
OverviewThis post discusses a use-after-free vulnerability, CVE-2024-0582, in io_ 2024-3-27 23:47:36 Author: blog.exodusintel.com(查看原文) 阅读量:31 收藏
Overview
This post discusses a use-after-free vulnerability, CVE-2024-0582, in io_uring in the Linux kernel. Despite the vulnerability being patched in the stable kernel in December 2023, it wasn’t ported to Ubuntu kernels for over two months, making it an easy 0day vector in Ubuntu during that time.
In early January 2024, a Project Zero issue for a recently fixed io_uring use-after-free (UAF) vulnerability (CVE-2024-0582) was made public. It was apparent that the vulnerability allowed an attacker to obtain read and write access to a number of previously freed pages. This seemed to be a very powerful primitive: usually a UAF gets you access to a freed kernel object, not a whole page – or even better, multiple pages. As the Project Zero issue also described, it was clear that this vulnerability should be easily exploitable: if an attacker has total access to free pages, once these pages are returned to a slab cache to be reused, they will be able to modify any contents of any object allocated within these pages. In the more common situation, the attacker can modify only a certain type of object, and possibly only at certain offsets or with certain values.
Moreover, this fact also suggests that a data-only exploit should be possible. In general terms, such an exploit does not rely on modifying the code execution flow, by building for instance a ROP chain or using similar techniques. Instead, it focuses on modifying certain data that ultimately grants the attacker root privileges, such as making read-only files writable by the attacker. This approach makes exploitation more reliable, stable, and allows bypassing some exploit mitigations such as Control-Flow Integrity (CFI), as the instructions executed by the kernel are not altered in any way.
Finally, according to the Project Zero issue, this vulnerability was present in the Linux kernel from versions starting at 6.4 and prior to 6.7. At that moment, Ubuntu 23.10 was running a vulnerable verison of 6.5 (and somewhat later so was Ubuntu 22.04 LTS), so it was a good opportunity to exploit the patch gap, understand how easy it would be for an attacker to do that, and how long they might possess an 0day exploit based on an Nday.
More precisely:
- The vulnerability was patched in stable release 6.6.5 on December 8, 2023.
- The Project Zero issue was made public one month later, January 8, 2024.
- The issue was patched in the Ubuntu kernel 6.5.0-21 which was released on February 22, 2024, for both Ubuntu 22.04 LTS Jammy and Ubuntu 23.10 Mantic .
This post describes the data-only exploit strategy that we implemented, allowing a non-privileged user (and without the need of unprivileged user namespaces) to achieve root privileges on affected systems. First, a general overview of the io_uring interface is given, as well as some more specific details of the interface relevant to this vulnerability. Next, an analysis of the vulnerability is provided. Finally, a strategy for a data-only exploit is presented.
Preliminaries
The io_uring interface is an asynchronous I/O API for Linux created by Jens Axboe and introduced in the Linux kernel version 5.1. Its goal is to improve performance of applications with a high number of I/O operations. It provides interfaces similar to functions like read() and write(), for example, but requests are satisfied in an asynchronous manner to avoid the context switching overhead caused by blocking system calls.
The io_uring interface has been a bountiful target for a lot of vulnerability research; it was disabled in ChromeOS, production Google servers, and restricted in Android. As such, there are many blog posts that explain it with a lot of detail. Some relevant references are the following:
- Put an io_uring on it – Exploiting the Linux Kernel, a writeup for an exploit targeting an
io_uringoperation that provides the same functionality (IORING_OP_PROVIDE_BUFFERS) as the vulnerability discussed here (IORING_REGISTER_PBUF_RING), and that has also a broad overview of this subsystem. - CVE-2022-29582 An io_uring vulnerability, where a cross-cache exploit is described. While the exploit described in our blog post is not strictly speaking cross-cache, there is some similarity between the two exploit strategies. It also provides an explanation of slab caches and the page allocator relevant to our exploit strategy.
