作者:知道创宇404实验室翻译组原文链接:https://labs.taszk.io/articles/post/full_chain_bb_part2/CVE-2022-217 2024-1-10 11:28:0 Author: paper.seebug.org(查看原文) 阅读量:60 收藏
作者:知道创宇404实验室翻译组
原文链接:https://labs.taszk.io/articles/post/full_chain_bb_part2/
CVE-2022-21744 漏洞存在于联发科基带中,是一个堆缓冲区溢出漏洞。
这个堆溢出漏洞的一个关键限制是:被覆盖的值是一个指向攻击者可控字节的分配的指针。
换言之,我们并非直接操控被破坏的字节,而是写入四字节的指针值,这些指针各自指向一个内容由攻击者控制的内存分配。
由于覆盖原语的特性,我们在 2022 年披露的联发科堆利用技术无法直接应用。然而,如果我们能找到合适的受害者在堆上进行破坏,这样的原语仍有可能有效。
这种连续写入指针值的方法可能会带来问题,但同时也可能为堆分配器本身提供新的机会。目前,还没有合适的公开技术,因此我们必须为这个基带寻找一个独创的解决方案。
下文我将描述我在研究这个漏洞可利用性时的发现。
1 Mediatek CVE-2022-21744 回顾
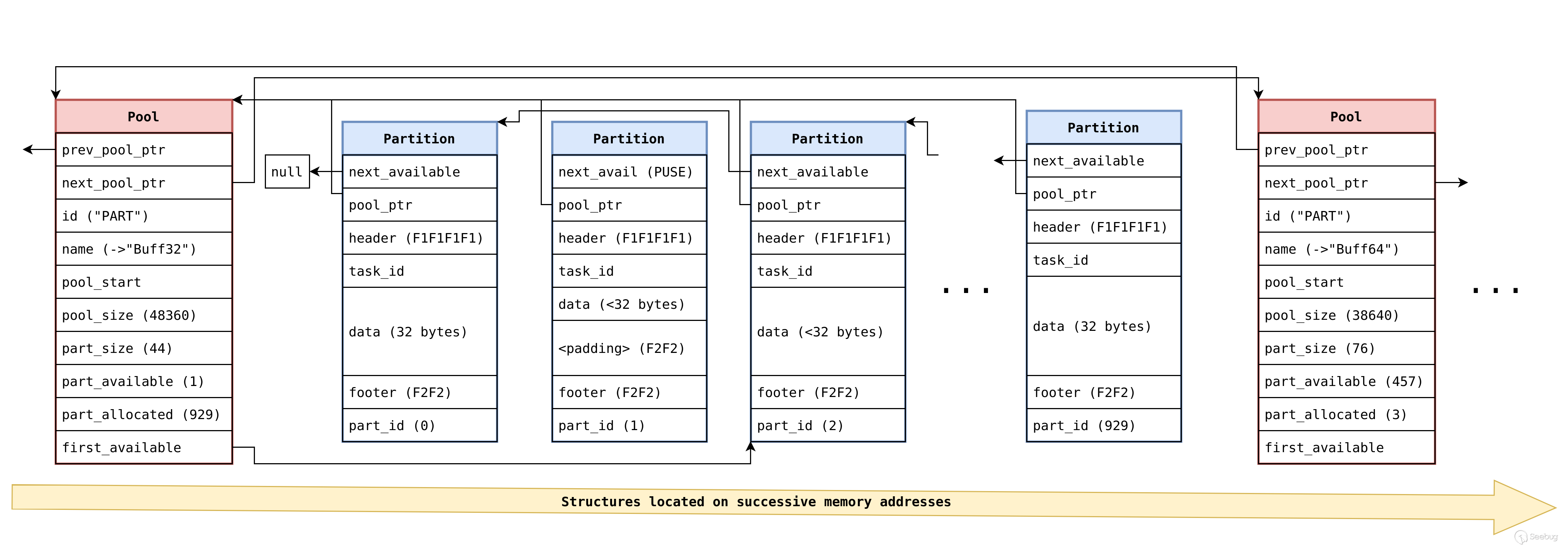
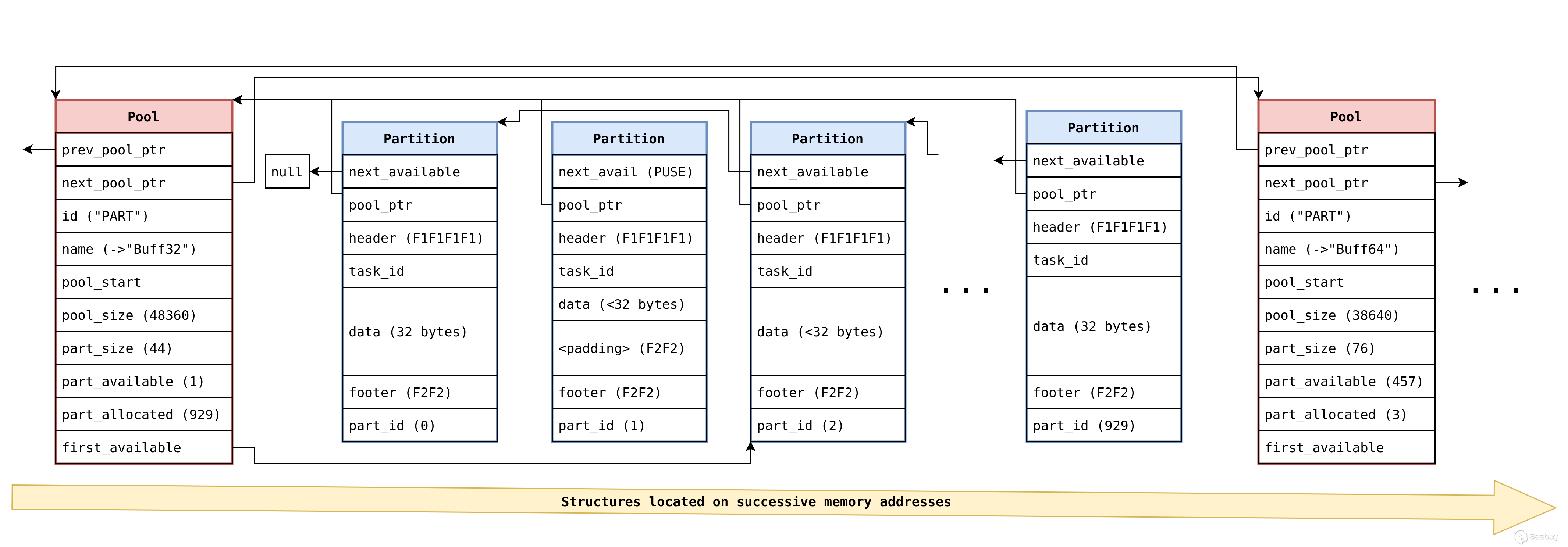
作为我们上一篇文章的简要回顾,原始的 Nucleus OS 堆实现具有以下基本结构:
-
基于池的分配器(插槽称为分区)。
-
分区大小是 2 的幂,因此分配请求四舍五入为 32/64/128/256/512 等字节。
-
每个分区的最小开销为 20 个字节:一个 16 字节的头部和一个 2 字节的分区计数器尾部,四舍五入为整数位宽,并填充
0xF2F2。 -
整个堆本身保留在固件内存布局中的固定位置(每次都相同地址);每个大小的所有分区池始终位于同一位置,一个接一个,分区池描述符结构始终位于实际池本身的正前方。
-
每当请求的大小本身小于插槽大小减去 4 时,在请求的大小之后附加一个重复的保护尾部;换言之,通过精确的分配请求,这些保护字节将被消除。
我们上一项研究强调了此实现的多个弱点,并解释了如何创建分区空闲表污染、分区到池覆盖和分区重叠技术,以创建一个能在任何地方分配的堆利用原语。
随后,联发科对分配器做了几处修改。在 Dimensity 中,我们发现了修改后的堆结构和增加的一系列堆加固检查,这些检查旨在阻止我们所描述的技术。
2 Mediatek How2Heap, Whack-a-Mole Edition
2.1 新的堆结构
为了减轻针对污染的攻击,修改实现以完全消除next_available这个空闲列表,转而引入一个新结构,即 mer pool descriptor。
struct mer_pool_desc_t
0x0 0x4 struct mer_pool_desc_t * struct mer_pool_desc_t * mer_pool
0x4 0x4 struct kal_pool_desc_t * struct kal_pool_desc_t * pool_desc
0x8 0x4 uint uint hdr_guard
0xc 0x4 void * void * int_ctx
0x0 0x1 char char is_ready
0x1 0x1 char pad
0x2 0x2 ushort pad
0x4 0x4 void * void * pool_start
0x8 0x4 uint uint pool_net_slot_size
0xc 0x2 ushort ushort partition_max_cnt
0xe 0x2 ushort ushort
0x10 0x1 char char lvl2_size
0x11 0x1 char pad
0x12 0x1 char pad
0x13 0x1 char pad
0x14 0x4 uint uint lvl1_bitmask
0x18 0x80 uint[32] uint[32] lvl2_bitmask对于每个内存池,现在的结构包括一个两级位掩码数组。这个数组在内存释放或分配时用于改变分区的状态,并且在进行分配时用于选择下一个要返回的分区。
此外,分区头部和池描述符也进行了修改。现在,分区头部的首个字段直接指向新引入的 mer_pool_desc_t 结构,而非指向分区本身。类似地,池描述符也采用了全新的格式,其首个字段现指向 next_available 指针,替换了原先未曾使用过的前一个和后一个池指针字段。
struct kal_buffer_header_t
