
作者:知道创宇404实验室翻译组原文链接:https://labs.taszk.io/articles/post/full_chain_bb_part3/前言在 Hardwea 2024-1-15 13:51:0 Author: paper.seebug.org(查看原文) 阅读量:26 收藏
作者:知道创宇404实验室翻译组
原文链接:https://labs.taszk.io/articles/post/full_chain_bb_part3/
前言
在 Hardwear.io 的 Basebanheimer 演讲中,我介绍了一种方法:通过利用联发科基带 Pivot 漏洞 CVE-2022-21765 ,在其较旧的 Helio 系列芯片组上使用 32 内核 Linux 的任意代码执行。
基于之前的想法,理论上这个漏洞也可以在联发科最新的芯片组系列(Dimensity,使用 64 位内核)上被利用。
1 漏洞:CVE-2022-21765 和 CVE-2022-21769
回顾一下,这些漏洞在 Linux 内核驱动程序中提供了 OOB 读写功能,该驱动程序为应用程序(AP)和蜂窝处理器(CP)之间提供了一个接口,联发科称之为 CCCI 驱动程序。具体而言,这些错误源于环形缓冲区实现过程中,未对存储在 AP 和 CP 之间共享内存中的环形缓冲区的偏移量和长度值进行合理性验证。下面是有问题的代码:

但在这一点上我们面临许多挑战,因为可获得的 OOB 原语是有限的。
首先,我们出界的最大限度为2*UINT_MAX。其次,也是最关键的一点,由于我们正在破坏内核用于其环形缓冲区操作的偏移量,因此我们不能直接控制:
- 读取操作被读入的位置(即 OOB 读取“泄漏”的目标),
- 写入操作写入的位置(即写入的值)
2 利用 Linux 内核中的 ioremap OOB 错误
在完成对天玑系列的开发之后,我们偶然看到了 p0ly 和 Vincent Dehors 关于特斯拉 pwn 的最新攻击演讲。他们展示了一个有趣的漏洞利用链,其最后一步巧妙地以类似方式利用了一个与之极为相似的漏洞。这揭示了一个有趣的现象,即截然不同的供应商如何设法解决相同的问题。
他们的方法与 Brandon Azad 的初始想法具有共通之处:针对 vmalloc 区域中的其他分配(这些环缓冲区是ioremap() ed,由 vmalloc 区域提供服务)。
我们同样采用了 Brandon 的这个想法,并尝试分配了 _do_fork。
因此,这让我们有了一个攻击目标的想法,但仍有几个关键问题需要解决:
