引言
在如今群魔乱舞的网络内容生态下,广告拦截器几乎已经从一种可选项变成了必需品;没有广告拦截的浏览体验几乎是不可接受的。
不过,仅靠安装一个广告拦截器,并不足以实现令人满意的效果。广告拦截器依赖的规则集——本质上是要拦截或隐藏的元素列表——都是由社区维护的,质量参差不齐;即使人气较高的规则,也会随着时间推移积累很多冗余和错误。如果贪多求全、囫囵启用,很容易拖累性能、导致误伤。
什么内容应当被屏蔽也是一个非常主观的判断。有些视觉干扰较小、出现频率不高、不涉及隐私追踪的广告,其实是可以接受的,也是给独立、小规模网站提供力所能及支持的一种方式。(这也是 Better Ads 和 Acceptable Ads 等项目的主张,尽管两者都因与广告商存在利益往来受到批判。)
相反,有些严格意义上不是「广告」的元素,同样具有浪费资源、占用注意力的危害,例如侧边栏里惹眼的推荐窗格、强行穿插在文章中的自动播放视频、邮件订阅请求,等等。
因此,完全符合自己要求的规则集其实是很难找到现成的。即使是 Fanboy’s Annoyance List、AdGuard Annoyances Filter 等针对「恼人」元素的规则集,也只相对保守地覆盖了有一定流量和人气的网站上一小部分的干扰元素。要真正取得理想的效果,自己动手是免不了的。
不过,广告拦截器官方文档(例如 uBlock Origin 和 AdGuard)中的说明一般比较晦涩,初上手时看起来可能有些门槛。为此,本文将从入门角度,介绍一些常用思路和对应语法,希望能帮助读者上手写出自己需要的规则。
(注:市面上广告拦截器很多,品质良莠不齐,规则语法各有差异。如无特别说明,后文示例均以综合口碑最好的 uBlock Origin 为准。如果所用浏览器不受支持,AdGuard 也可一用,两者语法大体上是兼容的。)
基础铺垫
在动手写规则之前,首先应当了解广告拦截器使用的规则主要分为两类:
- 基础规则(basic rules),也称拦截规则(blocking rules)。这种规则是针对特定文件地址的,目的是让显示广告所需的数据无法加载。因此,更适合用来屏蔽 URL 特征明显(例如文件名或路径有固定规律)的广告资源文件、跟踪脚本等;也只有这种规则能起到保护隐私的作用。
- 修饰规则(cosmetic rules),也称隐藏规则(hiding rules)。这种规则是针对特定页面元素的,目的是将页面上广告所在部分隐藏起来。因此,更适合屏蔽不易通过 URL 特征加以区分、但在页面上的出现位置有规律的元素;也经常用作普通规则的补充,隐藏无法加载的广告部分在页面上留下的空白。
(一些更复杂的规则,例如注入自定义 CSS 样式或 JavaScript 脚本的规则,是部分拦截器自行实现的,通用性不足,本文暂不讨论。)
就本文讨论的屏蔽干扰元素场景而言,由于这类元素大多同时包含了文本和媒体文件,位置上也常与主体内容穿插排列,用拦截规则来屏蔽既不方便也不现实,因此主要用得上的是修饰规则,追求一个「眼不见心不烦」。因此,下面也将以修饰规则为重点来介绍。
修饰规则的一般格式如下:
example.org##selector其中,分隔符 ## 之前的是规则针对的域名,之后的部分就是要屏蔽元素的表达式。
如何指定要屏蔽的元素呢?这主要是通过 CSS 选择器(CSS selector)来表达的。
插曲:CSS 选择器简介
如果你不熟悉 CSS 是什么及其工作机制,这是一个简单版的解释:网页的外观是由「内容」和「样式」两个部分共同决定的。例如,网页上「有什么字」是内容问题,「用什么字体」是样式问题;「显示什么图片」是内容问题,「图片的尺寸和动效」是样式问题;等等。
CSS 就是将样式应用于内容的一套语法规则。选择器是这套规则的一部分,其功能就是确定「要装饰哪些内容」。选择的依据可能是——
- 元素类型,例如一级标题
h1、图片img等; - class(类),可以理解为用于归类一组相关元素的自定义「标签」;
- id(标识符),可以理解为用于识别特定元素的专属自定义名称;
- 元素的任意属性,例如链接指向的特定网址
a[href="https://example.com"]; - 元素的特定状态,例如鼠标悬浮其上的元素
:hover、第一个下级元素:first-child; - 页面上具有可识别特征、但代码层面并无对应元素的局部,例如紧邻某个元素之后的位置
::after,段落中的第一个字符(::first-letter);或者 - 上述的结合。
可见,CSS 选择器为指定网页上的元素提供了充足的工具。又因为它是所有浏览器都支持的通用语法,借用 CSS 选择器来指定要屏蔽的范围就是很合理的选择了。
因此,要写出能屏蔽特定干扰元素的修饰规则,本质上就是要找出能选中相关元素的 CSS 选择器。事实上,修饰规则的基本工作原理,就是向当前页面注入一条针对选中元素的样式 display: none !important,指的是「使该元素不显示,忽略所有相反规定」。
怎么找呢?为了便于用户自定义修饰规则,大多数广告拦截插件都会提供一种「选择并屏蔽」功能。例如,下图是 uBlock Origin 的「元素选择器」模式,可以在页面上点击右键选择 Block element,或者在插件窗口中点击滴管形按钮打开。