0x0 0x4 struct mer_pool_desc_t * struct mer_pool_desc_t * mer_pool
0x4 0x4 struct kal_pool_desc_t * struct kal_pool_desc_t * pool_desc
0x8 0x4 uint uint hdr_guard
0xc 0x4 void * void * int_ctx
struct kal_pool_desc_t
0x0 0x4 struct mer_pool_desc_t * struct mer_pool_desc_t * mer_pool_ptr
0x4 0x4 uint uint pool_size
0x8 0x4 struct kal_pool_stat_t * struct kal_pool_stat_t * pool_stat_mb
0xc 0x2 ushort ushort
0xe 0x2 ushort ushort num_buffs例如,下面是 Ghidra 的屏幕截图,其中显示了 32 大小池的最终分区的尾部、64 大小池的池描述符以及后一个分区的头部。这些图像是根据我们自定义的 Mediatek 基带调试器在运行时生成的真实内存快照。
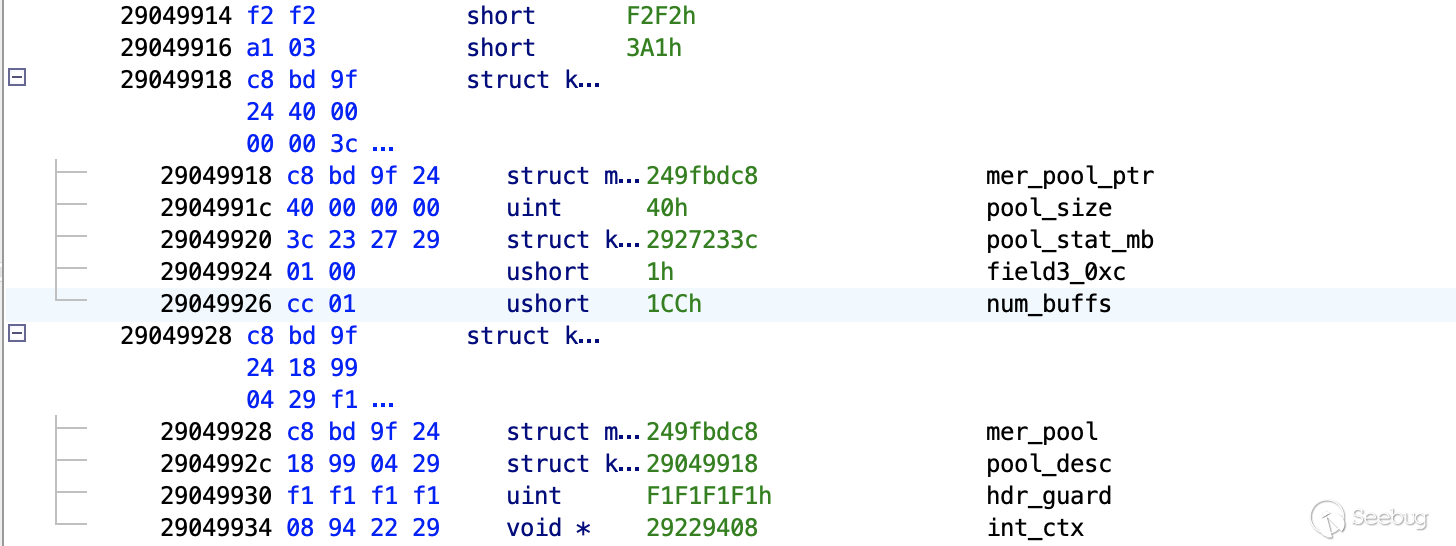

从图中可以看出,池描述符仍然与代码内联,但新引入的 mer_pool_desc_t结构并未在堆上以内联方式存储。
池和mer_pool_desc_t数组的建立反映了使用 Nucleus 的“后端分配器”为池预留内存的过程,具体指 kal_os_allocate_buffer_pool 和 kal_sys_mem_alloc。
struct kal_buff_pool_info_t
0x0 0x4 struct kal_pool_desc_t * struct kal_pool_desc_t * pool_ptr
0x4 0x4 uint uint pool_size
0x8 0x2 ushort ushort partition_cnt
0xa 0x2 ushort ushort
0xc 0x4 uint uint
struct kal_pool_size_info_t
0x0 0x4 struct kal_pool_desc_t * struct kal_pool_desc_t * pool_ptr
0x4 0x4 void * void * pool_start
0x8 0x4 void * void * pool_end 池管理所需的结构通过一些全局数组来实现,特别是 kal_buff_pool_info_t 类型,它记录了所有常规池的起始位置、分区大小和缓冲区数量信息,另外还有 kal_pool_size_info_t 类型。
虽然存在两个这样的数组可能初看令人困惑,但其用途将在下文中详细解释:一个数组用于选择合适的池进行分配,另一个用于验证所选择地址的正确性。
2.2 新的堆算法
堆仍然通过 get_ctrl_buffer_ext() 和 free_ctrl_buffer_ext() 使用。不过,堆中缓冲区的分配过程及其至关重要的合理性检查已经发生了变化。
在分配缓冲区时,API 主要基于 get_int_ctrl_buffer() 进行操作。在这个过程中,选择服务请求的池的初始步骤与以前相同,即通过遍历池信息结构数组来实现。
一旦选择了请求大小的池,__kal_get_buffer() 通过调用 kal_os_allocate_buffer()找到一个缓冲区返回,然后通过__kal_get_buff_num()和 kal_update_buff_header_footer()进行一系列检查来验证返回缓冲区的有效性和安全性。
void * get_int_ctrl_buffer(uint size,uint fileId,undefined4 lineNum,undefined caller_addr)
{
int idx;
uint module_id;
void *buff;
void *pool_ptr;
struct kal_pool_desc_t *pool_desc;
struct kal_buff_pool_info_t *pPool;
if (size != 0) {
pPool = g_gen_pool_info;
idx = 0;
do {
/* note: using pool_size here makes sense because pool_size is the
"net_slot_size", without the +8+8+4. Therefore, if the alloc request size