- 我们能否将有限的 OOB R/W 原语转换为对写入值有足够控制的原语。
- 我们如何绕过 KASLR。
- 我们能否在目标上获得可预测的 vmalloc 区域布局,从而选择合适的
_do_fork受害者。
3 改进 CVE-2022-21765/CVE-2022-21769 的 OOB 漏洞
AP 和 CP 使用的多个环形缓冲区大多数都非常嘈杂,这给我们的利用带来了困难。
幸运的是,我们发现仅用于远程文件系统 (RemoteFS) 实现的环形缓冲区在初始启动后变得非常平稳。因此,这为我们提供了一个利用的机会,无需过多担心其正常的运作。
更重要的是,RemoteFS API 为我们提供了理想的工具,可以将越界(OOB)原语转换为几乎完全受控的读取和写入操作:
- 为了写入内存,我们可以先使用 RemoteFS 的常规 File Write API 来准备受控数据。
- 然后,我们可以使用文件读取 API “回读”这些数据,并使用 OOB write 原语创建 write-what-where 的操作,具体见
CVE-2022-21765。 - 我们也可以反向执行相同的操作,以便读取任意内存(从何处读取):文件写入时损坏的环形缓冲区,以将所需的泄漏内存存储到文件中,然后使用文件读取 API 按预期将其读回。
对于“在哪里写入”,我们必须考虑到一个限制,即写入的值不是完全受控的。这是因为每次环形缓冲区的写入都包含了头部和尾部,如下图所示:
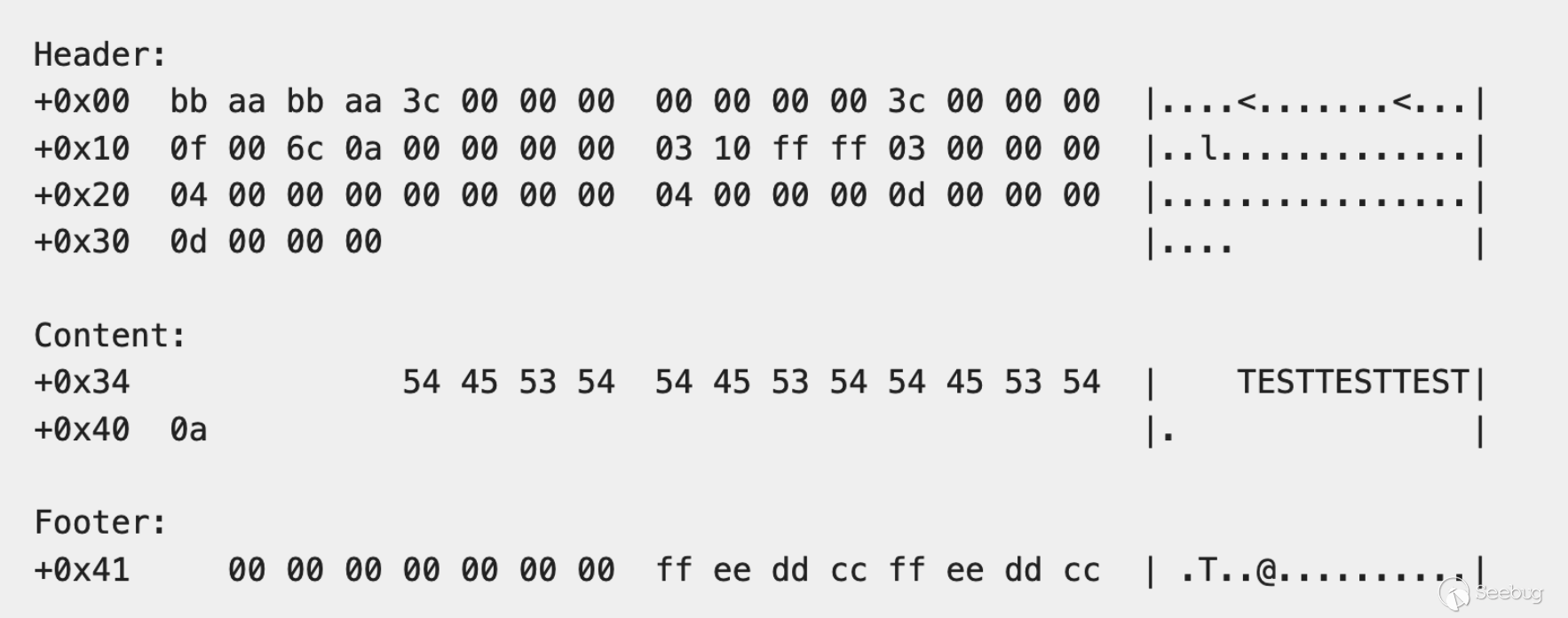
因此,我们需要选择一个可以容忍临近字节被头部和尾部"噪音"覆盖为副作用的损坏目标。
4 寻找可靠的 Vmalloc 受害者并绕过 KASLR
在我们的研究中,我们发现了许多潜在的目标,包括线程堆栈和 bpf 程序,这些都可以在/proc/vmallocinfo中查看。
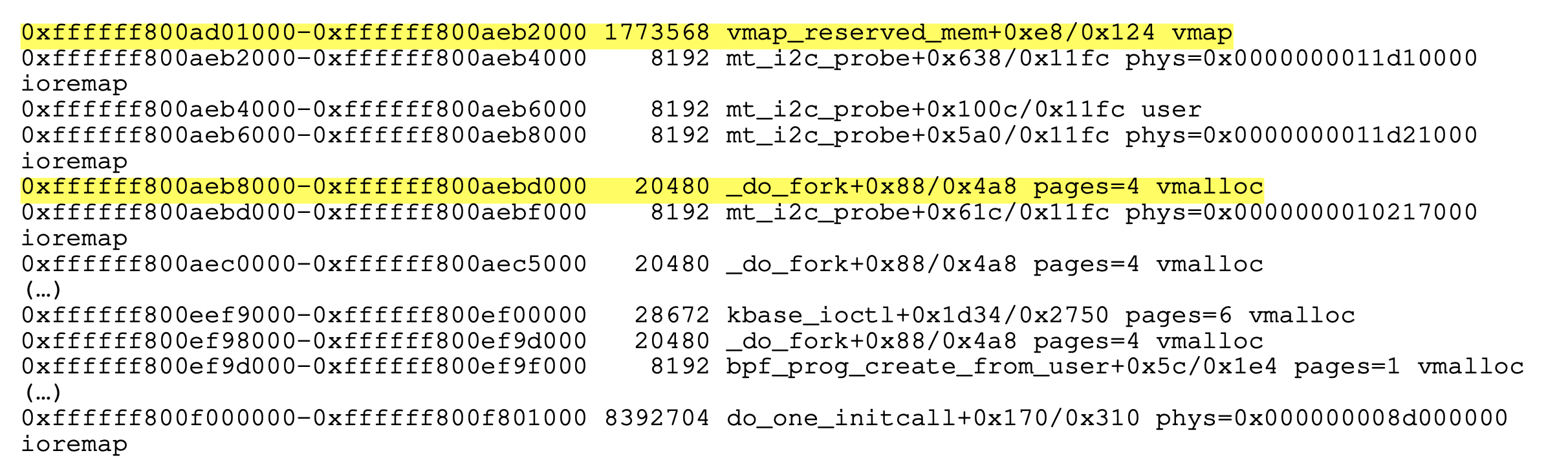
虽然 vmalloced 地址没有应用 KASLR 随机化,但受运行时提供的“自然”熵的影响,布局并不是完全静态的。
尽管如此,早期分配仍具有可预测的且稳定的模式。由于我们的分配发生在 vmalloc 的早期阶段,因此它最终会到达一个可预测的地址,并且相邻的分配也是可预测的,具有很高的准确性。
基于这一点,我们能够确定在 vmalloc 中靠_do_fork定位的分配。

总而言之,vmalloc 区域中的_do_fork分配表示内核中的线程堆栈。这些堆栈在系统调用执行期间被用户空间线程使用,同时也被内核线程用于存储其执行堆栈。
