简析全球AI监管的现状、影响与未来展望
日期:2024年04月24日 阅:138

AI是一个经常与机器学习(ML)或大型语言模型(LLM)等术语混淆的宽泛术语。围绕着新兴AI技术及其影响的潜力和兴奋中,行业领导者、政府组织和企业正在讨论监管干预措施,例如《欧盟人工智能法案》、美国纽约州AI法(限制使用自动化就业决策工具)以及全球正在制定的其他30余项AI相关提案。目前亟需制定相关法规,解决生成的数据的使用、滥用和道德挑战。法规的实施将对教育、数据隐私、生命科学和研究等各个领域产生深远影响。
对AI影响力的分析揭示了强调法规、法案和法律影响的关键主题。分析目标是通过对比现状与预期的未来,从而评估对有影响力的法规的必要性,并提高对法规如何积极改善AI领域的普遍认识。
全球监管干预的类型
目前,我国、欧盟、英国和美国各自制定了监管要求,以应对不断变化的AI环境。最近,《欧盟人工智能法案》为风险管理框架的发展进一步奠定了基础。而中国采取了不同的方式,采纳了三种不同的监管措施,分别符合国家、地区和地方的观点,其中最新的深度合成规定于2023年正式生效。尽管其他国家也曾尝试制定和实施不同的监管规定,但许多国家并未能跟上ML和AI工具及算法发展的步伐。
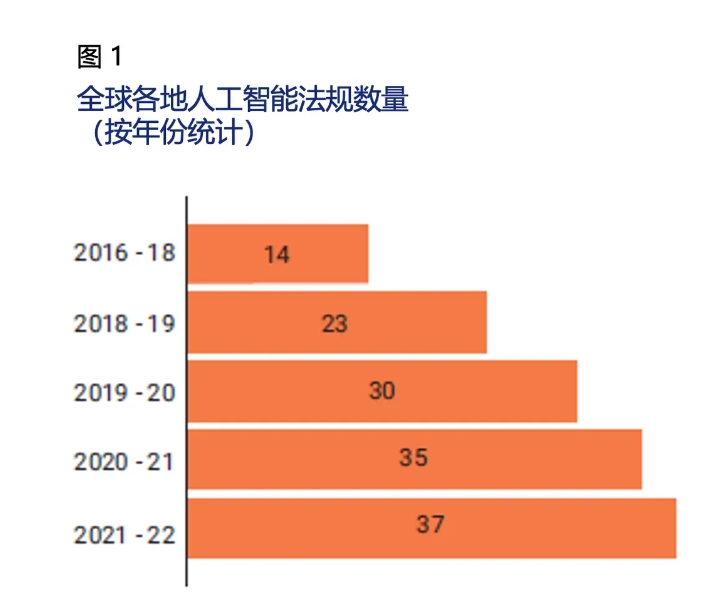
图1描绘了包含“人工智能”字样的法律法规年度增长情况。在过去几年中,127个国家的立法机构通过了37项涉及AI的法律,突显出AI在监管讨论中的重要性。
世界各国包括加拿大、中国、西班牙、英国和美国,已起草了针对AI相关的法案,颁布了AI法案或者通过了AI法规,以期解决在这一快速发展的知识领域中出现的道德问题(例如,数据偏差、特定地区或国家的数据来源)。其中一些地区采取行业方式监管AI(即专门针对数据隐私或特定内容),而其他地区,如中国和美国,在实施法律时侧重于多个领域(如透明度、偏见和数据保护)。从理解AI和ML模型及算法的工作原理开始,起草这些法规还有改进空间。
了解AI和ML模型
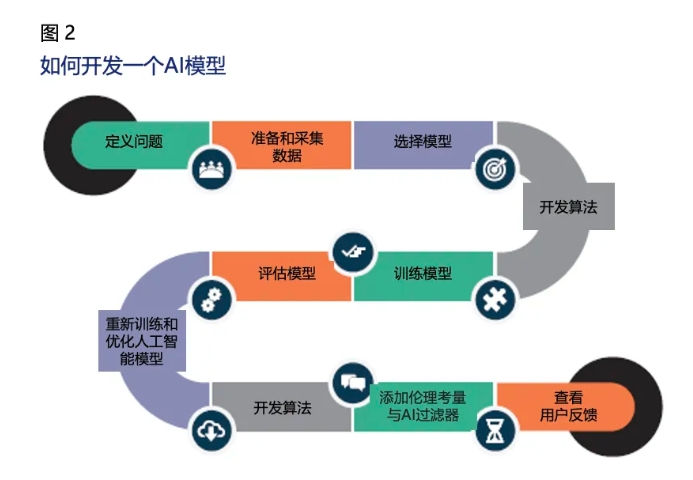
基于算法的AI和ML模型依赖于多种输入,其中主要输入是数据。数据用于已知的AI和ML模型生成训练数据集,以得出某一特定结果或效果。大多数模型解释数据,并就解决与特定问题相关的问题提供建议。图2描绘了开发AI模型的步骤。
深度神经网络、逻辑回归和线性回归、决策树、K近邻算法(k-Nearest Neighbor,KNN)、随机森林(Random Forest)和朴素贝叶斯(Naive Bayes)是当前流行的一些算法模型。这些模型通常按照它们可以在企业中或通过系统应用的位置进行分类。
