An Intro to Kafka and RabbitMQ: The Masters of MessagingIn the realm of messaging systems, tw 2024-1-30 21:58:36 Author: lab.wallarm.com(查看原文) 阅读量:46 收藏
An Intro to Kafka and RabbitMQ: The Masters of Messaging
In the realm of messaging systems, two names stand out: Kafka and RabbitMQ. These two powerhouses have become the go-to solutions for developers and organizations looking to handle high-volume, real-time data processing and messaging. But what are they, and how do they differ? Let's dive in.
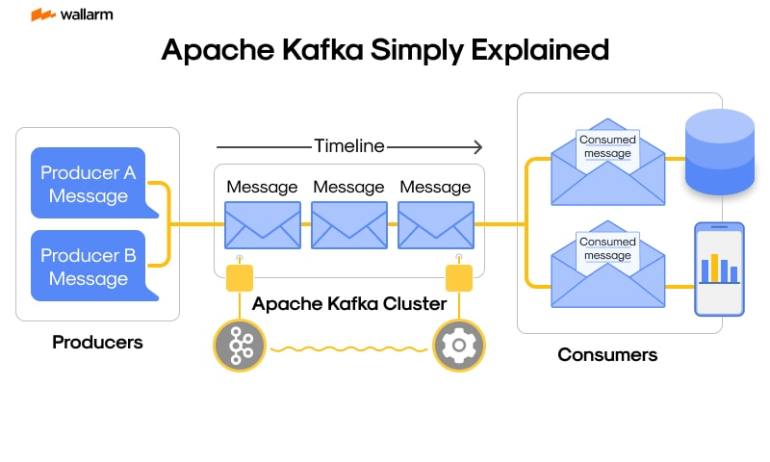
Apache Kafka, first developed by LinkedIn, is a distributed streaming platform designed to handle real-time data feeds with high throughput and low latency. It's like a highway for data, enabling the transport of massive amounts of information from producers to consumers in near real-time. Kafka's architecture is built around topics (data streams), producers (data generators), and consumers (data processors).
Here's a simple example of a Kafka producer:
<code class="language-java">import org.apache.kafka.clients.producer.*;
public class KafkaProducerExample {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++)
producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i), Integer.toString(i)));
producer.close();
}
}</code>
On the other hand, RabbitMQ is a message broker that supports multiple messaging protocols. It's like a post office for your data, accepting messages from producers and routing them to the correct consumers. RabbitMQ's architecture is built around exchanges (message routers), queues (message buffers), and bindings (rules for routing messages).
Here's a simple example of a RabbitMQ producer using Python:
<code class="language-python">import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello')
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!')
print(" [x] Sent 'Hello World!'")
connection.close()</code>
While both Kafka and RabbitMQ are designed to handle messaging, they approach the problem in different ways. Kafka is optimized for high-volume data streaming, while RabbitMQ is more versatile, supporting a variety of messaging patterns including request/reply, fanout, and topic-based routing.
| Feature | Kafka | RabbitMQ |
|---|---|---|
| Messaging Patterns | Publish/Subscribe, Point-to-Point | Publish/Subscribe, Point-to-Point, Request/Reply, Fanout |
| Message Durability | Yes | Yes |
| Message Ordering | Yes | Yes |
| Message Routing | Basic | Advanced |
| Transactional Messaging | Yes | Yes |
| Distributed Processing | Yes | Yes |
In the following chapters, we'll delve deeper into the features, benefits, and limitations of Kafka and RabbitMQ, as well as real-world performance comparisons and case studies. By the end, you should have a solid understanding of Kafka vs RabbitMQ and be able to make an informed decision on which is the best fit for your needs.
Delineating the Characteristics: A Contrastive Study of Kafka and RabbitMQ
In the wide sphere of messaging-based architectural patterns, Apache Kafka and RabbitMQ are two distinguished platforms that have been garnering considerable attention. Both are built on open-source technologies and widely used in many industries. Despite sharing commonalities, each platform exhibits distinct capabilites. In this chapter, we will navigate through the primary features of these tools, thus facilitating an extensive contrastive study. This exercise will help discern the distinctive merits and possible constraints of both platforms.
