03/19/2024
8 min read

As Cloudflare continues to grow, we are constantly provisioning new servers, data centers, and hardware all over the globe. With this increase in scale it became necessary to re-evaluate our approach to node and datacenter tooling. In this blog post, we explore an in-house infrastructure system we’ve built, called Zinc, to step up to the task. This system, built in Rust, has become an essential part of system engineering, platform management, and provisioning at Cloudflare, while providing user-friendly engineering tools and automations for Cloudflare employees to leverage.
The nature of Zinc is a rather simple system, providing first class data models for logical and physical infrastructure assets here at Cloudflare. Items such as servers (nodes), network devices, and data centers are all members of Zinc, modeled in a strongly-typed system. With these models, Zinc enables powerful APIs, integrations, and interfaces for efficient fleet management on top of this data. Tasks such as assigning workloads to nodes, scheduling any type of data center maintenance, querying data about our fleet, or even managing the repair cycle of faulty nodes are greatly simplified through Zinc and its integrations with other Cloudflare systems.
By providing Cloudflare engineers with a native web interface and command line tooling for interacting with Zinc’s data, a central pane of a glass has been created, where the ability to expand, build, and monitor our fleet has never been easier.
Humble Beginnings
Several years ago, workload management and server provisioning was a tedious process. For our control plane data centers, we would define the workload for every node in massive source-controlled YAML files, sometimes as long as 80,000 lines. Each entry was a node, its name, its rack, and roles to be read by our configuration management software for assignment.
compute5545:
rack: 219
clickhouse:
cluster: dns
comment: |-
Updated by <user>As time went on, this became extremely cumbersome for engineers to manage and assign workloads for servers. Engineers would often have to update multiple files, updating every entry to assign and change workload data by hand. While this may seem like a slight inconvenience at first, when provisioning new hardware or changing workload configuration data, engineers would have to update hundreds of lines of YAML. Additionally, this data was not readily accessible to other systems and automation to read and modify. It became clear that this pattern could not scale, and a stronger framework would need to be created to manage this information.
First, we aimed to tackle this problem by making nodes and their workloads — which we call roles — first class data structures. Workload and node information were collected and stored in this new system called Zinc, and our configuration management system Salt began to read this information not from the YAML files, but a new RESTful API. We also added several features to Zinc to administer and manage node data:
- Workload Management - Zinc assumed the role of the source of truth for node workloads, also taking charge of metadata management for roles. Attributes like a node's associated cluster or its designated kernel version are now managed through Zinc, eliminating the need for lengthy configuration files scattered across our repositories.
- Least-Privilege User Accounts - Leveraging Cloudflare Access, every Cloudflare employee who uses Zinc has an individual account, with scoped permissions for their job role. This prevents potentially compromised or prying users from viewing sensitive asset information, and makes modifications to production systems impossible without approval.
- Change Request and Approval System - Zinc implements a change request system, similar to pull requests, so nodes and their associated workloads require approval from the team that manages the workload. For example, if a Cloudflare engineer wanted to provision and assign new Kubernetes nodes, this action would require approval by the Kubernetes team before being applied.
- Node Reservations - It can become necessary for Cloudflare engineers to reserve specific hardware for testing and future workload capacity. Zinc provides this functionality as a first-class operation, providing a clear view into what a node is being used for, even when not in production. A common pattern to see is spare hardware for roles like Postgres or Clickhouse reserved and ready to take over if other nodes need to be taken out of production.
- Node Metadata - Zinc collects a variety of node asset data through other subsystems at Cloudflare, unifying it all under a single pane of glass. Hardware information such as CPU, memory, generation, chassis, power, and networking configuration are all members of Zinc’s APIs and interfaces.
These were the initial features Zinc offered to Cloudflare's SRE teams, but over time needs grew to expand the scope and start handling a variety of asset and operational data. Zinc has since started representing and managing more infrastructure related to network devices and datacenter management.
System Blueprint
At Cloudflare, two critical systems, Zinc and Netbox, play complementary roles in managing infrastructure. Zinc specializes in handling the logical infrastructure and operational configuration, while Netbox focuses on physical infrastructure. For those unfamiliar with Netbox, it plays the important role of acting as our Datacenter Inventory Management System (DCIM). Details such as hardware specifications, serial numbers, cable diagrams, and rack layouts are all stored in Netbox. These elements are the building blocks of the infrastructure that Zinc imports and relies on to create higher level abstractions, useful for a variety of systems on Cloudflare to depend on, without having to know the nitty-gritty specifics of our datacenter information.
