
02/08/2024
12 min read
It is no secret that Cloudflare is encouraging companies to deprecate their use of IPv4 addresses and move to IPv6 addresses. We have a couple articles on the subject from this year:
- Amazon’s $2bn IPv4 tax – and how you can avoid paying it
- Using DNS to estimate worldwide state of IPv6 adoption
And many more in our catalog. To help with this, we spent time this last year investigating and implementing infrastructure to reduce our internal and egress use of IPv4 addresses. We prefer to re-allocate our addresses than to purchase more due to increasing costs. And in this effort we discovered that our cache service is one of our bigger consumers of IPv4 addresses. Before we remove IPv4 addresses for our cache services, we first need to understand how cache works at Cloudflare.
How does cache work at Cloudflare?
Describing the full scope of the architecture is out of scope of this article, however, we can provide a basic outline:
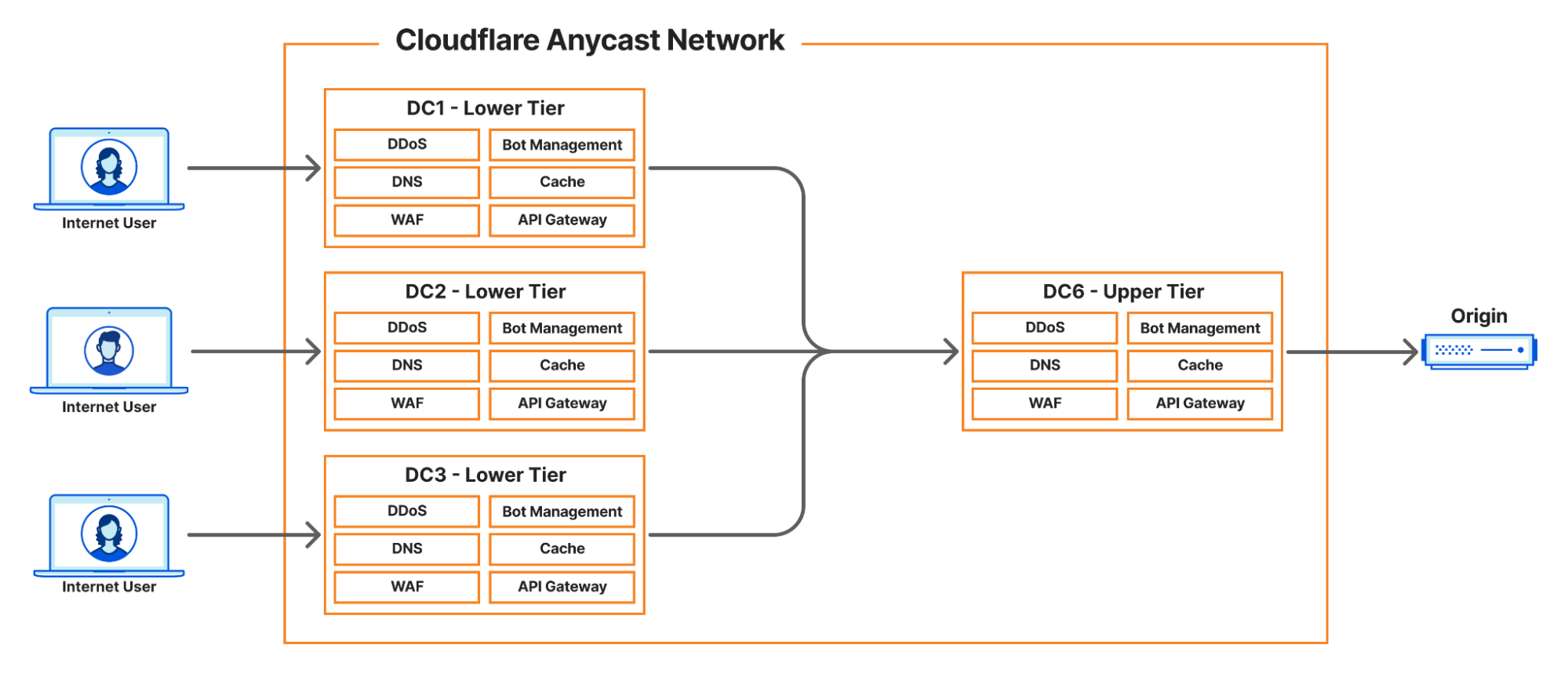
- Internet User makes a request to pull an asset
- Cloudflare infrastructure routes that request to a handler
- Handler machine returns cached asset, or if miss
- Handler machine reaches to origin server (owned by a customer) to pull the requested asset
The particularly interesting part is the cache miss case. When a very popular origin has an uncached asset that many Internet Users are trying to access at once, we may make upwards of:
50k TCP unicast connections to a single destination.
