 dB. Note that the metric SCR is equivalent to the metric of SNR in the case of noise carriers.
ii) Feature-twisted carriers: For feature-twisted speech signals, we shift the tone (i.e., the pitch) [113] to generate pitch-twisted carriers. Specifically, we shift up/down by 25 semitones[2] of the original speech to craft the pitch-twisted carriers, and add these carriers to the original speech with different SCR levels. For twisting the rhythm, we speed up and slow down the speech ranging from 0.5 to 2 times of its speech rate.
iii) Environmental sound carriers: Environmental sound carriers are selected from the large-scale human-labeled environmental sound datasets [47] with categories including natural sounds (e.g., wind and sea waves), sounds of things (e.g., vehicle and engine), human sounds (e.g., whistling), animal sounds (e.g., pets), and music (e.g., musical instruments). For each category, we randomly selected 6 audio clips.
We have created a total of 90 perturbed speech samples, 30 samples for each carrier set at different SCR levels.
Human participant involvement: We have recruited 30 volunteers, who are college students with no hearing issues (self-reported). Our study procedure was approved by our Institutional Review Board (IRB). Each volunteer is asked to rate the similarity between a pair of original and carrierperturbed speech clips using a scale from 1 to 7 commonly adopted in speech evaluation studies [47], [108], [23], [19], [91], [36], where 1 indicates the least similarity (i.e., speakers sound very different between the two clips) and 7 represents the most similarity (i.e., speakers sound very similar).
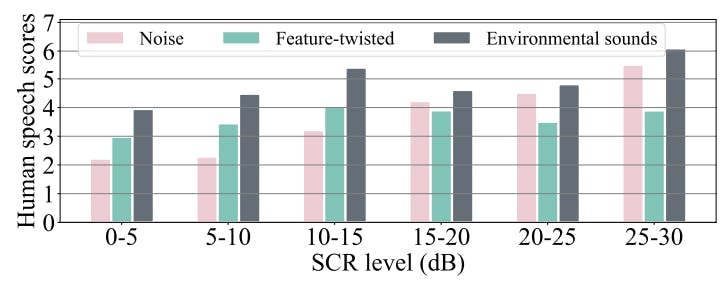
Perceptual quality of different carriers: Fig. 5 compares the average human scores at varying SCR levels for different


carriers. We can clearly see that the perception quality for noise carriers improves gradually with increasing the SCR, which indicates the less loudness of the noise carrier, the better perception of the perturbed speech. Interestingly, the human scores of the feature-twisted and environmental sound carriers are not closely correlated with the SCR. Both of them can indeed get better human scores at lower SCR levels (e.g., 10-15 dB vs 15-20 dB). Fig. 5 also shows that overall, environmental sound carriers yield the better human scores than the feature-twisted carriers and noise carriers.


C. Measuring Transferability of PT-AEs
We then move to evaluate the transferability of different carriers for PT-based AEs.
1) Building Target and Surrogate Models: The first step in evaluating the transferability is to build i) target models, which refer to the models to be attacked by the attacker using PTAEs, and ii) surrogate models, which are used by the attacker to generate PT-AEs against the target models. It is known that the difference between the target and surrogate models can affect the transferability of AEs [76].
Building target models: We consider building a diversity of target models with 4 DNN-based speaker recognition models including 2 CNN [58] and 2 TDNN models [99], [100]. These 4 target models are trained with the same 6 target speakers (3 males and 3 females). We randomly select them from LibriSpeech, and use 120 speech samples for each speaker for training. As the 4 target models have varying architectures and parameters (i.e., number of layers and weights), we denote them as CNN-A, CNN-B, TDNN-A, and TDNN-B. Their accuracies are 100.0%, 96.5%, 99.3%, and 97.2%, respectively.


