04/03/2024
9 min read

Data is fundamental to any real-world application: the database storing your user data and inventory, the analytics tracking sales events and/or error rates, the object storage with your web assets and/or the Parquet files driving your data science team, and the vector database enabling semantic search or AI-powered recommendations for your users.
When we first announced Workers back in 2017, and then Workers KV, Cloudflare R2, and D1, it was obvious that the next big challenge to solve for developers would be in making it easier to ingest, store, and query the data needed to build scalable, full-stack applications.
To that end, as part of our quest to make building stateful, distributed-by-default applications even easier, we’re launching our new Event Notifications service; a preview of our upcoming streaming ingestion product, Pipelines; and a sneak peek into our take on durable execution, Workflows.
Event-based architectures
When you’re writing data — whether that’s new data, changing existing data, or deleting old data — you often want to trigger other, asynchronous work to run in response. That could be processing user-driven uploads, updating search indexes as the underlying data changes, or removing associated rows in your SQL database when content is removed.
In order to make these event-driven workflows far easier to build across Cloudflare, we’re launching the first step towards a wider Event Notifications platform across Cloudflare, starting with notifications support in R2.
You can read more in the deep-dive on Event Notifications for R2, but in a nutshell: you can configure changes to content in any R2 bucket to write directly to a Queue, allowing you to reliably consume those events in a Worker or to pull from compute in a legacy cloud.
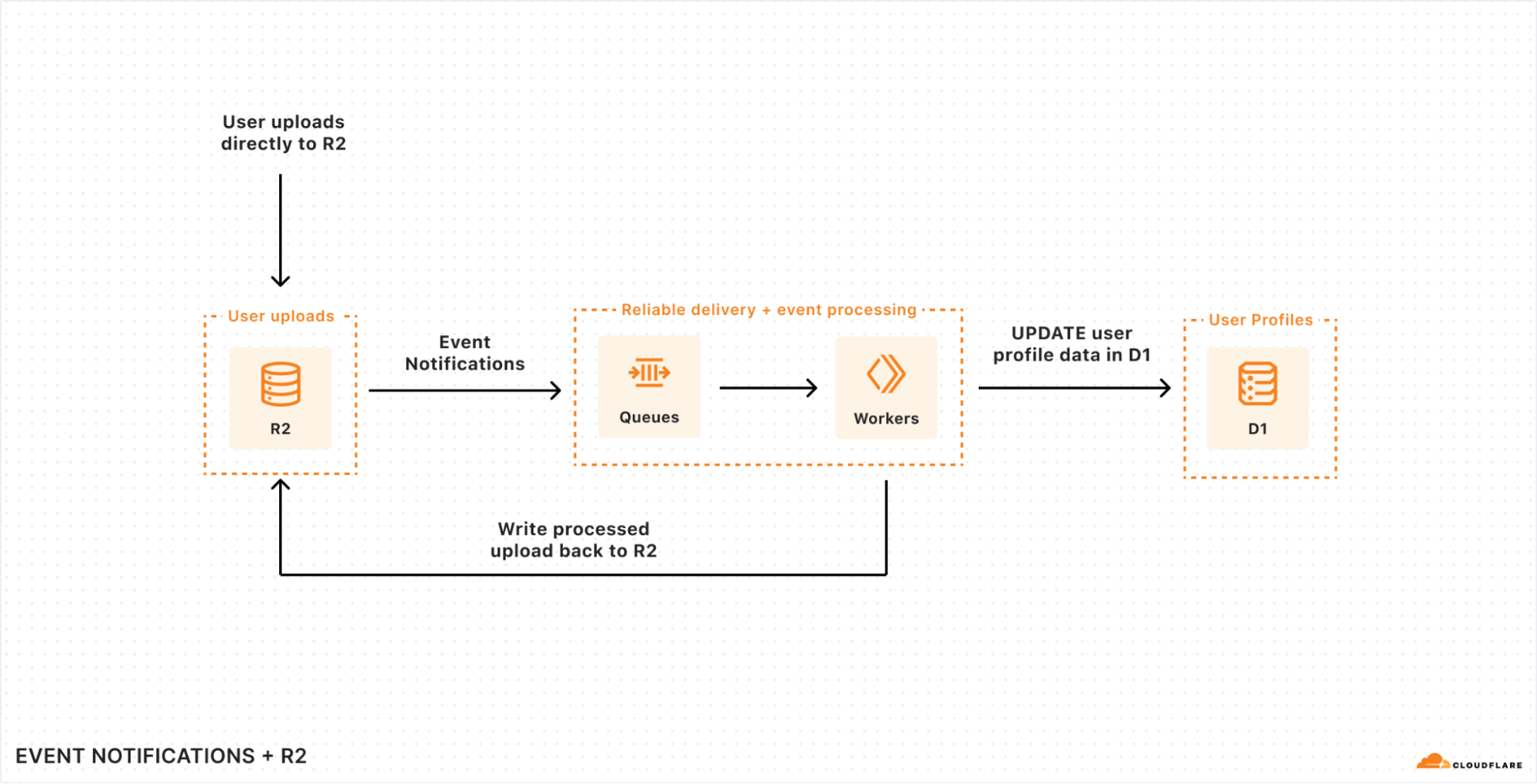
Event Notifications for R2 are just the beginning, though. There are many kinds of events you might want to trigger as a developer — these are just some of the event types we’re planning to support:
- Changes (writes) to key-value pairs in your Workers KV namespaces.
- Updates to your D1 databases, including changed rows or triggers.
- Deployments to your Cloudflare Workers