That is a lot of connections! We have strategies in place to limit the impact of this or avoid this problem altogether. But in these rare cases when it occurs, we will then balance these connections over two source IPv4 addresses.
Our goal is to remove the load balancing and prefer one IPv4 address. To do that, we need to understand the performance impact of two IPv4 addresses vs one.
TCP connect() performance of two source IPv4 addresses vs one IPv4 address
We leveraged a tool called wrk, and modified it to distribute connections over multiple source IP addresses. Then we ran a workload of 70k connections over 48 threads for a period of time.
During the test we measured the function tcp_v4_connect() with the BPF BCC libbpf-tool funclatency tool to gather latency metrics as time progresses.
Note that throughout the rest of this article, all the numbers are specific to a single machine with no production traffic. We are making the assumption that if we can improve a worse case scenario in an algorithm with a best case machine, that the results could be extrapolated to production. Lock contention was specifically taken out of the equation, but will have production implications.
Two IPv4 addresses

The y-axis are buckets of nanoseconds in powers of ten. The x-axis represents the number of connections made per bucket. Therefore, more connections in a lower power of ten buckets is better.
We can see that the majority of the connections occur in the fast case with roughly ~20k in the slow case. We should expect this bimodal to increase over time due to wrk continuously closing and establishing connections.
Now let us look at the performance of one IPv4 address under the same conditions.
One IPv4 address

In this case, the bimodal distribution is even more pronounced. Over half of the total connections are in the slow case than in the fast! We may conclude that simply switching to one IPv4 address for cache egress is going to introduce significant latency on our connect() syscalls.
The next logical step is to figure out where this bottleneck is happening.
Port selection is not what you think it is
To investigate this, we first took a flame graph of a production machine:
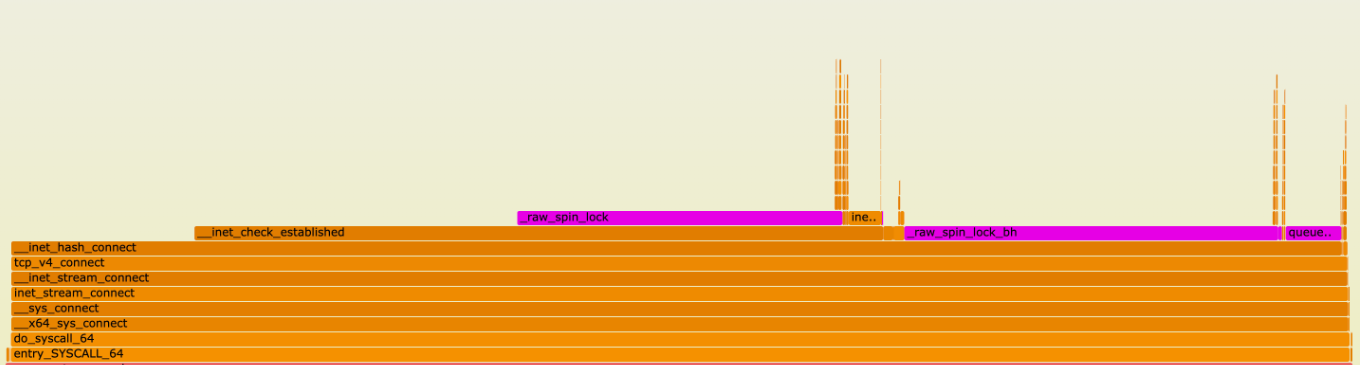
Flame graphs depict a run-time function call stack of a system. Y-axis depicts call-stack depth, and x-axis depicts a function name in a horizontal bar that represents the amount of times the function was sampled. Checkout this in-depth guide about flame graphs for more details.
Most of the samples are taken in the function __inet_hash_connect(). We can see that there are also many samples for __inet_check_established() with some lock contention sampled between. We have a better picture of a potential bottleneck, but we do not have a consistent test to compare against.
Wrk introduces a bit more variability than we would like to see. Still focusing on the function tcp_v4_connect(), we performed another synthetic test with a homegrown benchmark tool to test one IPv4 address. A tool such as stress-ng may also be used, but some modification is necessary to implement the socket option IP_LOCAL_PORT_RANGE. There is more about that socket option later.
