
2024-6-7 21:20:57 Author: securityboulevard.com(查看原文) 阅读量:3 收藏

In 2024, GitGuardian Released the State of Secrets Sprawl report. The findings speak for themselves; with over 12.7 million secrets detected in GitHub public repos, it is clear that hard-coded plaintext credentials are a serious problem. Worse yet, it is a growing problem, year over year, with 10 million found the previous year and 6 million found the year before that. These are not cumulative findings!
When we dig a little deeper into these numbers, one overwhelming fact springs out: specific secrets detected, the vast majority of which are API keys, outnumber generic secrets detected in our findings by a significant margin. This makes sense when you realize that API keys are used to authenticate specific services, devices, and workloads within our applications and pipelines to enable machine-to-machine communication. This is very much in line with research from CyberArk, machine identities outnumber human identities by a factor of 45 to one. This gap is only going to widen continually as we integrate more and more services in our codebases and with ever-increasing velocity.
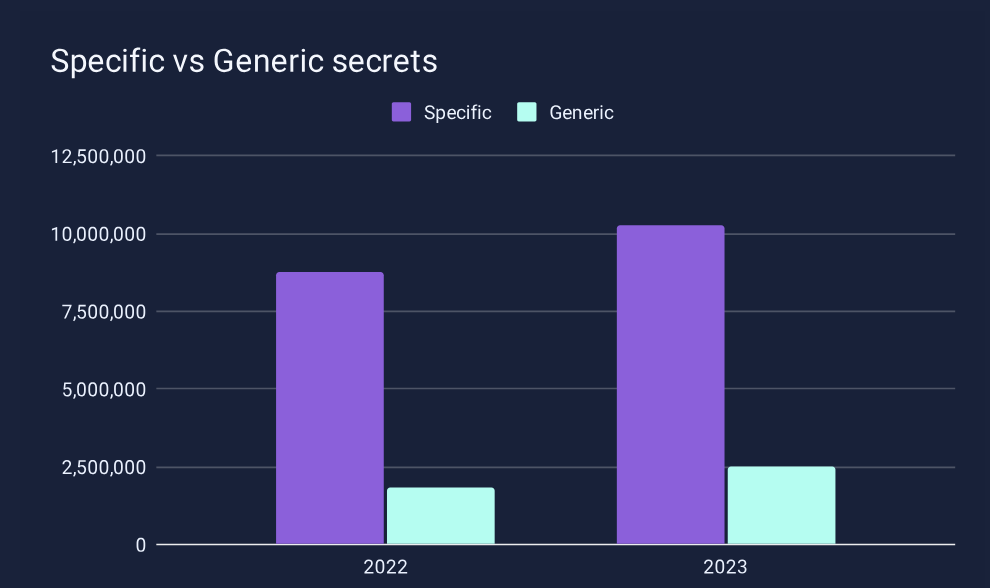
Secrets sprawl is clearly a problem for both human and machine identities, so why should we call out this distinction?
Machine identities
GitGuardian will be leaning into the term "machine identities" moving forward as a way to distinguish this area of secrets sprawl and its unique challenges apart from human identities and credentials. Each is problematic, but each calls for different approaches. We are following the naming convention from industry leaders in secrets management, such as CyberArk and analyst firms who define the industry, such as Gartner, in standardizing this terminology. Gartner defines the term in their 2020 IAM Technologies Hype Cycle report as, "Simply put, a machine identity is a credential used by any endpoint (which could be an IoT device, a server, a container, or even a laptop) to establish its legitimacy on a network." This term covers all API access keys, certificates, Public key infrastructure (PKI), and any other way possible to authenticate machine-to-machine communication.
Is a machine identity the same as a non-human Identity?
From a purely grammatical perspective, it must be a non-human identity if it is not a human identity. So why use the specific term machine identity? Well, practically speaking, a non-human could be a dog, a plant, or even a planet. When using the term "non-human" we must also necessarily further qualify what we mean, while the term 'machine identity' already has a widely accepted definition that narrows the scope to the secrets sprawl problem space.
For example, Venafi, a leading machine identity management platform, succinctly states, "The phrase “machine” often evokes images of a physical server or a tangible, robot-like device, but in the world of machine identity management, a machine can be anything that requires an identity to connect or communicate—from a physical device to a piece of code or even an API."
How did we get here?
Before we can talk about what to do about the issues of machine identities and secrets sprawl, it might be helpful to take a historical look at how we arrived at this point in the industry. In the early days of computer science, the only 'entities' we had to worry about accessing our machines and our code were humans. In the days of ENIAC or early UNIX systems, using a simple password and perhaps sturdy locks on the doors were really all you needed to ensure only the proper people could access a system. People love passwords, and we have for thousands of years. The Roman garrison used 'watchwords', which needed to be updated nightly, meaning we have been practicing manual password rotation for a couple of millennia now.
So, naturally, when it came time to implement machine-to-machine authentication, ensuring that we were only allowing access to trusted systems to recognize and communicate with one another, it was only natural we would turn to our old friend the password, in the form of a long and hard to guess token to get the job done. This system works okay until you remember the problem statement that started this article: we keep leaking these credentials into our code and into places around our code like Jira, Slack, and Confluence at an alarming rate.
