数据安全治理前期应通过现状分析找到已有的数据资产、已有的数据安全措施和已经存在的数据安全风险点,并以此作为数据安全规划和建设的依据。
现状分析概述
本文重点学习整理前期的数据安全现状分析,从安全合规对标、风险现状分析、行业最佳实践对比入手整理数据资产的梳理、重要数据的识别标识和通过数据安全风险评估、数据安全治理能力评估和DSMM评估等方式以评促建发现数据安全风险点。

一 数据资产梳理
数据资产梳理是数据分类分级、数据安全治理的关键环节,数据资产梳理工作的效果不仅直接关系到数据是否看得见,也关系到隐私及数据安全防护工作是否能达到预期的目标。
1. 梳理难点
当前各政企单位面临的数据资产问题统计主要如下:
- 历史遗留数据量级庞大,且新数据不断产生;
- 新系统上线和旧系统下线,业务系统繁多;
- 存在未登记备案的数据资产,管理存在盲点;
- 要么侧重于结构化数据,要么侧重于非结构化数据;
- 缺乏自动化工具,工作效率低,效果差,人工成本高;
- 数据管理与业务脱离,数据资产的责任方模糊不清;
- 新老员工的更迭交替,数据安全管理执行不连贯;
- 数据未能标识化管理,防护策略难以统一标准;
- 数据资产统计工作横跨安全、数据、研发、运维、DBA和业务灯众多部门。
部分行业痛点为例:
- 金融行业:数据规模庞大,种类庞杂,不仅有大量的个人隐私类数据,还有经营类数据,对于传统数据梳理方式而言,数据形式的多样性及复杂性带来数据资产梳理的难度加大。
- 运营商行业:由于过去烟囱式的开发方式和业务独立的运营模式,导致不同系统之间数据标准不一致,敏感数据分散分布在不同部门,加大数据资产梳理工作的复杂程度。
- 互联网行业:随着业务发展,数据呈爆发式增长,数据资产梳理往往需要投入大量人力物力进行手工处理,但是针对经营数据还是束手无策,导致无论是时效性、准确性还是数据价值挖掘都难以满足业务需求。
- 政府机构:数字政府建设是一个多元化技术融合的过程,横跨多个部门机构,数据来源复杂,标准化程度低,对于厘清数据资产分布情况,完成数据资产梳理及数据资产运营管理工作存在一定难度。
2. 梳理范围
数据资产梳理的范围一般包括三个角度:
组织范围:盘点要覆盖哪些组织和部门,例如:集团本部、集团+分子公司+部分供应链等。
业务范围:盘点哪些业务的数据,例如:生产业务、采购业务、营销业务、财务业务、人力资源业务等。
系统范围:盘点哪些应用系统的数据,例如:OA系统、ERP系统、MES系统、SCM系统、CRM系统、HR系统等。
3. 梳理方式
现阶段最好的梳理方式肯定是人工+自动化探测工具,紧靠人力,成本太大。
针对数据量大、过程文件、副本文件无法识别等行业痛点,以及用户老旧系统较多,数据字典丢失或维护不及时等问题现状,借助自动识别发现工具,采取静态扫描+动态监听的方式,对结构化与非结构化全量数据资源进行动态识别发现,形成数据资产清单。
人工的话主要是配合各部门干系人确定资产所在和数据核对,自动化梳理技术主要包含静态梳理技术和动态梳理技术,具体说明如下:
3.1静态自动化梳理技术
静态梳理技术主要用于完成对敏感数据的存储分布状况的摸底,从而帮助安全管理人员掌握系统的数据资产分布情况。
静态梳理技术可以分为结构化数据梳理和非结构化数据梳理两大类,最终建立对应的敏感数据资产清单。
- 对于结构化数据的梳理,静态扫描技术可用于获得数据的以下基本信息。通过端口扫描和特征发现,可以得到系统网段内存在的数据库列表及其所分布的IP地址,从而获得数据库资产清单。根据所定义的企业内不同敏感数据的特征,以及预先定义的这些数据的类别和级别,通过对表中的数据进行采样匹配,可以获得不同的列、表和库中的数据所对应的级别和类别。