We are now going to ensure a deterministic amount of connections, and remove lock contention from the problem. The result is something like this:
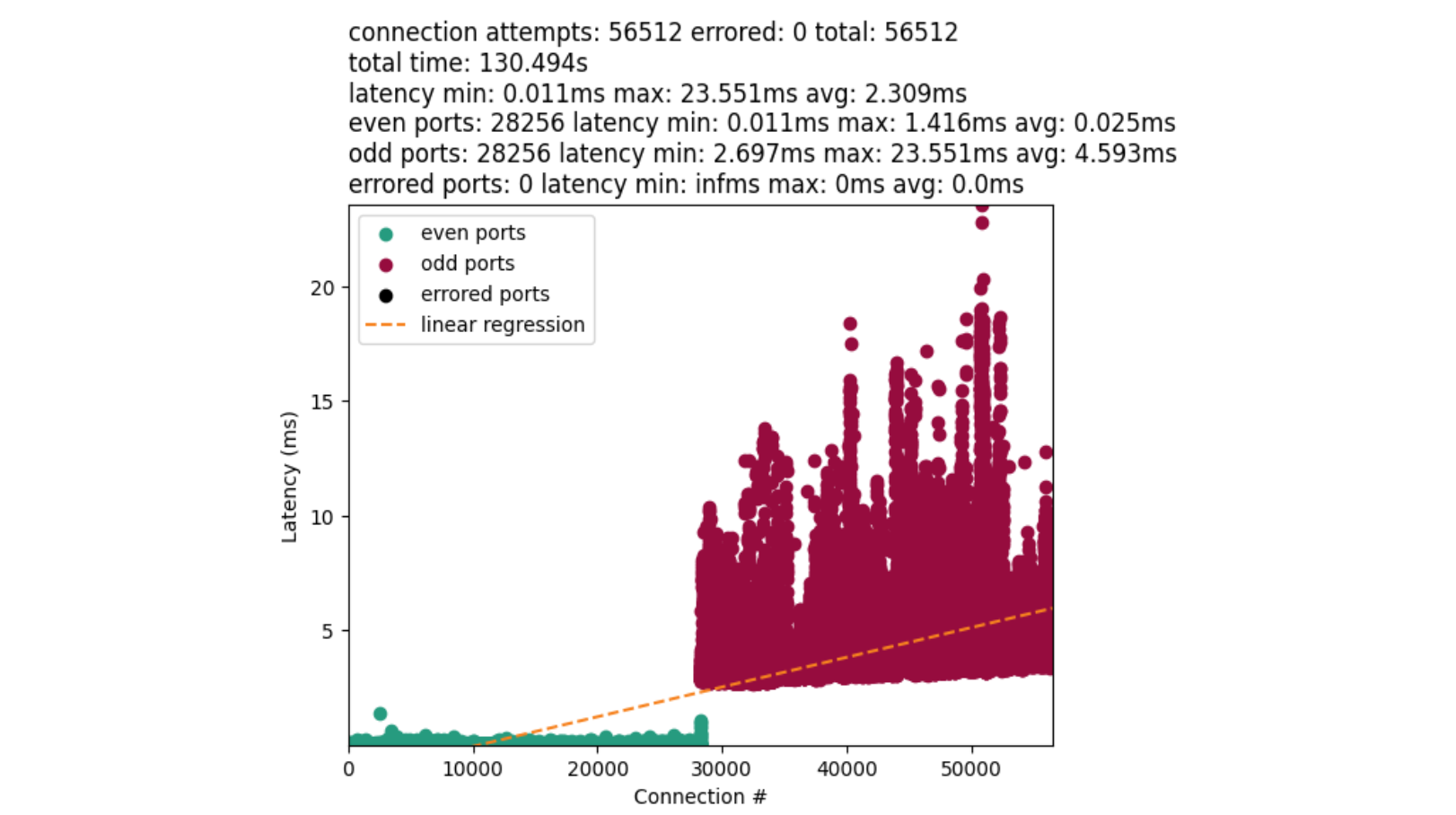
On the y-axis we measured the latency between the start and end of a connect() syscall. The x-axis denotes when a connect() was called. Green dots are even numbered ports, and red dots are odd numbered ports. The orange line is a linear-regression on the data.
The disparity between the average time for port allocation between even and odd ports provides us with a major clue. Connections with odd ports are found significantly slower than the even. Further, odd ports are not interleaved with earlier connections. This implies we exhaust our even ports before attempting the odd. The chart also confirms our bimodal distribution.
__inet_hash_connect()
At this point we wanted to understand this split a bit better. We know from the flame graph and the function __inet_hash_connect() that this holds the algorithm for port selection. For context, this function is responsible for associating the socket to a source port in a late bind. If a port was previously provided with bind(), the algorithm just tests for a unique TCP 4-tuple (src ip, src port, dest ip, dest port) and ignores port selection.