fits, it fits, quite simply. */
if (size <= pPool->pool_size) {
pool_desc = g_gen_pool_info[idx].pool_ptr;
if (pool_desc != (struct kal_pool_desc_t *)0x0) {
module_id = stack_get_active_module_id();
buff = (void *)kal_get_buffer(pool_desc,module_id,size,fileId,lineNum);
return buff;
}
break;
}
idx = idx + 1;
pPool = pPool + 1;
} while (idx != 0xd);
}
do {
trap(1);
} while( true );
}
void * kal_get_buffer(struct kal_pool_desc_t *pool_desc,undefined4 module_id,uint size,int file,
undefined4 line)
{
uint ret;
uint int_context;
uint buff_num;
int extraout_a0;
struct kal_pool_stat_t *psVar1;
void *new_alloc;
new_alloc = (void *)0x0;
if ((pool_desc != (struct kal_pool_desc_t *)0x0) &&
(ret = kal_os_allocate_buffer(pool_desc,(int *)&new_alloc,size,file,line), ret == 0)) {
/* add +8 for headers -> there are 4 dword headers in total,
kal_os_allocate_buffer skips 2 of them already */
new_alloc = (void *)((int)new_alloc + 8);
int_context = kal_get_internal_context();
if (pool_desc == *(struct kal_pool_desc_t **)((int)new_alloc + -0xc)) {
buff_num = __kal_get_buff_num(new_alloc,(short *)0x0);
kal_update_buff_header_footer(pool_desc,new_alloc,int_context,size,buff_num);
psVar1 = pool_desc->pool_stat_mb;
psVar1->buff_stat[buff_num].field0_0x0 = int_context | 1;
kal_atomic_update_return(&psVar1->curr_allocated,1,0xffffffff);
kal_atomic_sig(&psVar1->max_allocated,extraout_a0 + 1);
kal_atomic_sig(&psVar1->max_req_size,size);
if (file != 0) {
kal_debug_update_buff_history
((struct kal_buffer_header_t *)new_alloc,int_context,1,size,file,line,
(undefined2)module_id,UserTraceData,(char)buff_num);
return new_alloc;
}
}
}
do {
trap(1);
} while( true );
}kal_os_allocate_buffer() 函数现在基本上只是新的“mer”堆实现的一个包装器,这意味着调用 mer_service_fixmem_alloc_blk()。在这里,“mer”结构是通过从所选池的描述符的 mer_pool_ptr 字段中获取的。
按照预期,对于基于池的堆,其实际算法使用了两级位图数组来选择第一个可用的插槽。需要注意的是,这引入了一个关键的算法变更:以前的池是从尾部开始分配的,但现在位图从头部开始进行填充,以支持连续分配。
void* mer_service_fixmem_alloc_blk
(struct mer_pool_desc_t *mer_pool,int *out_buffer,uint size_3,uint fileId,uint lineNum)
{
void* ret;
uint lvl2_slot;
uint new_lvl2_bitmask;
