
12/22/2023
14 min read

Many applications rely on user data to deliver useful features. For instance, browser telemetry can identify network errors or buggy websites by collecting and aggregating data from individuals. However, browsing history can be sensitive, and sharing this information opens the door to privacy risks. Interestingly, these applications are often not interested in individual data points (e.g. whether a particular user faced a network error while trying to access Wikipedia) but only care about aggregated data (e.g. the total number of users who had trouble connecting to Wikipedia).
The Distributed Aggregation Protocol (DAP) allows data to be aggregated without revealing any individual data point. It is useful for applications where a data collector is interested in general trends over a population without having access to sensitive data. There are many use cases for DAP, from COVID-19 exposure notification to telemetry in Firefox to personalizing photo albums in iOS. Cloudflare is helping to standardize DAP and its underlying primitives. We are working on an open-source implementation of DAP and building a service to run with current and future partners. Check out this blog post to learn more about how DAP works.
DAP takes a significant step in the right direction, but private aggregation alone is often not sufficient to protect privacy. In this post, we explain the shortcomings of DAP, and how we can improve it by adding differential privacy.
The problem: private aggregation is not enough
DAP uses a cryptographic technique called multi-party computation. At a high-level, multi-party computation increases privacy by distributing the computation of the aggregate across multiple servers such that no server sees any individual's data in the clear. (See our earlier blog post on DAP for a primer on multi-party computation.) At first, it may seem like this ought to be sufficient to protect the privacy of each individual user: the data collector learns only the information it needs (namely, the aggregate), and not the underlying data used to compute it. Unfortunately this is often not the case because the aggregate itself can sometimes reveal lots of private information.

As a trivial example, computing an average over a set of numbers with just one input in it reveals the value of the unique element in the set. But even learning the sum of some numbers can also reveal whether there is a particularly large or small number in the set. For example, suppose we're computing the average height of a group of people. If a member of the group is particularly tall (as illustrated above), then knowing how many people are in the group and the expected average height, we can infer a significant amount of information about that individual's height.
More generally, releasing too many accurate aggregates about a database can allow an attacker to reconstruct the whole database.
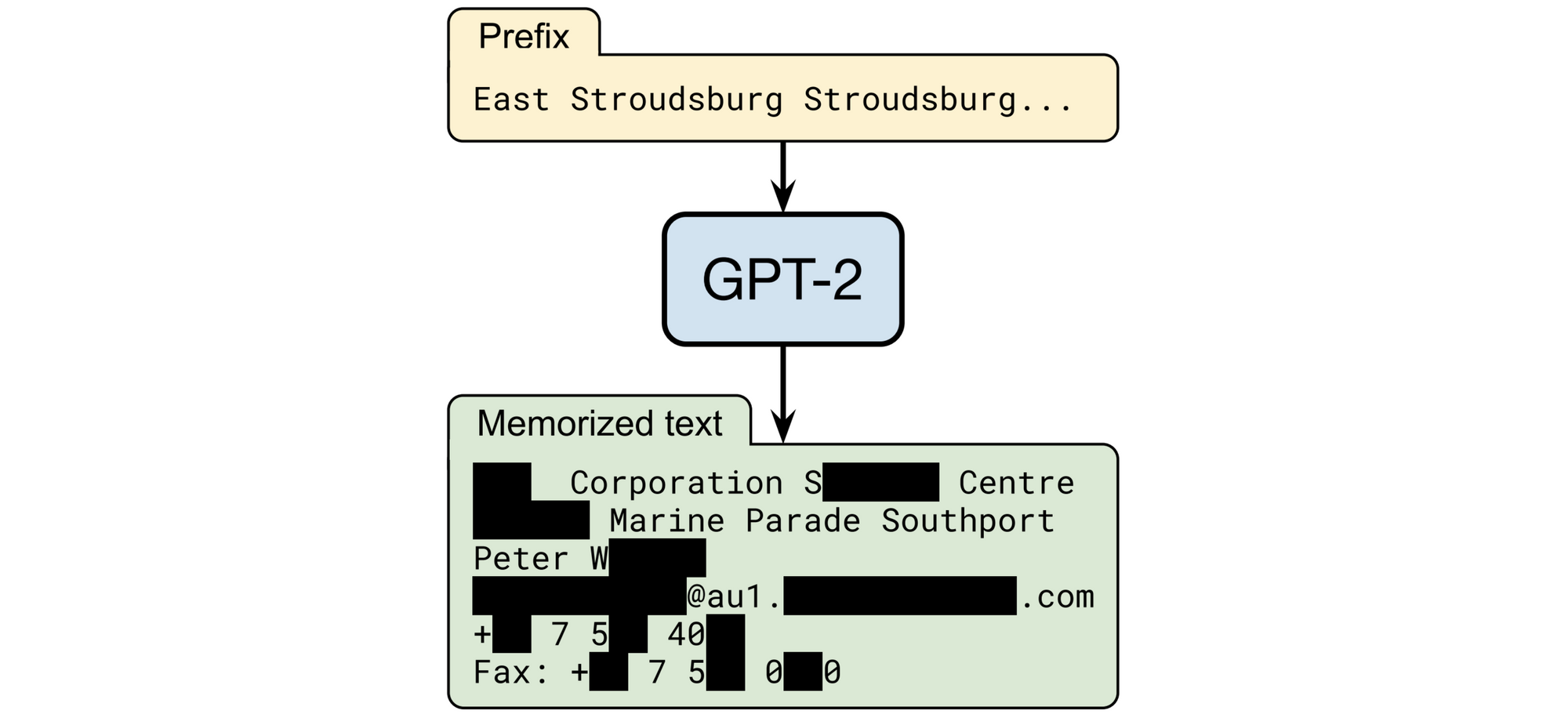