在元素选择器模式下,用鼠标点击页面上想要屏蔽的部分,uBlock Origin 就会自动记录其对应的 CSS 选择器,并加入到规则列表中。(左右两个滑块分别用于微调选择范围的「深度」和「广度」,你可以把它们分别想象成控制抓娃娃机中抓手的高低位置和开合幅度。)
这看起来挺方便,然而在当下,这么做越来越难以获得令人满意的结果。显然,要让修饰规则充分发挥效果,其选择器的写法必须足够有「代表性」;只针对当前页面有效的规则是没什么意义的。这正是元素选择器的缺陷所在:它往往只会机械地复制所选择元素的属性,其结果往往是上图中那种晦涩冗杂的规则。
这些「废话规则」的成因和问题将在后文具体说明,但不难从直观上感到它们把范围划得过于「具体」了,从而失去了代表性。
相比依赖于广告拦截器过于机械的元素选择工具,本文更推荐使用浏览器自带 DevTools(开发者工具)中的检查器功能。你可以在网页空白处点击右键选择 Inspect(或 Inspect Element、检查元素等类似菜单项)或按 F12 打开它(Safari 需先手动启用)。

检查器界面的主体是当前页面中所有元素的树状结构(DOM)。点击左上角的箭头按钮(Safari 为右上角的靶形按钮),可以从页面中高亮选择元素,并在 DOM 中定位到其位置。
在这些铺垫的基础上,下面就介绍几种常用的干扰元素屏蔽规则定制思路。
按 class、id 或其他属性的值屏蔽元素
前面提过,class 和 id 分别类似于网页元素的「分类标签」和「专属名称」,因此对于识别和定位网页元素意义重大。在干扰元素屏蔽的语境下,匹配 class 和 id 也通常是编写屏蔽规则最高效的方式。
按 class 和 id 的值屏蔽元素的语法分别是:
.value
#value其中 value 为 class 或 id 的值。
至于选择什么值来匹配,一般而言可以关注 ad(广告)、promo(推广)、popup(弹出)、cta(call to action,操作引导)等与功能相关的关键词,以及 video(视频)、banner(横幅)、carousel(轮播图片)等与形态、格式相关的关键词。
相反,一般不要考虑 row-span-2(指「占据网格布局中的 2 行高」)、col-md-6(指「在中等以上尺寸设备上占据网格的 6 列宽」)这样的名称。这些名称是使用 Tailwind、Bootstrap 等 CSS 框架的产物,其功能是指定元素在页面网格中的布局,用它们来定位元素既不够有针对性,也很容易随着网站的版面微调而失效。
下面举个例子。下图所示的 9to5Mac 页面中,文末植入的「相关视频」是一种典型的非常自私的设计,仅仅为了引流而占据了大量网页空间,对于用户毫无价值。通过检查器可以看到,这个视频位于一个 div 元素中,其 class 名称为非常直白的 article__youtube-video。