uint uVar1;
uint array_idx;
uint uVar2;
ret = 0xfffffffd;
if ((mer_pool->is_ready != '\0') && (ret = 0xfffffffc, mer_pool->pool_start != (void *)0x0)) {
mer_kernel_lock_take((int *)&DAT_249fb620);
uVar2 = mer_pool->lvl1_bitmask;
ret = 0xfffffffb;
uVar1 = reverse_all_bits(~uVar2);
array_idx = countLeadingZeros(uVar1);
if ((array_idx & 0xff) < (uint)(int)mer_pool->lvl2_size) {
ret = reverse_all_bits(~mer_pool->lvl2_bitmask[array_idx]);
lvl2_slot = countLeadingZeros(ret);
new_lvl2_bitmask = 1 << (lvl2_slot & 0x1f) | mer_pool->lvl2_bitmask[array_idx];
*out_buffer = (int)((int)mer_pool->pool_start +
mer_pool->pool_net_slot_size * (array_idx * 0x20 + lvl2_slot));
mer_pool->lvl2_bitmask[array_idx] = new_lvl2_bitmask;
if (new_lvl2_bitmask == 0xffffffff) {
mer_pool->lvl1_bitmask = 1 << (array_idx & 0x1f) | uVar2;
}
mer_kernel_lock_release_with_ei((undefined4 *)&DAT_249fb620);
ret = 0;
}
}
return ret;
}对于释放操作,free_ctrl_buffer_ext() 是 kal_release_buffer() 的直接包装器,它同样验证要释放的缓冲区。使用 kal_get_num、kal_is_valid_buff(),以及在分配未占满整个分区大小的情况下,通过 kal_debug_validate_buff_footer() 验证额外的填充防护值。
void kal_release_buffer(struct kal_buffer_header_t *address,undefined2 param_2,int file_name,
undefined4 line)
{
uint buff_slot_id;
uint internal_context;
uint ret;
struct kal_pool_desc_t *pool_desc;
ushort pool_idx;
struct kal_buff_history_node history_node;
pool_idx = 0xfeee;
if (address != (struct kal_buffer_header_t *)0x0) {
/* this verifies that the address actually falls into one of the correct pools
*/
buff_slot_id = __kal_get_buff_num(address,(short *)&pool_idx);
/* verifies:
* partition pool_ptr points to right pool
* header guard check
* paritition is within pool boundaries
* footer guard check (including correct slot for address)
ONCE AGAIN: no checking on the partition's mer pointer - but it is used in
the end!!! */
kal_is_valid_buffer(address,buff_slot_id);
pool_desc = address[-1].pool_desc;
kal_atomic_update(&pool_desc->pool_stat_mb->curr_allocated,-1,0xffffffff);
internal_context = kal_get_internal_context();