- Escaping the Google kCTF Container with a Data-Only Exploit, where a different strategy for data-only exploit of an
io_uringvulnerability is described. - Conquering the memory through io_uring – Analysis of CVE-2023-2598, a writeup of a vulnerability that yields a very similar exploit primitive to ours. In this case, however, the exploit strategy relies on manipulating a structure associated with a socket, instead of manipulating file structures.
In the next subsections we give an overview of the io_uring interface. We pay special attention to the Provided Buffer Ring functionality, which is relevant to the vulnerability discussed in this post. The reader can also check “What is io_uring?”, as well as the above references for alternative overviews of this subsystem.
The io_uring Interface
The basis of io_uring is a set of two ring buffers used for communication between user and kernel space. These are:
- The submission queue (SQ), which contains submission queue entries (SQEs) describing a request for an I/O operation, such as reading or writing to a file, etc.
- The completion queue (CQ), which contains completion queue entries (CQEs) that correspond to SQEs that have been processed and completed.
This model allows executing a number of I/O requests to be performed asynchronously using a single system call, while in a synchronous manner each request would have typically corresponded to a single system call. This reduces the overhead caused by blocking system calls, thus improving performance. Moreover, the use of shared buffers also reduces the overhead as no data between user and kernelspace has to be transferred.
The io_uring API consists of three system calls:
io_uring_setup()io_uring_register()io_uring_enter()
The io_uring_setup() System Call
The io_uring_setup() system call sets up a context for an io_uring instance, that is, a submission and a completion queue with the indicated number of entries each one. Its prototype is the following:
int io_uring_setup(u32 entries, struct io_uring_params *p);
Its arguments are:
entries: It determines how many elements the SQ and CQ must have at the minimum.params: It can be used by the application to pass options to the kernel, and by the kernel to pass information to the application about the ring buffers.
On success, the return value of this system call is a file descriptor that can be later used to perform operation on the io_uring instance.
The io_uring_register() System Call
The io_uring_register() system call allows registering resources, such as user buffers, files, etc., for use in an io_uring instance. Registering such resources makes the kernel map them, avoiding future copies to and from userspace, thus improving performance. Its prototype is the following:
int io_uring_register(unsigned int fd, unsigned int opcode, void *arg, unsigned int nr_args);
Its arguments are:
fd: The fileio_uringfile descriptor returned by theio_uring_setup()system call.opcode: The specific operation to be executed. It can have certain values such asIORING_REGISTER_BUFFERS, to register user buffers, orIORING_UNREGISTER_BUFFERS, to release the previously registered buffers.arg: Arguments passed to the operation being executed. Their type depends on the specificopcodebeing passed.nr_args: Number of arguments inargbeing passed.
On success, the return value of this system call is either zero or a positive value, depending on the opcode used.
Provided Buffer Rings
An application might need to have different types of registered buffers for different I/O requests. Since kernel version 5.7, to facilitate managing these different sets of buffers, io_uring allows the application to register a pool of buffers that are identified by a group ID. This is done using the IORING_REGISTER_PBUF_RING opcode in the io_uring_register() system call.
More precisely, the application starts by allocating a set of buffers that it wants to register. Then, it makes the io_uring_register() system call with opcode IORING_REGISTER_PBUF_RING, specifying a group ID with which these buffers should be associated, a start address of the buffers, the length of each buffer, the number of buffers, and a starting buffer ID. This can be done for multiple sets of buffers, each one having a different group ID.
Finally, when submitting a request, the application can use the IOSQE_BUFFER_SELECT flag and provide the desired group ID to indicate that a provided buffer ring from the corresponding set should be used. When the operation has been completed, the buffer ID of the buffer used for the operation is passed to the application via the corresponding CQE.
Provided buffer rings can be unregistered via the io_uring_register() system call using the IORING_UNREGISTER_PBUF_RING opcode.
