如今,无论是商业文件,电子书籍,还是学术论文,大多以 PDF 文件格式存储和分发。这主要是看中了 PDF 跨平台、跨设备、且不易修改的特点;也有说法称 PDF 为世界上最重要的文件格式。
但是,PDF 的很多特点和功能仍然不为人知,日常学习工作中遇到 PDF 相关的问题还是会让不少同学犯难。此外,发明 PDF 格式的 Adobe 公司推出的 Acrobat 不仅昂贵,也并非万能,在实现某些 PDF 功能时并非总是最优选项。
举个例子,我一位朋友热衷于将纸质书扫描成 PDF 电子书,前段时间他想将扫出的两页对开版本分割成单页,在 Acrobat 中折腾了半天也没有实现。能找到的其他软件价格都还不便宜。最终,通过我们下面会介绍的 MuPDF,他没花一分钱就实现了这个需求。
有鉴于此,本文接下来将分享一些我日常用到的 PDF 处理工具和技巧,让你无需 Adobe Acrobat 或其他付费 PDF 软件,也能轻松相应的问题。
方便查阅起见,下面先用表格列出这些工具的主要信息:
| 名称 | 语言 | 支持平台 | 许可方式 | 简介 | 安装方式 |
|---|---|---|---|---|---|
| pdftk-java | Java | Linux, macOS, Windows | GNU-2.0 | 命令行工具,导出 PDF 元数据,合并、拆分、修复 PDF 等 | brew install pdftk-java |
| Skim | Objective-C | macOS | BSD | 图形界面工具,阅读和批注 PDF,默认将 PDF 标注存储为 Skim notes | brew install --cask skim |
| MuPDF | C | Linux, macOS, Windows, Android, iOS | AGPL-3.0 | 轻量级 PDF、XPS 和电子书查看器;常用作框架,但也有命令行工具 | brew install mupdf |
| pdfjam | Shell | Linux, macOS, 通过 Cygwin 支持 Windows | GPL-2.0 | 命令行工具,主要用于涉及 PDF 页面的处理任务 | 安装 TeX Live 发行版或下载 release 后安装 |
| pypdf | Python | Linux, macOS, Windows | BSD | Python 库,通过 Python 对 PDF 进行分割、合并、裁剪和转换、提取文本等 | pip install pypdf |
可以看出,这些工具主要是命令行界面,天然地适合自动化使用。但为了让不熟悉命令行的朋友也能轻松,我也提供了 macOS 平台上的打包方案(下载) ,有依托 Keyboard Maestro、Automator(自动操作)和 Shortcuts(快捷指令)的版本可选。
给自己打个小广告:Keyboard Maestro 是我非常喜欢的自动化工具,我还为它写过一个完整的教程《生产力超频:Keyboard Maestro 拯救效率》(会员可以免费阅读)。如果你还没有购买 Keyboard Maestro,可以使用少数派读者专属优惠码 SSPAI 享受八折优惠。
调整 PDF 页码标签
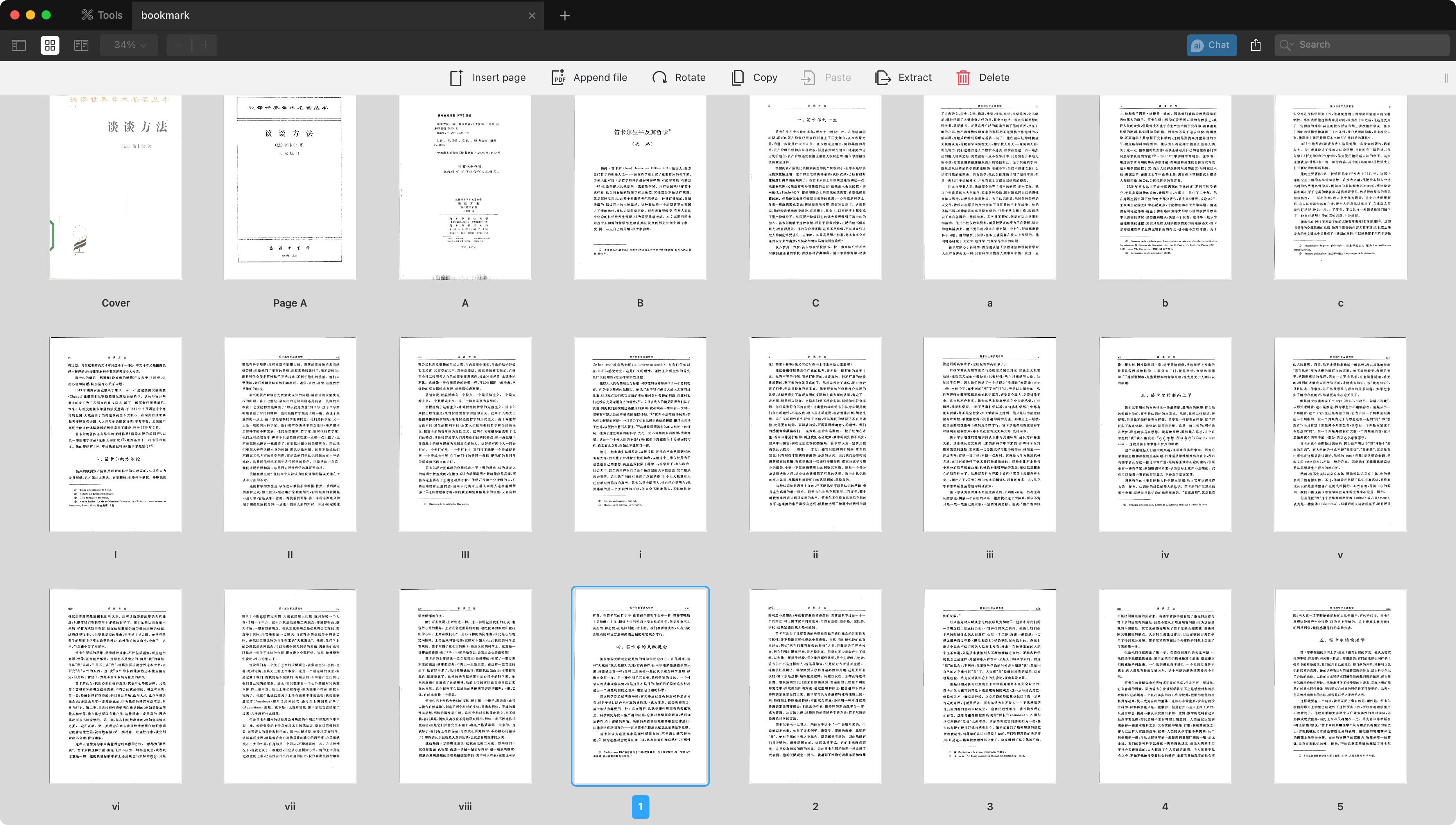
一般情况下,PDF 的页码(page numbers)是从文件的首页起算。但因为 PDF 常用来保存出版物,其实际内容的页码编排与 PDF 文件的页数未必一致。例如,在下图所示的 PDF 中,由于封面、目录等占用的页数,正文页脚的第 10 页实际上已经是文件的第 19 页。