pool_desc->pool_stat_mb->buff_stat[buff_slot_id].field0_0x0 = internal_context;
__kal_debug_get_last_history_node(address,&history_node,(uint)pool_idx,buff_slot_id);
/*
this check verifies that this is a block that was last allocated, not freed
*/
if (history_node.is_alloc == '\x01') {
if (history_node.size + 4 <= pool_desc->pool_size) {
/* the actual size request is not in the partition header anywhere, so it can
only be taken from the history node. with that the potential additional
padding footer guard values can be verified correctly. */
kal_debug_validate_buff_footer(address,&history_node);
}
if (file_name != 0) {
kal_debug_update_buff_history
(address,internal_context,0,history_node.size,file_name,line,param_2,UserTraceData
,(char)buff_slot_id);
/* check the is_alloced bit */
if ((address[-1].hdr_guard >> 1 & 1) != 0) {
/* Sets whole buffer to "FREE" */
kal_set_free_pattern(address,pool_desc->pool_size);
/* sets the is_alloced bit */
address[-1].hdr_guard = address[-1].hdr_guard & 0xfffffffd;
}
ret = kal_os_deallocate_buffer((int)&address[-1].hdr_guard);
if (ret == 0) {
return;
}
}
}
}
do {
trap(1);
} while( true );
}如果检查确认无误,我们使用 kal_os_deallocate_buffer() 来实际释放算法分区。此方法实际上是对新的“mer”堆算法的一层封装,由 mer_service_fixmem_free_blk() 提供。在进行释放操作时,该函数按照预期“简单地”翻转了“mer”结构位图的必要位。为了找到正在使用的“mer”结构,此算法从分区头部获取指针。
uint mer_service_fixmem_free_blk(struct mer_pool_desc_t *mer_pool,int blk_address)
{
uint uVar1;
uint slot_id;
uint array_field;
slot_id = (uint)(blk_address - (int)mer_pool->pool_start) / mer_pool->pool_net_slot_size;
mer_kernel_lock_take((int *)&DAT_249fb620);
uVar1 = slot_id >> 5;
array_field = uVar1 & 0xff;
mer_pool->lvl1_bitmask = mer_pool->lvl1_bitmask & ~(1 << (uVar1 & 0x1f));
mer_pool->lvl2_bitmask[array_field] =
~(1 << (slot_id & 0x1f)) & mer_pool->lvl2_bitmask[array_field];
mer_kernel_lock_release_with_ei((undefined4 *)&DAT_249fb620);
return 0;
}2.3 新的合理性检查
首先要提到的重要变更是移除了分区的空闲列表,这有效地防止了空闲列表劫持攻击。
其次,在 kal_os_allocate_buffer() 返回选定的分区后,会验证其内联池描述符指针,确保它指向由 get_int_ctrl_buffer() 选定的同一个池描述符,这意味着我们不能简单地通过操纵分配过程,从其他池返回一个合法的分区。