Before we dive in, there is a little bit of setup work that happens first. Linux first generates a time-based hash that is used as the basis for the starting port, then adds randomization, and then puts that information into an offset variable. This is always set to an even integer.
offset &= ~1U;
other_parity_scan:
port = low + offset;
for (i = 0; i < remaining; i += 2, port += 2) {
if (unlikely(port >= high))
port -= remaining;
inet_bind_bucket_for_each(tb, &head->chain) {
if (inet_bind_bucket_match(tb, net, port, l3mdev)) {
if (!check_established(death_row, sk, port, &tw))
goto ok;
goto next_port;
}
}
}
offset++;
if ((offset & 1) && remaining > 1)
goto other_parity_scan;
Then in a nutshell: loop through one half of ports in our range (all even or all odd ports) before looping through the other half of ports (all odd or all even ports respectively) for each connection. Specifically, this is a variation of the Double-Hash Port Selection Algorithm. We will ignore the bind bucket functionality since that is not our main concern.
Depending on your port range, you either start with an even port or an odd port. In our case, our low port, 9024, is even. Then the port is picked by adding the offset to the low port:
port = low + offset;
If low was odd, we will have an odd starting port because odd + even = odd.
There is a bit too much going on in the loop to explain in text. I have an example instead:
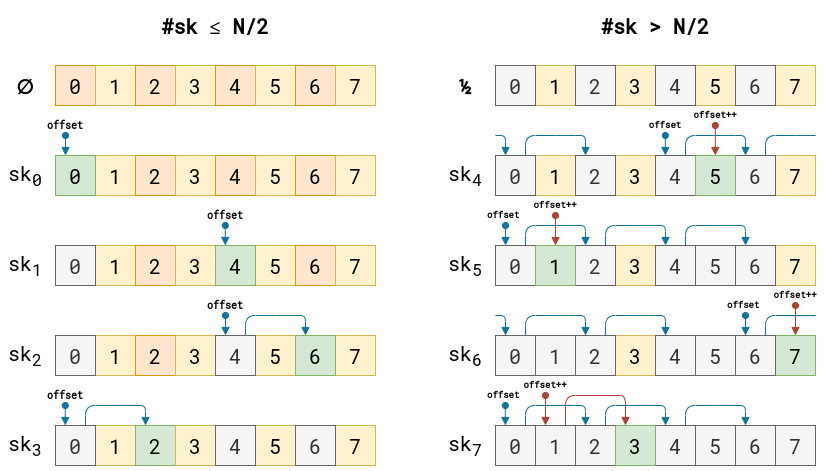
This example is bound by 8 ports and 8 possible connections. All ports start unused. As a port is used up, the port is grayed out. Green boxes represent the next chosen port. All other colors represent open ports. Blue arrows are even port iterations of offset, and red are the odd port iterations of offset. Note that the offset is randomly picked, and once we cross over to the odd range, the offset is incremented by one.
For each selection of a port, the algorithm then makes a call to the function check_established() which dereferences __inet_check_established(). This function loops over sockets to verify that the TCP 4-tuple is unique. The takeaway is that the socket list in the function is usually smaller than not. This grows as more unique TCP 4-tuples are introduced to the system. Longer socket lists may slow down port selection eventually. We have a blog post that dives into the socket list and port uniqueness criteria.
At this point, we can summarize that the odd/even port split is what is causing our performance bottleneck. And during the investigation, it was not obvious to me (or even maybe you) why the offset was initially calculated the way it was, and why the odd/even port split was introduced. After some git-archaeology the decisions become more clear.
Security considerations
Port selection has been shown to be used in device fingerprinting in the past. This led the authors to introduce more randomization into the initial port selection. Prior, ports were predictably picked solely based on their initial hash and a salt value which does not change often. This helps with explaining the offset, but does not explain the split.
Why the even/odd split?
Prior to this patch and that patch, services may have conflicts between the connect() and bind() heavy workloads. Thus, to avoid those conflicts, the split was added. An even offset was chosen for the connect() workloads, and an odd offset for the bind() workloads. However, we can see that the split works great for connect() workloads that do not exceed one half of the allotted port range.
Now we have an explanation for the flame graph and charts. So what can we do about this?
User space solution (kernel < 6.8)
We have a couple of strategies that would work best for us. Infrastructure or architectural strategies are not considered due to significant development effort. Instead, we prefer to tackle the problem where it occurs.
Select, test, repeat
For the “select, test, repeat” approach, you may have code that ends up looking like this:
sys = get_ip_local_port_range()
estab = 0
i = sys.hi
while i >= 0:
if estab >= sys.hi:
break
random_port = random.randint(sys.lo, sys.hi)
connection = attempt_connect(random_port)
if connection is None:
i += 1
continue
i -= 1
estab += 1
The algorithm simply loops through the system port range, and randomly picks a port each iteration. Then test that the connect() worked. If not, rinse and repeat until range exhaustion.