Such attacks exist in real life. For instance, deanonymization attacks against the U.S. Census have been credibly demonstrated. Large language models, such as ChatGPT, are also vulnerable; a machine learning model can be seen as a particular type of statistical aggregate computed over a training dataset. Here is an example of an attack, where researchers gave a special instruction to GPT-2 and extracted the name, address and phone number of a real individual whose data appeared only once in the training dataset:
One way of protecting the inputs to model training is a technique called federated learning, where the data are kept on end user devices and model updates are aggregated by a central server. (The aggregation step can even be done in DAP.) Yet even these systems are vulnerable to clever attacks that can leverage the final model, along with some intermediate versions, to reconstruct sensitive data.
We illustrate this idea in the figure below, which comes from a recent paper describing an attack on a machine learning model being trained for image classification. In this example we begin with 8 users, each of whom has one labeled image (e.g. an image of a cat that has been labeled “Cat”). These starting images are referred to as the Ground Truth. Each user runs their image through the image classification model to see if it can accurately label what is in the photograph. When the model misses, it generates a model update — a set of data that tells the model how to improve itself, so that it more reliably recognizes that user’s photo next time.
All eight users generate their own model update locally, and then federated learning is used to take the average of those model improvements, in a manner ostensibly designed to avoid any individual update or photograph from being extracted. However, researchers were able to exploit this approach.
The goal of the attack is to reconstruct the 8 Ground Truth images in the bottom row of the figure, with only access to the federated, average update. The attacker starts from a random guess ("Initial"), and progressively improves it by moving the guess in a direction that would give an update similar to the true average update. After enough iterations, we see that the images in the attacker's guess ("Fully Leaked") are close to the images in the true Ground Truth dataset, although the order can be different.

These attacks suggest that private aggregation (with DAP or by some other means) is not sufficient for privacy. Luckily there is a way forward: a variety of organizations, including Apple, and Google, the U.S. Census Bureau and a growing set of industry and government actors, now use differential privacy to protect their data.
Differential privacy
Differential privacy (DP) is a statistical framework that provides an extra layer of data protection for secure aggregation systems. It adds noise to aggregates, to prevent attackers from learning too much about any individual. Roughly speaking, the amount of randomness added is inversely proportional to a privacy parameter, typically denoted by the Greek letter 𝜖 (pronounced "epsilon"): a small 𝜖 is more private but has noisy results, while a large 𝜖 is less private but more accurate. In this way, 𝜖 rigorously quantifies the amount of information revealed by the aggregate.