User-mapped Provided Buffer Rings
In addition to the buffers allocated by the application, since kernel version 6.4, io_uring allows a user to delegate the allocation of provided buffer rings to the kernel. This is done using the IOU_PBUF_RING_MMAP flag passed as an argument to io_uring_register(). In this case, the application does not need to previously allocate these buffers, and therefore the start address of the buffers does not have to be passed to the system call. Then, after io_uring_register() returns, the application can mmap() the buffers into userspace with the offset set as:
IORING_OFF_PBUF_RING | (bgid >> IORING_OFF_PBUF_SHIFT)
where bgid is the corresponding group ID. These offsets, as well as others used to mmap() the io_uring data, are defined in include/uapi/linux/io_uring.h:
/*
* Magic offsets for the application to mmap the data it needs
*/
#define IORING_OFF_SQ_RING 0ULL
#define IORING_OFF_CQ_RING 0x8000000ULL
#define IORING_OFF_SQES 0x10000000ULL
#define IORING_OFF_PBUF_RING 0x80000000ULL
#define IORING_OFF_PBUF_SHIFT 16
#define IORING_OFF_MMAP_MASK 0xf8000000ULL
The function that handles such an mmap() call is io_uring_mmap():
// Source: https://elixir.bootlin.com/linux/v6.5.3/source/io_uring/io_uring.c#L3439
static __cold int io_uring_mmap(struct file *file, struct vm_area_struct *vma)
{
size_t sz = vma->vm_end - vma->vm_start;
unsigned long pfn;
void *ptr;
ptr = io_uring_validate_mmap_request(file, vma->vm_pgoff, sz);
if (IS_ERR(ptr))
return PTR_ERR(ptr);
pfn = virt_to_phys(ptr) >> PAGE_SHIFT;
return remap_pfn_range(vma, vma->vm_start, pfn, sz, vma->vm_page_prot);
}
Note that remap_pfn_range() ultimately creates a mapping with the VM_PFNMAP flag set, which means that the MM subsystem will treat the base pages as raw page frame number mappings wihout an associated page structure. In particular, the core kernel will not keep reference counts of these pages, and keeping track of it is the responsability of the calling code (in this case, the io_uring subsystem).
The io_uring_enter() System Call
The io_uring_enter() system call is used to initiate and complete I/O using the SQ and CQ that have been previously set up via the io_uring_setup() system call. Its prototype is the following:
int io_uring_enter(unsigned int fd, unsigned int to_submit, unsigned int min_complete, unsigned int flags, sigset_t *sig);
Its arguments are:
fd: Theio_uringfile descriptor returned by theio_uring_setup()system call.to_submit: Specifies the number of I/Os to submit from the SQ.flags: A bitmask value that allows specifying certain options, such asIORING_ENTER_GETEVENTS,IORING_ENTER_SQ_WAKEUP,IORING_ENTER_SQ_WAIT, etc.sig: A pointer to a signal mask. If it is notNULL, the system call replaces the current signal mask by the one pointed to bysig, and when events become available in the CQ restores the original signal mask.
Vulnerability
The vulnerability can be triggered when an application registers a provided buffer ring with the IOU_PBUF_RING_MMAP flag. In this case, the kernel allocates the memory for the provided buffer ring, instead of it being done by the application. To access the buffers, the application has to mmap() them to get a virtual mapping. If the application later unregisters the provided buffer ring using the IORING_UNREGISTER_PBUF_RING opcode, the kernel frees this memory and returns it to the page allocator. However, it does not have any mechanism to check whether the memory has been previously unmapped in userspace. If this has not been done, the application has a valid memory mapping to freed pages that can be reallocated by the kernel for other purposes. From this point, reading or writing to these pages will trigger a use-after-free.
The following code blocks show the affected parts of functions relevant to this vulnerability. Code snippets are demarcated by reference markers denoted by [N]. Lines not relevant to this vulnerability are replaced by a [Truncated] marker. The code corresponds to the Linux kernel version 6.5.3, which corresponds to the version used in the Ubuntu kernel 6.5.0-15-generic.