因此,对应的屏蔽规则就是:
9to5mac.com##.article__youtube-video类似地,可以用下面的规则屏蔽评论区:
9to5mac.com###comments(注意这里有三个 #,其中前两个是分隔符,第三个是 id 选择器的标志。)
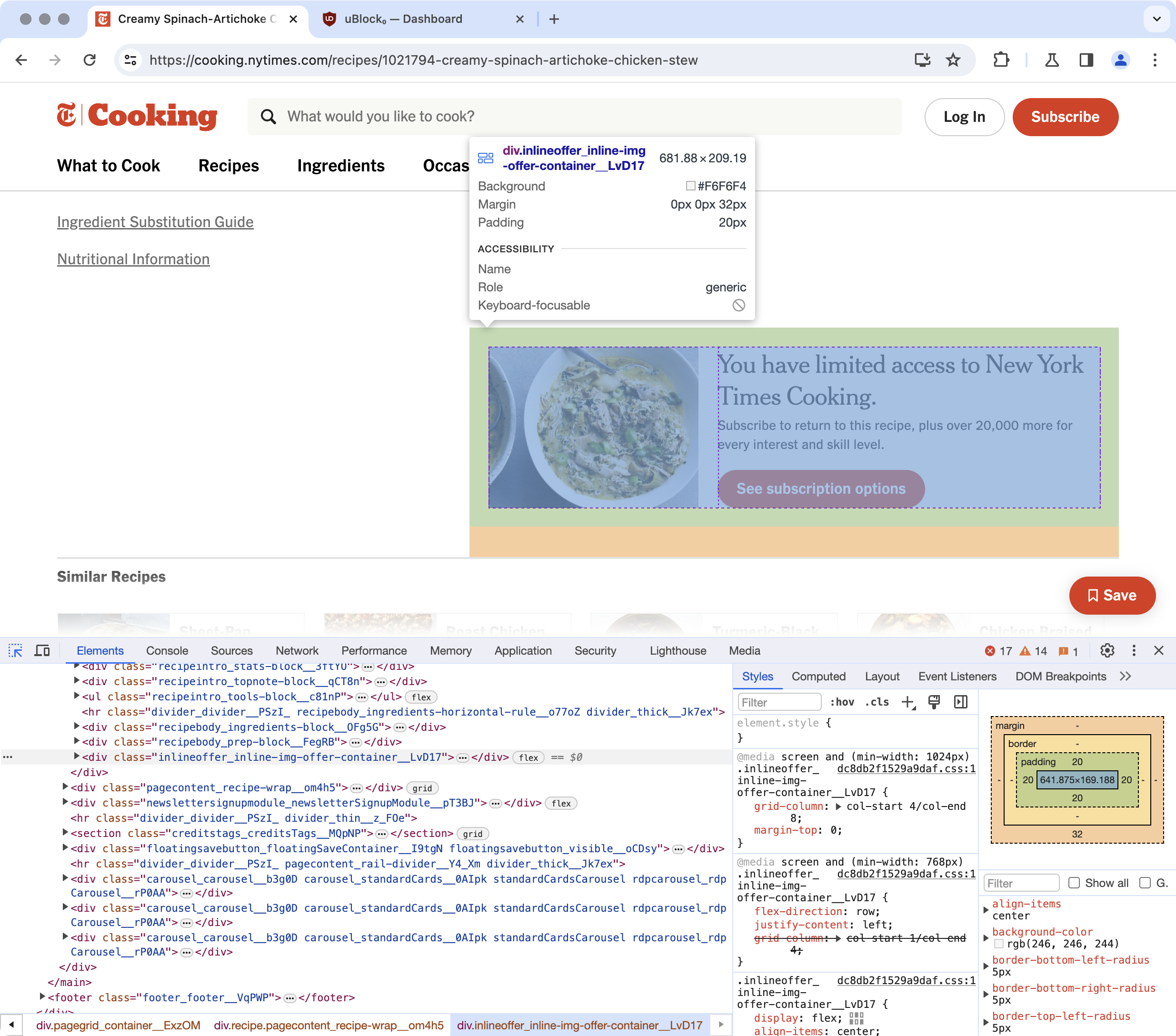
但这只是最简单的情况。在更多情况下,你看到的 class 名称可能是像下面这样的:

这里,尽管可以从类名中的 offer 字样判断出这就是广告横幅对应的 class,但如果你直接将完整的类名写成规则,很可能没过多久就会发现它失效了。
这是因为,上述类名末尾的 __LvD17 是使用网页开发框架编译所产生的随机字符串,会随着网站版本的更新不断改变。不过,这么做的目的并不是和用户「躲猫猫」,故意让用户难以屏蔽,而是为了避免手工命名 class 导致的操作繁琐、名称相互「打架」等问题,在大型站点开发中属于主流做法。当然,其副作用就是降低了网页代码的可读性,也变相提高了屏蔽元素的难度。
但办法还是有的,因为 CSS 选择器可以匹配属性值的片段(子字符串),具体如下所示:
| 语法 | 含义 |
|---|---|
[class^=value] |
选中类名的开头为 value 的元素 |
[class$=value] |
选中类名的结尾为 value 的元素 |
[class*=value] |
选中类名中任意位置包含 value 的元素 |
(在上述语法结尾的括号之前加一个字母 i,即 [class^=value i] 等等,可以让匹配变成大小写不敏感。)
因此,使用 [class^=inlineoffer](匹配开头)或者 [class*=inline-img-offer-container](匹配中间部分)都可以选中上面的广告横幅。至于用哪个更好,没有标准答案,应当结合尝试结果做个案判断。一般而言,越长的名称意味着越具体,好处是可以避免误伤;但也可能增加编写规则的工作量,需要多条规则才能屏蔽干净本可以「一网打尽」的同类。
这里,考虑到较短的 inlineoffer(字面意思是「行内广告」)无论如何都是干扰元素,不用担心误伤,再测试发现确实有效后就可以选用。
此外,如上所述,class 和 id 只是两种地位特殊的 HTML 元素属性,本节中提及的选择器语法也适用于其他任何属性。例如,在下图所示的 The Economist 页面上,右侧的广告元素可以通过自定义属性 data-test-id 的值识别出来。

因此,可以使用如下的规则来屏蔽:
www.economist.com##[data-test-id="right-hand-rail-ads"]经验上,其他有助于识别干扰元素的属性还有 data-ad-type、data-ad-zone、role、src、aria-label 等,留意观察一般都能发现规律。
根据位置特征屏蔽元素
尽管通过 class、id 和属性选择器已经能有效应对很多屏蔽需求,但这些选择器依赖于找出属性值中的规律,而这并不总是可行的。有些场合,干扰元素的属性特征并不明显,但出现的位置比较固定。这时,关系选择器(combinators)——根据层级和位置关系选择元素——就是更好的选择。