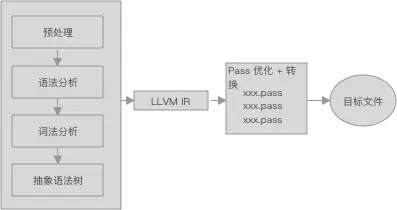
简单来说llvm就是一个编译架构项目,它是一个模块化可重用的编译器及工具链技术的集合
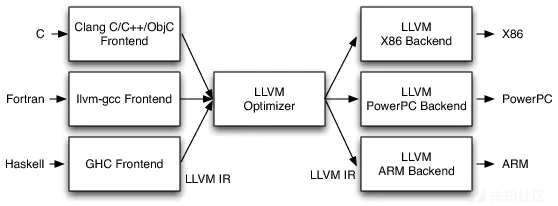
编译器一般采用三段式的设计,LLVM,GCC, JIT(Java, Python) 等编译器都遵循经典的三段式设计

- 前端 (Frontend) :进行词法分析,语法分析, 生成抽象语法树,生成中间语言 (例如 java 的字节码,llvm 的 IR,GCC 的 GIMPLE Tuples)
- 优化器 (Optimizer) :分析中间语言,避免多余的计算,提高性能;
- 后端 (Backend): 根据中间语言,生成对应的 CPU 架构指令 例如 X86,ARM;
通过这种设计,增加新的语言,只需要实现新的前段,优化器 和 后端可以重用;同理新增新的 CPU 架构时,也只需要实现新的后端。