This approach is good for up to ~70-80% port range utilization. And this may take roughly eight to twelve attempts per connection as we approach exhaustion. The major downside to this approach is the extra syscall overhead on conflict. In order to reduce this overhead, we can consider another approach that allows the kernel to still select the port for us.
Select port by random shifting range
This approach leverages the IP_LOCAL_PORT_RANGE socket option. And we were able to achieve performance like this:
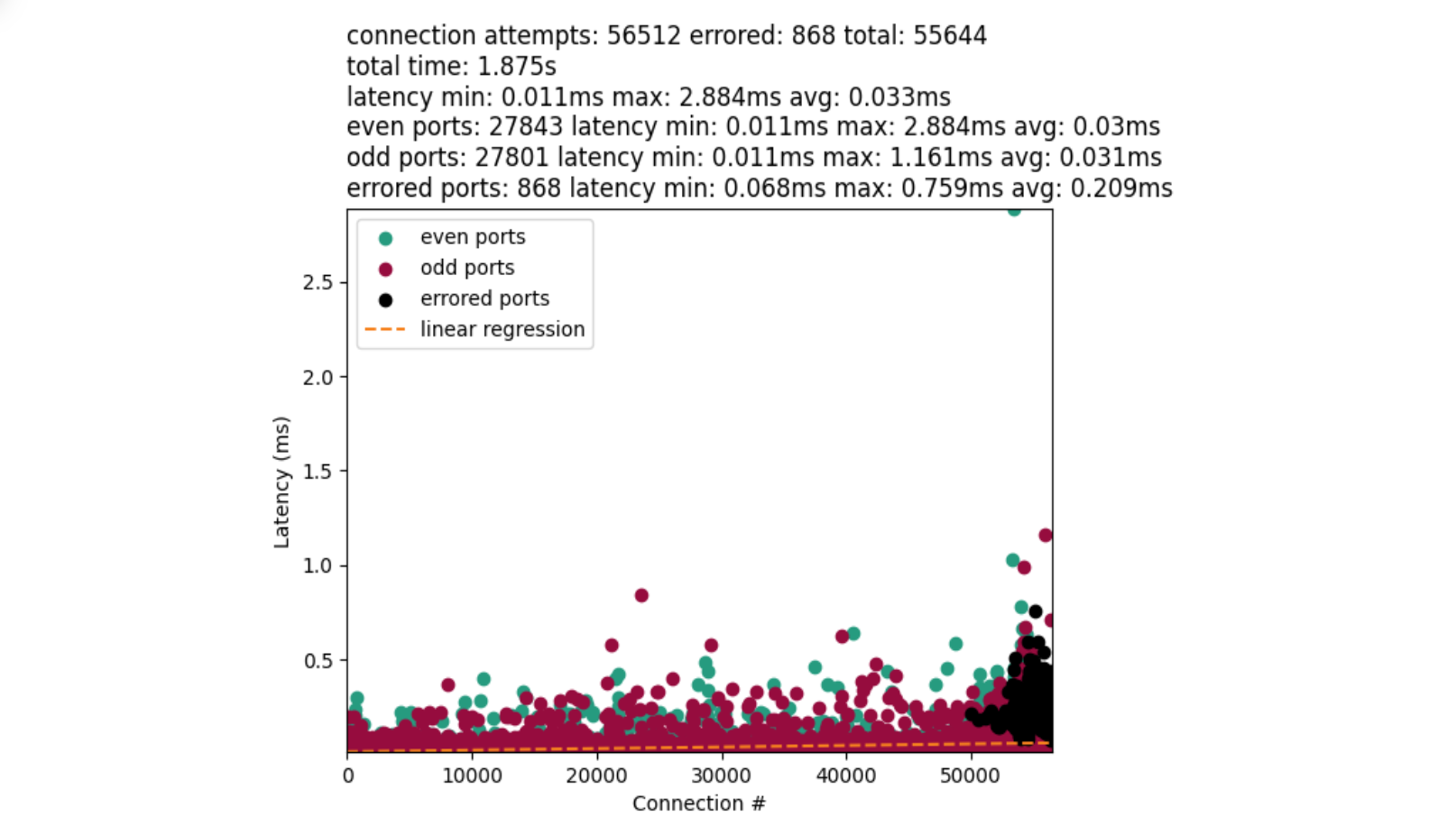
That is much better! The chart also introduces black dots that represent errored connections. However, they have a tendency to clump at the very end of our port range as we approach exhaustion. This is not dissimilar to what we may see in “select, test, repeat”.