To be fair, even without differential privacy, some deployments of computing statistics on sensitive datasets already provide guardrails against the most blatant privacy violations, by imposing certain restrictions. For instance, DAP has a mechanism for preventing the data collector from aggregating batches of inputs that are too small. In other settings, it's possible to redact certain attributes when they do not appear often in the dataset, or to limit the number of times a data point can be aggregated. However, it is easy for such ad-hoc privacy protections to make assumptions about the data that turn out to be invalid.
First, these restrictions are essentially “patches” against some obvious attacks, but do not necessarily cover every possible attack. For instance, some aggregation tasks are particularly sensitive to outliers could still leak whether a particularly unusual measurement is part of the aggregation set. Moreover, while simple aggregates such as sums are easier to protect with handcrafted rules, multidimensional and structured statistics such as (averaged) neural network updates can leak a surprisingly large amount of information, as shown in the previous section. On the contrary, differential privacy is a general property that protects complex statistics even against adversaries we know nothing about.
Second, another benefit of differential privacy is that it harmonizes the security parameters across applications: the privacy guarantees are expressed as a particular value for 𝜖, that can be compared across use cases going from bit counts to federated learning. The value of 𝜖 can also be communicated publicly or discussed with DP experts. While setting 𝜖 is still a complicated matter (see below), it is at least less application-dependent than setting parameters such as the number of measurements to aggregate. In fact, the differential privacy parameter constitutes an extra degree of freedom which disentangles privacy from other application-specific parameters, giving more control over tradeoffs between utility and privacy (e.g. it is possible to fix 𝜖 first, and then independently decide on the batch size for an aggregation task).
Finally, most handcrafted protection and anonymity techniques do not offer the same elegant and practical properties as differential privacy. For instance, DP guarantees degrade gracefully when groups of reports are correlated, or when the same underlying data is aggregated multiple times (which is essential in some applications like federated learning), while ad-hoc methods or definitions such as k-anonymity can fail catastrophically in these cases. DP has other desirable properties, such as resilience to side information (for instance, some real-life privacy attacks can leverage datasets purchased from data brokers).
Fundamentally, differential privacy transforms the cat-and-mouse game of privacy engineering into a rigorous, mathematical framework in which privacy is proven, not merely claimed.
The science of privacy engineering: Making DAP differentially private
As an intern at Cloudflare (Summer 2023), my task was to devise a strategy for endowing DAP with differential privacy, while optimizing for some of Cloudflare's use cases for DAP that we’ll explore in this post. There are many ways to do this. We highlight three techniques, that come with different threat models:
- The simplest way is to compute the aggregate as usual, and then add noise to that. The DAP protocol defines a role known as the "Collector", who is the intended recipient of the aggregate result. The Collector could add noise itself (which we might call Collector Randomization or Central DP). The problem of course is that the aggregate result is not DP from the point of view of the Collector.
- Another method – called Local DP, or Client Randomization in the DAP context – is to ask each client to add noise to its report before submitting it. This provides strong privacy guarantees (DP holds even if all the Aggregators and the Collector are malicious) but usually comes at a cost in accuracy. This is because more noise has to be added to each measurement in order to achieve privacy. Though recent advances make such protocols practical in some cases.