接下来,我们在 __kal_get_buff_num() 中添加了一个新检查。这一措施至关重要,目的是为了减轻我们在之前文章中构建的任意位置分配原语。
这个函数不仅计算选定缓冲区的分区槽 ID(使用公式)((int)buff_addr - (int)pool_start) / ((g_poolSizeInfo[idx].pool_ptr)->pool_size + 20),而且在执行此操作之前,它使用全局数组 g_poolSizeInfo 验证选定缓冲区的地址是否落在任何有效池的范围内。
最后,kal_update_buff_header_footer() 调用验证了头部和尾部的防护值。这些值是已知的,但尾部包括分区 ID,因此对于每个(有效的)分区来说都是不同的。
显然,这些检查旨在确保我们不能操纵分配器返回一个未对齐或超出合法池的缓冲区。
另一方面,释放缓冲区时,首先再次使用 __kal_get_buff_num() 计算缓冲区号,这样就已经确保了我们不能对一个完全不在池范围内的地址进行释放。
此后,调用 kal_is_valid_buffer() 旨在验证缓冲区的合理性。一旦验证通过,就不是以遍历全局数组来找到合适大小的池描述符指针,而是直接从缓冲区头部获得。
这个结构有几次解引用,包括双重解引用以写入类似 pool_desc->pool_stat_mb->curr_allocated 和 pool_desc->pool_stat_mb->buff_stat 这样的字段,所以在已释放的头部中未验证的池描述符指针将导致任意地址写入。
kal_is_valid_buffer() 负责处理这个问题,因为在这里遍历池描述符列表,直到找到与头部中的地址相同的地址(匹配失败则中止)。除了这个匹配,该函数还检查了头部和尾部防护值的正确性,如分配路径中所示。
这并不是检查的终点,因为还有另一套机制在起作用:堆事件的环形缓冲区。虽然这看起来像只是用于调试目的,但实际上也用于此处的完整性检查。
在联发科的案例中,这些环形缓冲区不是用于整个堆,而是每个分区。每个池的历史数组存储在 (g_poolSizeInfo[pool_idx].pool_ptr)->pool_stat_mb->buff_stat 中,其元素类型为 struct kal_buff_history_desc_t。
每个历史描述符对应一个分区槽,因此历史数组使用计算出的 __kal_get_buff_num() 访问 history[buff_num]。每个元素包含一个有3个槽的环形缓冲区,包含堆事件节点,类型为 struct kal_buff_history_node。
0x0 0x4 uint uint context_id
0x4 0x1 char char is_alloc
0x5 0x1 char char pad
0x6 0x2 short short module_id
0x8 0x4 uint uint file
0xc 0x4 uint uint line
0x10 0x4 uint uint size
0x14 0x4 uint uint ts 正如我们所见,这种方法允许算法检查分区上的最后一个事件是否为分配,并检索请求的分配大小。如果检查不通过,堆将执行中止操作。如果通过,将进一步检查填充字节是否符合正确的保护模式,以防存在填充的需要。
最后,检查分区头部防护字段中的“is_alloced”标志位。如果这个标志位未被正确设置,系统不会采取任何行动。相反,如果该标志位设置正确,它将被反转,随后整个缓冲区将被标记为“FREE”模式。
综上所述,一个有效的分区应该满足以下条件:
- 位于请求大小对应的池内。
- 包含正确缓冲区的 4 字节,即 0xcpool_desc。
- 包含必须是 0xf1f1f1fX 的 4 字节。
- 包含必须是 0xNNNNf2f2 的 4 字节,其中 NNNN 是计算出的缓冲区编号 + pool_desc->pool_size。
- 如果打算释放,其最后一个分区历史节点作为分配。
- 如果打算释放且有填充字节,填充部分具有正确的 0xf2f2 模式。
需要指出的是,在所有这些检查中,任何一个失败都将导致中止(trap(1))的发生。
2.4 新的漏洞
经过这些详尽的步骤,我们来讨论针对堆的新漏洞。
尽管完全消除了分区头部的空闲列表,并增加了一系列新的检查,但“mer”实现的更改有一个致命弱点:分区头部和池描述符的指针在分配或释放过程中并未得到适当的验证,即mer_pool_desc_t。
这个漏洞的严重性在于,在这两种结构中,这些字段都是首先被定义的:
struct kal_buffer_header_t
0x0 0x4 struct mer_pool_desc_t * struct mer_pool_desc_t * mer_pool
(...)