Registering User-mapped Provided Buffer Rings
The handler of the IORING_REGISTER_PBUF_RING opcode for the io_uring_register() system call is the io_register_pbuf_ring() function, shown in the next listing.
// Source: https://elixir.bootlin.com/linux/v6.5.3/source/io_uring/kbuf.c#L537
int io_register_pbuf_ring(struct io_ring_ctx *ctx, void __user *arg)
{
struct io_uring_buf_reg reg;
struct io_buffer_list *bl, *free_bl = NULL;
int ret;
[1]
if (copy_from_user(&reg, arg, sizeof(reg)))
return -EFAULT;
[Truncated]
if (!is_power_of_2(reg.ring_entries))
return -EINVAL;
[2]
/* cannot disambiguate full vs empty due to head/tail size */
if (reg.ring_entries >= 65536)
return -EINVAL;
if (unlikely(reg.bgid io_bl)) {
int ret = io_init_bl_list(ctx);
if (ret)
return ret;
}
bl = io_buffer_get_list(ctx, reg.bgid);
if (bl) {
/* if mapped buffer ring OR classic exists, don't allow */
if (bl->is_mapped || !list_empty(&bl->buf_list))
return -EEXIST;
} else {
[3]
free_bl = bl = kzalloc(sizeof(*bl), GFP_KERNEL);
if (!bl)
return -ENOMEM;
}
[4]
if (!(reg.flags & IOU_PBUF_RING_MMAP))
ret = io_pin_pbuf_ring(&reg, bl);
else
ret = io_alloc_pbuf_ring(&reg, bl);
[Truncated]
return ret;
}
The function starts by copying the provided arguments into an io_uring_buf_reg structure reg [1]. Then, it checks that the desired number of entries is a power of two and is strictly less than 65536 [2]. Note that this implies that the maximum number of allowed entries is 32768.
Next, it checks whether a provided buffer list with the specified group ID reg.bgid exists and, in case it does not, an io_buffer_list structure is allocated and its address is stored in the variable bl [3]. Finally, if the provided arguments have the flag IOU_PBUF_RING_MMAP set, the io_alloc_pbuf_ring() function is called [4], passing in the address of the structure reg, which contains the arguments passed to the system call, and the pointer to the allocated buffer list structure bl.
// Source: https://elixir.bootlin.com/linux/v6.5.3/source/io_uring/kbuf.c#L519
static int io_alloc_pbuf_ring(struct io_uring_buf_reg *reg,
struct io_buffer_list *bl)
{
gfp_t gfp = GFP_KERNEL_ACCOUNT | __GFP_ZERO | __GFP_NOWARN | __GFP_COMP;
size_t ring_size;
void *ptr;
[5]
ring_size = reg->ring_entries * sizeof(struct io_uring_buf_ring);
[6]
ptr = (void *) __get_free_pages(gfp, get_order(ring_size));
if (!ptr)
return -ENOMEM;
[7]
bl->buf_ring = ptr;
bl->is_mapped = 1;
bl->is_mmap = 1;
return 0;
}
The io_alloc_pbuf_ring() function takes the number of ring entries specified in reg->ring_entries and computes the resulting size ring_size by multiplying it by the size of the io_uring_buf_ring structure [5], which is 16 bytes. Then, it requests a number of pages from the page allocator that can fit this size via a call to __get_free_pages() [6]. Note that for the maximum number of allowed ring entries, 32768, ring_size is 524288 and thus the maximum number of 4096-byte pages that can be retrieved is 128. The address of the first page is then stored in the io_buffer_list structure, more precisely in bl->buf_ring [7]. Also, bl->is_mapped and bl->is_mmap are set to 1.
Unregistering Provided Buffer Rings
The handler of the IORING_UNREGISTER_PBUF_RING opcode for the io_uring_register() system call is the io_unregister_pbuf_ring() function, shown in the next listing.
