03/08/2024
9 min read
Today, we’re excited to talk about URL Scanner, a tool that helps everyone from security teams to everyday users to detect and safeguard against malicious websites by scanning and analyzing them. URL Scanner has executed almost a million scans since its launch last March on Cloudflare Radar, driving us to continuously innovate and enhance its capabilities. Since that time, we have introduced unlisted scans, detailed malicious verdicts, enriched search functionality, and now, integration with Security Center and an official API, all built upon the robust foundation of Cloudflare Workers, Durable Objects, and the Browser Rendering API.
Integration with the Security Center in the Cloudflare Dashboard
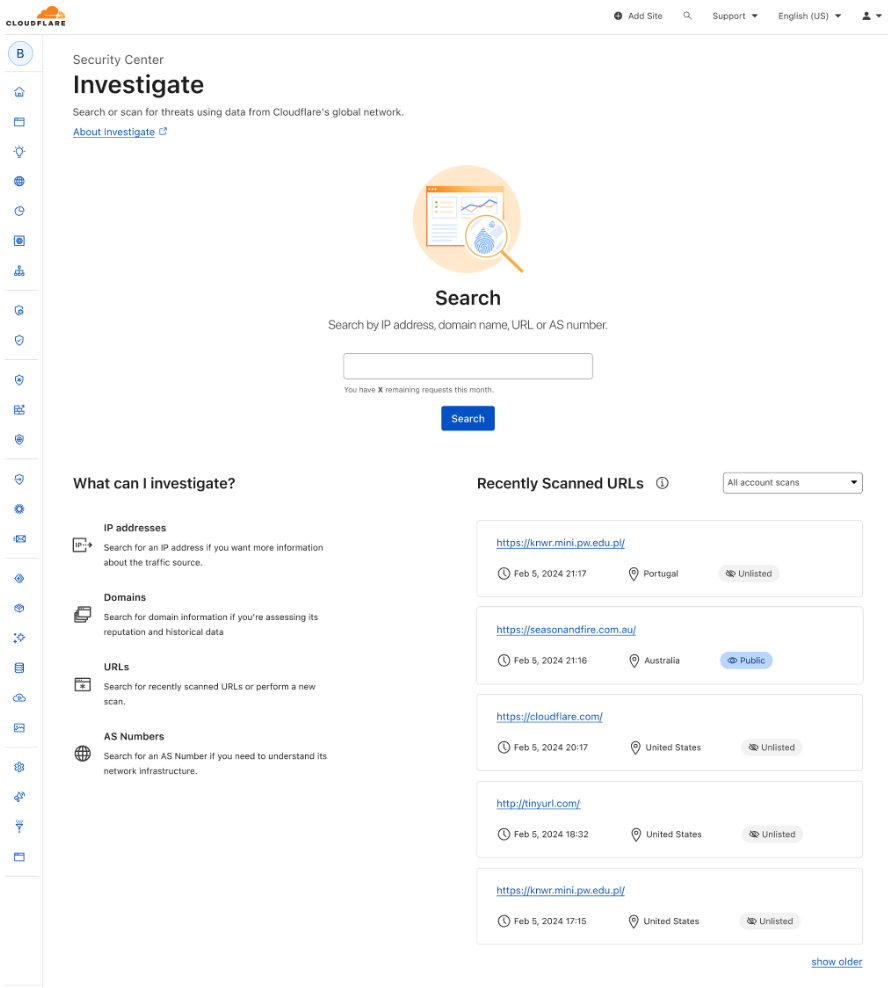
Security Center is the single place in the Cloudflare Dashboard to map your attack surface, identify potential security risks, and mitigate risks with a few clicks. Its users can now access the URL scanner directly from the Investigate Portal, enhancing their cybersecurity workflow. These scans will be unlisted by default, ensuring privacy while facilitating a deep dive into website security. Users will be able to see their historic scans and access the related reports when they need to, and they will benefit from automatic screenshots for multiple screen sizes, enriching the context of each scan.
Customers with Cloudflare dashboard access will enjoy higher API limits and faster response times, crucial for agile security operations. Integration with internal workflows becomes seamless, allowing for sophisticated network and user protection strategies.