Supercharged Automations
Growing pains were inevitable given the sheer pace of Cloudflare’s growth. Processes around server provisioning, maintenance windows, repairs, and diagnostics reporting were reaching their limits. Luckily, the data available through Zinc made it a natural home for new and improved workflow automations aimed at removing toil across various touch points throughout a server’s lifecycle.
Repairs
Hardware failures are common at our scale. Issues such as disk failure, motherboard problems, or CPU voltage errors are just a few of the many common failures seen in production. While Cloudflare’s infrastructure is very fault tolerant, we want to quickly return hardware to production after a failure to increase capacity and optimize infrastructure costs. Prior to Zinc, engineers would have to manually collect and file tickets with information related to the hardware failure, tediously filling ticket details manually in order for data center technicians to service it. With Zinc, however, the process of collecting this data and generating repair tickets is entirely automated. As we continue developing Zinc, we will be able to manage this process all the way down to the individual hardware component level and enhance existing automation and diagnostic integrations, further optimizing the repair process. With just a few clicks (or driven by other automation), an accurate service ticket can be filed, enabling data center technicians to make repairs and get servers back into production as fast as possible.
Diagnostic Reports
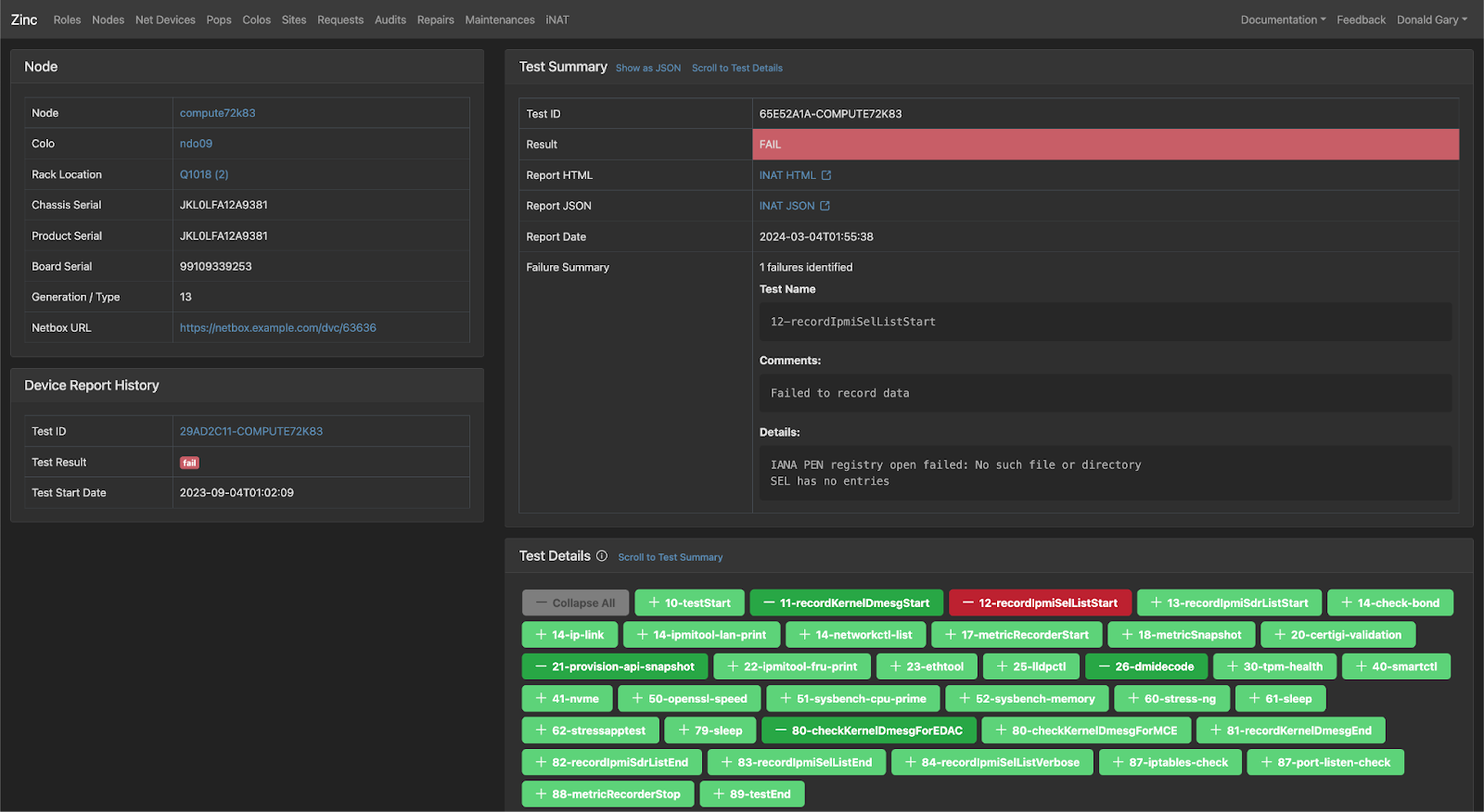
Zinc integrates directly with a diagnostic service we use to identify hardware issues on our fleet, known as INAT (Integrated Node Acceptance Tests). Zinc leverages this system to run acceptance tests before, during, and after server provisioning. It also can be executed in an ad hoc manner to determine the health of a machine. With INAT, we are able to save engineers time and quickly get results back to aid in the debugging process. Once these diagnostics are complete, the Zinc interface provides a report that can be used to determine the health of a server and if any actions need to be taken.