1. System Structure
Kafka exhibits a decentralised design, exclusively formulated to handle large-scale data-stream operations. It aligns with the publisher-subscriber paradigm, using 'topics' as repositories for messages. Participants who supply data to these 'topics' are called producers, while those who extract data are labelled as consumers. The design of Kafka is optimized for immediate data transfer, ensuring minimum latency and optimal results.
In comparison, RabbitMQ, a time-honoured message broker, exploits the Advanced Message Queuing Protocol (AMQP). It aligns with various messaging protocols and supports dynamic flow of messages to queues. RabbitMQ's architecture is versatile, enabling diverse messaging approaches such as request/reply, direct, and publisher/subscriber.
2. Data Propagation
Kafka embodies a data delivery guarantee as a foundational aspect. Possessing a flexible record log, it permits consumers to regulate the pace of data management. This feature renders Kafka fit for stream processing environments.
Conversely, RabbitMQ maintains either a maximum-once or a minimum-once delivery assurance. The receipt of messages is confirmed and there is also an option to store messages on disk. This distinctive aspect makes RabbitMQ ideal for scenarios where the delivery of messages is of paramount importance.
3. Stability and Permanance
Kafka excels in ensuring data permanance and system stability. Data is duplicated across numerous nodes to prevent any data loss and can customize the number of confirmations needed for a successful data write operation by any producer.
RabbitMQ fosters data permanance by preserving it on disk. It supports clustering and configurations that maximize availability to ensure successful message delivery even during failover situations.
4. Scalability
Kafka is built with inherent scalability, utilizing its decentralized model for capacity expansion. It processes colossal volumes of real-time data while maintaining negligible latency. Additionally, features like log compression and data retention enhance its storage management efficiency.
Conversely, RabbitMQ offers the ability to optimize its performance both vertically and horizontally. It supports clustering and offers an array of strategies for efficient dispersion of load across nodes.
5. Operational Application
Kafka's exceptional architecture and concepts may present hurdles during the initial learning phase. However, a robust API and a mature tool-based ecosystem compensate for the complexity.
RabbitMQ offers a more amicable learning curve, accompanied by an easily navigable console for management and comprehensive support for client libraries and enhancements.
Outlined below is a grid that outlines the features of Kafka and RabbitMQ:

In sum, both Kafka and RabbitMQ provide unique propositions. While Kafka shines in managing brisk, real-time data processing, RabbitMQ is well-known for its flexibility and user-friendly demeanor. Therefore, the specifics of your use-case and prerequisites would guide your choice between Kafka and RabbitMQ.
`
`
Unraveling RabbitMQ: Evaluating its Benefits and Flaws

In the vast expanse of systems meant for manipulating data, RabbitMQ frequently lands in the top tier. Acclaimed for its efficiency, interactive abilities, and sturdy performance, RabbitMQ is an open-source instrument that quietly carries out its role. Yet, similar to all tech tools, it has its asset and liabilities, which we will examine in-depth in this critique.
Key Features of RabbitMQ:
1. Easy-to-use Setup: A dimension where RabbitMQ shines is its clear-cut configuration approach. It provides a user-friendly dashboard that streamlines the organization of messaging routes, exchanges and links.
<code class="language-bash"># Setting up RabbitMQ sudo apt-get install rabbitmq-server # Bringing RabbitMQ server to life sudo service rabbitmq-server start # Launching management interface sudo rabbitmq-plugins enable rabbitmq_management</code>
2. Wide-ranging Protocol Integration: RabbitMQ is adept at integrating an array of communication protocols, with AMQP, MQTT, and STOMP being the prominent ones. This bolsters its versatility, making it a favored tool across numerous applications.
<code class="language-python"># Python script for sending messages using AMQP protocol import pika connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() channel.queue_declare(queue='hello') channel.basic_publish(exchange='', routing_key='hello', body='Hello, World!') print(" [x] Dispatched 'Hello, World!'") connection.close()</code>
3. Reliability: Aspects like persistent messages, acknowledgment of receipt, and sender validations are integrated into RabbitMQ to ensure trouble-free operations during message delivery.
4. Diverse Scaling: RabbitMQ houses both clustering and federation features, facilitating the extension of your messaging infrastructure over numerous domains for enhanced accessibility and equilibrium.
5. Adaptable Transmission: RabbitMQ enables users to employ exchanges and links to devise intricate conveying mechanisms.
