2024-5-20 15:3:6 Author: hackernoon.com(查看原文) 阅读量:1 收藏
Authors:
(1) Xiaofei Sun, Zhejiang University;
(2) Xiaoya Li, Shannon.AI and Bytedance;
(3) Shengyu Zhang, Zhejiang University;
(4) Shuhe Wang, Peking University;
(5) Fei Wu, Zhejiang University;
(6) Jiwei Li, Zhejiang University;
(7) Tianwei Zhang, Nanyang Technological University;
(8) Guoyin Wang, Shannon.AI and Bytedance.
Table of Links
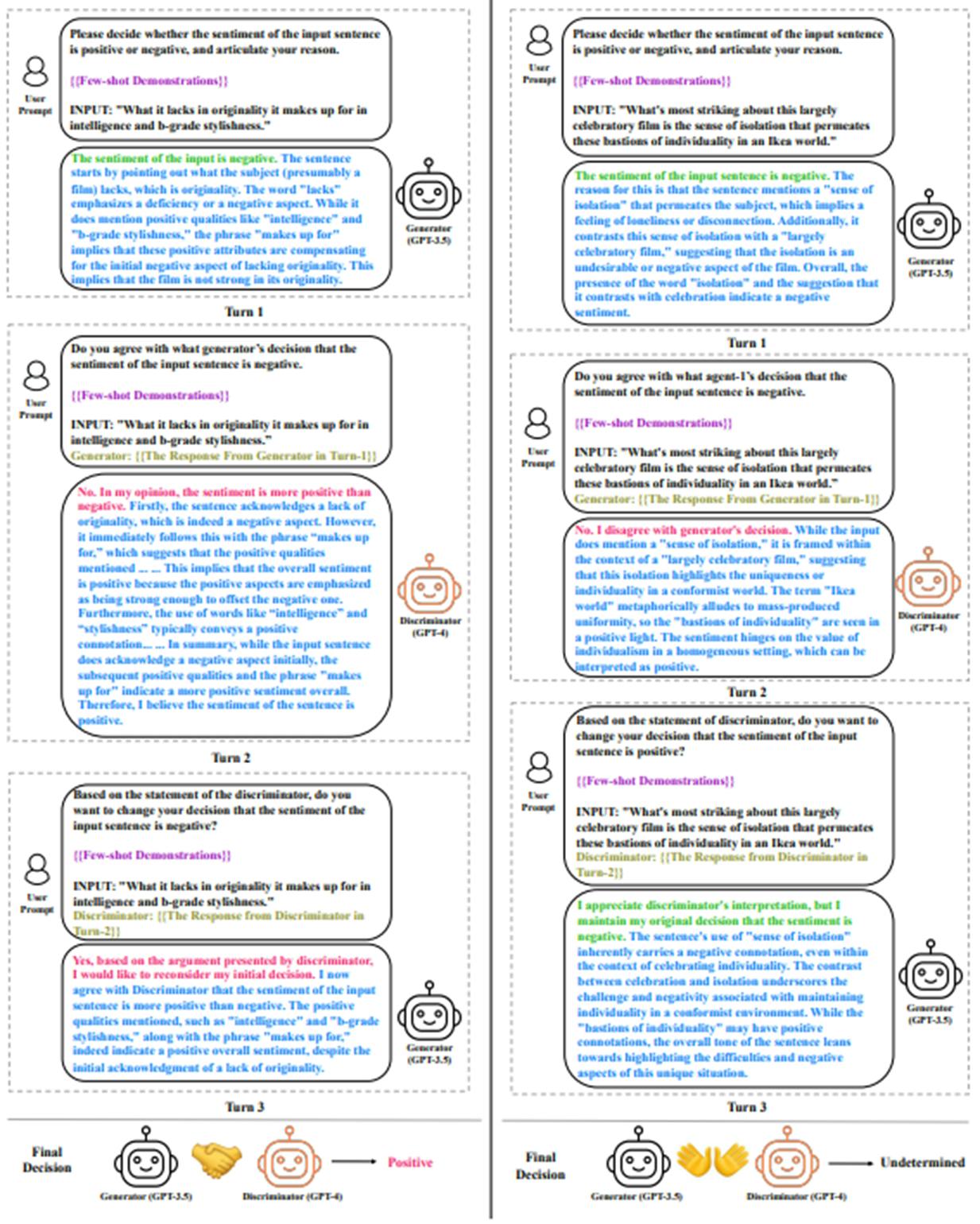
LLM Negotiation for Sentiment Analysis
2.1 Sentiment Analysis
Sentiment analysis (Pang and Lee, 2008; Go et al., 2009; Maas et al., 2011a; Zhang and Liu, 2012; Baccianella et al., 2010; Medhat et al., 2014; Bakshi et al., 2016; Zhang et al., 2018) is a task that aims to determine the overall sentiment polarity (e.g., positive, negative, neutral) of a given text. Earlier work often formalized the task as a two-step problem: (1) extract features using RNNs (Socher et al., 2013; Qian et al., 2016; Peled and Reichart, 2017; Wang et al., 2016b; Guggilla et al., 2016; Vo and Zhang, 2015), CNNs (Kalchbrenner et al., 2014; Wang et al., 2016a; Guan et al., 2016; Yu and Jiang, 2016; Mishra et al., 2017), pretrained language models (Lin et al., 2021; Sun et al., 2021; Phan and Ogunbona, 2020; Dai et al., 2021), etc; and (2) feed extracted features into a classifier for obtaining a pre-defined sentimental label.