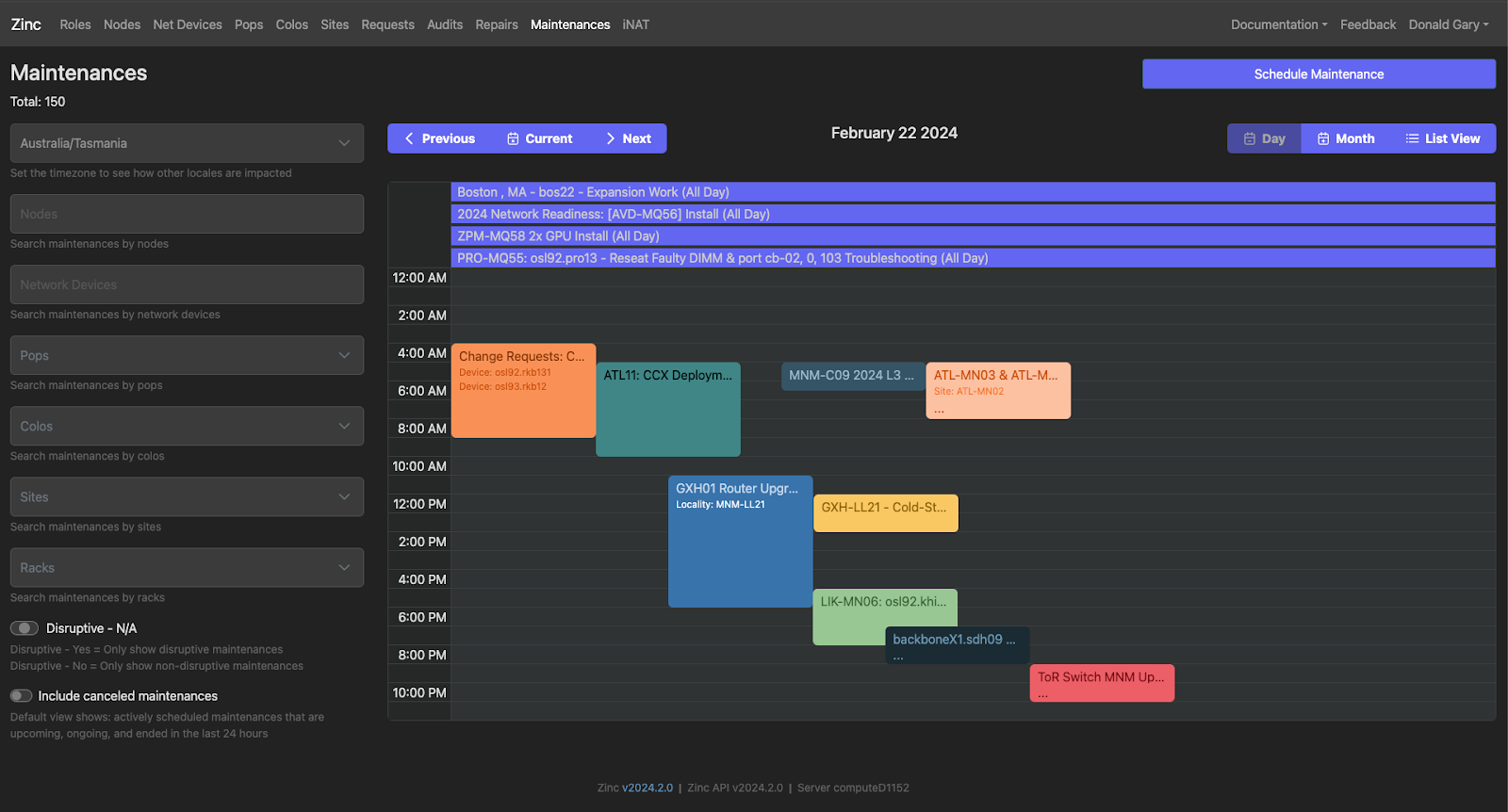
Maintenance Windows
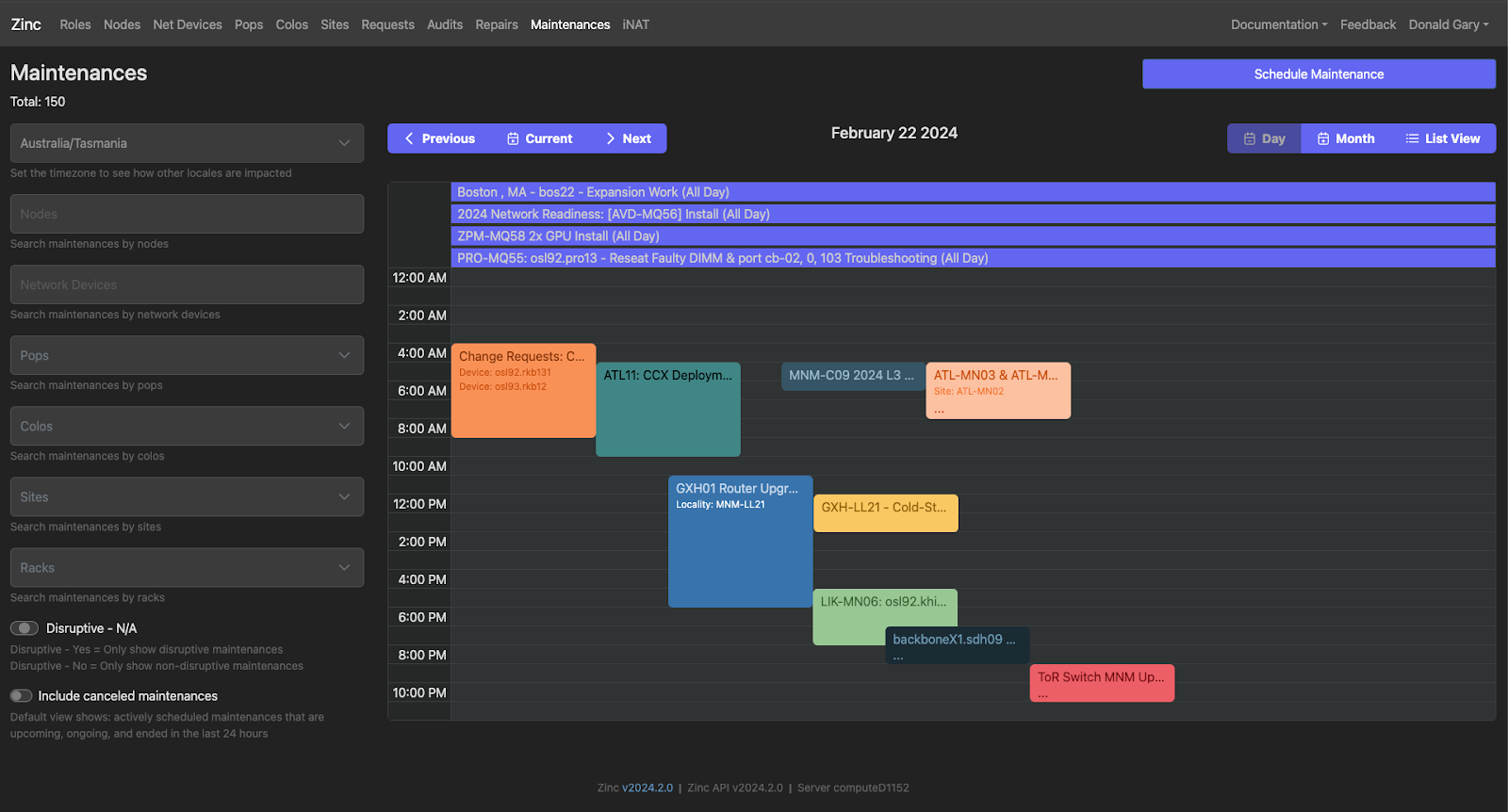
If you’ve ever wondered how the maintenance page on Cloudflare Status is populated, Zinc is the place of origin. As we are constantly doing hardware and network upgrades, it's important for Cloudflare to have a centralized view of what maintenance is happening, where it is happening, and the scale of all the systems and services that are or can be impacted by the maintenance. During maintenance, there are a variety of automated systems that ensure that Cloudflare sees no loss in quality of service, no matter where in the world the maintenance is happening. Zinc orchestrates and tracks these maintenance windows, and sends alerts to teams and Cloudflare customers when a disruptive, or even potentially disruptive, maintenance is scheduled in a region.