The way this solution works is something like:
IP_BIND_ADDRESS_NO_PORT = 24
IP_LOCAL_PORT_RANGE = 51
sys = get_local_port_range()
window.lo = 0
window.hi = 1000
range = window.hi - window.lo
offset = randint(sys.lo, sys.hi - range)
window.lo = offset
window.hi = offset + range
sk = socket(AF_INET, SOCK_STREAM)
sk.setsockopt(IPPROTO_IP, IP_BIND_ADDRESS_NO_PORT, 1)
range = pack("@I", window.lo | (window.hi << 16))
sk.setsockopt(IPPROTO_IP, IP_LOCAL_PORT_RANGE, range)
sk.bind((src_ip, 0))
sk.connect((dest_ip, dest_port))
We first fetch the system's local port range, define a custom port range, and then randomly shift the custom range within the system range. Introducing this randomization helps the kernel to start port selection randomly at an odd or even port. Then reduces the loop search space down to the range of the custom window.
We tested with a few different window sizes, and determined that a five hundred or one thousand size works fairly well for our port range:
| Window size | Errors | Total test time | Connections/second |
|---|---|---|---|
| 500 | 868 | ~1.8 seconds | ~30,139 |
| 1,000 | 1,129 | ~2 seconds | ~27,260 |
| 5,000 | 4,037 | ~6.7 seconds | ~8,405 |
| 10,000 | 6,695 | ~17.7 seconds | ~3,183 |
As the window size increases, the error rate increases. That is because a larger window provides less random offset opportunity. A max window size of 56,512 is no different from using the kernels default behavior. Therefore, a smaller window size works better. But you do not want it to be too small either. A window size of one is no different from “select, test, repeat”.
In kernels >= 6.8, we can do even better.
Kernel solution (kernel >= 6.8)
A new patch was introduced that eliminates the need for the window shifting. This solution is going to be available in the 6.8 kernel.
Instead of picking a random window offset for setsockopt(IPPROTO_IP, IP_LOCAL_PORT_RANGE, …), like in the previous solution, we instead just pass the full system port range to activate the solution. The code may look something like this:
IP_BIND_ADDRESS_NO_PORT = 24
IP_LOCAL_PORT_RANGE = 51
sys = get_local_port_range()
sk = socket(AF_INET, SOCK_STREAM)
sk.setsockopt(IPPROTO_IP, IP_BIND_ADDRESS_NO_PORT, 1)