Consuming event notifications from a single Worker is just one approach, though. As you start to consume events, you may want to trigger multi-step workflows that execute reliably, resume from errors or exceptions, and ensure that previous steps aren’t duplicated or repeated unnecessarily. An event notification framework turns out to be just the thing needed to drive a workflow engine that executes durably…
Making it even easier to ingest data
When we launched Cloudflare R2, our object storage service, we knew that supporting the de facto-standard S3 API was critical in order to allow developers to bring the tooling and services they already had over to R2. But the S3 API is designed to be simple: at its core, it provides APIs for upload, download, multipart and metadata operations, and many tools don’t support the S3 API.
What if you want to batch clickstream data from your web services so that it’s efficient (and cost-effective) to query by your analytics team? Or partition data by customer ID, merchant ID, or locale within a structured data format like JSON?
Well, we want to help solve this problem too, and so we’re announcing Pipelines, an upcoming streaming ingestion service designed to ingest data at scale, aggregate it, and write it directly to R2, without you having to manage infrastructure, partitions, runners, or worry about durability.
With Pipelines, creating a globally scalable ingestion endpoint that can ingest tens-of-thousands of events per second doesn’t require any code:
$ wrangler pipelines create clickstream-ingest-prod --batch-size="1MB" --batch-timeout-secs=120 --batch-on-json-key=".merchantId" --destination-bucket="prod-cs-data"
✅ Successfully created new pipeline "clickstream-ingest-prod"
📥 Created endpoints:
➡ HTTPS: https://d458dbe698b8eef41837f941d73bc5b3.pipelines.cloudflarestorage.com/clickstream-ingest-prod
➡ WebSocket: wss://d458dbe698b8eef41837f941d73bc5b3.pipelines.cloudflarestorage.com:8443/clickstream-ingest-prod
➡ Kafka: d458dbe698b8eef41837f941d73bc5b3.pipelines.cloudflarestorage.com:9092 (topic: clickstream-ingest-prod)
As you can see here, we’re already thinking about how to make Pipelines protocol-agnostic: write from a HTTP client, stream events over a WebSocket, and/or redirect your existing Kafka producer (and stop having to manage and scale Kafka) directly to Pipelines.
But that’s just the beginning of our vision here. Scalable ingestion and simple batching is one thing, but what about if you have more complex needs? Well, we have a massively scalable compute platform (Cloudflare Workers) that can help address this too.