Projectable Challenges with RabbitMQ:
1. Data Transfer Speed Constraints: Although RabbitMQ excels in catering to diverse applications, it might falter when faced with high-demanding data transfer scenarios. This highlights the need for high-performance substitutes like Kafka.
2. Managing Disk Space: Being a tool that stores messages in memory as well as hard disk, RabbitMQ necessitates meticulous maintenance to prevent unchecked exhaustion of disk space.
3. Excessive Memory Utilization: Processing a large number of messages in RabbitMQ can exhaust memory significantly, jeopardizing operations in environments with tight memory margins.
4. Lack of Message Ordering System: RabbitMQ falls short in providing innate message sequencing functionality, pressuring applications that heavily rely on this capability to script additional code.
5. Scaling Dilemmas: While RabbitMQ functions sufficiently on smaller scales, expansion to larger magnitudes may cause certain hiccups, especially when dealing with a variety of routes and connections.
Wrapping up, given its blend of features and versatility, RabbitMQ holds its ground as a viable choice for data handling across multiple applications. However, its unique set of challenges calls for careful exploration. Balancing these variables when selecting a messaging solution can guide you towards the most fitting choice for your needs. Keep an eye out for our forthcoming appraisal wherein we dissect the pros and cons of Kafka.
Peeling back the layers of Kafka: Exploring the Potentials and Pains of Kafka

Identified as a titan in the field of message transmission systems, Apache Kafka has decidedly chiseled its niche in the present-day technological galaxy, given its multifaceted proficiencies. Kafka, akin to any tech system, introduces its individual blend of elements and caves. This dissection involves an exploration into Kafka’s traits, and aims to provide an exhaustive comprehension of its positives and negatives, arming you with the knowledge necessary to assess its suitability for your individual needs.
Unraveling Kafka's Powers
1. Potent Data Stream Management: Kafka is engineered to control massive, real-time data surges. Exhibiting its impressive strength in processing countless messages every second with insignificant delay, Kafka commonly becomes the top pick for apps wrestling with considerable amounts of data.
<code class="language-java">Properties setProps = new Properties();
setProps.put("bootstrap.servers", "localhost:9092");
setProps.put("acks", "all");
setProps.put("delivery.timeout.ms", 30000);
setProps.put("batch.size", 16384);
setProps.put("linger.ms", 1);
setProps.put("buffer.memory", 33554432);
setProps.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
setProps.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(setProps);
for(int i = 0; i < 1000000; i++)
producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i), Integer.toString(i)));
producer.close();</code>
The Java code fragment above effectively illustrates Kafka's capability to handle an influx of messages routed to a specified topic, thus highlighting the impressive data handling prowess of Kafka.
2. Scalability: Owing to its inherent decentralized structure, Kafka can broaden its scale by integrating more nodes into its cluster, thereby facilitating a smooth accommodation of growing data streams.
3. Resilience and Reliability: Kafka guarantees robustness against mishaps by preserving data on disk and replicating it across different brokers, thus ensuring no data is lost, even when a broker fails.
4. Rapid Data Processing: The speedy processing capability of Kafka makes it a prime choice for handling real-time data, an essential aspect of current software apps.
Addressing Kafka's Hiccups
1. Complexity: Mastering Kafka's extensive, potent features is no picnic. Initiating and monitoring the Kafka clusters require a deep grasp of its structure and configuration specifics.
2. Insufficient Message-Level Security: The default Kafka setup falls short in offering granular security for each message. Despite having SSL/TLS for data encryption and SASL for client authentication, protecting every message necessitates additional efforts.
3. Simplistic Message Distribution: Kafka doesn’t have the advanced message distribution abilities found in systems like RabbitMQ. It relies on a plain topic-oriented structure, which may not suffice for apps needing complex distribution systems.
4. Resource-Hungry: Kafka can be intensive in terms of its resource requirements, particularly memory and disk space. This could pose problems for smaller entities or apps functioning within resource constraints.
In conclusion, Kafka stands out for its capabilities in managing large-scale data transfer, scalablity, resilience, and swift processing. However, complexities with setup, less-than-ideal message-level security, basic message dispersal, and resource-heavy needs can act as potential obstacles. An in-depth grasp of these elements is crucial in understanding whether Kafka fits your messaging needs.