其整体架构如下:
llvm特点:
- 模块化
- 统一的中间代码IR,而前端、后端可以不一样。而GCC的前端、后端耦合在了一起,所以支持一门新语言或者新的平台,非常困难。
- 功能强大的Pass系统,根据依赖性自动对Pass(包括分析、转换和代码生成Pass)进行排序,管道化以提高效率。
llvm有广义和狭义两种定义
在广义中,llvm特指一整个编译器框架,由前端、优化器、后端组成,clang只是用于c/c++的一种前端,llvm针对不同的语言可以设计不同的前端,同样的针对不同的平台架构(amd,arm,misp),也会有不同后端设计
在狭义中 ,特指llvm后端,指优化器(pass)对IR进行一系列优化直到目标代码生成的过程
LLVM的主要子项目
| 项目名称 | 描述 |
|---|---|
| LLVM Core | 包含一个源代码和目标架构无关的独立配置器,一个针对很多主流(甚至于一些非主流)的CPU的汇编代码生成支持。这些核心库围绕IR来构建。 |
| Clang | 一个C/C++/Objective-C编译器,提供高效快速的编译效率,风格良好、极其有用的错误和警告信息。 |
| LLDB | 基于LLVM提供的库和Clang构建的优秀的本地调试器。原生支持调试多线程程序。 |
| LLD | clang/llvm内置的链接器 |
| dragonegg | gcc插件,可将GCC的优化和代码生成器替换为LLVM的相应工具。 |
| libc++, libc++ ABI | 符合标准的,高性能的C++标准库实现,以及对C++11的完整支持。 |
| compiler-rt | 为动态测试工具(如AddressSanitizer,ThreadSanitizer,MemorySanitizer和DataFlowSanitizer)提供了运行时库的实现。为像“__fixunsdfdi”这样的低级代码生成器支持进程提供高层面的调整实现,也提供当目标没有用于实现核心IR操作的短序列本机指令时生成的其他调用。 |
| OpenMP | 提供一个OpenMP运行时,用于Clang中的OpenMP实现。 |
| vmkit | 基于LLVM的Java和.NET虚拟机实现。 |
| polly | 支持高级别的循环和数据本地化优化支持的LLVM框架,使用多面体模型实现一组缓存局部优化以及自动并行和矢量化。 |
| libclc | OpenCL(开放运算语言)标准库的实现. |
| klee | 基于LLVM编译基础设施的符号化虚拟机。它使用一个定理证明器来尝试评估程序中的所有动态路径,以发现错误并证明函数的属性。 klee的一个主要特性是它可以在检测到错误时生成测试用例。 |
| SAFECode | 用于C / C ++程序的内存安全编译器。 它通过运行时检查来检测代码,以便在运行时检测内存安全错误(例如,缓冲区溢出)。 它可用于保护软件免受安全攻击,也可用作Valgrind等内存安全错误调试工具 |
我这里的环境是Ubuntu1604,采用cmake的方式进行编译,首先要安装以下:
sudo apt-get install subversion sudo apt-get install cmake
去官网下载lvm、clang、 clang-tools-extra 、 compiler-rt 、 libcxx 、 libcxxabi ,我这里统一下载8.0.0版本
一系列安装编译命令如下,整理成shell脚本方便一把梭
#!/usr/bin/env bash cd ~ && mkdir LLVM && cd LLVM wget http://releases.llvm.org/8.0.0/llvm-8.0.0.src.tar.xz tar -xf llvm-8.0.0.src.tar.xz && rm llvm-8.0.0.src.tar.xz mv ./llvm-8.0.0.src ./llvm-8.0.0 cd llvm-8.0.0/tools/ wget http://releases.llvm.org/8.0.0/cfe-8.0.0.src.tar.xz tar -xf ./cfe-8.0.0.src.tar.xz && rm ./cfe-8.0.0.src.tar.xz mv ./cfe-8.0.0.src ./clang cd ./clang/tools wget http://releases.llvm.org/8.0.0/clang-tools-extra-8.0.0.src.tar.xz tar -xf ./clang-tools-extra-8.0.0.src.tar.xz && rm ./clang-tools-extra-8.0.0.src.tar.xz mv ./clang-tools-extra-8.0.0.src ./clang-tools-extra cd ../../../projects/ wget http://releases.llvm.org/8.0.0/compiler-rt-8.0.0.src.tar.xz wget http://releases.llvm.org/8.0.0/libcxx-8.0.0.src.tar.xz wget http://releases.llvm.org/8.0.0/libcxxabi-8.0.0.src.tar.xz tar -xf ./compiler-rt-8.0.0.src.tar.xz && rm ./compiler-rt-8.0.0.src.tar.xz tar -xf libcxx-8.0.0.src.tar.xz && rm libcxx-8.0.0.src.tar.xz tar -xf libcxxabi-8.0.0.src.tar.xz && rm libcxxabi-8.0.0.src.tar.xz mv compiler-rt-8.0.0.src ./compiler-rt mv libcxx-8.0.0.src ./libcxx mv libcxxabi-8.0.0.src ./libcxxabi cd ../../ && mkdir build && cd build cmake -G "Unix Makefiles" -DCMAKE_BUILD_TYPE=Release ../llvm-8.0.0 make -j4 sudo make install
make -j4这里的-j4参数表示同时使用4个核心的cpu进行编译,可根据不同机器调整,这里用wget从官网下载速度挺慢的,可以用下载器下载好在放入相应的目录中
整个过程持续一个小时,编译完成后LLVM文件夹足足有3.3G,最后尝试./bulid/bin/clang++ -v
如图所示,说明编译安装成功
这时clang也可以直接使用了,为了测试一下clang,可以用clang再编译一次llvm
同样在build目录下执行:
CC=clang CXX=clang++ cmake -G "Unix Makefiles" -DCMAKE_BUILD_TYPE=Release ../llvm-8.0.0
make -j4
sudo make install
可以发现clang的编译速度简直完虐gcc。。。速度快太多了
基本使用
#include <iostream> using namespace std; int main() { cout << "Hello, world!" << endl; return 0;; }
编译c++,使用c++11的标准和libc++库
clang++ -std=c++11 -stdlib=libc++ test.cpp
检验x.cpp的语法正确性
clang test.cpp -fsyntax-only
clang -S和-c的参数作用
-c : Only run preprocess, compile, and assemble steps,表示仅进行预处理和编译部分步骤,输出一个重定位elf,但无法运行,执行clang++ -std=c++11 -stdlib=libc++ ./test1.cpp -S -o test,结果如图:
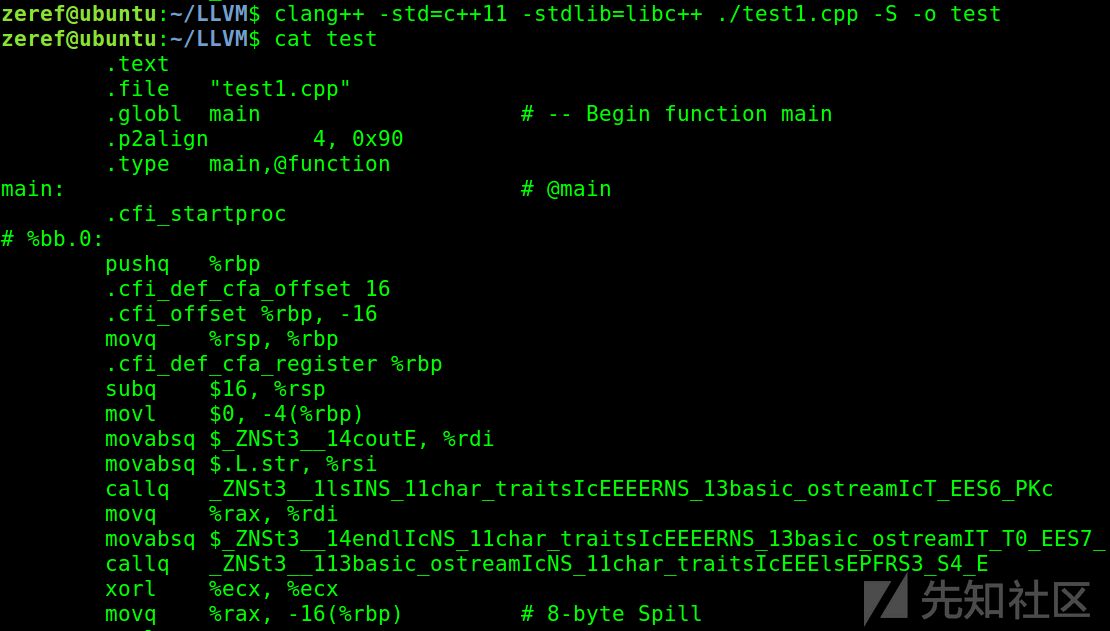
-S Only run preprocess and compilation steps,表示只进行预处理和编译部分步骤,输出一个可读汇编文本
输出x.cpp未优化的LLVM代码,执行clang++ -std=c++11 -stdlib=libc++ ./test1.cpp -c -o test,结果如图