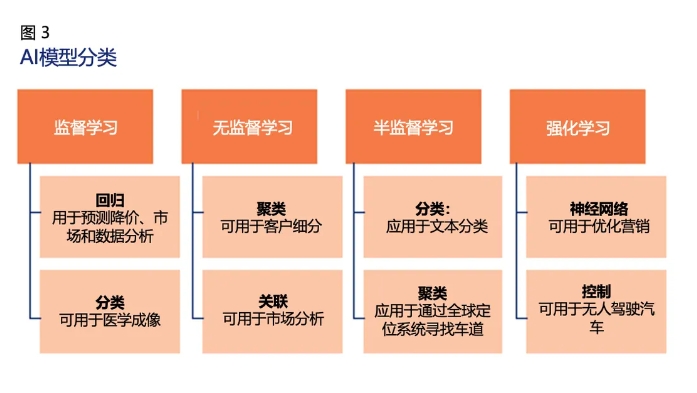
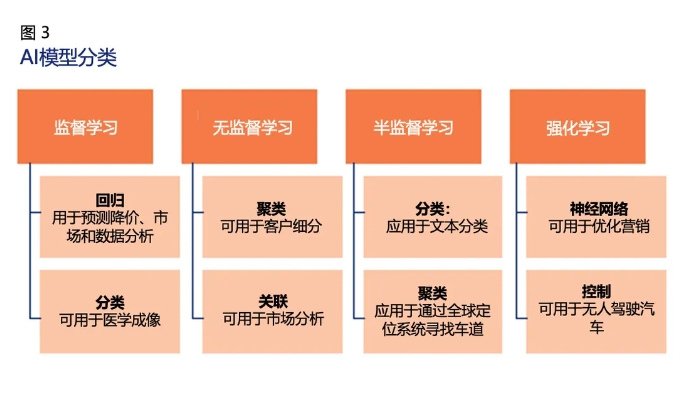
图3描绘了AI模型的分类及其应用领域。
任何基于AI的ML模型都可以通过支持ML数据集的统计方法学习。AI模型分为以下四类:
- 监督学习:涉及从有标签的数据集或经验收集的数据中学习。
- 半监督学习:涉及到两组数据——一组是有标签的数据,另一组是无标签的数据。
- 无监督学习:允许机器使用未标记的数据学习。
- 强化学习:基于一系列关于学习目标的积极或消极结果。
AI监管会带来哪些影响?
讨论与公平、真实性以及内容限制(这些是最主要的监管考量因素)相关的问题是政府的职责。许多现行的AI法案和法规对大型语言模型、生成式AI聊天机器人以及自然语言处理算法产生了深远的影响。全球范围内的IT专业人士和组织需要审视监管的当前和未来的影响,以了解哪些领域可能需要进一步的监管干预。
近期法规的影响
除了规定的指导原则和禁令之外,现行法规并未深入探究其实际影响(比如在涉及儿童时如何促进道德实践,或者如何对AI模型进行编程,以根据以人为中心的价值观做出决策)。欧盟旨在根据各类应用对公众造成的风险程度进行分类。中国AI法案建议通过设计一种监管型大型语言模型,增加或创建过滤机制(如审查算法并提供用户和儿童保护措施的管理系统),旨在删除无依据的、非专有的和不受欢迎的信息。这两种做法与美国法规制定形成鲜明对比,美国更常见的做法是,提出通过监管手段指导如何设计或使用AI的原则。
目前所有的监管干预措施都是由政府和监管机构实施的,他们有强烈的驱动力管理某些风险领域。这些领域是根据风险类型(由AI和ML产生)以及对监管所作出的具体响应的预期结果确定的。图4描绘了监管干预所管理的四个风险领域。
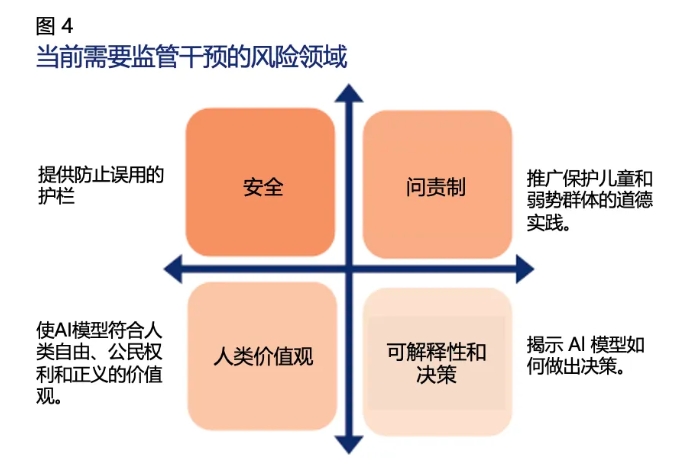
ML和AI法规及法案的最佳结果将符合人类价值观,防止不道德原则,并有能力说明是如何做出决策的。
AI法规的预期影响
在追求设立确保AI领域公平监管的过程中,存在隐性和显性两种期望的影响:
1. 非受控数据的影响——有必要保护数据的生成位置、目的、原始来源及其所有者/作者的引用。有些法规(如欧盟人工智能法案、中国AI相关规定)规定了这一需求,但其他法规没有规定。需要强制监管要求,以提供必要的保障。
2. 与道德和人类考量因素相关的影响和偏见——法规应强制组织审查其AI模型中现有算法中存在的偏差类型(例如,由未经验证的数据源驱动的以特定人群为中心的数据),并对此类算法进行改进。监管要求应当明确列出算法应避免的偏差类型(例如,以特定人群为中心的偏差、由未经验证的数据源驱动的偏差)。通过使用不同类型数据集训练算法,以防止产生偏差。
