


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

一、前言
之前在挖某SRC,和carrypan师傅交流了一番,发现他在js接口里面收获颇多,找到很多敏感信息与未授权访问,本着学习的心态我开始研究如何高效地寻找目标网站js中存在的接口
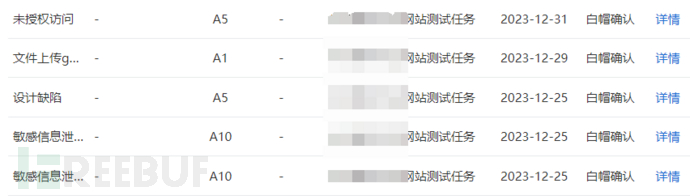
贴一张SRC的收获图片:
二、思路历程
接口路径收集可能很多人会先想到URLFinder,这个工具确实不错
虽然也能自定义规则,但是没有详细参考文档。于是我就选择了资产灯塔ARL里面的插件wih
使用文档参考:https://tophanttechnology.github.io/ARL-doc/function_desc/web_info_hunter/
这里为了单独使用wih功能,直接从docker启动版本里面把wih文件拉出来
 wih自带的规则文件wih_rules.yml,其中有一条内置规则为匹配路径,默认是不开启该规则的
wih自带的规则文件wih_rules.yml,其中有一条内置规则为匹配路径,默认是不开启该规则的
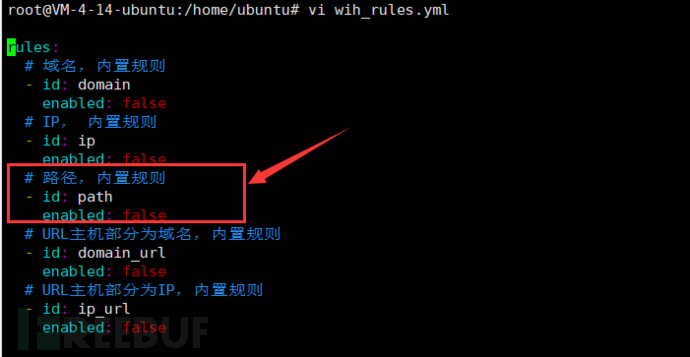 修改路径规则的enable为true,关闭其他剩下的规则
修改路径规则的enable为true,关闭其他剩下的规则
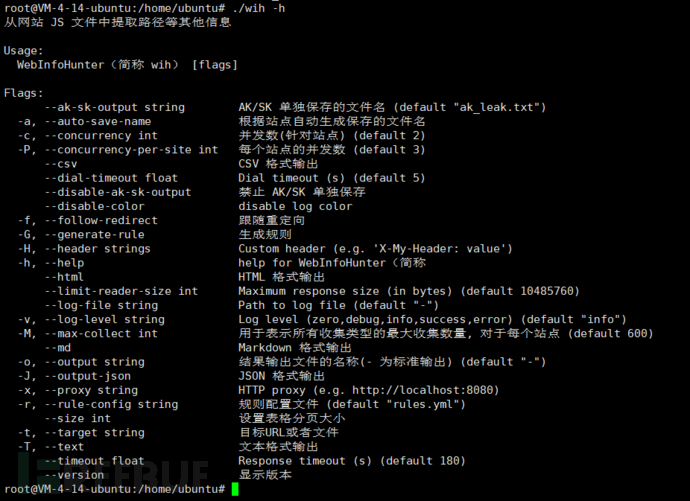
根据wih命令,-a为自动保存,-c和-P调整并发数
可能是为了适配ARL,所有是按域名来保存的,这样对我们来说很不友好,不方便查看
好在wih还有一个json格式导出的功能,但是只是打印结果,不是输出json,于是就要写一个python脚本来协助处理一下数据
主要处理的步骤如下:
1、读取wih的json结果,匹配路径等信息
2、拼接域名和路径并请求,返回状态码和长度(后来我注释掉了这段功能代码,因为请求很可能会被封禁,不利于后续的测试)
3、输出所有结果,并整合进一个html页面中方便查看
代码如下,需要将wih和wih_rules.yml放在同一目录下面:
import argparse
import subprocess
import json
import re
import requests
import time
from concurrent.futures import ThreadPoolExecutor
import os
from datetime import datetime
import glob
# 在 run_command 函数中保存输出和链接
def run_command(target):
command = f"./wih -t {target} -r wih_rules2.yml -J -c 10 -P 10"
result = subprocess.getoutput(command)
# 使用正则表达式提取JSON结果
json_matches = re.findall(r'\{.*\}', result, re.DOTALL) # 使用正则表达式提取JSON
if json_matches:
for json_match in json_matches:
try:
json_data = json.loads(json_match)
# 对JSON字符串进行处理
# 例如,打印JSON中的特定字段
# print(json_data)
output, check_links = get_size(json_data)
# 保存输出
target_name = target.replace('htt