In-depth Examination of Proficiency - Comparing RabbitMQ and Kafka
The field of messaging-powered middleware systems presents a dynamic duel between two crucial contenders - RabbitMQ and Apache Kafka. This chapter will embark on an intricate inquiry into different performance metrics of RabbitMQ and Kafka. This support will come from substantiated data, elucidative code samples, and a critical comparative analysis.
1. Messaging Processing Potential
An essential measure of a middleware messaging service's performance is its ability, also known as throughput, to manage a number of notifications within a specific duration.
Designed for handling extensive event streaming, Apache Kafka excels in this vital performance parameter. It proficiently processes countless messages by leveraging its distributed design and disk-based storage. The following code snip gives a demonstration of Kafka's unparalleled throughput:
<code class="language-java">Properties properties = new Properties();
properties.put("bootstrap.servers", "localhost:9092");
properties.put("acks", "all");
properties.put("delivery.timeout.ms", 30000);
properties.put("batch.size", 16384);
properties.put("linger.ms", 1);
properties.put("buffer.memory", 33554432);
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(properties);
for(int i = 0; i < 1000000; i++)
producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i), Integer.toString(i)));
producer.close();</code>
Conversely, while RabbitMQ may not achieve a throughput level as pronounced as Kafka's, its caliber should not be underestimated. Depending on the utilized hardware and settings, RabbitMQ can proficiently handle thousands to tens of thousands of messages per second. The following code clip illustrates this:
<code class="language-python">import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
for i in range(100000):
message = str(i)
channel.basic_publish(
exchange='',
routing_key='task_queue',
body=message,
properties=pika.BasicProperties(
delivery_mode=2, # make message persistent
))
print(" [x] Sent %r" % message)</code>
2. Message Transit Time
Latency - the time taken for a notification to traverse from its origin to the destination - plays a considerable role in determining the efficiency of a messaging system.
Devised to tackle messages in batches to enhance efficiency, Apache Kafka's design may contribute to minor lags. However, these delays are usually minuscule, confined within a few milliseconds.
In contrast, RabbitMQ trumps Kafka in this facet by facilitating almost immediate message delivery. This makes it a viable choice for applications necessitating real-time updates.
3. Scalability
RabbitMQ and Kafka both boast scalable designs, although the two employ varying strategies.
Kafka's scalability can be escalated horizontally by increasing the number of brokers in a Kafka cluster, thereby enhancing its message-handling capacity. This makes it an excellent choice for dealing with sizeable message volumes.
Conversely, RabbitMQ implements a more conventional vertical scalability approach. Enhancing the server's hardware empowers RabbitMQ with superior message-processing abilities.
4. Reliability
Both RabbitMQ and Kafka offer a shared characteristic of reliable message delivery. They assure that no messages are misplaced during any system disturbance.
Kafka safeguards messages by storing them on the disk and creating multiple broker replicas. This ensures that even in the event of a single broker crash, the messages remain secure.
In the same vein, RabbitMQ also ensures messages' safety by storing them on disk. However, it’s noteworthy that high message traffic could cause a slight dip in RabbitMQ's performance.
In conclusion, both Kafka and RabbitMQ display formidable performance in their standout areas. Kafka outperforms in high-throughput and scalable environments, whereas RabbitMQ shines brightest in situations demanding low-latency and immediate interactivity. The final selection between the two would hinge on the specific requirements of your system.
`
`
Illustrative Examples: Leveraging Kafka and RabbitMQ for Optimal Efficiency
In this part of our coverage, we will dig deep into real-life examples that showcase the implementation of Kafka and RabbitMQ in optimizing efficiency under diverse conditions. These examples will lend a hands-on viewpoint on the discussion comparing Kafka with RabbitMQ, throwing light on the positives and drawbacks of both these messaging systems in varying setups.
Illustrative Example 1: Application of Kafka in LinkedIn
LinkedIn, the globally renowned platform for professional networking, has been efficiently utilizing Kafka as its principal messaging system starting from 2010. Kafka, which was initially conceptualized and created by LinkedIn to cater to their escalating requirements for data pipeline, is now responsible for handling more than 7 trillion messages on a daily basis.
Kafka was chosen by LinkedIn mainly for its ability to manage massive, real-time data streams. The log-centric design and distributed processing features of Kafka empowered LinkedIn to manage exceedingly high volumes of data in real-time, which was absolutely vital for their features such as live feed updates, recommendations, and search functionalities.