3. 易访问的隐私和敏感信息的影响——多部数据隐私法规已经解决了潜在的安全风险(例如欧盟人工智能法案、中国AI相关法规);然而,法规需要强制要求AI组织提供数据清理、数据清洗、和加密个人可识别信息(PII)的能力。
4. 对儿童教育的影响——监管机构和领先的AI组织需要共同努力设计儿童适宜的特定AI过滤模型,减轻偏见并激发儿童的好奇心,从而帮助他们从答案中学习,而不是像生成式AI简单地为问题提供简单的答案。
5. 对研究与创新的影响——AI模型可以根据研究论文的重点、领域、时间线及创新准备(即快速实现想法的能力),帮助从研究论文中提炼出有意义的见解。未来,AI模型可能能够通过按主题设计研发模型或根据现有的按主题研究生成创新模型的方式,弥合研究与创新之间的鸿沟。监管机构需要意识到AI的潜力,制定或更新监管法案和法规,以确保在数据和创新AI模型效果方面建立信任。
6. 对生命科学(包括药物研发)的影响——目前,有一些AI算法可以加快识别潜在药物成分,这些成分可能对于某些威胁生命的疾病的药物配方至关重要。还有一些模型能够模拟医生会诊,准确率接近70%-80%。监管机构的关键是通过定期对这些模型进行审计来实现信任和数据准确性。这一过程与法定审计或现场检查非常相似。
7. 对未来互联设备的影响——世界是复杂且相互连接的。智能手表数据(用于测量健康数据)可以位于与智能家居设备使用相同电子邮件地址共享的同一云服务上。由于数据、用户和设备之间不可避免的相互连接,监管机构必须开始将主要设备和辅助设备上的所有AI软件视为设备本身的扩展,并提供监管干预(通过监管AI模型或针对偏见和隐私问题的额外过滤器)。
AI监管的未来是什么?
为了确保当前和未来AI法规的有效性,亟待解决以下问题:
- 监管机构对AI模型的类型和应用的知识培训与意识提升;
- 根据风险考虑数据、算法和模型在世界各地的适用性;提供多层次的自我监管方法,不仅由监管机构推动,并且根据行业、公众和组织的反馈,不断实现反馈和改进;
- 建立监管机构联盟,这些机构共同探讨当前监管法律中存在的差距(如AI模型中的数据透明度和决策),并研讨如何在短期、中期和长期填补这些差距;
- 监管机构与行业团体就AI的影响进行持续和定期的协调,并共同探讨挑战与解决方案。政府、州或地方监管机构可能会与致力于开发和实施ML和AI工具的组织、企业和顾问会面,从而达成一致。
结论
对AI和ML的监管干预的未来似乎是一条漫长且曲折的道路。如果行业从业者和监管机构组建联盟或参与联合项目,持续监测并改进现有法规,将有助于明确确定和实施AI工具的护栏。
如有侵权请联系:admin#unsafe.sh