实际上,PDF 也考虑到了这种情况,不仅支持从首页单调递增的纯数字页码,还支持一种被称作 page folios 的富格式页码(在 Acrobat 中也叫作 page labels)。page folios 支持分组,内容可以是阿拉伯数字、英文字母、罗马数字或自定义标记,还能添加前缀,因此可以与文件内容完全对应。
如果你有 Adobe Acrobat,选中需要调整的页面缩略图,右键点击「Page Labels…」,在弹出的对话框中设置即可。

但如果你不想为 Acrobat 付费,或者觉得页数多时操作繁琐,则可以使用命令行工具 PDFtk。假设输入文件为 input.pdf,用下面的命令将其元数据导出为一个纯文本文件 metadata.text(文档):
pdftk input.pdf dump_data_utf8 output metadata.text使用文本编辑器打开生成的 metadata.text,可以看到 input.pdf 的各种元数据,其中就包括页码标签信息,如下所示:
PageLabelBegin
PageLabelNewIndex: 1
PageLabelStart: 1
PageLabelPrefix: Cover
PageLabelNumStyle: NoNumber
PageLabelBegin
PageLabelNewIndex: 2
PageLabelStart: 1
PageLabelPrefix: Page
PageLabelNumStyle: UppercaseLetters
PageLabelBegin
PageLabelNewIndex: 3
PageLabelStart: 1
PageLabelNumStyle: UppercaseLetters
PageLabelBegin
PageLabelNewIndex: 6
PageLabelStart: 1
PageLabelNumStyle: LowercaseLetters
PageLabelBegin
PageLabelNewIndex: 9
PageLabelStart: 1
PageLabelNumStyle: UppercaseRomanNumerals
PageLabelBegin
PageLabelNewIndex: 12
PageLabelStart: 1
PageLabelNumStyle: LowercaseRomanNumerals
PageLabelBegin
PageLabelNewIndex: 17
PageLabelStart: 1
PageLabelNumStyle: DecimalArabicNumerals容易发现,每个 PDF 页码标签的元数据由 4 或 5 行组成:
PageLabelBegin:开始一个页码标签PageLabelNewIndex:页码标签开始的索引,对应 PDF 的 page numbersPageLabelStart:页码标签开始的页码PageLabelPrefix:页码标签的前缀(可选)PageLabelNumStyle:页码标签的类型,包括NoNumber(无页码)、DecimalArabicNumerals(阿拉伯数字)、UppercaseLetters(大写英文字母)、LowercaseLetters(小写英文字母)、UppercaseRomanNumerals(大写罗马数字)和LowercaseRomanNumerals(小写罗马数字)。
据此,示例输出的元数据可以解读为:
| 页码范围 | 页码格式 |
| 1 | Cover |
| 2 | 带有前缀 Page 的大写英文字母 Page A |
| 3-5 | 大写英文字母 A,依次递增 |
| 6-8 | 小写英文字母 a,依次递增 |
| 9-11 | 大写罗马数字 I,依次递增 |
| 12-16 | 小写罗马数字 i,依次递增 |
| 17- | 阿拉伯数字 17,依次递增直至最后一页 |
当然,PDF 未必都需要页码定义,如果元数据没有定义页码标签,阅读器默认会使用最普通的格式,即从阿拉伯数字 1 开始递增。
回到我们的需求:如果将 metadata.text 倒数第 3 行的 17 修改为 20,就是指文件第 17 页开始的 page labels 修改为从阿拉伯数字 20 开始。
最后将修改后的 metadata.text 导入回 PDF 即可:
pdftk input.pdf update_info_utf8 metadata.text output output.pdf输出的 output.pdf 所显示的页码如下图所示。