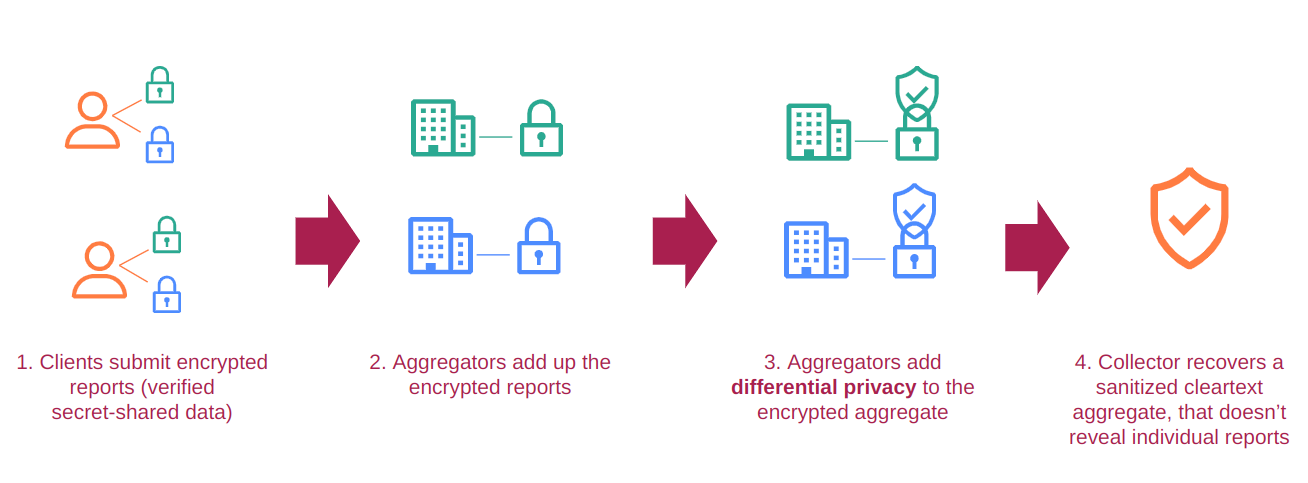
- DAP involves another role, called an "Aggregator", that computes a share of the aggregate result. (Combining the Aggregators' share yields the aggregate result.) As a middle-ground, we can have each Aggregator add noise to its aggregate share, thereby ensuring that the aggregate is DP from the point of view of the Collector. We must trust, of course, that at least one Aggregator is honest and adds noise from the proper distribution.
This third method, which we'll call Aggregator Randomization, is the method we decided to investigate during my internship. It is straightforward to implement, has about the same computational overhead as basic Central DP, and satisfies the same threat model as DAP (more on that later!). Aggregator Randomization is illustrated below.
Although our Aggregator-Randomization version of DAP seems straightforward, we need to be convinced that it provides the privacy guarantees we expect. That means writing down the protocol and carrying out a formal analysis of its guarantees.
Interestingly, the traditional definition of DP and the standard proof techniques do not apply immediately to our setting. Indeed, unlike most DP mechanisms, DAP is an interactive protocol involving many parties (Clients, Aggregators, Collector) distributed across the Internet, and some of them might be malicious. Moreover, DAP’s security is based on computational assumptions (we assume that certain cryptographic problems, like cracking AES, are prohibitively costly), which consider adversaries that might run in a "reasonable" amount of time. Standard notions of DP consider adversaries that have arbitrary run time.
Luckily, other protocols combining differential privacy with multiparty computation have been studied in the past, and there are suitable definitions under the umbrella of Computational Differential Privacy. This definition of DP makes it possible to model a computationally bounded adversary interacting with a real-world protocol containing cryptographic components. However, more work needs to be done to build a generic framework for composing DP mechanisms with existing DAP subroutines (that already come with proven security guarantees).
Example: Making Network Error Logging private
To keep things concrete and get some experimental data, we looked for real-life DAP use cases where differential privacy could be useful and immediately applicable. Consider a protocol that privately aggregates and reports client-side connection errors to an origin, as a privacy-preserving alternative to Network Error Logging (NEL). It is a good use-case for DAP, because it is desirable to collect aggregate statistics (e.g. number of tcp.timed_out errors for a particular domain, or domains with the most errors in the past 24 hours), but individual reports may reveal sensitive information about browsing habits.