Unlocking the potential of the URL Scanner API
The URL Scanner API is a powerful asset for developers, enabling custom scans to detect phishing or malware risks, analyze website technologies, and much more. With new features like custom HTTP headers and multi-device screenshots, developers gain a comprehensive toolkit for thorough website assessment.
Submitting a scan request
Using the API, here’s the simplest way to submit a scan request:
curl --request POST \
--url https://api.cloudflare.com/client/v4/accounts/<accountId>/urlscanner/scan \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer <API_TOKEN>" \
--data '{
"url": "https://www.cloudflare.com",
}'
New features include the option to set custom HTTP headers, like User-Agent and Authorization, request multiple target device screenshots, like mobile and desktop, as well as set the visibility level to “unlisted”. This essentially marks the scan as private and was often requested by developers who wanted to keep their investigations confidential. Public scans, on the other hand, can be found by anyone through search and are useful to share results with the wider community. You can find more details in our developer documentation.
Exploring the scan results
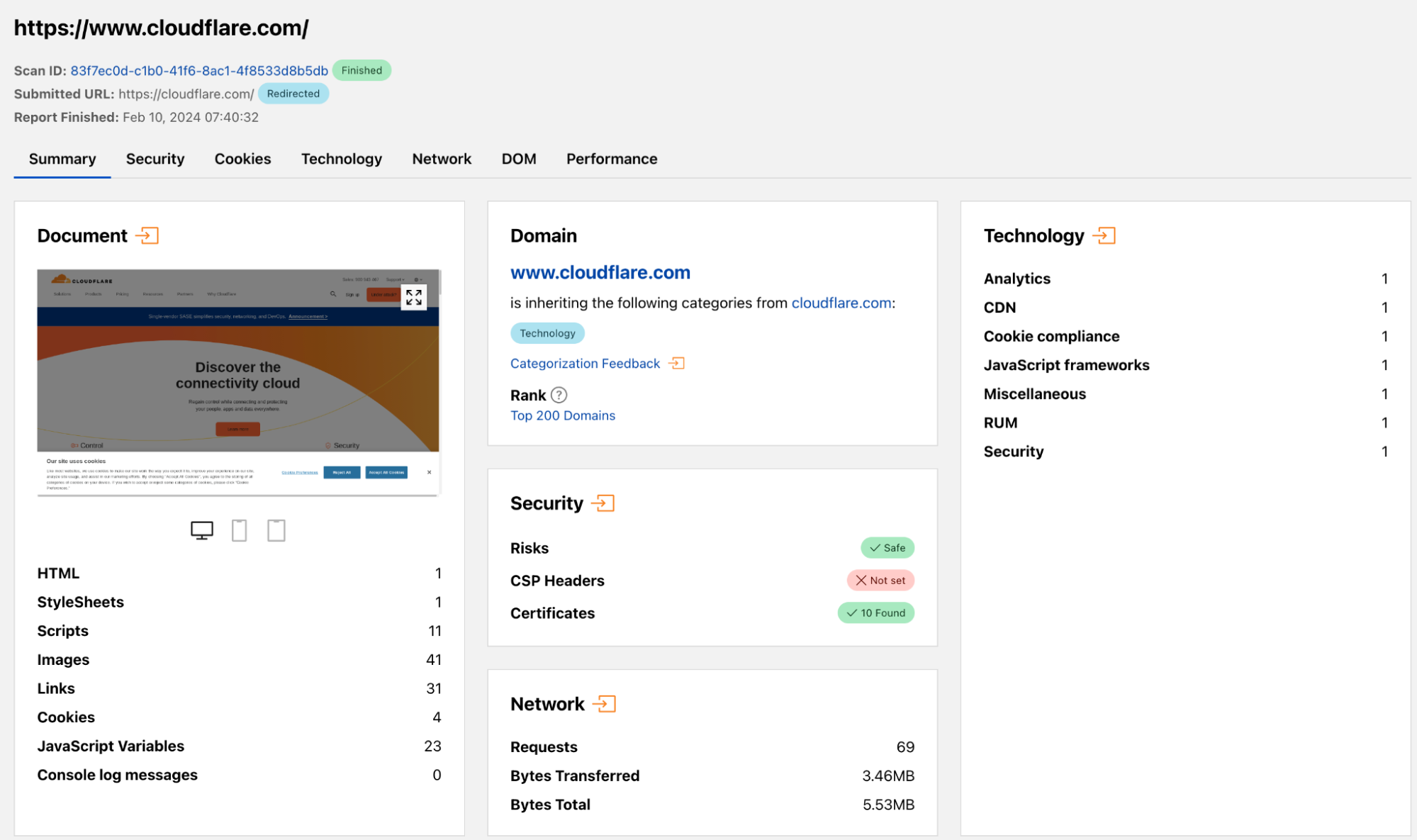
Once a scan concludes, fetch the final report and the full network log. Recently added features include the `verdict` property, indicating the site’s malicious status, and the `securityViolations` section detailing CSP or SRI policy breaches — as a developer, you can also scan your own website and see our recommendations. Expect improvements on verdict accuracy over time, as this is an area we’re focusing on.