The code below is just an initial exploration for how we’re thinking about an API for running transforms over streaming data. If you’re aware of projects like Apache Beam or Flink, this programming model might even look familiar:
export default {
// Pipeline handler is invoked when batch criteria are met
async pipeline(stream: StreamPipeline, env: Env, ctx: ExecutionContext): Promise<StreamingPipeline> {
// ...
return stream
// Type: transform(label: string, transformFunc: TransformFunction): Promise<StreamPipeline>
// Each transform has a label that is used in metrics to provide
// per-transform observability and debugging
.transform("human readable label", (events: Array<StreamEvent>) => {
return events.map((e) => ...)
})
.transform("another transform", (events: Array<StreamEvent>) => {
return events.map((e) => ...)
})
.writeToR2({
format: "json",
bucket: "MY_BUCKET_NAME",
prefix: somePrefix,
batchSize: "10MB"
})
}
}
Specifically:
- The Worker describes a pipeline of transformations (mapping, reducing, filtering) that operates over each subset of events (records)
- You can call out to other services — including D1 or KV — in order to synchronously or asynchronously hydrate data or lookup values during your stream processing
- We take care of scaling horizontally based on records-per-second and/or any concurrency settings you configure based on processing latency requirements.
We’ll be bringing Pipelines into open beta later in 2024, and it will initially launch with support for HTTP ingestion and R2 as a destination (sink), but we’re already thinking bigger.
We’ll be sharing more as Pipelines gets closer to release. In the meantime, you can register your interest and share your use-case, and we’ll reach out when Pipelines reaches open beta.
Durable Execution
If the term “Durable Execution” is new to you, don’t worry: the term comes from the desire to run applications that can resume execution from where they left off, even if the underlying host or compute fails (where the “durable” part comes from).
As we’ve continued to build out our data and AI platforms, we’ve been acutely aware that developers need ways to create reliable, repeatable workflows that operate over that data, turn unstructured data into structured data, trigger on fresh data (or periodically), and automatically retry, restart, and export metrics for each step along the way. The industry calls this Durable Execution: we’re just calling it Workflows.
What makes Workflows different from other takes on Durable Execution is that we provide the underlying compute as part of the platform. You don’t have to bring-your-own compute, or worry about scaling it or provisioning it in the right locations. Workflows runs on top of Cloudflare Workers – you write the workflow, and we take care of the rest.
Here’s an early example of writing a Workflow that generates text embeddings using Workers AI and stores them (ready to query) in Vectorize as new content is written to (or updated within) R2.
- Each Workflow run is triggered by an Event Notification consumed from a Queue, but could also be triggered by a HTTP request, another Worker, or even scheduled on a timer.
- Individual steps within the Workflow allow us to define individually retriable units of work: in this case, we’re reading the new objects from R2, creating text embeddings using Workers AI, and then inserting.
- State is durably persisted between steps: each step can emit state, and Workflows will automatically persist that so that any underlying failures, uncaught exceptions or network retries can resume execution from the last successful step.
- Every call to step() automatically emits metrics associated with the unique Workflow run, making it easier to debug within each step and/or break down your application into its smallest units of execution, without having to worry about observability.