range = pack("@I", sys.lo | (sys.hi << 16))
sk.setsockopt(IPPROTO_IP, IP_LOCAL_PORT_RANGE, range)
sk.bind((src_ip, 0))
sk.connect((dest_ip, dest_port))
Setting IP_LOCAL_PORT_RANGE option is what tells the kernel to use a similar approach to “select port by random shifting range” such that the start offset is randomized to be even or odd, but then loops incrementally rather than skipping every other port. We end up with results like this:
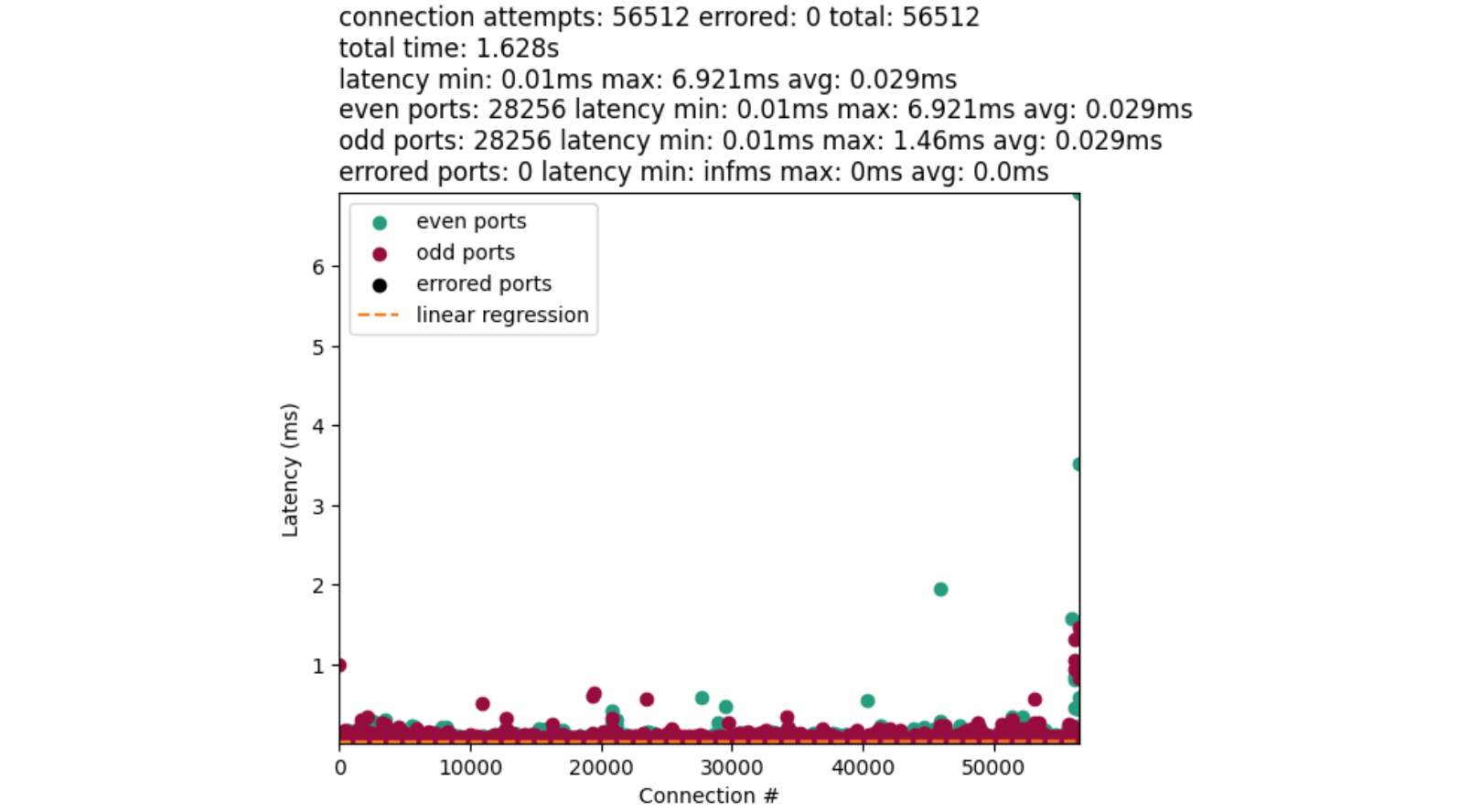
The performance of this approach is quite comparable to our user space implementation. Albeit, a little faster. Due in part to general improvements, and that the algorithm can always find a port given the full search space of the range. Then there are no cycles wasted on a potentially filled sub-range.
These results are great for TCP, but what about other protocols?
Other protocols & connect()
It is worth mentioning at this point that the algorithms used for the protocols are mostly the same for IPv4 & IPv6. Typically, the key difference is how the sockets are compared to determine uniqueness and where the port search happens. We did not compare performance for all protocols. But it is worth mentioning some similarities and differences with TCP and a couple of others.
DCCP
The DCCP protocol leverages the same port selection algorithm as TCP. Therefore, this protocol benefits from the recent kernel changes. It is also possible the protocol could benefit from our user space solution, but that is untested. We will let the reader exercise DCCP use-cases.
UDP & UDP-Lite
UDP leverages a different algorithm found in the function udp_lib_get_port(). Similar to TCP, the algorithm will loop over the whole port range space incrementally. This is only the case if the port is not already supplied in the bind() call. The key difference between UDP and TCP is that a random number is generated as a step variable. Then, once a first port is identified, the algorithm loops on that port with the random number. This relies on an uint16_t overflow to eventually loop back to the chosen port. If all ports are used, increment the port by one and repeat. There is no port splitting between even and odd ports.