Enhanced search functionality
Developers can now search scans by hostname, a specific URL or even any URL the page connected to during the scan. This allows, for example, to search for websites that use a JavaScript library named jquery.min.js (‘?path=jquery.min.js’). Future plans include additional features like searching by IP address, ASN, and malicious website categorisation.
The URL Scanner can be used for a diverse range of applications. These include capturing a website's evolving state over time (such as tracking changes to the front page of an online newspaper), analyzing technologies employed by a website, preemptively assessing potential risks (as when scrutinizing shortened URLs), and supporting the investigation of persistent cybersecurity threats (such as identifying affected websites hosting a malicious JavaScript file).
How we built the URL Scanner API
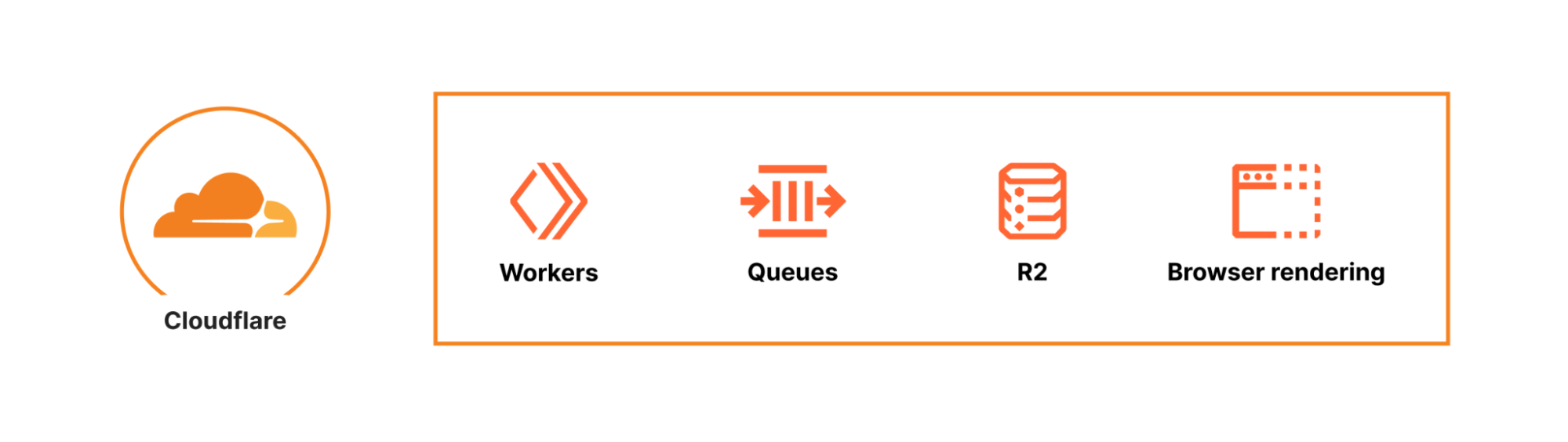
In recounting the process of developing the URL Scanner, we aim to showcase the potential and versatility of Cloudflare Workers as a platform. This story is more than a technical journey, but a testament to the capabilities inherent in our platform's suite of APIs. By dogfooding our own technology, we not only demonstrate confidence in its robustness but also encourage developers to harness the same capabilities for building sophisticated applications. The URL Scanner exemplifies how Cloudflare Workers, Durable Objects, and the Browser Rendering API seamlessly integrate.