Step-by-step, it looks like this:
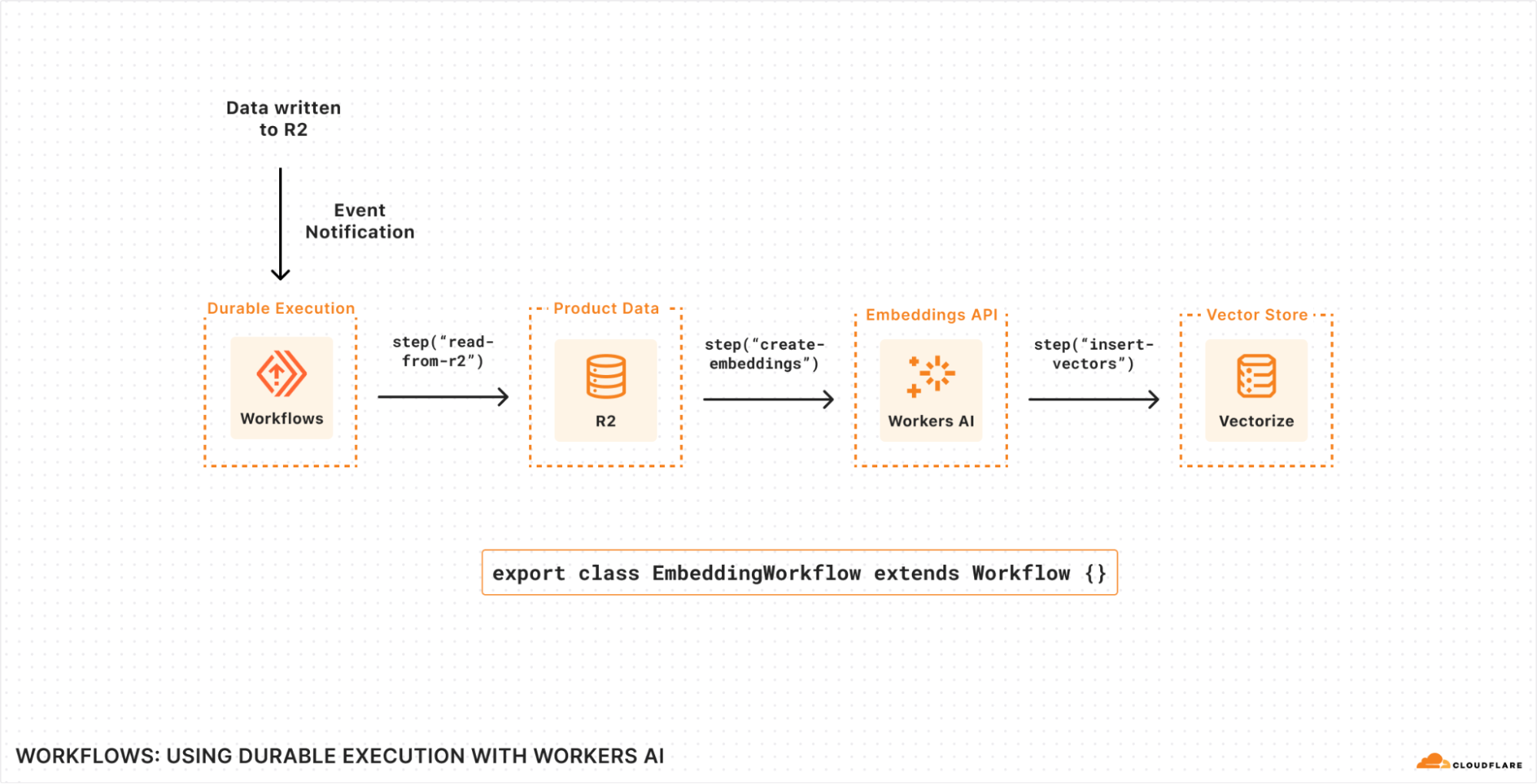
Transforming this series of steps into real code, here’s what this would look like with Workflows:
import { Ai } from "@cloudflare/ai";
import { Workflow } from "cloudflare:workers";
export interface Env {
R2: R2Bucket;
AI: any;
VECTOR_INDEX: VectorizeIndex;
}
export default class extends Workflow {
async run(event: Event) {
const ai = new Ai(this.env.AI);
// List of keys to fetch from our incoming event notification
const keysToFetch = event.messages.map((val) => {
return val.object.key;
});
// The return value of each step is stored (the "durable" part
// of "durable execution")
// This ensures that state can be persisted between steps, reducing
// the need to recompute results ($$, time) should subsequent
// steps fail.
const inputs = await this.ctx.run(
// Each step has a user-defined label
// Metrics are emitted as each step runs (to success or failure)
// with this label attached and available within per-Workflow
// analytics in near-real-time.