The best comparison to the TCP measurements is a UDP setup similar to:
sk = socket(AF_INET, SOCK_DGRAM)
sk.bind((src_ip, 0))
sk.connect((dest_ip, dest_port))
And the results should be unsurprising with one IPv4 source address:
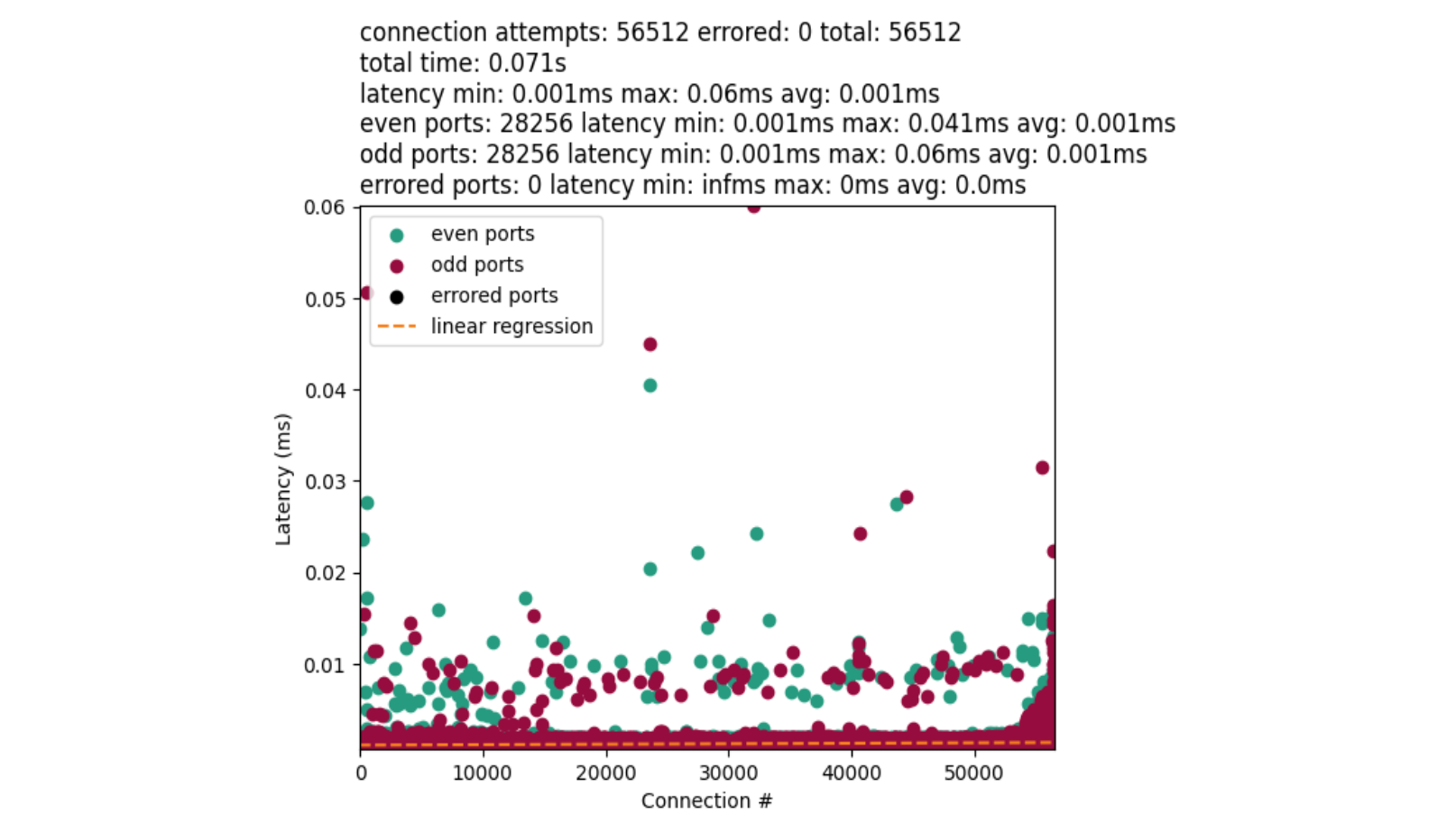
UDP fundamentally behaves differently from TCP. And there is less work overall for port lookups. The outliers in the chart represent a worst-case scenario when we reach a fairly bad random number collision. In that case, we need to more-completely loop over the ephemeral range to find a port.
UDP has another problem. Given the socket option SO_REUSEADDR, the port you get back may conflict with another UDP socket. This is in part due to the function udp_lib_lport_inuse() ignoring the UDP 2-tuple (src ip, src port) check given the socket option. When this happens you may have a new socket that overwrites a previous. Extra care is needed in that case. We wrote more in depth about these cases in a previous blog post.
In summary
Cloudflare can make a lot of unicast egress connections to origin servers with popular uncached assets. To avoid port-resource exhaustion, we balance the load over a couple of IPv4 source addresses during those peak times. Then we asked: “what is the performance impact of one IPv4 source address for our connect()-heavy workloads?”. Port selection is not only difficult to get right, but is also a performance bottleneck. This is evidenced by measuring connect() latency with a flame graph and synthetic workloads. That then led us to discovering TCP’s quirky port selection process that loops over half your ephemeral ports before the other for each connect().
We then proposed three solutions to solve the problem outside of adding more IP addresses or other architectural changes: “select, test, repeat”, “select port by random shifting range”, and an IP_LOCAL_PORT_RANGE socket option solution in newer kernels. And finally closed out with other protocol honorable mentions and their quirks.
Do not take our numbers! Please explore and measure your own systems. With a better understanding of your workloads, you can make a good decision on which strategy works best for your needs. Even better if you come up with your own strategy!
We protect entire corporate networks, help customers build Internet-scale applications efficiently, accelerate any website or Internet application, ward off DDoS attacks, keep hackers at bay, and can help you on your journey to Zero Trust.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you're looking for a new career direction, check out our open positions.