0x01 前言
本篇paper来自ICCAI 2018,采用了fastText和随机森林算法相结合的FRF-WD模型,使用一些静态features和PHP opcode,对Webshell进行检测。但与之前的文章不同,本篇文章不再是基于HTTP流量检测,而是针对文件进行检测。
0x02 Background
Opcode是一种PHP脚本编译后的中间语言,对于PHP的语言引擎Zend执行代码,会经过如下4个步骤:
1.Scanning(Lexing) ,将PHP代码转换为语言片段(Tokens);
2.Parsing, 将Tokens转换成简单而有意义的表达式;
3.Compilation, 将表达式编译成Opocdes;
4.Execution, 顺次执行Opcodes,每次一条,从而实现PHP脚本的功能。
而现有的一些工作已经表明,通过opcodes的频率可以区分恶意软件和可信软件。虽然PHP Opcode不同于恶意软件识别中使用的Opcode,但是他们在本质上是一致的,故此本篇文章想要借助PHP Opcode来对恶意php webshell文件进行检测。
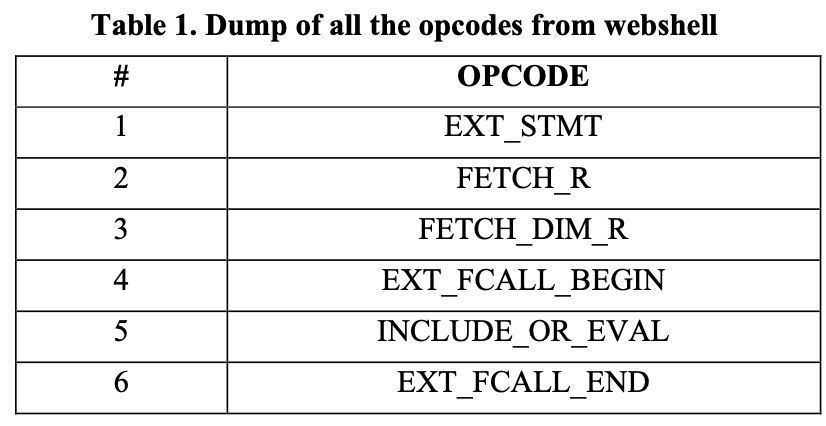
PHP拥有拓展Vulcan Logic Disassembler (VLD),其可以hook Zend引擎,方便我们dump出所有的opcodes,例如如下一句话木马:
< ?php eval($_POST['a']); ? >
如果我们运行该webshell,通过VLD,我们可以得到:

而我们正可以利用fastText和VLD得到的Opcode,训练文本分类器模型。
0x03 实现方法
FRF-WD模型对于文件的特征提取,可以分为两大步:
1. 分析提取文件的静态特征
2. 利用PHP-VLD获取文件的Opcode,利用fastText训练文本分类器模型。
然后再利用上述获取的特征作为随机森林的输入,训练一个webshell检测模型。
1、静态特征
对于文件的静态特征,选取如下5种:
1.长字符串
为了bypass现有的webshell检测,大多数的webshell会进行混淆,其惯用技术是利用编码,如base64,但其缺点就是对于一个较短的webshell,会经过编码,拼接变成一个很长的字符串。并且只检测php tag中的长字符串,可以有效避免富文本,js,图片,video或是css文件的干扰。
2.信息熵(Information Entropy)
由于内容加密会增加信息熵,所以计算信息熵是检测加密webshell的一个非常好的手段。
3.IC(Index of Coincidence)
IC在分析自然语言明文和密文中非常有用,如果IC值较低,那么表明文件中可能存在混淆或加密。
4.关键词搜索
如果文本文件中存在敏感词,诸如:eval(), assert(), exec(), shell_exec(), passthru(), system(), show_source(), proc_open() and pcntl_exec(),则会被认为是一个可疑文件。
5.黑名单
如果文件中检测到诸如:
webshell by 、
hack by、
bypass AV、
password is *、
etc .....
那么可以认为其是一个可疑危险文件,因为一般正常文件的注释中不会存在这些语句。
2、PHP Opcode特征
考虑到PHP文件可以利用PHP-VLD快速得到PHP Opcode,那么可以尝试使用文本分类器来识别webshell。在本文中选用了fastText模型来训练文本分类器。
fastText是一个快速文本分类算法,与基于神经网络的分类算法相比有两大优点:
1.fastText在保持高精度的情况下加快了训练速度和测试速度
2.fastText不需要预训练好的词向量,fastText会自己训练词向量
3.fastText两个重要的优化:Hierarchical Softmax、N-gram
同时,对于不同的文件,Opcode的数量可能只有少量,也可能有上千个,所以fastText比传统的深度学习方法TextCNN更适合处理这样的数据集。
工作大致分为3步:
1.通过PHP-VLD,将PHP文件代码转化为PHP Opcode;
2.使用fastText和标记好的样本对文本分类器进行训练;
3.使用训练好的文本分类器去判断哪些标记过的文本来自PHP Opcode;
最终得到的预测值用于文件Opcode的特征值。
3、分类器
在特征提取结束后,使用随机森林方法实现分类。
集成学习是通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成单预测,因此优于任何一个单分类的做出预测。
而随机森林是集成学习的一个子类,它依靠于决策树的投票选择来决定最后的分类结果。同时随机森林具有快速、高效、预测精度高等特点。同时其在生成过程中,能够获取到内部生成误差的一种无偏估计。

0x04 数据实验
实验收集了共计8521个PHP文件,其中包括1587个PHP Webshell,其来自于github上一些webshell Project。对于正常文件来自于几个著名PHP框架,例如Yii2、Wordpress、CI等。
对于数据集,30%用于构建PHP Opcode文本分类器,70%用于随机森林的训练和模型测试。
为了证明FRF-WD模型的性能,实验使用了如下几个公式进行评估:
TP:True Positive、TP是正确分类为webshell文件的个数、TN:True Negative、FN是错误分类为良性文件的webshell文件的个数。



由于在fastText模型中,word-Ngram是一个重要参数,为了找到最适合的N-gram,实验测试了n=1 ~ n=6,效果如下:

可见最佳的N-gram是4-gram。
同时实验比较了随机森林模型,和随机森林与fastText相结合的模型性能的差异:


可见在不考虑PHP Opcode特征下,随机森林的准确率仅为88.97%,而在FRF-WD模型下,准确数在97.92%。同时ROC曲线也能说明FRF-WD模型拥有更好的性能。
0x05 后记
本文与之前的工作不同,之前的webshell检测使用了CNN对text进行分类,而本文则使用了fastText和随机森林结合的方式进行webshell检测。
0x06 参考链接
http://www.laruence.com/2008/06/18/221.html
https://blog.csdn.net/feilong_csdn/article/details/88655927
https://www.cnblogs.com/gczr/p/7097704.html
本文为 一叶飘零 原创稿件,授权嘶吼独家发布,如若转载,请注明原文地址
如有侵权请联系:admin#unsafe.sh