In recent years, in-context learning (ICL) has achieved great success and changed the paradigm of NLP tasks. Many works adapt ICL to the sentiment analysis task: Qin et al. (2023b); Sun et al. (2023a) propose a series of strategies to improve ChatGPT’s performance on the sentiment analysis task; Fei et al. (2023) propose a threehop reasoning framework, which induces the implicit aspect, opinion, and finally the sentiment polarity for the implicit sentiment analysis task;ƒ Zhang et al. (2023d) find that LLMs can achieve satisfactory performance on the binary sentiment classification task, but they underperform to the supervised baseline on more complex tasks (e.g., fine-grained sentiment analysis) that require deeper understanding or structured sentiment information.
2.2 Large Language Models and In-context Learning
Large language models (LLMs) (Wang et al., 2022a; Zhang et al., 2023b) are models trained on massive unlabeled text corpora with selfsupervised learning techniques. Based on the model architecture, LLMs can be categorized into three types: (1) encoder-only models, which contain a text encoder and generate the input representations, such as BERT (Devlin et al., 2018) and its variants (Lan et al., 2019; Liu et al., 2019; Sun et al., 2020; Clark et al., 2020; Feng et al., 2020; Joshi et al., 2020; Sun et al., 2020, 2021); (2) decoder-only models, which have a decoder and generate text conditioned on the input text like GPT-series models (Radford et al., 2019; Brown et al., 2020; Keskar et al., 2019; Radford et al., 2019; Chowdhery et al., 2022; Ouyang et al., 2022; Zhang et al., 2022a; Scao et al., 2022; Zeng et al., 2022b; Touvron et al., 2023a; Peng et al., 2023; OpenAI, 2023); and (3) encoder-decoder models, which have a pair of encoder-decoder and generate text conditioned on the input representation, such as T5 (Raffel et al., 2020) and its variants (Lewis et al., 2019; Xue et al., 2020).

Starting with GPT-3 (Brown et al., 2020), LLMs have shown emerging capabilities (Wei et al., 2022a) and completed NLP tasks through incontext learning (ICL), where LLMs generate labelintensive text conditioned on a few annotated examples without gradient updates. Many studies in the literature propose strategies for improving ICL performances on NLP tasks. Li and Liang (2021); Chevalier et al. (2023); Mu et al. (2023) optimize prompts in the continuous space. Liu et al. (2021a); Wan et al. (2023); Zhang et al. (2023a) search through the train set to retrieve k nearest neighbors of a test input as demonstrations. Zhang et al. (2022b); Sun et al. (2023b); Yao et al. (2023) decompose a task into a few subtasks and solve them step-by-step towards the final answer conditioned on LLM-generated reasoning chains. Sun et al. (2023a); Wang et al. (2023) propose to verify LLMs’ results by conducting a new round of prompting; Liu et al. (2021b); Feng et al. (2023) use LLMs to generate natural language knowledge statements and integrate external knowledge statements into prompts.
2.3 The LLM collaboration
The LLM collaboration involves multiple LLMs working together to solve a given task. Specifically, the task is decomposed to several intermediate tasks, and each LLM is assigned to complete one intermediate task independently. The given task is solved after integrating or summarizing these intermediate results. The LLM collaboration approach can exploit the capabilities of LLMs, improve performances on complex tasks and enable to build complicated systems. Shinn et al. (2023); Sun et al. (2023a); Gero et al. (2023); Wang and Li (2023); Chen et al. (2023b) construct auxiliary tasks (e.g., reflection, verification tasks) and revise the response to the original task referring to the result of the auxiliary task. Talebirad and Nadiri (2023); Hong et al. (2023); Qian et al. (2023) assign characterize profiles (e.g., project manager, software engineer) to LLMs and gain performance boosts on character-specific tasks through behavior animations. Li et al. (2022); Zeng et al. (2022a); Chen et al. (2023a); Du et al. (2023); Liang et al. (2023) use a debate strategy in which multiple different LLMs propose their own responses to the given task and debate over multiple turns until getting a common final answer. Besides, Shen et al. (2023); Gao et al. (2023); Ge et al. (2023); Zhang et al. (2023c); Hao et al. (2023) employ one LLM as the task controller, which devises a plan for the given task, selects expert models for implementation and summarizes the responses of intermediate planned tasks. Other LLMs serve as task executors, completing intermediate tasks in their areas of expertise.
如有侵权请联系:admin#unsafe.sh