clang++ -std=c++11 -stdlib=libc++ test.cpp -S -emit-llvm -o test
-emit-llvm :Use the LLVM representation for assembler and object files,表示使用llvm的ir中间语言的表示方法描述汇编和目标文件

输出x.cpp经过O3级别优化的LLVM IR中间代码
clang++ -std=c++11 -stdlib=libc++ test.cpp -S -emit-llvm -o test -O3
clang编译过程
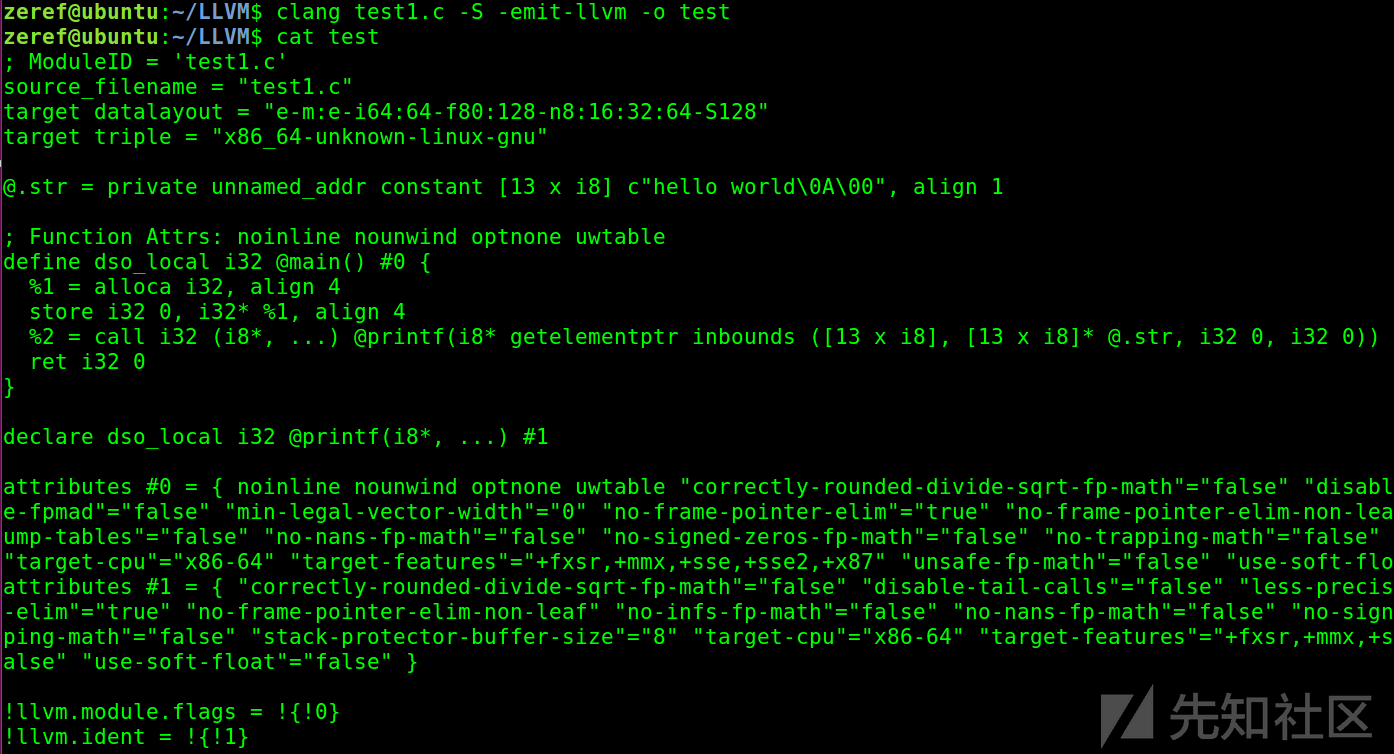
#include <stdio.h> int main() { printf("hello world\n"); return 0; } //test1.c
查看各个阶段:
clang -ccc-print-phases test1.c

查看预处理过程,主要作用是 将#include, @import,#import引入,引入头文件内容,宏定义的代码替换,条件编译(#ifdef),删除注释等。
clang -E test1.c

词法分析,生成Token,将代码分解,生成一个个 Token。Token是代码的最小单元, Token类型包括:关键字,标识符,字面量,特殊符号。
clang -fmodules -E -Xclang -dump-tokens test1.c

验证语法正确性,将所有Token组成AST抽象语法树
clang -fmodules -fsyntax-only -Xclang -ast-dump test1.c

TranslationUnitDecl 根节点,表示一个编译单元
节点主要有三种:Type类型,Decl声明,Stmt陈述
ObjCInterfaceDecl OC中Interface声明
FunctionDecl 函数声明
ParmVarDecl 参数声明
CompoundStmt 具体语句
DeclStmt 语句声明
VarDecl 变量声明
IntegerLiteral 整数字面量
BinaryOperator 操作符
ImplicitCastExpr 隐式转换
DeclRefExpr 引用类型声明
ReturnStmt 返回语句
使用clang的API可针对AST进行相应的分析及处理。
IR,即 Intermediate language ,有两种表示样式:
文本格式
便于阅读的文本格式,类似于汇编格式,后缀为.ll
也就是上面所说的clang test1.c -S -emit-llvm -o test
生成的test严格意义上是.ll后缀的文本格式,只不过-o的时候没有指定.ll后缀

二进制格式
不可读,后缀为.bc,可以使用使用llvm-dis工具可将其转化为.ll文件
生成命令:clang test1.c -c -emit-llvm -o test.bc