"read objects from R2", async () => {
const objects = [];
for (const key of keysToFetch) {
const object = await this.env.R2.get(key);
objects.push(await object.text());
}
return objects;
});
// Persist the output of this step.
const embeddings = await this.ctx.run(
"generate embeddings",
async () => {
const { data } = await ai.run("@cf/baai/bge-small-en-v1.5", {
text: inputs,
});
if (data.length) {
return data;
} else {
// Uncaught exceptions trigger an automatic retry of the step
// Retries and timeouts have sane defaults and can be overridden
// per step
throw new Error("Failed to generate embeddings");
}
},
{
retries: {
limit: 5,
delayMs: 1000,
backoff: "exponential",
},
}
);
await this.ctx.run("insert vectors", async () => {
const vectors = [];
keysToFetch.forEach((key, index) => {
vectors.push({
id: crypto.randomUUID(),
// Our embeddings from the previous step
values: embeddings[index].values,
// The path to each R2 object to map back to during
// vector search
metadata: { r2Path: key },
});
});
return this.env.VECTOR_INDEX.upsert();
});
}
}
This is just one example of what a Workflow can do. The ability to durably execute an application, modeled as a series of steps, applies to a wide number of domains. You can apply this model of execution to a number of use-cases, including:
- Deploying software: each step can define a build step and subsequent health check, gating further progress until your deployment meets your criteria for “healthy”.
- Post-processing user data: triggering a workflow based on user uploads (e.g. to Cloudflare R2) that then subsequently parses that data asynchronously, redacts PII or sensitive data, writes the sanitized output, and triggers a notification via email, webhook, or mobile push.