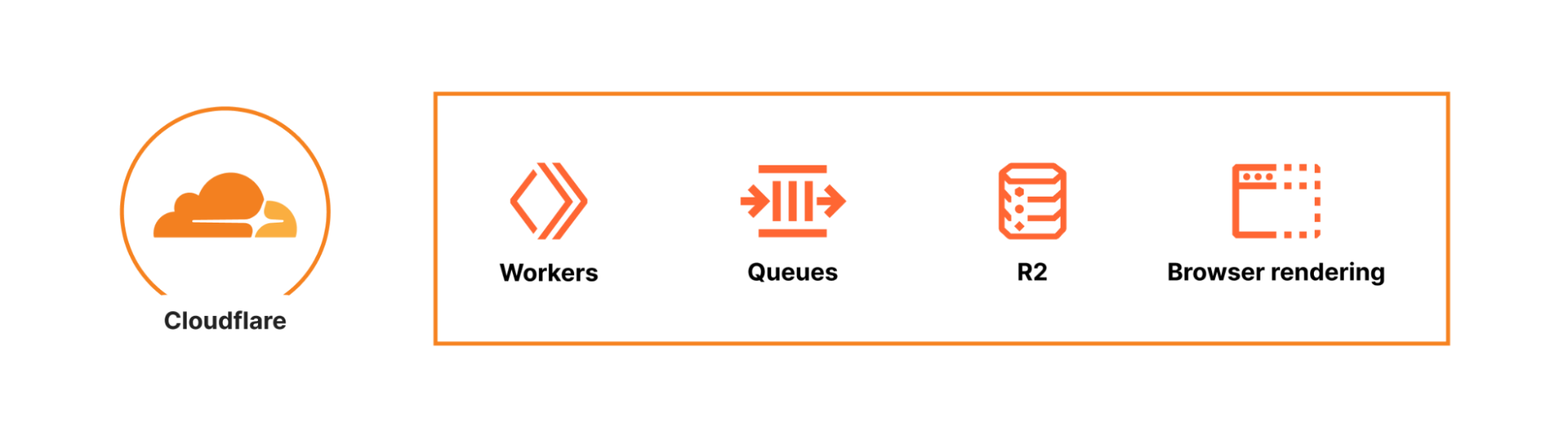
As seen above, Cloudflare’s runtime infrastructure is the foundation the system runs on. Cloudflare Workers serves the public API, Durable Objects handles orchestration, R2 acts as the primary storage solution, and Queues efficiently handles batch operations, all at the edge. However, what truly enables the URL Scanner’s capabilities is the Browser Rendering API. It’s what initially allowed us to release in such a short time frame, since we didn’t have to build and manage an entire fleet of Chrome browsers from scratch. We simply request a browser, and then using the well known Puppeteer library, instruct it to fetch the webpage and process it in the way we want. This API is at the heart of the entire system.
Scanning a website
The entire process of scanning a website, can be split into 4 phases:
- Queue a scan
- Browse to the website and compile initial report
- Post-process: compile additional information and build final report
- Store final report, ready for serving and searching
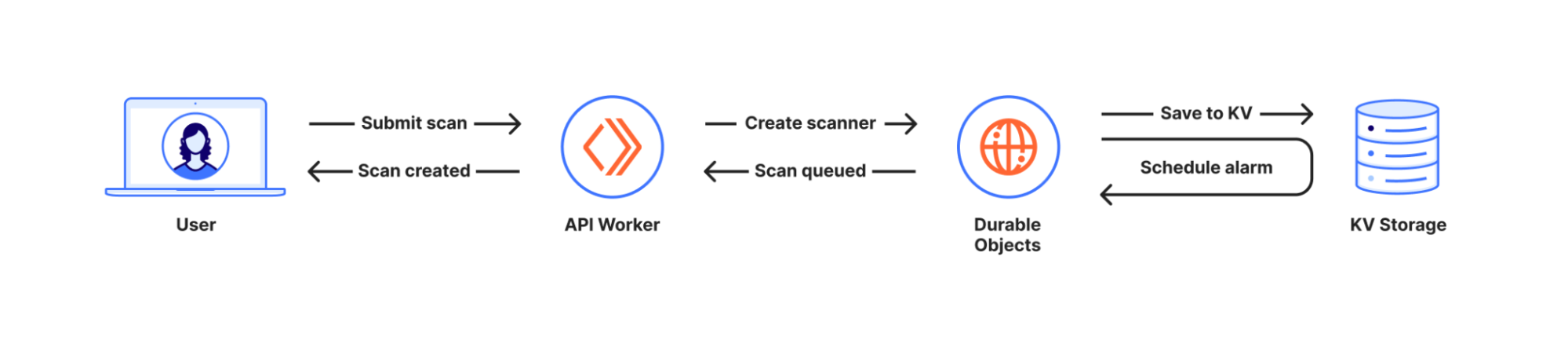
In short, we create a Durable Object, the Scanner, unique to each scan, which is responsible for orchestrating the scan from start to finish. Since we want to respond immediately to the user, we save the scan to the Durable Object’s transactional Key-Value storage, and schedule an alarm so we can perform the scan asynchronously a second later. We then respond to the user, informing them that the scan request was accepted.