相互转换:
.bc转换为 .ll llvm-dis test.bc
.ll 或者 .bc 转换为汇编文件:llc ./test.ll -o test.s
这里有一张图很好描述了相关后缀文件之间的转换关系:

IR语法
IR是基于寄存器的指令集,只能通过load和store指令来进行CPU和内存间的数据交换。
IR关键字意义:
- ; 注释,以;开头直到换行符
- define 函数定义
- declare 函数声明
- i32 所占bit位为32位
- ret 函数返回
- alloca 在当前执行的函数的栈空间分配内存,当函数返回时,自动释放内存
- align 内存对齐
- load 读取数据
- store 写入数据
- icmp 整数值比较,返回布尔值结果
- br 选择分支,根据cond来转向label
- label 代码标签
- %0,%1分别为函数参数
LLVM IR 标识符有两种基本类型:
- 全局标识符(函数,全局变量)以’@’字符开头
- 本地标识符(寄存器名称,类型)以’%’字符开头
以一个变量%x乘以8为例子,可以有三种IR汇编写法
#乘法运算
%result = mul i32 %X, 8
#左移运算
%result = shl i32 %X, 3
#三次加法运算
%0 = add i32 %X, %X ; yields {i32}:%0
%1 = add i32 %0, %0 ; yields {i32}:%1
%result = add i32 %1, %1到这里其实IR的语法格式大体上并不难理解,还是标准的三元格式: 操作符+操作数1+操作数2
只不过多了一些赋值和数据类型等花里胡哨的东西
LLVM程序由Module组成,每个程序模块都是输入程序的翻译单元。每个模块由函数,全局变量和符号表条目组成。模块可以与LLVM链接器组合在一起,LLVM链接器合并函数(和全局变量)定义,解析前向声明,并合并符号表条目
例子
#include <stdio.h> #define MONEY 0x200; int main() { //hello world! char name[0x10]={0}; int age=0x20; int money=age+0x100+MONEY; printf("hello!\ninput your name:"); read(0,name,0x10); puts(name); return 0; } void test(int a, int b) { int c =a+b+0x666; }
如上所示源码转换成IR后,main函数如下
; Function Attrs: argmemonly nounwind declare void @llvm.memset.p0i8.i64(i8* nocapture writeonly, i8, i64, i1) #1 declare dso_local i32 @printf(i8*, ...) #2 declare dso_local i32 @read(...) #2 declare dso_local i32 @puts(i8*) #2 @.str = private unnamed_addr constant [24 x i8] c"hello!\0Ainput your name:\00", align 1 ; Function Attrs: noinline nounwind optnone uwtable define dso_local i32 @main() #0 { %1 = alloca i32, align 4 %2 = alloca [16 x i8], align 16 %3 = alloca i32, align 4 %4 = alloca i32, align 4 store i32 0, i32* %1, align 4 %5 = bitcast [16 x i8]* %2 to i8* call void @llvm.memset.p0i8.i64(i8* align 16 %5, i8 0, i64 16, i1 false) store i32 32, i32* %3, align 4 %6 = load i32, i32* %3, align 4 %7 = add nsw i32 %6, 256 %8 = add nsw i32 %7, 512 store i32 %8, i32* %4, align 4 %9 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([24 x i8], [24 x i8]* @.str, i32 0, i32 0)) %10 = getelementptr inbounds [16 x i8], [16 x i8]* %2, i32 0, i32 0 %11 = call i32 (i32, i8*, i32, ...) bitcast (i32 (...)* @read to i32 (i32, i8*, i32, ...)*)(i32 0, i8* %10, i32 16) %12 = getelementptr inbounds [16 x i8], [16 x i8]* %2, i32 0, i32 0 %13 = call i32 @puts(i8* %12) ret i32 0 }
test函数如下
; Function Attrs: noinline nounwind optnone uwtable define dso_local void @test(i32, i32) #0 { %3 = alloca i32, align 4 %4 = alloca i32, align 4 %5 = alloca i32, align 4 store i32 %0, i32* %3, align 4 store i32 %1, i32* %4, align 4 %6 = load i32, i32* %3, align 4 %7 = load i32, i32* %4, align 4 %8 = add nsw i32 %6, %7 %9 = add nsw i32 %8, 1638 store i32 %9, i32* %5, align 4 ret void }
全局变量用unnamed_addr来标记,表示地址不重要,只有内容
nsw 是“No Signed Wrap”缩写,是一种无符号值运算的标识
nuw 是“ No Unsigned Wrapp”缩写,是一种有符号值运算的标识
bitcast ... to ..是类型转换指令,可以在不修改数据的前提下转换数据类型
例如,上面的%5 = bitcast [16 x i8]* %2 to i8*
意思是把变量%2(原本的类型是一个指向16字节的数组指针) 转换为一个指向字符的指针,然后%5存储转换后的指针
函数或者变量用dso_local标记,表示解析为同一链接单元中的符号, 即使定义不在此编译单元内,也会直接访问
使用define定义函数时,遵守以下定义规则:
define [linkage] [PreemptionSpecifier] [visibility] [DLLStorageClass]
[cconv] [ret attrs]
<ResultType> @<FunctionName> ([argument list])
[(unnamed_addr|local_unnamed_addr)] [AddrSpace] [fn Attrs]
[section "name"] [comdat [($name)]] [align N] [gc] [prefix Constant]
[prologue Constant] [personality Constant] (!name !N)* { ... }参数列表是逗号分隔的参数序列,其中每个参数遵守以下规则
<type> [parameter Attrs] [name]其中<>中为必填项,[]中为可选项
更多IR语法可参考: http://llvm.org/docs/LangRef.html ,这个页面非常大,可以通过最开头的目录快速找到相应IR指令的语法
LLVM的优化即对中间代码IR优化,由多个Pass来完成,每个Pass完成特定的优化工作。
可以分组比如像 clang命令的参数如-O2,-O3, -O4等。
Pass即为一层一层相互独立的IR优化器。可以做到代码优化,代码混淆等
pass一般有以下几种分类