- Payment and batch workflows: aggregating raw customer usage data on a periodic schedule by querying your data warehouse (or Workers Analytics Engine), triggering usage or spend alerts, and/or generating PDF invoices.
Each of these use cases model tasks that you want to run to completion, minimize redundant retries by persisting intermediate state, and (importantly) easily observe success and failure.
We’ll be sharing more about Workflows during the second quarter of 2024 as we work towards an open (public!) beta. This includes how we’re thinking about idempotency and interactions with our storage, per-instance observability and metrics, local development, and templates to bootstrap common workflows.
Putting it together
We’ve often thought of Cloudflare’s own network as one massively scalable parallel data processing cluster: data centers in 310+ cities, with the ability to run compute close to users and/or close to data, keep it within the bounds of regulatory or compliance requirements, and most importantly, use our massive scale to enable our customers to scale as well.
Recapping, a fully-fledged data platform needs to enable three things:
- Ingesting data: getting data into the platform (in the right format, from the right sources)
- Storing data: securely, reliably, and durably.
- Querying data: understanding and extracting insights from the data, and/or transforming it for use by other tools.
When we launched R2 we tackled the second part, but knew that we’d need to follow up with the first and third parts in order to make it easier for developers to get data in and make use of it.
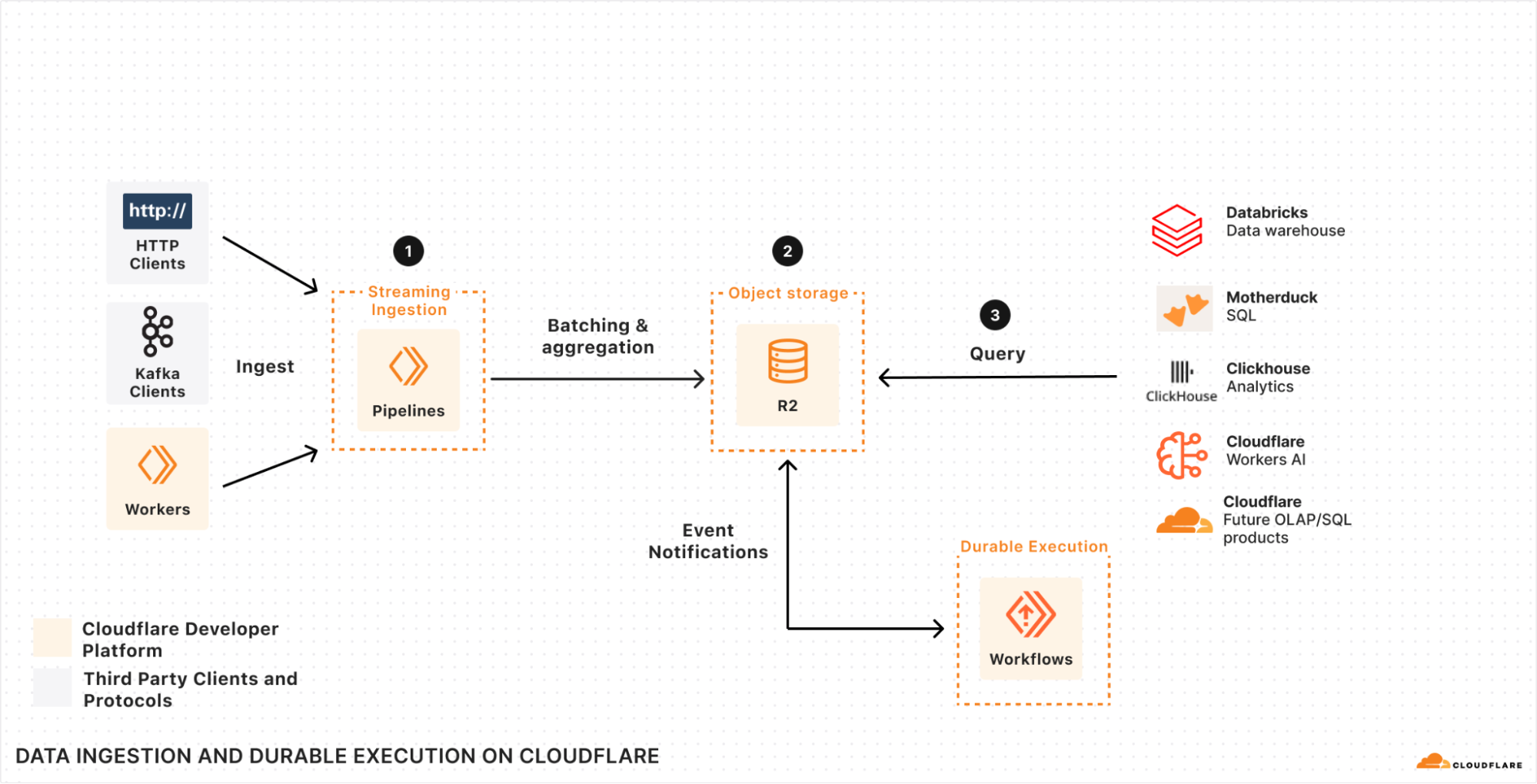
If we look at how we can build a system that helps us solve each of these three parts together with Pipelines, Event Notifications, R2, and Workflows, we end up with an architecture that resembles this:
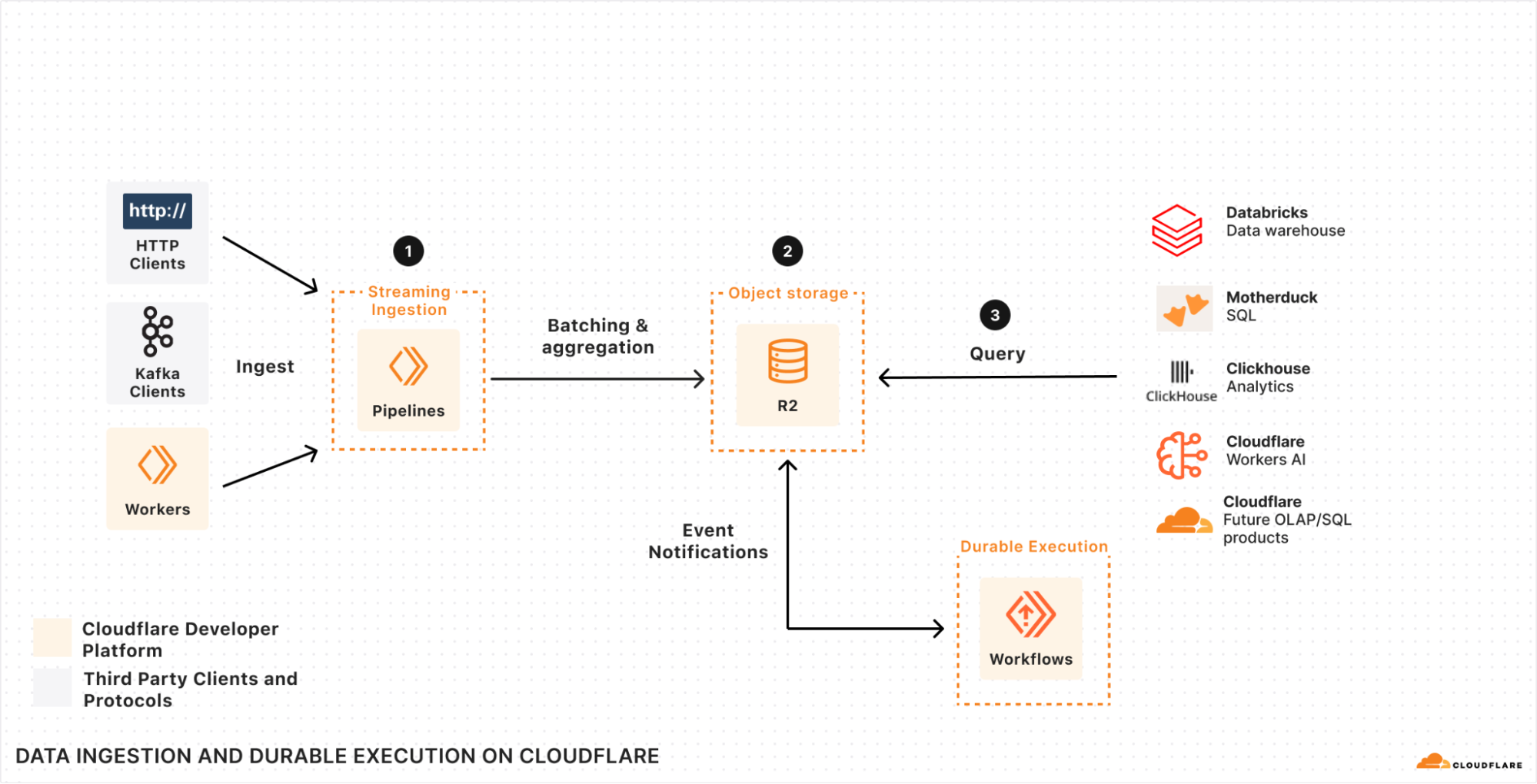
Specifically, we have Pipelines (1) scaling out to ingest data, batch it, filter it, and then durably store it in R2 (2) in a format that’s ready and optimized for querying. Workflows, ClickHouse, Databricks, or the query engine of your choice can then query (3) that data as soon as it’s ready — with “ready” being automatically triggered by an Event Notification as soon as the data is ingested and written to R2.
There’s no need to poll, no need to batch after the fact, no need to have your query engine slow down on data that wasn’t pre-aggregated or filtered, and no need to manage and scale infrastructure in order to keep up with load or data jurisdiction requirements. Create a Pipeline, write your data directly to R2, and query directly from it.
If you’re also looking at this and wondering about the costs of moving this data around, then we’re holding to one important principle: zero egress fees across all of our data products. Just as we set the stage for this with our R2 object storage, we intend to apply this to every data product we’re building, Pipelines included.
Start Building
We’ve shared a lot of what we’re building so that developers have an opportunity to provide feedback (including via our Developer Discord), share use-cases, and think about how to build their next application on Cloudflare.
We protect entire corporate networks, help customers build Internet-scale applications efficiently, accelerate any website or Internet application, ward off DDoS attacks, keep hackers at bay, and can help you on your journey to Zero Trust.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you're looking for a new career direction, check out our open positions.