据此,我们还可以通过 Keyboard Maestro 将其固定为一个 marco,这样以后就可以一键调用了。
先看成品效果,如下图所示:

简单描述,这个 macro:
1. 首先获取访达(Finder)中选中文件及其所在路径,然后保存为 Keyboard Maestro 中的变量 selected_pdf。
2. 判断选中的文件是否是 PDF,如果不是,则弹出通知然后取消执行 macro。
3. 弹出一个提示框,让用户输入页码标签的起始页,这里包括了 3 种类型,也就是 PDFtk 的读取的 3 个变量:1
FirstPage:第一页,通常为Cover,默认值设置为 1LowercaseRomanNumerals:小写罗马数字页码标签的起始页DecimalArabicNumerals:阿拉伯数字页码标签的起始页
如果上述 3 个值留空的话,则表示不包括该类页码标签。
4. 将用户输入的值作为变量传递给下面的 Shell 脚本。
export PATH="$PATH:/opt/homebrew/bin:/usr/local/bin"
cd "$KMVAR_pdf_path"
# Dump PDF metadata
pdftk "$KMVAR_selected_pdf" dump_data_utf8 output metadata.text
# Path to the metadata file dumped by pdftk
METADATA_FILE="metadata.text"
# Remove existing page label information if present
sed -i '' '/PageLabelBegin/,$d' "$METADATA_FILE"
# Function to append page label information
append_page_label(){
cat <<EOF >> "$METADATA_FILE"
PageLabelBegin
PageLabelNewIndex: $1
PageLabelStart: $2
$3
$4
EOF
}
# Append new page label information if variables are not empty
[ -n "$KMVAR_FirstPage" ] && append_page_label "$KMVAR_FirstPage" "1" "PageLabelPrefix: Cover" "PageLabelNumStyle: NoNumber"
[ -n "$KMVAR_LowercaseRomanNumerals" ] && append_page_label "$KMVAR_LowercaseRomanNumerals" "1" "PageLabelNumStyle: LowercaseRomanNumerals"
[ -n "$KMVAR_DecimalArabicNumerals" ] && append_page_label "$KMVAR_DecimalArabicNumerals" "1" "PageLabelNumStyle: DecimalArabicNumerals"
# Update PDF metadata
pdftk "$KMVAR_selected_pdf" update_info_utf8 metadata.text output adjusted-page-labels.pdf
# Remove `metadata.text`
rm metadata.text这段代码使用 pdftk 导出 PDF 的元数据为文本文件 metadata.text,然后使用 sed 删除 metadata.text 中已有的页码标签信息。接着,使用 cat 将用户输入的页码标签信息追加到 metadata.text 中,通过 pdftk 导入,最后删除临时文件 metadata.text。
这就完成了 marco 的编写。以后,在访达中选中需要修改页码标签的 PDF 文件,按下快捷键 ⌃ + ⌥ + L ,在弹出的窗口中输入不同类型的页码标签的起始页,就可以得到页码标签修改后的 PDF 文件。

转移 PDF 书签
PDF 书签(bookmark)是指导航窗格的书签面板中的超链接文本,对应着不同的页码,有时也叫作「目录」或「大纲」。