When the Scanner’s alarm triggers, we enter the second phase:
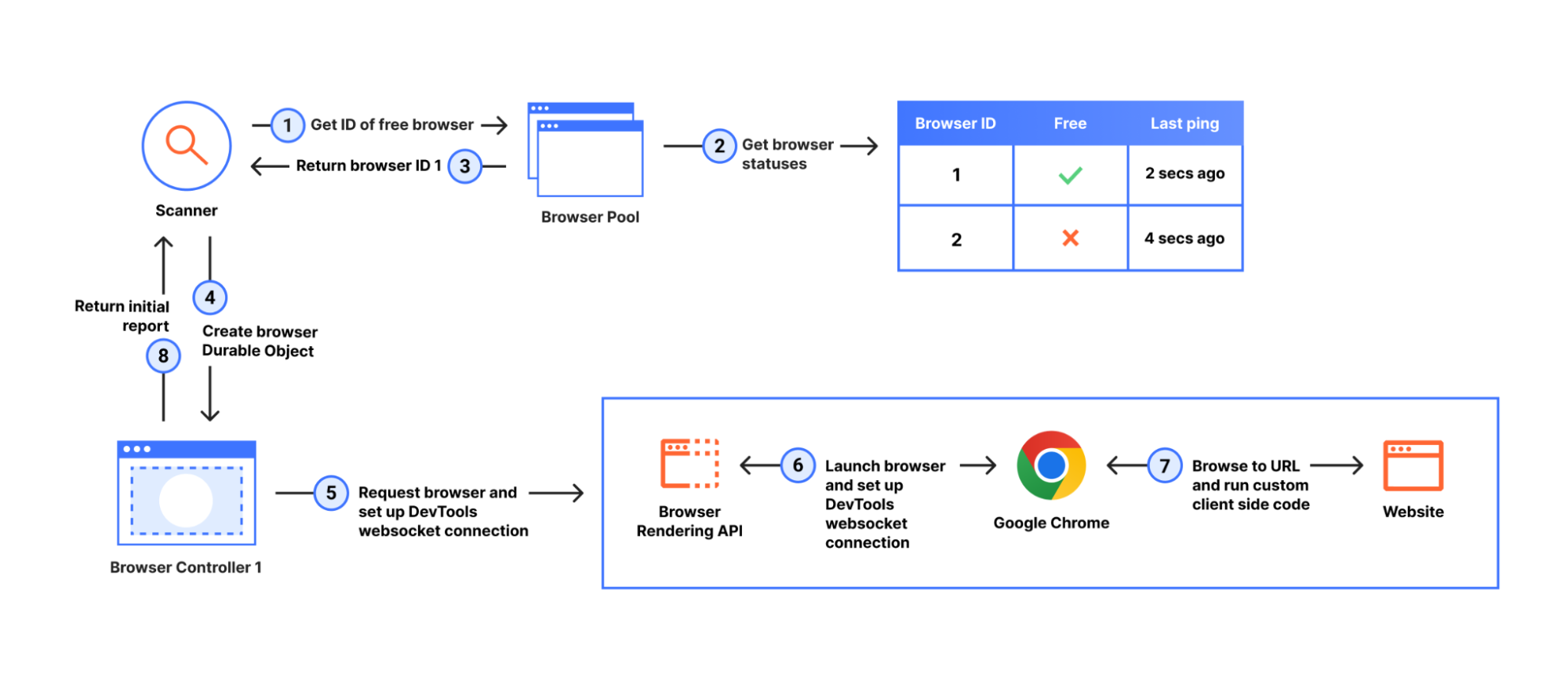
There are 3 components at work in this phase, the Scanner, the Browser Pool and the Browser Controller, all Durable Objects.
