美国国家标准与技术研究院 (NIST) 近日发布了有关对抗性机器学习 (AML) 攻击和缓解措施指南, 呼吁人们再度关注近年来人工智能 (AI) 系统部署增加所带来的隐私和安全挑战,并表示目前没有万无一失的方法对这类系统进行保护。
NIST指出,这些安全和隐私挑战包括恶意操纵训练数据、恶意利用模型漏洞对人工智能系统的性能造成不利影响,甚至是恶意操纵、修改或仅仅是与模型交互,就可以外泄关乎个人、企业甚至是模型本身专有的敏感数据。
伴随着OpenAI ChatGPT 和 Google Bard 等生成式人工智能系统的出现,人工智能系统正快速融入在线服务,但支持这些技术的模型在机器学习操作的各个阶段都面临着许多威胁。NIST ,重点关注了四种主要类型的攻击:逃避、中毒、隐私和滥用。
- 规避攻击:目的是在模型部署后产生对抗性输出
- 中毒攻击:通过引入损坏的数据,针对算法的训练阶段进行攻击
- 隐私攻击:目的是通过提出规避现有防护措施的问题,收集有关系统或其训练数据的敏感信息
- 滥用攻击:目的是破坏合法的信息来源,如包含错误信息的网页,以重新利用系统的预期用途
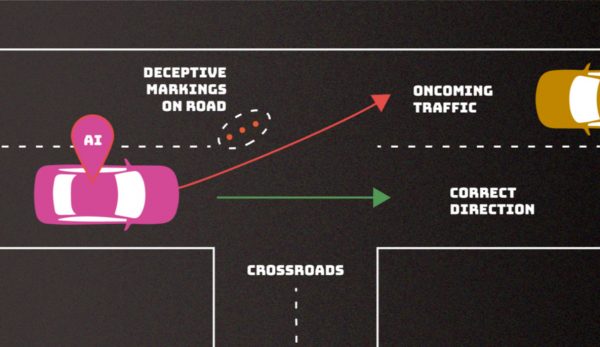
在规避攻击中,NIST 以对自动驾驶车辆的攻击作为示例,例如创建令人困惑的车道标记导致汽车偏离道路。

在中毒攻击中,黑客试图在人工智能训练期间引入损坏的数据。例如,通过将大量此类语言实例植入对话记录中,让聊天机器人使用不恰当的语言,以使人工智能相信这是常见的用语。
在隐私攻击中,黑客试图通过询问聊天机器人大量问题,并使用给出的答案对模型进行逆向工程,进而发现弱点来获取有关人工智能或其训练数据中存在的敏感数据。
在滥用攻击中,黑客将不正确的信息插入到源中,例如网页或在线文档,让人工智能吸收这些信息。与前面提到的中毒攻击不同,滥用攻击试图从合法但受损的来源向人工智能提供不正确的信息,以重新调整人工智能系统的预期用途。
NIST表示,上述攻击并不需要完全掌握人工智能系统某些方面的知识就可以轻松实现,希望AI业界能拿出更好的防御措施来应对这些风险。
转自FreeBuf,原文链接:https://www.freebuf.com/news/389195.html
封面来源于网络,如有侵权请联系删除