2024-2-1 22:26:58 Author: securityboulevard.com(查看原文) 阅读量:7 收藏
Data lakes are a popular solution for data storage, and for good reason. Data lakes are flexible and cost effective, as they allow multiple query engines and many object formats without the need to manage resources like disks, CPUs, and memory. In a data lake, data is simply stored in an object store, and you can use a managed query engine for a complete pay-per-usage solution.
With terabytes of compressed data added every day by automated processes, and with hundreds of users adding more data, regular cleanup of unused data is a must-have process.
Before deleting unused data, you first need to monitor the data lake’s usage. This can be a real challenge. The object store has millions of objects. The metastore has thousands of tables. There are multiple query engines, and it is also possible to access data directly through the object store. Monitoring this vast amount of data is tricky and can be expensive, so we set out to develop a method to collect usage data in an efficient way.
We wanted to monitor the usage of the data lake tables. We decided to store the log history from the different engines, and use this data to monitor our data lake tables usage. The usage data was used to find unused tables, which helped us to get to a cleanup process. Using this process saves us in storage costs, reduces the data lake attack surface and gives us a cleaner work environment.
In this blog post, you’ll learn about data lake table usage monitoring and cleanup. Code snippets are included to help you monitor your own tables.
How to Monitor Query Engine Usage
Data lakes are flexible and allow you to use multiple query engines, such as Apache Spark,Trino, and others. Collecting usage data requires effort for each individual engine, and the collected data differs from one engine to another, but it’s important to monitor all access options. As an example, you can read how we monitored AWS Athena usage.
Once the usage data is stored and accessible, it is possible to monitor the data lake’s objects usage to detect access patterns, perform cost analysis, monitor user access, and more.
As an example, below is a table usage query which can be used if you want to identify potential unused tables and objects for removal. We used the internal information_schema to query the list of tables from the metastore and our own data_lake_audit table which has daily partition, user, and query columns:
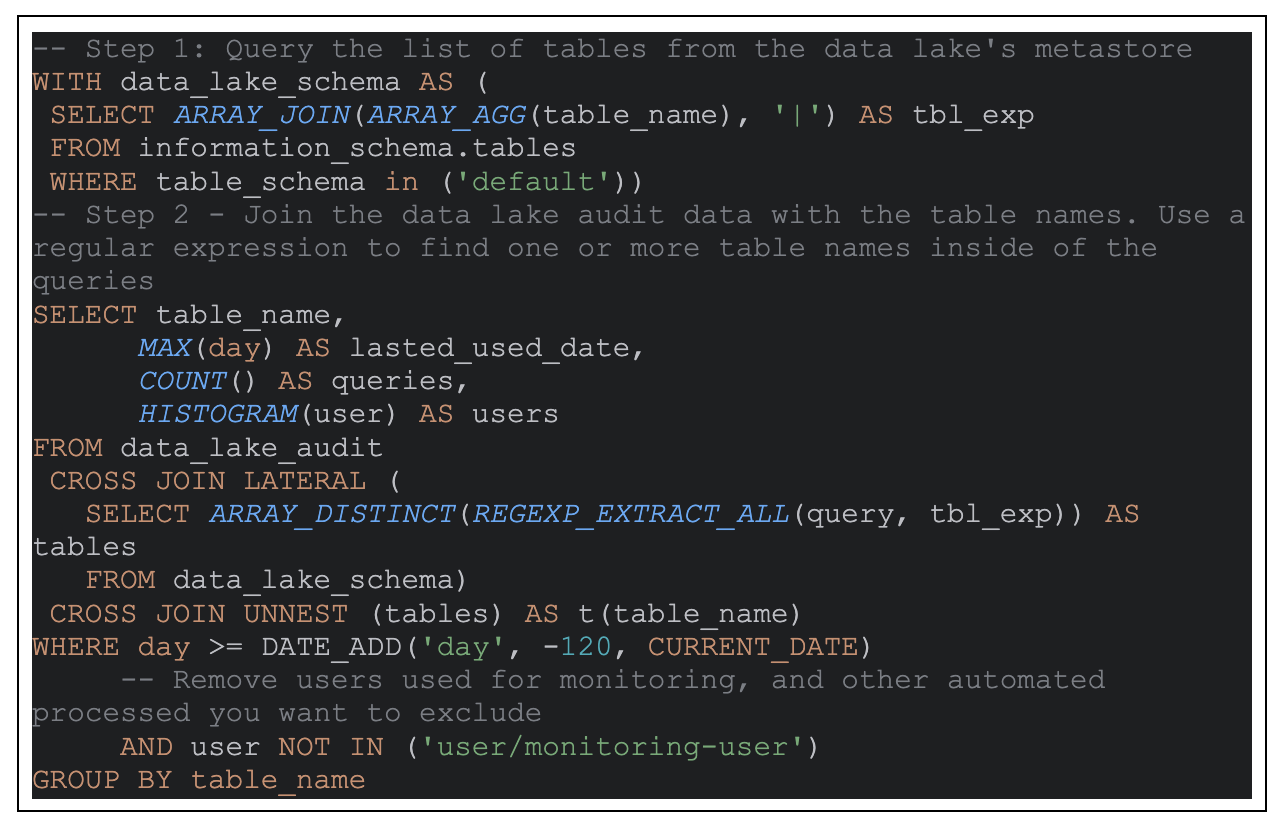
Below is an example of the results from the query. You can find the last time a table was used, the number of queries in the given period, and the usage distribution by users:
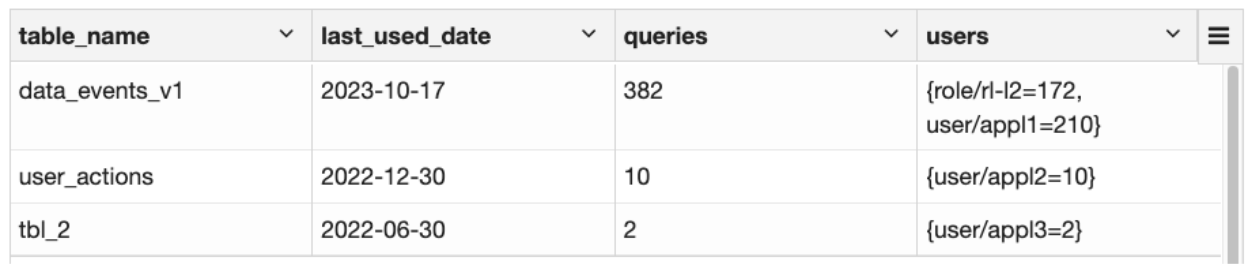
Table usage query results example
We recommend running an ETL (Extract-Transform-Load) process which performs a similar query and writing the results, which is the tables access log, to a dedicated table. Once you have such a table, you can monitor the usage continuously and report alerts on anomalies and unused tables.
Collecting Information About Unused Data
After detecting unused tables, you should collect information to decide if you can remove any of the data. As an example, for tables we create based on ETL processes, we join the data with our infrastructure data to get the average daily size of data entering the data lake. This allows us to focus on the tables with higher resource consumption.
Another example of data we can collect about unused tables is the size of the tables, number of objects, and when the data was last updated. Below is an example of how we collect such info from an AWS S3 object store using Python:
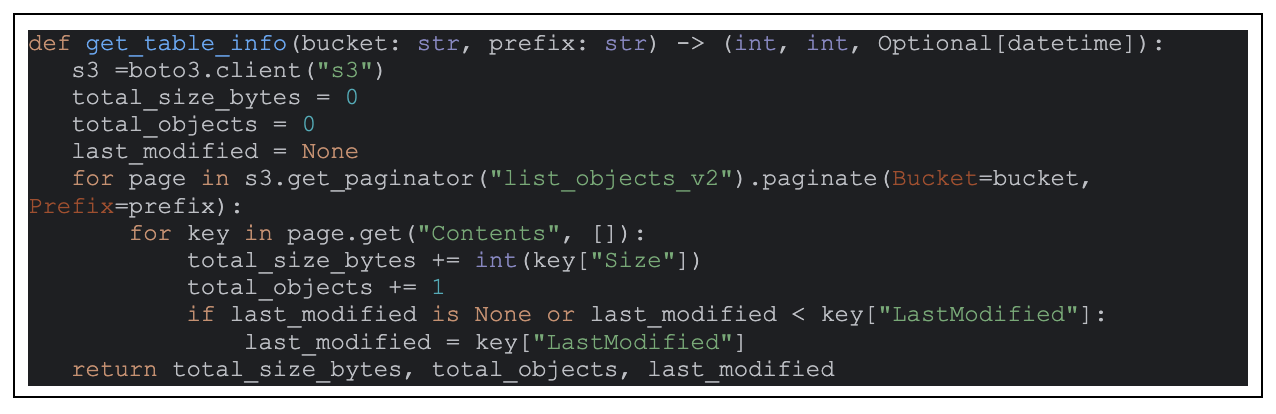
The python function gets an object store location and returns information about it.
The additional information we collect on unused tables, like the resource consumption and last modification time, helps us to focus on the heavier tables and to decide if we can remove data.
Takeaway
Monitoring data lake usage is an important task. Data lakes can be accessed using multiple query engines, which makes monitoring a complex task. Using the monitoring data we collected, we detected unused tables and removed hundreds of them. We sent informative alerts on unused tables, which were removed as part of our operation.
We were able to understand our operation, save costs, reduce the attack surface, and work in a cleaner environment. If you want to do it on your own data lake, you have to understand how your data is being accessed, audit your data access, and finally implement usage monitoring.
The post Optimizing Data Lakes: Streamlining Storage with Effective Object Management appeared first on Blog.
*** This is a Security Bloggers Network syndicated blog from Blog authored by Ori Nakar. Read the original post at: https://www.imperva.com/blog/optimizing-data-lakes-with-effective-object-management/
如有侵权请联系:admin#unsafe.sh