// Source: https://elixir.bootlin.com/linux/v6.5.3/source/io_uring/kbuf.c#L601
int io_unregister_pbuf_ring(struct io_ring_ctx *ctx, void __user *arg)
{
struct io_uring_buf_reg reg;
struct io_buffer_list *bl;
[8]
if (copy_from_user(&reg, arg, sizeof(reg)))
return -EFAULT;
if (reg.resv[0] || reg.resv[1] || reg.resv[2])
return -EINVAL;
if (reg.flags)
return -EINVAL;
[9]
bl = io_buffer_get_list(ctx, reg.bgid);
if (!bl)
return -ENOENT;
if (!bl->is_mapped)
return -EINVAL;
[10]
__io_remove_buffers(ctx, bl, -1U);
if (bl->bgid >= BGID_ARRAY) {
xa_erase(&ctx->io_bl_xa, bl->bgid);
kfree(bl);
}
return 0;
}
Again, the function starts by copying the provided arguments into a io_uring_buf_reg structure reg [8]. Then, it retrieves the provided buffer list corresponding to the group ID specified in reg.bgid and stores its address in the variable bl [9]. Finally, it passes bl to the function __io_remove_buffers() [10].
// Source: https://elixir.bootlin.com/linux/v6.5.3/source/io_uring/kbuf.c#L209
static int __io_remove_buffers(struct io_ring_ctx *ctx,
struct io_buffer_list *bl, unsigned nbufs)
{
unsigned i = 0;
/* shouldn't happen */
if (!nbufs)
return 0;
if (bl->is_mapped) {
i = bl->buf_ring->tail - bl->head;
if (bl->is_mmap) {
struct page *page;
[11]
page = virt_to_head_page(bl->buf_ring);
[12]
if (put_page_testzero(page))
free_compound_page(page);
bl->buf_ring = NULL;
bl->is_mmap = 0;
} else if (bl->buf_nr_pages) {
[Truncated]
In case the buffer list structure has the is_mapped and is_mmap flags set, which is the case when the buffer ring was registered with the IOU_PBUF_RING_MMAP flag [7], the function reaches [11]. Then, the page structure of the head page corresponding to the virtual address of the buffer ring bl->buf_ring is obtained. Finally, all the pages forming the compound page with head page are freed at [12], thus returning them to the page allocator.
Note that if the provided buffer ring is set up with IOU_PBUF_RING_MMAP, that is, it has been allocated by the kernel and not the application, the userspace application is expected to have previously mmap()ed this memory. Moreover, recall that since the memory mapping was created with the VM_PFNMAP flag, the reference count of the page structure was not modified during this operation. In other words, in the code above there is no way for the kernel to know whether the application has unmapped the memory before freeing it via the call to free_compound_page(). If this has not happened, a use-after-free can be triggered by the application by just reading or writing to this memory.
Exploitation
The exploitation mechanism presented in this post relies on how memory allocation works on Linux, so the reader is expected to have some familiarity with it. As a refresher, we highlight the following facts:
- The page allocator is in charge of managing memory pages, which are usually 4096 bytes. It keeps lists of free pages of order n, that is, memory chunks of page size multiplied by 2^n. These pages are served in a first-in-first-out basis.
- The slab allocator sits on top of the buddy allocator and keeps caches of commonly used objects (dedicated caches) or fixed-size objects (generic caches), called slab caches, available for allocation in the kernel. There are several implementations of slab allocators, but for the purpose of this post only the SLUB allocator, the default in modern versions of the kernel, is relevant.
- Slab caches are formed by multiple slabs, which are sets of one or more contiguous pages of memory. When a slab cache runs out of free slabs, which can happen if a large number of objects of the same type or size are allocated and not freed during a period of time, the operating system allocates a new slab by requesting free pages to the page allocator.
One of such cache slabs is the filp, which contains file structures. A filestructure, shown in the next listing, represents an open file.
// Source: https://elixir.bootlin.com/linux/v6.5.3/source/include/linux/fs.h#L961
struct file {
union {
struct llist_node f_llist;
struct rcu_head f_rcuhead;
unsigned int f_iocb_flags;
};
/*
* Protects f_ep, f_flags.