For simplicity, let’s focus on the case where the list of domains is already known, e.g., to track connection errors for a single domain, or across a closed set of paying customers. For the rest of the blog post, you can assume that we are using a DAP deployment to compute a histogram of connection errors for a single domain (but other statistics from the DAP specification share the same structure, which makes them suitable for similar DP mechanisms). The true aggregate might look something like this:
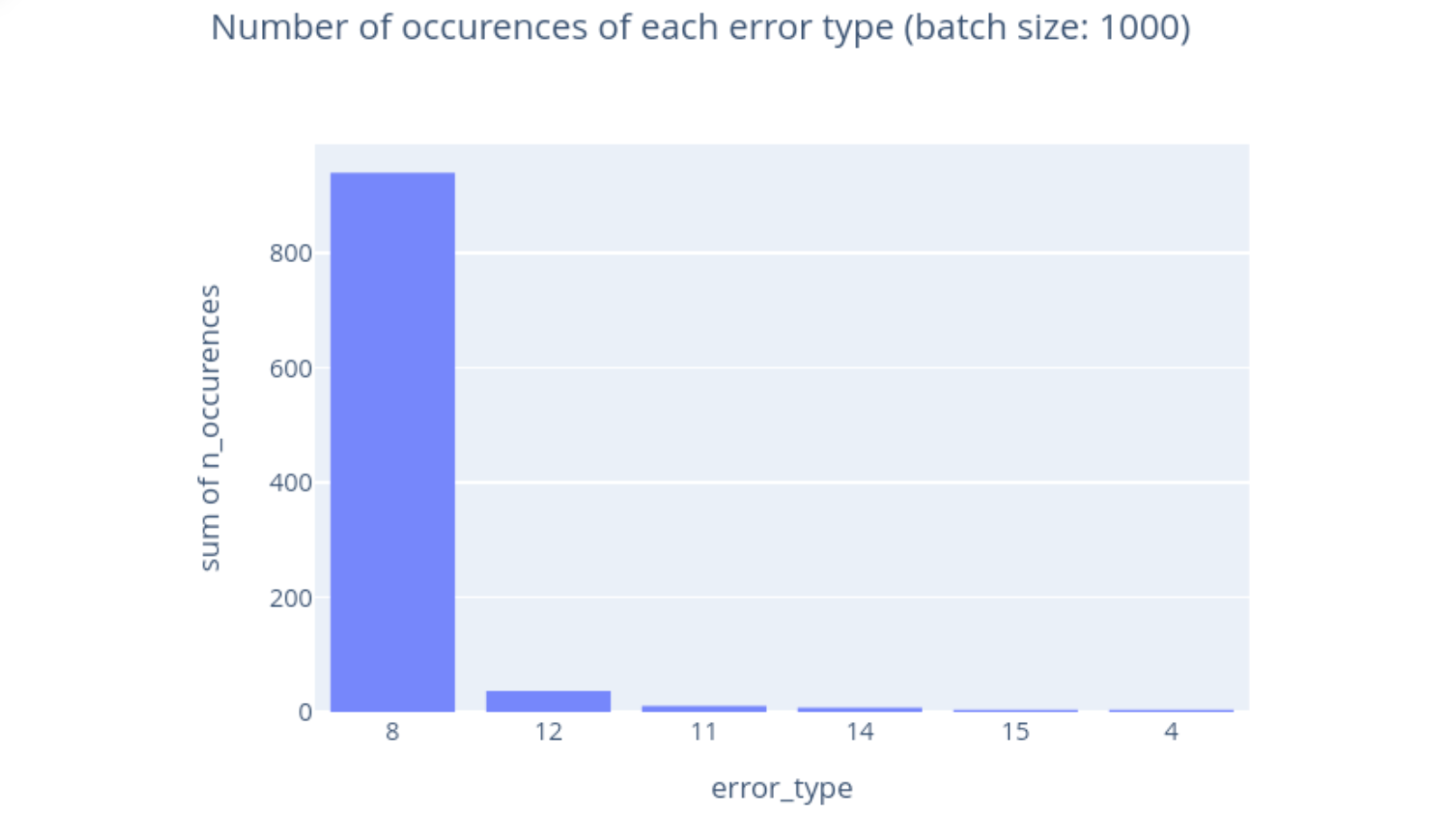
In this figure, we see a typical distribution of errors from 1,000 reports. The actual error types are irrelevant, and thus are just represented by numbers here. error_type = 8 is by far the most common, but we observe a smattering of other error types as well.