Solving both human identity and machine identity sprawl
Now that we have a common vocabulary and understand the two areas of concern, human and machine, what are our next steps? Let's start with human identities. People need to be able to authenticate to gain access to systems to get their work done. Using phishing-resistant MFA, preferably hardware-based, at every juncture where a human uses a password is a solid approach. Even if a password is leaked, it is much harder to exploit and gives the user time to rotate the credential. While not a silver bullet, Microsoft believes this could stop up to 99.9% of fraudulent sign-ins. Even better, if there is a way to eliminate that password, such as with a passkey using FIDO2 or hardware-based biometrics for authentication, then we should probably move in that direction.
Dealing with machine resources requires a different approach, as we can't just turn on MFA for machines. We also can't disrupt these machine identities, as the business of the enterprise is to do business, and the connections must continue to allow our systems to function and satisfy the availability leg of the CIA Triad. Similarly, we can not devote endless resources and hours to this issue, as new vulnerabilities in the form of CVEs, misconfigurations and licensing issues continue to be other areas security teams need to tackle.
In an ideal world, we could immediately move all of our systems to leverage short-lived certificates or JWTs that are issued at run time when needed and only live for the life of the request. Indeed, there are frameworks such as SPIFFE and its implementation, SPIRE, that can help organizations achieve this goal. While this is indeed a great approach, it has the real-world issues of developer adoption, development time and effort, and the overhead of running such services at scale.
While we can dream up many such ideal scenarios, we need to address the current situation head-on. Developers will continue to use machine identities, which can be leaked and exploited by attackers. At the same time, we know that if a malicious actor gets their hands on a secret, they can only leverage it if it is still valid. We believe the best practical solution for any organization is to rotate secrets much more frequently.
Automatically rotating secrets more frequently
One of the other stand-out findings from our State of Secrets Sprawl Report was the fact that of all the valid secrets we discovered in public, over 90% were still valid five days later. We believe this points to the fact that teams expect secrets to be long-lived and that the current manual approach to secrets rotation is hard. Further evidence of these conclusions can be found in breach reports involving companies such as Cloudflare.
In our Secret Management Maturity Model white paper, a clear differentiator in organizations in the Advanced and Expert categories is that they have adopted regular credential rotation policies. It is very unlikely these mature organizations are doing manual rotation, as that would be an overwhelming, time-consuming, and error-prone process, which potentially could mean disaster in our interconnected architectures.
We need a way to automate the rotation process. The good news is that awesome tools are available, such as CyberArk's Conjure or AWS Secrets Manager, that make the process of auto-rotation pretty straightforward. Of course, this assumes all of your machine identities already and totally live within their system.
Auto-rotation of secrets first means knowing all your machine identities
Now, we could ask for every developer and infrastructure owner to give security teams a list of all their credentials in plaintext for all their various workloads, services, and devices, but obviously, that is a terrible and highly problematic idea.
In all seriousness, what is needed is a scalable end-to-end solution that can help you systematically and automatically find all the plaintext credentials inside of your code base, leaked out onto GitHub publicly, or even found in the communication tools that surround your code. Good news! GitGuardian makes exactly this. This is the heart and soul of our Secrets Detection Platform.
Automating the discovery and auto-rotation of machine identities with Brimstone
GitGuardian has partnered with CyberArk to offer a unique solution for security teams to detect machine identity leaks and manage their remediation effectively. We call this project Brimstone. This innovative integration allows communication between the GitGuardian Secrets Detection platform and CyberArk's Conjur, automatically addressing leaked machine identities across various critical scenarios.
- "Unknown" machine identities. Known machine identities already exist in Conjur and need rotation or revocation, while unknown machine identities should be created there and then auto-rotated.
- Known machine identities found in sources monitored by GitGuardian.
- Publicly exposed machine identities on GitHub.com.
If you are already a CyberArk Conjur user, reach out to us to schedule a time to discuss how you can take advantage of this integration.
GitGuardian can help no matter where you store your machine identities
While we are very proud of our advanced integration with CyberArk, you can reap the machine identity discovery no matter where on your secrets management maturity journey. Taking that first step of understanding the scope of your issue is the best step in the right direction any organization can take to begin fighting secrets sprawl and better securing machine identities. Thanks to GitGuardian's dashboard and API, teams can quickly get a handle on tackling the problem of hard-coded secrets, machine identities, and human identities alike. And with ggshield we can help you eliminate the issue at the root, on the developer's machine
If you are struggling with machine identities, we invite you to schedule some time with us to explore what we can do together to make your organization safer while keeping your developers productive and happy. We are all in this together and we would be glad to work with you.
*** This is a Security Bloggers Network syndicated blog from GitGuardian Blog - Code Security for the DevOps generation authored by Dwayne McDaniel. Read the original post at: https://blog.gitguardian.com/securing-your-machine-identities/
如有侵权请联系:admin#unsafe.sh