特别是内核线程具有相当可预测的调用堆栈,因为 Linux 调度程序以完全相同的方式生成它们。所以这些堆栈的顶部是推送的堆栈帧 ret_from_fork、worker_thread 、kthread 、schedule 等。
因此,通过覆盖调度的内核线程的相应堆栈帧,我们可以轻松地“竞争”其调度,劫持该内核线程的执行,创建一个 ROP 链,并从那里执行自定义代码。

此外,选择这样的目标还为我们提供了绕过 KASLR 的直接途径。在案例中我们发现,在 RemoteFS 环形缓冲区中,我们总能找到一个包含固定指针+0x3eb8``kthread的区域(与可作为覆盖目标的区域相同),这简化了泄露内核映像 KASLR 滑动的过程。
5 内核 RCE 的 ROP 链
p0ly 和 Vincent Dehors 采用了经典的 ROP 方法,即通过覆盖字符串来执行 ROP 调用。这种方法既高效又干净,但其局限性在于只能以 kworker 根用户的身份执行命令,如poweroff_cmd和poweroff_work_func。
这种情况在过去可能意味着攻击的成功结束,但在现在的 Android 系统中,SELinux 对用户施加了严格的限制,以至于这种方法几乎无法实现有效的操作。
甚至由于缺乏打开网络套接字的权限,无法执行回连Shell。因此,在面对搭载联发科天玑芯片组的智能手机时,我们需要寻找更强大的攻击手段。
Brandon Azad 使用了 ROP 技术,然而这对我们来说是行不通的,因为联发科内核阻止了___bpf_prog_run()这种方法。
特别是,联发科天玑内核被强制执行了 BPF JIT 编译,这导致内核中完全省略了这个 API:
#ifndef CONFIG_BPF_JIT_ALWAYS_ON
static unsigned int ___bpf_prog_run(u64 *regs, const struct bpf_insn *insn,
u64 *stack)
...相反,我们所做的是查看我们拥有的 BPF JIT 实现。事实证明,始终对 eBPF 程序进行 JIT 的意味着module_alloc调用(简单的为调用者分配 RWX 内存)存在于内核中。当然,这为 ROP 链到任意 shellcode 提供了一个完美的环境。
void *module_alloc(unsigned long size)
{
u64 module_alloc_end = module_alloc_base + MODULES_VSIZE;
gfp_t gfp_mask = GFP_KERNEL;
void *p;
...