As we saw earlier, this aggregate information might still leak sensitive information – for instance, if an error type occurs only once, we might be able to tell whether a particular user visited a certain website. Now, our goal is to modify DAP to output a slightly noisy version of the histogram, so that it doesn’t leak information about individual reports.
libprio-rs is a widely-used Rust implementation of the cryptographic primitives used in DAP. To add DP, we started by designing a general API that any Aggregator Randomization scheme should satisfy, with objects to represent privacy budget and noise addition. Then, we implemented the DP API for concrete statistical aggregates. After reviewing various DP mechanisms, we settled on the discrete Gaussian and the discrete Laplace mechanisms, because of their clear guarantees and their suitability for modular ring arithmetic. We leveraged a secure noise sampler written in Rust by the OpenDP library. After adapting the Daphne implementation of DAP, we were able to run a toy deployment of DAP with differential privacy on network error logging data!
The art of privacy engineering: Exploring the privacy-utility trade-off
Recall that differential privacy involves a parameter, 𝜖, that determines the degree of privacy our system can achieve. From the code's perspective, any positive real number is a valid choice here: smaller is more private, but also less useful. So what should we pick for 𝜖?
Up until this point, we have treated DP engineering as a science, but choosing 𝜖 remains somewhat of an art. To illustrate, let's go back to our NEL data and compute some DP histograms for the network errors on one domain. Here are noisy histograms for different values of 𝜖:
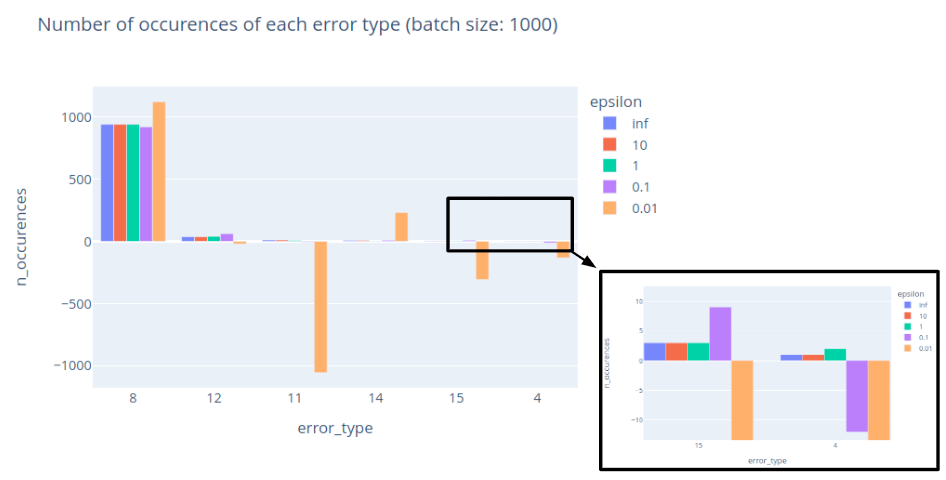
We observe that decreasing 𝜖 yields noisier results, even giving negative counts in some cases – although we can always truncate or round results without losing privacy. Since this example has many reports and a few possible errors, it is reasonably easy to mask the contribution of any single individual. Here we see that 𝜖 = 1 seems to be a reasonable choice for this use case. We can still observe that the relative error is higher for rare events (such as error_type = 15) than for common errors (such as error_type = 8).