* Must not be taken from IRQ context.
*/
spinlock_t f_lock;
fmode_t f_mode;
atomic_long_t f_count;
struct mutex f_pos_lock;
loff_t f_pos;
unsigned int f_flags;
struct fown_struct f_owner;
const struct cred *f_cred;
struct file_ra_state f_ra;
struct path f_path;
struct inode *f_inode; /* cached value */
const struct file_operations *f_op;
u64 f_version;
#ifdef CONFIG_SECURITY
void *f_security;
#endif
/* needed for tty driver, and maybe others */
void *private_data;
#ifdef CONFIG_EPOLL
/* Used by fs/eventpoll.c to link all the hooks to this file */
struct hlist_head *f_ep;
#endif /* #ifdef CONFIG_EPOLL */
struct address_space *f_mapping;
errseq_t f_wb_err;
errseq_t f_sb_err; /* for syncfs */
} __randomize_layout
__attribute__((aligned(4))); /* lest something weird decides that 2 is OK */
The most relevant fields for this exploit are the following:
f_mode: Determines whether the file is readable or writable.f_pos: Determines the current reading or writing position.f_op: The operations associated with the file. It determines the functions to be executed when certain system calls such asread(),write(), etc., are issued on the file. For files inext4filesystems, this is equal to theext4_file_operationsvariable.
Strategy for a Data-Only Exploit
The exploit primitive provides an attacker with read and write access to a certain number of free pages that have been returned to the page allocator. By opening a file a large number of times, the attacker can force the exhaustion of all the slabs in the filp cache, so that free pages are requested to the page allocator to create a new slab in this cache. In this case, further allocations of file structures will happen in the pages on which the attacker has read and write access, thus being able to modify them. In particular, for example, by modifying the f_mode field, the attacker can make a file that has been opened with read-only permissions to be writable.
This strategy was implemented to successfully exploit the following versions of Ubuntu:
- Ubuntu 22.04 Jammy Jellyfish LTS with kernel
6.5.0-15-generic. - Ubuntu 22.04 Jammy Jellyfish LTS with kernel
6.5.0-17-generic. - Ubuntu 23.10 Mantic Minotaur with kernel
6.5.0-15-generic. - Ubuntu 23.10 Mantic Minotaur with kernel
6.5.0-17-generic.
The next subsections give more details on how this strategy can be carried out.
Triggering the Vulnerability
The strategy begins by triggering the vulnerability to obtain read and write access to freed pages. This can be done by executing the following steps:
- Making an
io_uring_setup()system call to set up theio_uringinstance. - Making an
io_uring_register()system call with opcodeIORING_REGISTER_PBUF_RINGand theIOU_PBUF_RING_MMAPflag, so that the kernel itself allocates the memory for the provided buffer ring.