<code class="language-java">// An example of Kafka Producer Code implementation Properties prop = new Properties(); prop.put("bootstrap.servers", "localhost:9092"); prop.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); prop.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); Producer<String, String> producer = new KafkaProducer<>(prop); producer.send(new ProducerRecord<String, String>("test", "key", "value")); producer.close();</code>
Illustrative Example 2: Deployment of RabbitMQ in Instagram
Instagram, an extremely popular platform for sharing photos and videos, preferentially uses RabbitMQ as its chief messaging system. The sturdy messaging proficiencies of RabbitMQ have been instrumental in managing Instagram's gigantic user base, which spews out billions of likes and comments every day.
Instagram's selection of RabbitMQ was prompted by its adaptable routing capabilities, dependable message transmission, and user-friendly nature. The exchange and queue model of RabbitMQ enabled Instagram to distribute messages effectively based on a variety of routing scenarios, ensuring that every message found its way to the right recipient.
<code class="language-python"># An example of RabbitMQ Producer Code implementation import pika connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() channel.queue_declare(queue='test') channel.basic_publish(exchange='', routing_key='test', body='Hello World!') print(" [x] Sent 'Hello World!'") connection.close()</code>
Comparative Examination
| Attribute | Kafka | RabbitMQ |
|---|---|---|
| Data Throughput | Superior (7 trillion messages/day at LinkedIn) | Average (Billions of likes/comments per day at Instagram) |
| Real-time Processing Capability | Present | Absent |
| Flexibility in Routing | Restricted | Superior |
| User-friendliness | Average | Superior |
To conclude, both Kafka and RabbitMQ have demonstrated their effectiveness in managing high-volume messaging requirements in extensive, real-world setups. Kafka's forte lies in its capacity to process large-volume, real-time data streams, making it the go-to choice for applications necessitating real-time analytics and data processing. Contrastingly, the flexible routing capabilities and user-friendliness of RabbitMQ make it a favored option for applications requiring elaborate routing rules and dependable message transmission.
Concluding Thoughts: Deciphering the Right Selection Between Kafka and RabbitMQ
We've meticulously examined two strong messaging systems, Kafka and RabbitMQ, and now it's time to provide guidance for choosing the most suitable one. The decision isn't a uniform fix for all, but rather it demands a deeper understanding of your unique scenario, the type of data in question, and the demands of your system.
1. Comprehending Your Scenario
The preliminary point to contemplate in making a decision between Kafka and RabbitMQ relies on your exact circumstance. Are you working with large-scale data or minuscule data volumes? Does the mechanism need to address high traffic or is rapid response time more paramount?
If you are contending with expansive data and need a high-bandwidth system, Kafka could serve as the most viable option. Kafka is equipped to manage gigantic data stacks and can accommodate processing of millions of notes in a second.
Conversely, if your operation revolves around smaller data stacks and necessitates rapid communication, look at RabbitMQ. It thrives in circumstances where minimizing communication delay is fundamental, focusing on delivering messages at the highest speed.
2. Scrutinizing Your Data Characteristics
Another crucial aspect to consider is the particular nature of your data. Are you working with continuous data flow or gathered data? Is real-time processing vital or is accumulated data handling a larger concern?
For uninterrupted data flow, Kafka stands out. Its principal advantage lies in real-time manipulation, successfully handling incoming data instantly, making it perfect for live analytics, real-time supervising, and event-oriented structures.
Meanwhile, RabbitMQ is directed towards managing data in chunks. It excels in managing bulk data stacks simultaneously, so it's apt for task allocation, message brokering, and collective data processing.
3. Analyzing Your System Specifications
Ultimately, calculate your system necessities. Are you searching for an easy, manageable setup, or can you dedicate more resources to installation and controlling a more potent mechanism?
For ease of setup and smooth administration, RabbitMQ is hard to beat. With its intuitive interface and various plugins for additional capabilities, it's perfect for smaller teams and less resource-intensive projects.
In contrast, Kafka delivers high-performance and scalability but at a cost of more intricate setup and management. The lack of an intuitive interface necessitates a higher comprehension of its blueprint for effective usage. However, for larger teams with abundant resources, Kafka offers a more robust option.
In a nutshell, your decision between Kafka and RabbitMQ should factor in your unique scenario, data type, and system specifications. By decoding these factors, you can confidently choose the most advantageous option for your needs.
如有侵权请联系:admin#unsafe.sh