这里首先需要了解几个概念:
Module, Function, BasicBlock, Instruction, Value
- Module: 包含 Function,简单的说就是一个.c或者.cpp文件的集合,它包含了许多的function,main就是其中一种
- Function:包含若干 BasicBlock,也就是一个函数里面会有很多的代码嘛,每一段顺序执行的代码都是一个BasicBlock
- BasicBlock:包含若干 Instruction,也就是包含若干个汇编层指令了,想add啊sub啊之类的
- Instruction: 具体到每一个指令,就保护了若干个opcode,或者说value
- 指令的格式一般为: 操作符+操作数
为了直观的体现出pass的作用,这里举个例子,编写一些简单的pass
mkdir outpass
cd outpass
mkdir print_pass在outpass文件夹中创建一个CMakeLists.txt文件,内容为以下:
cmake_minimum_required(VERSION 3.4)
set(ENV{LLVM_DIR} ~/LLVM/bulid/lib/cmake/llvm) #这里设置LLVM_DIR变量为前面编译安装llvm的build目录下的/lib/cmake/llvm
find_package(LLVM REQUIRED CONFIG)
add_definitions(${LLVM_DEFINITIONS})
include_directories(${LLVM_INCLUDE_DIRS})
link_directories(${LLVM_LIBRARY_DIRS})
# add c++ 14 to solve "error: unknown type name 'constexpr'"
add_compile_options(-std=c++14)
add_subdirectory(Print_FuncPass) # Use your pass name here.然后cd print_pass,再创建一个CMakeLists.txt文件,内容为以下:
add_library(PrintFunctions MODULE
#这里填写pass文件名
Print_FuncPass.cpp
)
# LLVM is (typically) built with no C++ RTTI. We need to match that;
# otherwise, we'll get linker errors about missing RTTI data.
set_target_properties(PrintFunctions PROPERTIES
COMPILE_FLAGS "-fno-rtti"
)
# Get proper shared-library behavior (where symbols are not necessarily
# resolved when the shared library is linked) on OS X.
if(APPLE)
set_target_properties(PrintFunctions PROPERTIES
LINK_FLAGS "-undefined dynamic_lookup"
)
endif(APPLE)最后就是编写pass了,pass本质上也是一个c++,创建Print_FuncPass.cpp,内容如下
#include "llvm/Pass.h" #include "llvm/IR/Function.h" #include "llvm/Support/raw_ostream.h" #include "llvm/IR/LegacyPassManager.h" #include "llvm/Transforms/IPO/PassManagerBuilder.h" using namespace llvm; namespace { struct Hello : public FunctionPass { static char ID; Hello() : FunctionPass(ID) {} virtual bool runOnFunction(Function &F) { //输出当前调用的函数名 errs() << "A function has been called: " << F.getName() << "!\n"; return false; } }; } char Hello::ID = 0;//实例化hello static RegisterPass<Hello> X("print_func", "print func name PASS", false /* Only looks at CFG */, false /* Analysis Pass */); //注册到 opt 中,通过 opt -print_func 来使用该pass,第一个参数用于命令行,第二个参数是说明该pass的作用,第三个参数用于cfg时才需要true,第四个参数用于分析pass的时候才需要true static RegisterStandardPasses Y( PassManagerBuilder::EP_EarlyAsPossible, [](const PassManagerBuilder &Builder, legacy::PassManagerBase &PM) { PM.add(new Hello()); }); //注册到标准编译流程中,默认会执行该pass,通过 clang 即可调用pass,如果不进行RegisterStandardPasses注册,则clang无法调用pass,只能通过opt
这个pass的作用是每次调用一个函数,就会输出其函数的名字
pass编写完了,就直接编译
在outpass目录下执行:
cmkae .
make
编译完成后会生成一个.so文件,接下来就需要一个test.c来验证pass的效果
在outpass目录编写一个test.c
#include <stdio.h> int func2() { int a,b =1; return a+b; } int func1() { int a,b =1; func2(); return a+b; } int main() { func1(); return 0; }
最后就调用pass作用在这个test.c了,有两种方式
一、直接使用clang
clang -Xclang -load -Xclang ./outpass/Print_FuncPass/libPrintFunctions.so ./test.c
输出如图