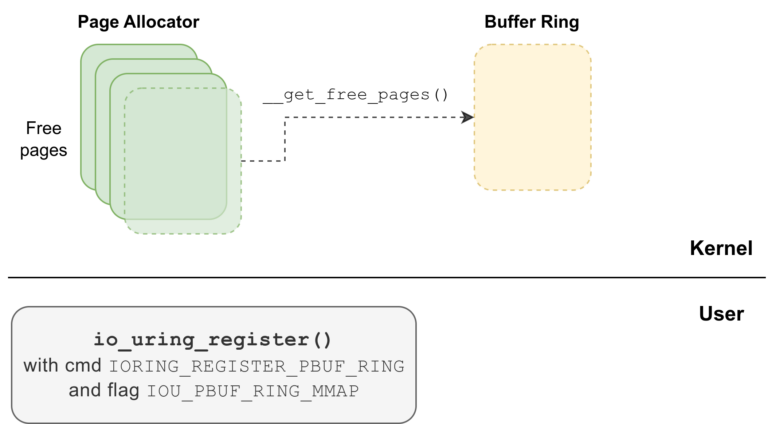
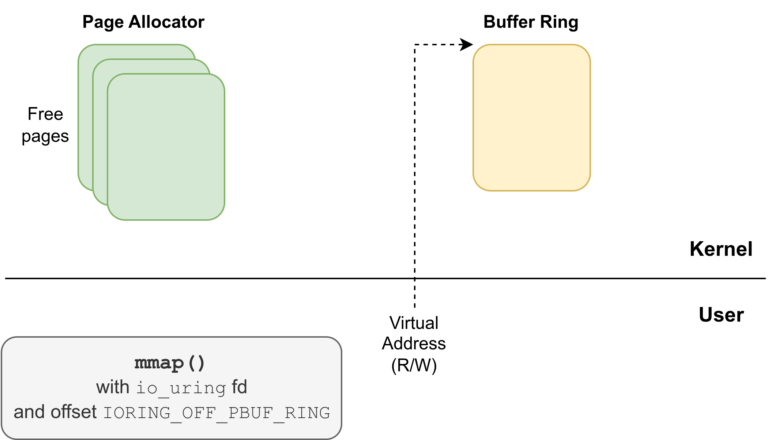
mmap()ing the memory of the provided buffer ring with read and write permissions, using theio_uringfile descriptor and the offsetIORING_OFF_PBUF_RING.
- Unregistering the provided buffer ring by making an
io_uring_register()system call with opcodeIORING_UNREGISTER_PBUF_RING.
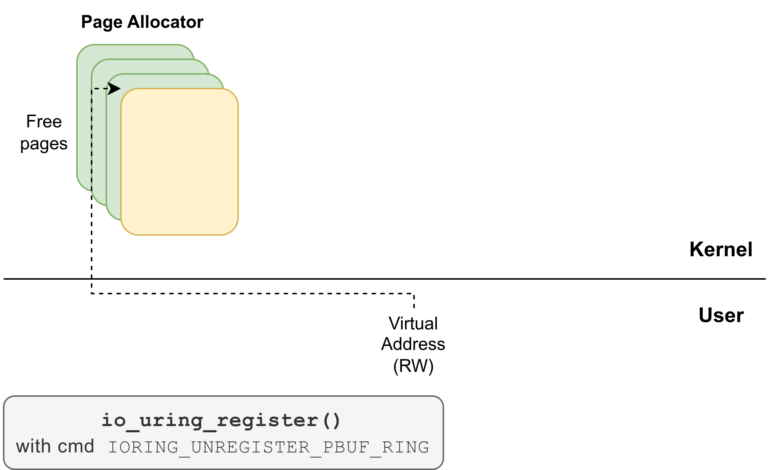
At this point, the pages corresponding to the provided buffer ring have been returned to the page allocator, while the attacker still has a valid reference to them.
Spraying File Structures
The next step is spawning a large number of child processes, each one opening the file /etc/passwd many times with read-only permissions. This forces the allocation of corresponding file structures in the kernel.
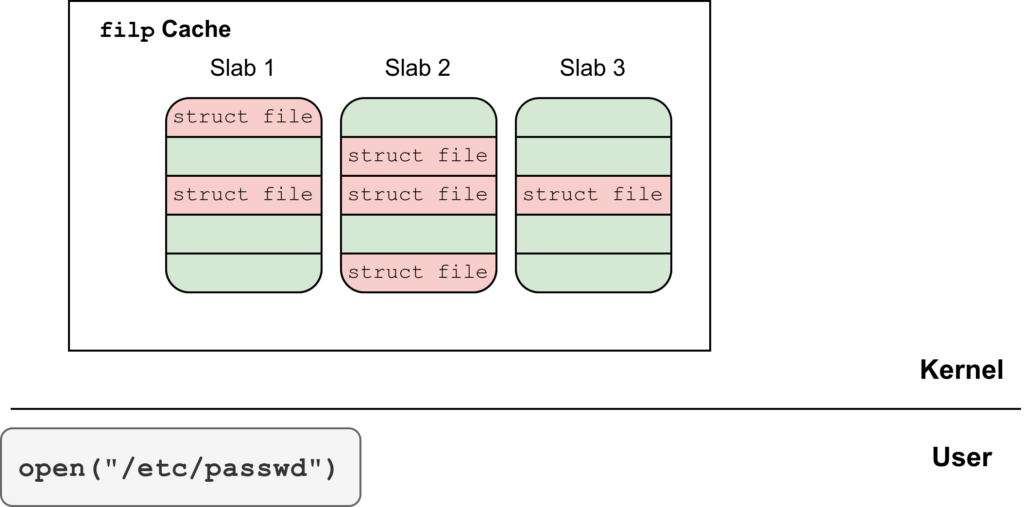
By opening a large number of files, the attacker can force the exhaustion of the slabs in the filp cache. After that, new slabs will be allocated by requesting free pages from the page allocator. At some point, the pages that previously corresponded to the provided buffer ring, and to which the attacker still has read and write access, will be returned by the page allocator.