struct kal_pool_desc_t
0x0 0x4 struct mer_pool_desc_t * struct mer_pool_desc_t * mer_pool_ptr
(...)此外,我们还注意到了一个显著的问题:在分配新的缓冲区时,并没有对所选缓冲区的"使用中"状态位进行检查。尽管在释放缓冲区时已经进行了这一状态的验证,但在分配过程中,这一步骤却被完全忽视了。
换句话说,在 kal_update_buff_header_footer() 中对头部防护字段的检查并不完整。虽然它试图验证防护值的其他位,但它简单地屏蔽了包含使用中位的最后一个半字节。
void kal_update_buff_header_footer
(struct kal_pool_desc_t *pool_desc,struct kal_buffer_header_t *new_buffer,
void *int_context,int size,int buff_num)
{
void *end_of_chunk;
/* Masks the in_use bit away */
if ((new_buffer[-1].hdr_guard & 0xfffffff0) == 0xf1f1f1f0) {
new_buffer[-1].int_ctx = int_context;
if (*(uint *)((int)&new_buffer->mer_pool + pool_desc->pool_size) == (buff_num << 0x10 | 0xf2f2U)
) {
if (size + 4U <= pool_desc->pool_size) {
end_of_chunk = (void *)((int)&new_buffer->mer_pool + size);
*(undefined *)end_of_chunk = 0xf2;
*(undefined *)((int)end_of_chunk + 1) = 0xf2;
*(undefined *)((int)end_of_chunk + 2) = 0xf2;
*(undefined *)((int)end_of_chunk + 3) = 0xf2;
}
return;
}
}
do {
trap(1);
} while( true );
}有了这些观察结果,我想出了许多方法来创建新的堆利用原语。
3 Bitflip-What-Where
如果我们对一个空闲的分区执行覆盖操作,就有可能破坏其所属的 mer 池描述符指针。在这种情况下,如果该指针被更改,对其字段的位图操作将变成无约束的"Bitflip-What-Where"操作,因为对该指针所指向的位置没有进行任何约束或检查。
uint mer_service_fixmem_free_blk(struct mer_pool_desc_t *mer_pool,int blk_address)
{
uint uVar1;
uint slot_id;
uint array_field;
slot_id = (uint)(blk_address - (int)mer_pool->pool_start) / mer_pool->pool_net_slot_size;
mer_kernel_lock_take((int *)&DAT_249fb620);
uVar1 = slot_id >> 5;
array_field = uVar1 & 0xff;
/*
bit flips at an arbitrary address */
mer_pool->lvl1_bitmask = mer_pool->lvl1_bitmask & ~(1 << (uVar1 & 0x1f));
mer_pool->lvl2_bitmask[array_field] =
~(1 << (slot_id & 0x1f)) & mer_pool->lvl2_bitmask[array_field];
mer_kernel_lock_release_with_ei((undefined4 *)&DAT_249fb620);
return 0;
}值得高兴的是,释放算法的其他步骤并不依赖于被释放分区的 mer 指针字段。因此,即使发生了这种位翻转,它也不会产生任何其他副作用,释放操作仍然会成功执行。
如果同一个分区被再次分配,损坏的 mer 指针可能会引起问题。但通过适当的堆整形,我们可以避免这种情况发生,因为分配算法优先使用空闲的时隙,而非后进先出(LIFO)方式。
这是一个非常强大的功能,因为它构成了一个任意位置的位翻转原语。
但在我们的特定案例中,这种通用技术并不适用于我们所研究的 CVE,因为我们无法写入任意的指针值。如果我们通过堆溢出破坏相邻分区的 mer 指针,我们只能在 PNCD 缓冲区分配内部或其相邻位置产生位翻转。
尽管如此,这种技术并非完全没有价值:由于溢出的指针指向的 PNCD 堆分配长度为 0x1C 字节,我们可以控制 mer 结构的所有字段,一直到第二级位图。接着,我们可以使这个位图数组与相邻的分配重叠。换言之,这个原语允许我们在最小尺寸(0x20)池中的分配内执行任意选定的位翻转。
struct mer_pool_desc_t
0x0 0x4 struct mer_pool_desc_t * struct mer_pool_desc_t * mer_pool