2) AE generations via different carriers: After building the surrogate and target models, we generate AEs from the surrogate models using the three types of carriers based on existing studies.
i) For the noise carrier, we solve the white-box problem (2) via projected gradient descent (PGD) [49], and we choose L∞ norm as the distance metric, which shows a good performance in Table III. We set ϵ = 0.05 to control the L∞ norm.
ii) For the feature-twisted carrier, we twist the pitch and rhythm of the original speech [113], [44] using the perception metric SRS as the distance measurement. As the random-forest-based SRS is non-differentiable, we use grid search to solve 2. Specifically, we shift up/down for 25 semitones of the pitch, and the minimal shift-pitch step ∆p = 1 semitone. We speed up and slow down the speech ranging from 0.2 to 2.0 its speech rate with the minimal rhythm-changed step ∆r to be 0.2.
iii) For the environmental sound carrier, we choose 30 environmental sounds from [47] which includes natural sounds, sounds of things, human sounds, animal sounds, and music. Based on the SRS to represent the distance D in (2), we solve (2) via finding the best linear weights [44] of different environmental sounds using grid search with the minimal search step to be 0.1ϵ with threshold ϵ set to be 0.05 (the same as the noise carrier’s threshold).
For each carrier type, we generate 20 PT-AEs from each PT-surrogate model (a total of 480 PT-AEs). In addition, we generate 20 GT-AEs from each GT-surrogate model for the comparison purpose (also a total of 480 GT-AEs).
3) Evaluation metric for transferability: The transferability has been extensively studied in the image domain [88], [76], [89], [79]. One important evaluation metric in the transfer attacks [79], [76] is the match rate, which measures the percentage of AEs that can make both a surrogate model and a target model predict the same wrong label. We use the metric of the match rate to measure the transferability of PT-AEs in this work. Specifically, we can test a generated PT-AE: x+δ with both surrogate model f(·) and target model f ′ (·). If f(x +δ)=f ′ (x+δ) ̸= f(x), we can say x+δ is a matched AE for both f(·) and f ′ (·). The match rate is the ratio between the number of matched AEs and the total number of AEs.

Table IV shows the match rates between different surrogate and target models under the 3 types of AE carriers. We can see that the environmental sound carrier achieves better AE transferability than the noise and feature-twisted carriers in terms of the average match rate over the 4 target models. In particular, PT-AEs based on environmental sounds have match rates from 0.23 to 0.27, compared with 0.10 to 0.14 (noise carrier) and 0.15 to 0.22 (feature-twisted carrier). The results demonstrate that using environmental sounds as the carrier achieves the best transferability of PT-AEs from a PT-surrogate model to a target model.
Table IV also compares the match rates of PT-AEs generated from PT models in comparison with GT-AEs generated from GT models. We can observe that the match rate of PTAEs is slightly lower than their GT counterparts. For example, using the noise carrier, GT-AEs based on GT-TDNN-D achieve the best average match rate of 0.1625; in contrast, PT-AEs based on PT-TDNN-D obtain a slightly lower average match rate of 0.1375. Overall, we can see that PT-AEs are slightly less transferable than GT-AEs, but still effective against target models, especially using the environmental sound carrier.
D. Defining Transferability-Perception Ratio for Evaluation
Now, given an AE carrier type C ∈ {noise, feature-twisted, environmental sounds}, we have the metrics of SRS(C) and match rate m(C) to measure the perceptual quality and transferability of PT-AEs of type C, respectively. We define a joint metric, named Transferability-Perception Ratio (TPR), as
TPR(C) = m(C)/(8 − SRS(C)), (4)
where 8 − SRS(C) ranges from 1 to 7, denoting the score loss to the best human perceptual quality. The resultant value of TPR(C) is in [0, 1] and quantifies, on average, how much transferability (in terms of the match rate) we can obtain by degrading one unit of human perceptual quality (in terms of the SRS). A higher TPR indicates a better AE quality from a joint perspective of transferability and perception.
As the attacker only knows one-sentence speech of her target speaker, the length of the speech (measured by seconds) is an important factor for the attacker to build the PT model and determines the effectiveness of PT-AEs. Fig. 6 shows the TPRs of PT-AEs using the 3 types of carriers under different attack knowledge levels (2, 4, 8, and 12 seconds). It is observed in Fig. 6 that the TPRs of all AE carriers increase by giving more knowledge about the target speaker’s speech. For example, the TPR of the environmental sound carrier increases substantially from 0.14 (4-second level) to 0.25 (8-second level), and then slightly to 0.259 (12-second level).
Note that the environmental sound carrier in all three types has the highest TPR at each knowledge level, which is consistent with the findings in Fig. 5 and Table IV. We also see that the feature-twisted carrier achieves the second-highest TPR, while the noise carrier has the lowest TPR. In summary, our TPR results show that we can base environment sounds to generate PT-AEs to improve their transferability to a black-box target model.
[2] 1 semitone = 12 log2 (f ′/f), where f and f ′ are the original and perturbed speech frequencies, respectively [14].
如有侵权请联系:admin#unsafe.sh