Hence, all of the file structures created after this point will be allocated in the attacker-controlled memory region, giving them the possibility to modify the structures.
Note that these child processes have to wait until indicated to proceed in the last stage of the exploit, so that the files are kept open and their corresponding structures are not freed.
Locating a File Structure in Memory
Although the attacker may have access to some slabs belonging to the filp cache, they don’t know where they are within the memory region. To identify these slabs, however, the attacker can search for the ext4_file_operations address at the offset of the file.f_op field within the file structure. When one is found, it can be safely assumed that it corresponds to the file structure of one instance of the previously opened /etc/passwd file.
Note that even when Kernel Address Space Layout Randomization (KASLR) is enabled, to identify the ext4_file_operations address in memory it is only necessary to know the offset of this symbol with respect to the _text symbol, so there is no need for a KASLR bypass. Indeed, given a value val of an unsigned integer found in memory at the corresponding offset, one can safely assume that it is the address of ext4_file_operations if:
(val >> 32 & 0xffffffff) == 0xffffffff, i.e. the 32 most significant bits are all 1.(val & 0xfffff) == (ext4_fops_offset & 0xfffff), i.e. the 20 least significant bits ofvalandext4_fops_offset, the offset ofext4_file_operationswith respect to_text, are the same.
Changing File Permissions and Adding a Backdoor Account
Once a file structure corresponding to the /etc/passwd file is located in the memory region accessible by the attacker, it can be modified at will. In particular, setting the FMODE_WRITE and FMODE_CAN_WRITE flags in the file.f_mode field of the found structure will make the /etc/passwd file writable when using the corresponding file descriptor.
Moreover, setting the file.f_pos field of the found file structure to the current size of the /etc/passwd/ file, the attacker can ensure that any data written to it is appended at the end of the file.
To finish, the attacker can signal all the child processes spawned in the second stage to try to write to the opened /etc/passwd file. While most of all of such attempts will fail, as the file was opened with read-only permissions, the one corresponding to the modified file structure, which has write permissions enabled due to the modification of the file->f_mode field, will succeed.
Conclusion
To sum up, in this post we described a use-after-free vulnerability that was recently disclosed in the io_uring subsystem of the Linux kernel, and a data-only exploit strategy was presented. This strategy proved to be realitvely simple to implement. During our tests it proved to be very reliable and, when it failed, it did not affect the stability of the system. This strategy allowed us to exploit up-to-date versions of Ubuntu during the patch gap window of about two months.
About Exodus Intelligence
Our world class team of vulnerability researchers discover hundreds of exclusive Zero-Day vulnerabilities, providing our clients with proprietary knowledge before the adversaries find them. We also conduct N-Day research, where we select critical N-Day vulnerabilities and complete research to prove whether these vulnerabilities are truly exploitable in the wild.
For more information on our products and how we can help your vulnerability efforts, visit www.exodusintel.com or contact [email protected] for further discussion.
如有侵权请联系:admin#unsafe.sh