- 非结构化数据的梳理可以采用磁盘扫描技术,根据预先定义的数据特征,对CSV、HTML、XML、PDF、Word、Excel和PPT等文档中的内容进行扫描,可以获得这些文件中信息的类别和级别。
3.2动态自动化梳理技术
动态梳理技术主要基于对网络流量的扫描,对系统中敏感数据的访问状况进行梳理,具体包括敏感数据的存储分布、系统访问状况、批量访问状况和访问风险等内容。
动态梳理技术可用于获得数据的以下基本信息:
- 哪些IP(数据库主机的)是数据的来源。哪些IP(业务系统或运维工具的)是数据的主要访问者。业务系统是如何访问敏感数据的(时间、流量、操作类型、语句)。运维人员是如何访问敏感数据的(IP、用户、操作)。
- 动态梳理技术同样也可分为对结构化数据访问网络流量的扫描,以及对非结构化数据访问网络流量的扫描。结构化数据的网络流量,主要是对各种RDBMS、NoSQL、MPP数据库的通信协议的流量监控;非结构化数据则主要是对Mail协议、HTTP、FTP等协议的监控和解析。
二 重要数据识别
1. 重要数据定义
《数据安全法》提出的一项重要制度即数据分类分级保护制度,一个重要概念即重要数据。重要数据的确定也是分类分级、数据治理的核心工作之一。
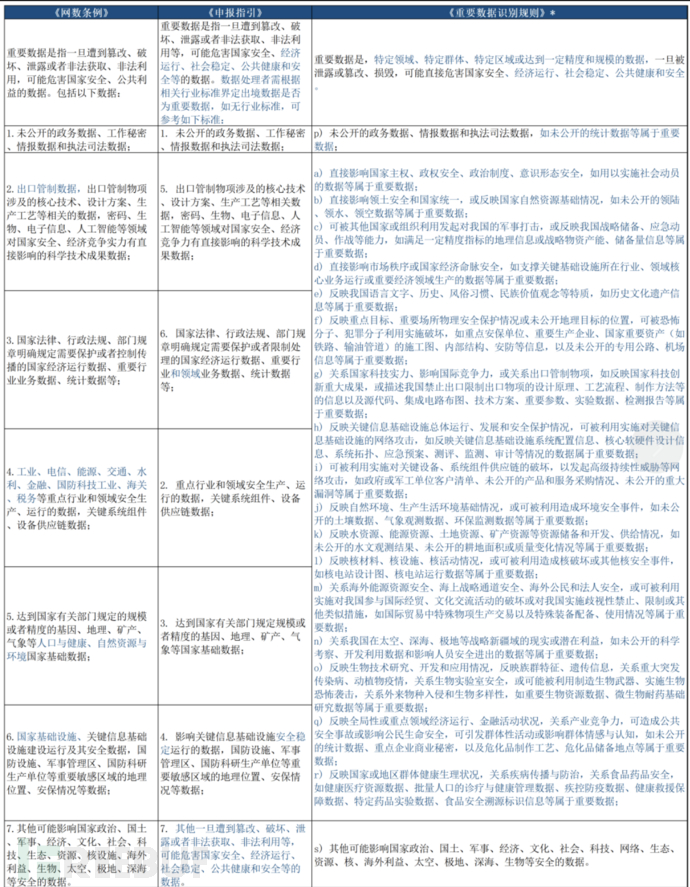
从定义上看,重要数据是指一旦遭到篡改、破坏、泄露或者非法获取、非法利用,可能危害国家安全、经济运行、社会稳定、公共健康和安全的数据;
从范围上看,可通过数据遭到篡改、破坏、泄露或者非法获取、非法利用对“国家政治、国土、军事、经济、文化、社会、科技、生态、资源、核设施、海外利益、生物、太空、极地、深海”等维度的影响程度加以判断;
从识别要素上看,特定领域(如与出口管制物项、关键信息基础设施相关)、特定群体(如与国防科研生产单位相关)、特定区域(如军事管理区)、是否公开(如各规范均已明确“未公开的政务数据、情报数据和执法司法数据”属于重要数据)、是否达到一定精度和规模(如达到一定规模或精度的基因、地理、矿产、气象数据)等作为识别相关数据是否构成重要数据的关键考虑要素。
这里要注意的是重要数据不包括国家秘密、保护级别低于核心数据、一般情况下也不包括个人信息(人信息通过《个人信息保护法》来具体实现)、重要数据也不等同于商业秘密。
对于重要数据的提及主要参考如下:

2. 重要数据识别原则
重要数据识别原则
(1)聚焦安全、重点保护原则
数据流动可以释放数据价值,对数据的保护在一定程度上会阻碍数据流动的速度,应在保障数据安全的前提下,促进数据的流通。通过数据分级分类制度,明确安全保护的重点。重要数据主要从国家安全、公共利益角度考虑,应尽量缩小重要数据的范围。
(2)综合考虑风险原则
根据数据用途、面临的风险等不同因素,考虑数据遭到篡改、破坏、泄露或者非法获取、非法利用等风险,从保密性、完整性、可用性、真实性、准确性等多个角度识别数据的重要性。
(3)定性和定量相结合
采取定性和定量结合的方式,定性识别主要通过评估数据的重要程序及损坏后可能对社会秩序、公共利益和国家安全造成的影响程度来确定是否落入到重要数据的范围。定量识别主要考虑到大量数据聚合分析后可能产生的数据流通性风险。
(4)动态识别原则
数据用途、共享方式、重要性会随着时间的变化而变化,应动态识别重要数据。
3. 识别规则
具体识别这里直接引用“中伦数据团队”整理的表格,已经非常详细了。

如有侵权请联系:admin#unsafe.sh