p = __vmalloc_node_range(size, MODULE_ALIGN, module_alloc_base,
module_alloc_end, gfp_mask, PAGE_KERNEL_EXEC, 0,
NUMA_NO_NODE, __builtin_return_address(0));
...我们仍需找到工具来为 ROP 链的步骤准备必要的寄存器值,并需要比仅使用一个寄存器更精确的控制。
其中一个困难是,像 Linux 内核中的 memcpy 这样的函数通常被优化得很好,它们甚至不使用堆栈(因此它们的结语没有提供方便的 ROP 小工具链接),这是因为它们需要在系统启动的早期阶段运行,那时堆栈可能还未初始化。不过幸运的是,memcpy周围存在一些包装器,能够增加堆栈的使用(可以将此与第 3 种方法中使用 copy_from_user 的方法进行比较)。
最终,我们可以利用 ROP 中的 memcpy 将所需的 shellcode 从一个可靠的固定地址复制到新的 RWX 区域。在我们的案例中,我们能够再次利用我们的线程堆栈,并使用该堆栈框架的顶部do_fork作为暂存区域。
当这些步骤在 ROP 链中组合起来后,我们可以执行完全任意的 shellcode。
1. set x0 = 0x100 (size of the injected code), x1 = <dummy>
2. module_alloc(x0:size) -> x0:dst
3. set x8 = x0
4. set x0 = 0x100 (size of the injected code), x1 = <dummy>
5. set x2 = x0
6. set x0 = <dummy>, x1 = <code source>
7. set x0 = x8
8. memcpy(x0:dst, x1:src, x2:size) (preserves x0)
9. set x8 = x0
10. jump on x86 漏洞利用演示
最后,下方链接是在天玑芯片组设备(小米 POCO M3 5G)上利用 RCE 漏洞的视频演示:
https://www.youtube.com/embed/0ICLk3HO_zY?si=s_NdlXPhvtPAujFU
如视频中展示的,为了简单起见,我们的概念验证只执行了一个 shellcode,它将所有寄存器设置为独特的模式,以证明代码的有效执行(摘自 poc 源代码)。
#define __SHELLCODE_SIZE__ (0x100)
const int shellcode_size = __SHELLCODE_SIZE__;
const ulong shellcode_addr = target_vmalloc + 0x1000;
uint shellcode[__SHELLCODE_SIZE__/4] = {
0x00000000, // padding for exploit_write
0xd2802020, // mov x0, #0x101
0xd2802221, // mov x1, #0x111
0xd2802422, // mov x2, #0x121
0xd2802623, // mov x3, #0x131
0xd2802824, // mov x4, #0x141
0xd2802a25, // mov x5, #0x151
0xd2802c26, // mov x6, #0x161
0xd2802e27, // mov x7, #0x171
0xd2803028, // mov x8, #0x181
(...)
0xd280563a, // mov x26, #0x2b1
0xd280583b, // mov x27, #0x2c1
0xd2805a3c, // mov x28, #0x2d1
0xd2805c3d, // mov x29, #0x2e1
0xd2805e3e, // mov x30, #0x2f1
0xd65f03c0, // ret
}; 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/3101/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/3101/
如有侵权请联系:admin#unsafe.sh