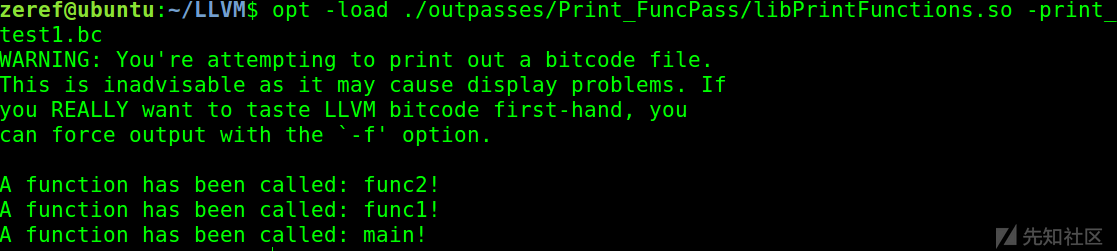
二、使用opt
首先要用clang生成.bc文件
clang -emit-llvm -c ./test.c
然后再使用opt
opt -load ./outpass/Print_FuncPass/libPrintFunctions.so -print_func < ./test.bc
输出如图
当输入opt -load ./outpasses/Print_FuncPass/libPrintFunctions.so -help可以看到

这说明我们paas中的RegisterPass注册方法是有效的,print_func的参数选项显示在-help下供选择择
官方: http://llvm.org/
GitHub:https://github.com/llvm-mirror/llvm
官方历史版本下载页面: http://releases.llvm.org/download.html
llvm中文文档网: https://llvm.comptechs.cn/
http://www.aosabook.org/en/llvm.html
http://ruiy.leanote.com/post/ubuntu16.04-%E5%AE%89%E8%A3%85-llvm
https://www.leadroyal.cn/?cat=20
https://juejin.im/post/5ddbda4051882572f56b57b8
https://juejin.im/post/5e01dc03f265da33e67b4873
如有侵权请联系:admin#unsafe.sh