In the initial release, for each new scan we would launch a brand-new browser. However, This operation would take time and was inefficient, so after review, we decided to reuse browsers across multiple scans. This is why we introduced both the Browser Pool and the Browser Controller components. The Browser Pool keeps track of what browsers we have open, when they last pinged the browser pool (so it knows they’re alive), and whether they’re free to accept a new scan. The Browser Controller is responsible for keeping the browser instance alive, once it’s launched, and orchestrating (ahem, puppeteering) the entire browsing session. Here’s a simplified version of our Browser Controller code:
export class BrowserController implements DurableObject {
//[..]
private async handleNewScan(url: string) {
if (!this.browser) {
// Launch browser: 1st request to durable object
this.browser = await puppeteer.launch(this.env.BROWSER)
await this.state.storage.setAlarm(Date.now() + 5 * 1000)
}
// Open new page and navigate to url
const page = await this.browser.newPage()
await page.goto(url, { waitUntil: 'networkidle2', timeout: 5000, })
// Capture DOM
const dom = await page.content()
// Clean up
await page.close()
return {
dom: dom,
}
}
async alarm() {
if (!this.browser) {
return
}
await this.browser.version() // stop websocket connection to Chrome from going idle
// ping browser pool, let it know we're alive
// Keep durable object alive
await this.state.storage.setAlarm(Date.now() + 5 * 1000)
}
}
Launching a browser (Step 6) and maintaining a connection to it is abstracted away from us thanks to the Browser Rendering API. This API is responsible for all the infrastructure required to maintain a fleet of Chrome browsers, and led to a much quicker development and release of the URL Scanner. It also allowed us to use a well-known library, Puppeteer, to communicate with Google Chrome via the DevTools protocol.
The initial report is made up of the network log of all requests, captured in HAR (HTTP Archive) format. HAR files, essentially JSON files, provide a detailed record of all interactions between a web browser and a website. As an established standard in the industry, HAR files can be easily shared and analyzed using specialized tools. In addition to this network log, we augment our dataset with an array of other metadata, including base64-encoded screenshots which provide a snapshot of the website at the moment of the scan.
Having this data, we transition to phase 3, where the Scanner Durable Object initiates a series of interactions with a few other Cloudflare APIs in order to collect additional information, like running a phishing scanner over the web page's Document Object Model (DOM), fetching DNS records, and extracting information about categories and Radar rank associated with the main hostname.
This process ensures that the final report is enriched with insights coming from different sources, making the URL Scanner more efficient in assessing websites. Once all the necessary information is collected, we compile the final report and store it as a JSON file within R2, Cloudflare’s object storage solution. To empower users with efficient scan searches, we use Postgres.
While the initial approach involved sending each completed scan promptly to the core API for immediate storage in Postgres, we realized that, as the rate of scans grew, a more efficient strategy would be to batch those operations, and for that, we use Worker Queues:
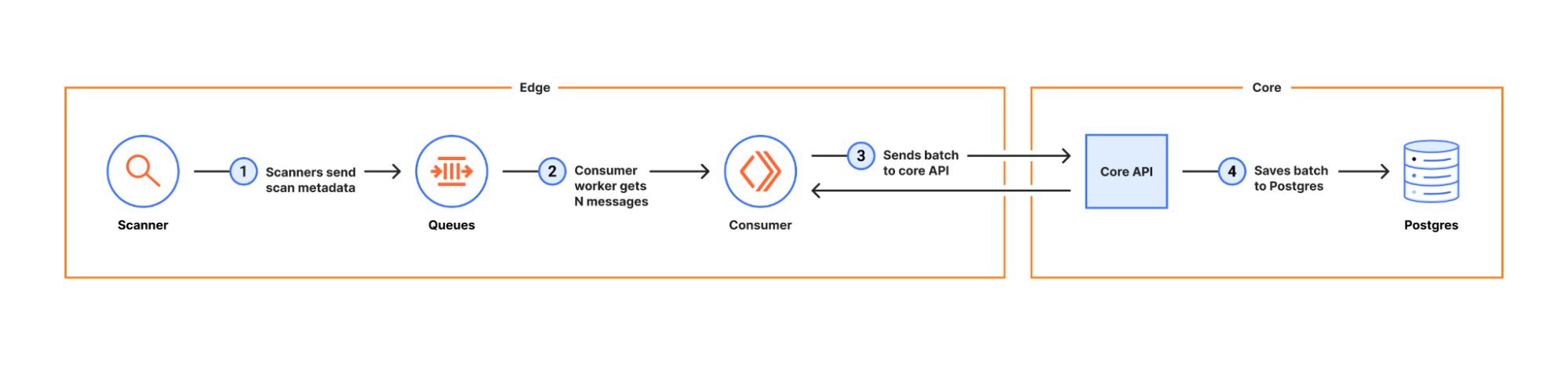
This allows us to better manage the write load on Postgres. We wanted scans available as soon as possible to those who requested them, but it’s ok if they’re only available in search results at a slightly later point in time (seconds to minutes, depending on load).