Reboots
Zinc provides an integration with a core system responsible for scheduling node reboots. When a node needs to be rebooted, such as to apply a new firmware upgrade or new Kernel version, there are systems at Cloudflare that schedule and safely manage this functionality. For example, it would be unsafe to reboot a production Clickhouse node with no prior warning, so these systems ensure traffic is properly routed away from this node prior to its reboot. Zinc provides an integration in its Web UI and CLI with this reboot management system to make the process of queuing and executing reboots much easier, as well as providing a place where we can add orchestration logic that leverages Zinc's operational management capabilities for server reboots.
Engineer Productivity
One of the most valuable parts of Zinc is that it provides engineers the ability to quickly perform complex queries and apply changes to our assets in production. At the API layer, we ensure that any access or changes to our infrastructure are properly scoped and authenticated. From there, Zinc provides two interfaces for employees managing our fleet: a command-line interface built in Rust, and a web application built in React, both of which are built on the same Zinc API that can be directly called from scripts or other systems as integrations are built out to automate more of the management of our infrastructure.
Here are some common examples of the CLI tooling our engineers use:
# List all datacenters at Cloudflare
$ zinc site get --all
# Set a node's status to disabled, removing it from production.
$ zinc node update status compute5545 disabled
# Querying all nodes in a specific rack, that are Kubernetes nodes.
$ zinc node get -f "rack:A413" -f “role:kubernetes”
# Putting a node failure into a repair state with debug information on how to fix.
$ zinc repair node create –name 36com360 --repair-type motherboard –remove-from-prod –comments “Diagnostic determined bad motherboard”
While these are simple queries, Zinc also provides its own query syntax to get more detailed information using its own query structure. Here we see an example of looking for Kubernetes workers that are a part of our pdx cluster, while ignoring storage and rook nodes.
zinc node get -f 'role:kubernetes.cluster=pdx&kubernetes.worker=true&!kubernetes.storage&!kubernetes.rook'
Node Name Node Type Node Status Colo ID Colo Name Rack Rack Unit Roles
compute2712 compute V 348 pdx05 B103 39 kubernetes
compute1995 compute V 349 pdx06 A104 7 kubernetes
compute1192 compute V 36 pdx01 A203 10 kubernetes
…
Total records: 1337Web UI
Despite being an internal tool, we felt it necessary to ensure that the UX of Zinc was intuitive and crisp. As it stands, hundreds of engineers at Cloudflare rely on Zinc’s web interface, so we found it essential to provide a fast, easy to use design. Built in React as a single page application, we aim to optimize for ease of use wherever possible. Querying items such as assets in repair, nodes in a specific city or country, or even CPU model are all first-class searchable items in our UI.
As mentioned previously, Zinc also provides a user-friendly Change Request interface, similar to Git Pull Requests, which shows what asset data is changing and who is making the change, and ensures the change is approved by designated staff prior to being applied in production.
Looking Ahead
Zinc represents a significant advancement in infrastructure management at Cloudflare. With our fleet growing faster than ever, especially with our new expansions to deliver GPUs on the Edge and Cloudflare’s R2, Zinc has stepped up to the plate, tackling the challenges of growth and providing invaluable support to our engineering teams. We hope this has been an insightful view of how Cloudflare is building to grow and scale well into the future.
There are still many wins to be had when it comes to infrastructure tooling here at Cloudflare. In the long term, Zinc will continue to be the backbone of infrastructure and asset data, with deeper automations and integrations to save our engineers time and toil and reduce manual errors as we continue to expand.
If managing and operating a fleet of servers as large as Cloudflare sounds like an exciting challenge to you, we’re hiring!
We protect entire corporate networks, help customers build Internet-scale applications efficiently, accelerate any website or Internet application, ward off DDoS attacks, keep hackers at bay, and can help you on your journey to Zero Trust.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you're looking for a new career direction, check out our open positions.