In this blog post we will see how to use basic Python Script in SAP Datasphere. The aim of th 2024-1-4 08:47:22 Author: blogs.sap.com(查看原文) 阅读量:47 收藏
In this blog post we will see how to use basic Python Script in SAP Datasphere. The aim of this post is not to teach you an expert Python coding, but you will see elementary features of its usage in SAP Datasphere. Instead of learning complex Python functions, you will just see how to update or insert columns of a local table by data flows. For more detailed and formal information you can refer to SAP documents.
Use-case scenario
Let’s assume that we have a list of characters from the movie “The Lord of the Rings (LOTR)”. We uploaded data from an excel file to a local table named “TAB_LOTR_001 – LOTR CSV Source File”. By the way, I am not going to mention how to upload a flat file to SAP Datasphere in this blog post.
The raw data of our input table is as follows:

Data Flows with Python Script
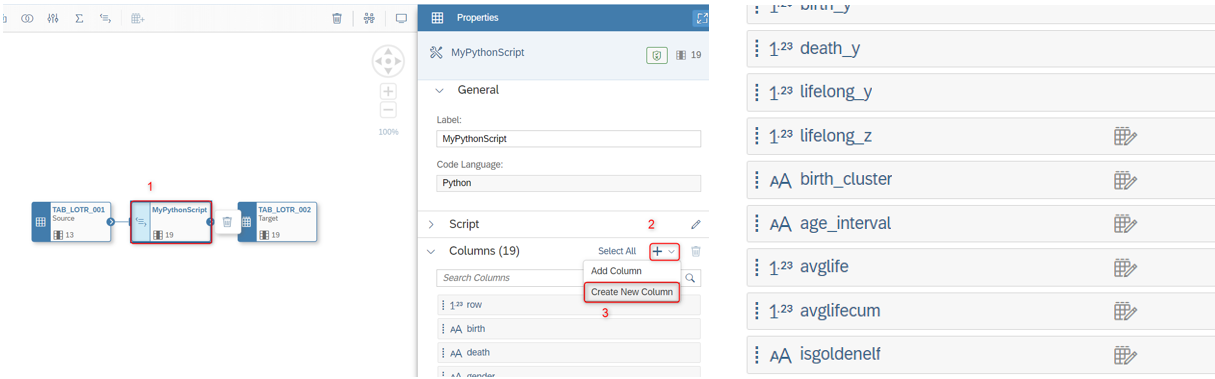
In this post, I would like to show you the logic with 2 data flows and 2 output tables. I assumed that you have already know how an output table (type: target) is created automatically in a dataflow. After creating following objects, we have clicked the Script button and added the Python Script step between source and target tables:
Output Table: TAB_LOTR_002 – LOTR Updated Table 1
Data Flow: DF_LOTR_001 – LOTR Data Flow 1

As you can see in the above picture, target table has 6 new columns which will be calculated in the script soon.

You can add new columns in the same data type and length that you added in the local table. You can find the steps below.

After everything is ready, you can start to implement your code by clicking on the pencil button.

New column: lifelong_z
By using the features of Python, you can update all columns in a single step. Here you can see how to multiply all values in a column by 2 and write it to a new column.
![]()

New column: birth_cluster
First we can open a for-loop in order to calculate our new columns. “len(data)” returns us the row number of the table and we are looping in this range. The variable “i” is the index number i.e. row number starting from zero.
In the first step you can also see how we should have updated a current column by “pandas.DataFrame.loc” which will update the ith line and the column “row”.
In the second step, the code checks the column “birth” and makes a clustering by taking first 2 letters of it unless it is mentioned as “Before CA”. Therefore, we have added an if-condition.


New column: age_interval
We can also group our characters’ age with a group of 0,100,200,1000 and more.

In our “for-loop” we can add the code block below. You can enhance the code by more complex conditions regarding your needs.

New columns: avglife & avglifecum
It is time to calculate the average life duration and its cumulative value in two different columns. Since there are already built-in functions and we know that we could have calculated in a single step like in line 18, we would like to show you how to do it in a primitive way. First, we have initialized two local variables.
![]()
We have calculated the sum and average of the lifelong year of a character via built-in functions. The column “avglife” is assigned directly to “lv_avg” however we have a new logic in “avglifecum”. The request is that the whole sum should be divided into the row number in each line.
![]()
These calculations are implemented before the “for-loop”. Now we increment the count in each line and divide the sum for each row to achieve a cumulative sum. Actually, this is a reverse cumulative sum, but you can change the logic as you need. The aim is to show some simple steps and make the code interesting by adding some cases.

In the last row you can see that the value of “avglifecum” equals to “avglife” which is “953.82” since the sum is divided by correct row count which is 389.

New column: isgoldenelf
You may have realized that the row count decreased from 389 to 379 in the screenshots. This is because of our new logic about golden-haired elves. We want to delete these characters from our new table. To establish this, we must mark them in a new column. In fact, we don’t need “isgoldenelf” column in output but used it in within the code blocks.
First, the script logic was giving errors during the calculations, so we filled the rows in the “race” and “hair” columns with a dummy value “no-race” and an empty string before the “for-loop”.
![]()
Then, within the “for-loop” we added the following code. Let me explain all the lines in detail.

Line 49: We translate the values in “hair” column to lower case to avoid discrepancies.
Line 50: Then we mark all rows with an “X” in “isgoldenelf” column.
Lines 51-53: if the race of our character bleongs to “Elf” or “Elves” with a golden hair we assign a “D” instead of “X” in the column “isgoldenelf”.
Next, there can be many options to delete rows from a table. Here you can see how we did it. We have masked all lines including “D” with null or not assigned value . In short, we have N/A instead of “D”.
![]()
Hence, we can delete all lines with a not assigned value in column “isgoldenelf”.
![]()
10 records in the source table are deleted from the target table.

Python Script 1
You can find the whole code here:

Adding new lines to the table
Let’s create a new output table and use the previous target as source. Here we will manipulate the data by adding new lines with respect to the new conditions.
Output Table: TAB_LOTR_003 – LOTR Updated Table 2
Data Flow: DF_LOTR_002 – LOTR Data Flow 2

For each race type Hobbit, we want to add a new soldier with an ID of row count.

The new lines are as follows.

Conclusion
Your needs may differ, but I would like to describe what I did. I hope it will help you to have an idea before you start using Python script. Since Python is a powerful programming language, you can implement any logic with complex scenarios. Thanks for reading until so far.

如有侵权请联系:admin#unsafe.sh