0x4 0x4 struct kal_pool_desc_t * struct kal_pool_desc_t * pool_desc
0x8 0x4 uint uint hdr_guard
0xc 0x4 void * void * int_ctx
0x0 0x1 char char is_ready
0x1 0x1 char pad
0x2 0x2 ushort pad
0x4 0x4 void * void * pool_start
0x8 0x4 uint uint pool_net_slot_size
0xc 0x2 ushort ushort partition_max_cnt
0xe 0x2 ushort ushort
0x10 0x1 char char lvl2_size
0x11 0x1 char pad
0x12 0x1 char pad
0x13 0x1 char pad
0x14 0x4 uint uint lvl1_bitmask
0x18 0x80 uint[32] uint[32] lvl2_bitmask实际上,由于 PNCD 溢出的灵活性,我们可以在多个相邻已分配分区上引发溢出。这意味着在32字节大小的池中,可以实现多个指定位的翻转,但它绝对没有在写入字节完全受控的溢出中那样强大。
如果我们观察一下攻击技术的堆的分配端便能很容易看出,同样的“破坏 mer 指针以获得任意位翻转”的技巧在这里也是可行的,但有几个区别:
-
第一,与释放路径不同,分配时的 mer 结构指针是从池描述符中获取的,因此溢出需要破坏相邻池的描述符,而不仅仅是相邻分区的描述符。现在这更容易实现,因为池是从开始处填充的。尤其在有喷射原语时,我们可以确保缓冲区溢出仅进入空闲的"无主地带"分区,直到它到达末端并破坏下一个池的描述符。
-
第二,与释放情况不同,分配情况下发生的位翻转当然有一个巨大的副作用:它立即返回一个(任意)值作为选定的缓冲区,而且可能导致中止。
4 任意分配的返回
此节探讨如何在一般情况下利用这个 bitflip 原语。
实际上,我们不必在堆外找到一个适合的受害者。如果我们在 g_poolSizeInfo 数组中翻转一个池边界值,我们就能绕过旨在防止“任意位置分配”模式的检查。
然后,触发相同溢出导致的后续分区释放被破坏,现在可以指向一个完全由攻击者控制的 mer 结构,并实现自由选择地址的回归。
当然,因为额外的分配检查验证了头部和尾部的防护值,我们不能强制任意地址成为返回的分配缓冲区,但在堆栈和全局内存中仍有很多机会,我们可以控制邻近某些我们想要目标的值。分配大小会上升到数千个,因此“邻近”的定义并不是那么严格。
5 不对齐分配的返回
这种攻击不需要对值进行额外的控制,在我们能够充分控制写入值的情况下,可以恢复之前的"未对齐分配"攻击,但这需要一个更强大的溢出原语。
虽然它不适合这个 CVE,但作为一个思考训练,我做了以下观察:
- 溢出到池描述符边界并破坏池的大小字段,可以操纵计算出的
buff_num成为任何值。 - 控制不仅是一个池的 mer 指针,还有一个(有效或假的)分区的池描述符指针和防护值,我们可以让任何一个不同于为大小请求意图的池的分区,或者分区内的一个不对齐位置被接受为有效分区。
这些方法都是可行的,可以使攻击者能够破坏其他实时分配的数据,但这确实需要比此 CVE 更好地控制覆盖值。有一种更简单、更强大的方法来接管其他分配。
6 双重任意分配
正如我已经描述的,对于分配情况,如果我们想损坏 mer 描述符指针,我们必须覆盖相邻池的描述符。
同样,由于现在池选择算法的第一个空闲槽性质,以及这个指针是池描述符的第一个字段这一事实,这对我们的 CVE 的损坏原语来说是一个实际的攻击。
另一方面,我们需要假的 mer 池描述符(即我们注册的 PNCD 分配的数据)来返回实际的有效分区,否则后续检查将中止。
我们也观察到“已分配”位被忽略了,这意味着通过完全控制 mer 描述符的所有值(包括第一级位图),我们可以返回一个实际上忙碌的完全合法分区。
最后,我们得到了一个接近完美的UAF原语。我们现在可以选择进入任何相邻池的分配,并创建一个能够分配的情况。
7 受害者分配
现在,我们已经从有限控制的堆溢出中制造出一个强大且通用的攻击原语。通过这种方式,我们可以接管目标池中的任何已分配分区,换句话说,我们可以为任何落入给定池的分配创建一个强大的UAF等效物。
在这个阶段,我花了很多时间寻找在CVE相关的池类中使用的受害者。
由于多种原因,在联发科基带中找到一个合适的受害者并不容易:
- 2G 代码库是用 C 语言编写的,没有 C++ 虚拟类对象实例提供方便的目标;
- 绝大多数任务上下文描述符结构实例都不存在于堆中;
- 事件或计时器对象这一传统目标也不再适用:尽管它们的结构布局使其成为理想的目标,但它们分配在各自独立的池中,这与每种大小池的“标准”列表不同。由于所有池的分配都在初始化时完成且不可更改,因此采用“交叉式缓存”式的方法是行不通的。
尽管如此,我最终还是找到了合适的堆整形和受害者分配选项。在之后的部分,我将分享如何确定受害者的分配。
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/3100/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/3100/
如有侵权请联系:admin#unsafe.sh