In short, Durable Objects together with the Browser Rendering API power the entire scanning process. Once that’s finished, the Cloudflare Worker serving the API will simply fetch it from R2 by ID. All together, Workers, Durable Objects, and R2 scale seamlessly and will allow us to grow as demand evolves.
Last but not least
While we've extensively covered the URL scanning workflow, we've yet to delve into the construction of the API worker itself. Developed with Typescript, it uses itty-router-openapi, a Javascript router with Open API 3 schema generation and validation, originally built for Radar, but that’s been improving ever since with contributions from the community. Here’s a quick example of how to set up an endpoint, with input validation built in:
import { DateOnly, OpenAPIRoute, Path, Str, OpenAPIRouter } from '@cloudflare/itty-router-openapi'
import { z } from 'zod'
import { OpenAPIRoute, OpenAPIRouter, Uuid } from '@cloudflare/itty-router-openapi'
export class ScanMetadataCreate extends OpenAPIRoute {
static schema = {
tags: ['Scans'],
summary: 'Create Scan metadata',
requestBody: {
scan_id: Uuid,
url: z.string().url(),
destination_ip: z.string().ip(),
timestamp: z.string().datetime(),
console_logs: [z.string()],
},
}
async handle(
request: Request,
env: any,
context: any,
data: any,
) {
// Retrieve validated scan
const newScanMetadata = data.body
// Insert the scan
// Return scan as json
return newScanMetadata
}
}
const router = OpenAPIRouter()
router.post('/scan/metadata/', ScanMetadataCreate)
// 404 for everything else
router.all('*', () => new Response('Not Found.', { status: 404 }))
export default {
fetch: router.handle,
}
In the example above, the ScanMetadataCreate endpoint will make sure to validate the incoming POST data to match the defined schema before calling the ‘async handle(request,env,context,data)’ function. This way you can be sure that if your code is called, the data argument will always be validated and formatted.
You can learn more about the project on its GitHub page.
Future plans and new features
Looking ahead, we're committed to further elevating the URL Scanner's capabilities. Key upcoming features include geographic scans, where users can customize the location that the scan is done from, providing critical insights into regional security threats and content compliance; expanded scan details, including more comprehensive headers and security details; and continuous performance improvements and optimisations, so we can deliver faster scan results.
The evolution of the URL Scanner is a reflection of our commitment to Internet safety and innovation. Whether you're a developer, a security professional, or simply invested in the safety of the digital landscape, the URL Scanner API offers a comprehensive suite of tools to enhance your efforts. Explore the new features today, and join us in shaping a safer Internet for everyone.
Remember, while Security Center's new capabilities offer advanced tools for URL Scanning for Cloudflare’s existing customers, the URL Scanner remains accessible for basic scans to the public on Cloudflare Radar, ensuring our technology benefits a broad audience.
If you’re considering a new career direction, check out our open positions. We’re looking for individuals who want to help make the Internet better; learn more about our mission here.
We protect entire corporate networks, help customers build Internet-scale applications efficiently, accelerate any website or Internet application, ward off DDoS attacks, keep hackers at bay, and can help you on your journey to Zero Trust.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you're looking for a new career direction, check out our open positions.