利用机器学习进行恶意邮件识别
#01 引言 随着互联网的普及和电子邮件的广泛应用,恶意邮件已成为网络安全领域的一大公害。这些邮件往往携带病毒、恶意软件或诈骗信息,对个人和企业造成巨大的损失和安全隐患。 传统的基于规则的 2024-1-11 14:25:16 Author: Reset安全(查看原文) 阅读量:33 收藏
#01 引言 随着互联网的普及和电子邮件的广泛应用,恶意邮件已成为网络安全领域的一大公害。这些邮件往往携带病毒、恶意软件或诈骗信息,对个人和企业造成巨大的损失和安全隐患。 传统的基于规则的 2024-1-11 14:25:16 Author: Reset安全(查看原文) 阅读量:33 收藏
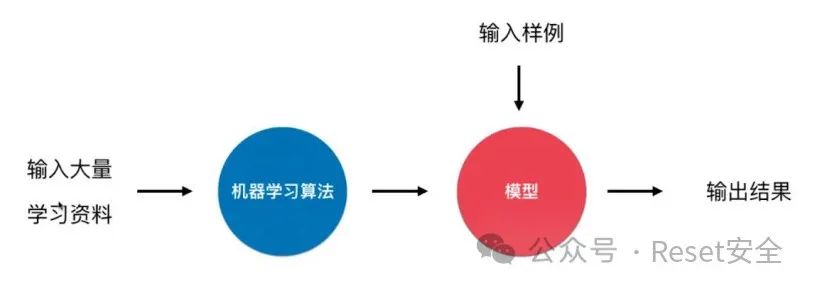
监督学习:在这种方法中,算法使用标记过的数据(即已知道分类的结果)来训练模型。例如,对于恶意邮件识别,监督学习需要使用已标记为“恶意”或“非恶意”的邮件来训练模型。 无监督学习:无监督学习不依赖于标记的数据,而是通过聚类、降维等方式探索数据内在的结构或关系。在恶意邮件识别中,无监督学习可以用于发现未知的恶意邮件模式或集群。
朴素贝叶斯:基于概率的分类方法,通过计算各类别的条件概率来做出预测。 支持向量机 (SVM):通过找到能够将不同类别的数据点最大化分隔的决策边界来实现分类。 深度学习:包括卷积神经网络 (CNN) 和循环神经网络 (RNN) 等,能够从原始数据中提取多层次的特征。
文本内容分析:通过分析邮件的正文内容,提取关键词、情感倾向等信息,用于判断邮件是否包含欺诈或恶意信息。 附件检测:检查邮件是否包含可疑附件,如未知类型的文件或特定类型的恶意软件。 元数据分析:分析邮件的元数据,如发件人、收件人、邮件大小等,以识别可能的欺诈或垃圾邮件模式。
发送频率分析:通过分析同一发件人在短时间内发送大量邮件的行为,识别垃圾邮件发送者。 时间戳分析:利用邮件发送和接收的时间戳信息,识别出批量发送或具有特定时间规律的邮件。
卷积神经网络 (CNN):用于从邮件内容中提取图像、文本等复杂特征。 循环神经网络 (RNN):处理序列数据,如文本信息,能够捕捉文本中的时序依赖性。 长短期记忆网络 (LSTM):是RNN的一种改进,特别适合处理具有较长依赖关系的序列数据。
为了评估机器学习方法在恶意邮件识别中的效果,需要进行实验并对结果进行分析。以下是实验和结果分析的详细步骤:
数据集收集:收集大量恶意邮件和正常邮件的数据集,用于训练和测试机器学习模型。 数据预处理:对收集的数据进行清洗、去重、格式化等处理,确保数据的质量和一致性。
算法选择:根据前文所述的机器学习方法,选择适合的算法进行实验。 参数调整:对算法进行参数优化,如调整超参数、选择合适的核函数等,以提高模型的性能。 训练与测试:将数据集分为训练集和测试集,利用训练集训练模型,并在测试集上评估模型的性能。
结果展示:通过绘制混淆矩阵、计算准确率、召回率、F1分数等指标,展示模型分类结果的性能。 对比分析:对比不同算法在不同数据集上的性能,分析它们的优缺点和适用场景。
特征选择:分析不同特征在恶意邮件识别中的重要性和影响,讨论如何选择最佳特征组合。 算法性能:探讨不同算法在处理恶意邮件识别时的性能差异,以及如何根据实际需求选择合适的算法。
集成与维护:将机器学习模型集成到现有的邮件安全系统中,并确保持续的模型更新和维护。 性能与资源:机器学习模型可能对计算资源和存储有较高要求,需要在保证性能的同时优化资源利用。
误报率:模型可能将正常邮件误判为恶意邮件,导致不必要的拦截或干扰。 实时性:机器学习模型需要快速处理大量邮件数据,以满足实时检测的需求。 隐私与合规性:在处理邮件数据时,需要确保符合隐私法规和合规性要求。
持续学习与更新:随着恶意邮件的不断演变,需要持续训练和更新模型以应对新的威胁。 多模态数据融合:结合文本、图像、音频等多种数据模态,进一步提高恶意邮件识别的准确性。 自动化与智能化:利用自动化工具和智能流程,简化机器学习在恶意邮件识别中的应用和管理。
文章来源: http://mp.weixin.qq.com/s?__biz=MzU3Mzg1NzMyNw==&mid=2247484820&idx=1&sn=757aa7cddfd5d187c8e044bb0aeda23e&chksm=fc33b3c47dc5d4d64f9592ae2817a2dd61e675622ef235fba7a4c3703271b18a206d18bba587&scene=0&xtrack=1#rd
如有侵权请联系:admin#unsafe.sh
如有侵权请联系:admin#unsafe.sh