Let’s focus on these two events, and look at how 𝜖 impacts accuracy:
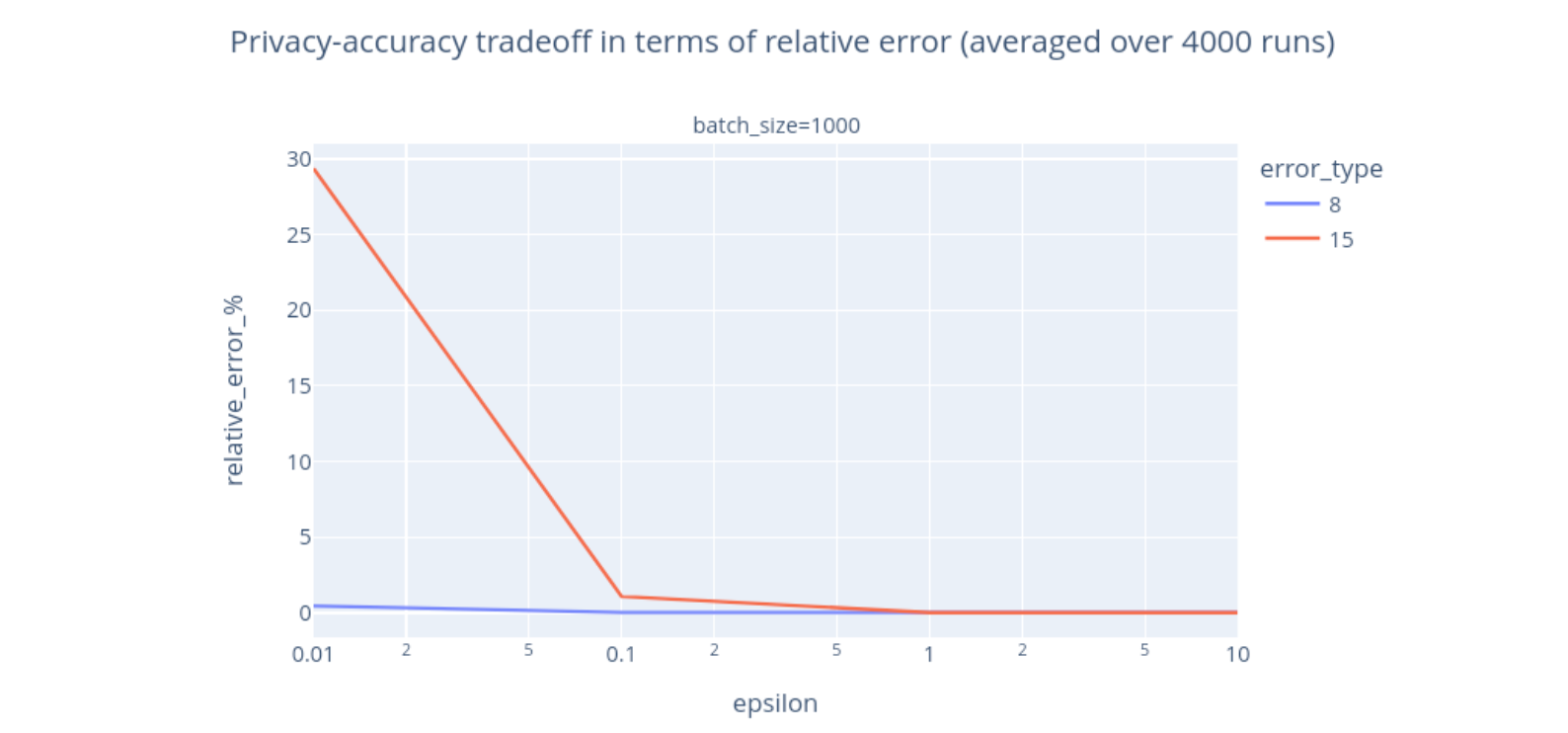
It becomes clearer that the accuracy increases with 𝜖 – an aggregate that is less noisy is also less private and more accurate. This tradeoff is known as the privacy-utility tradeoff. You can notice that the tradeoff depends on what we are measuring. If we are only interested in error_type = 8 and can tolerate at most 2% of relative error, then using 𝜖 = 0.01 would be sufficient. If we are interested in error_type = 15, then we would need to use 𝜖 = 0.1 to reach the same level of accuracy.
We can also look at how other parameters, such as batch size, can impact accuracy for a fixed privacy guarantee:
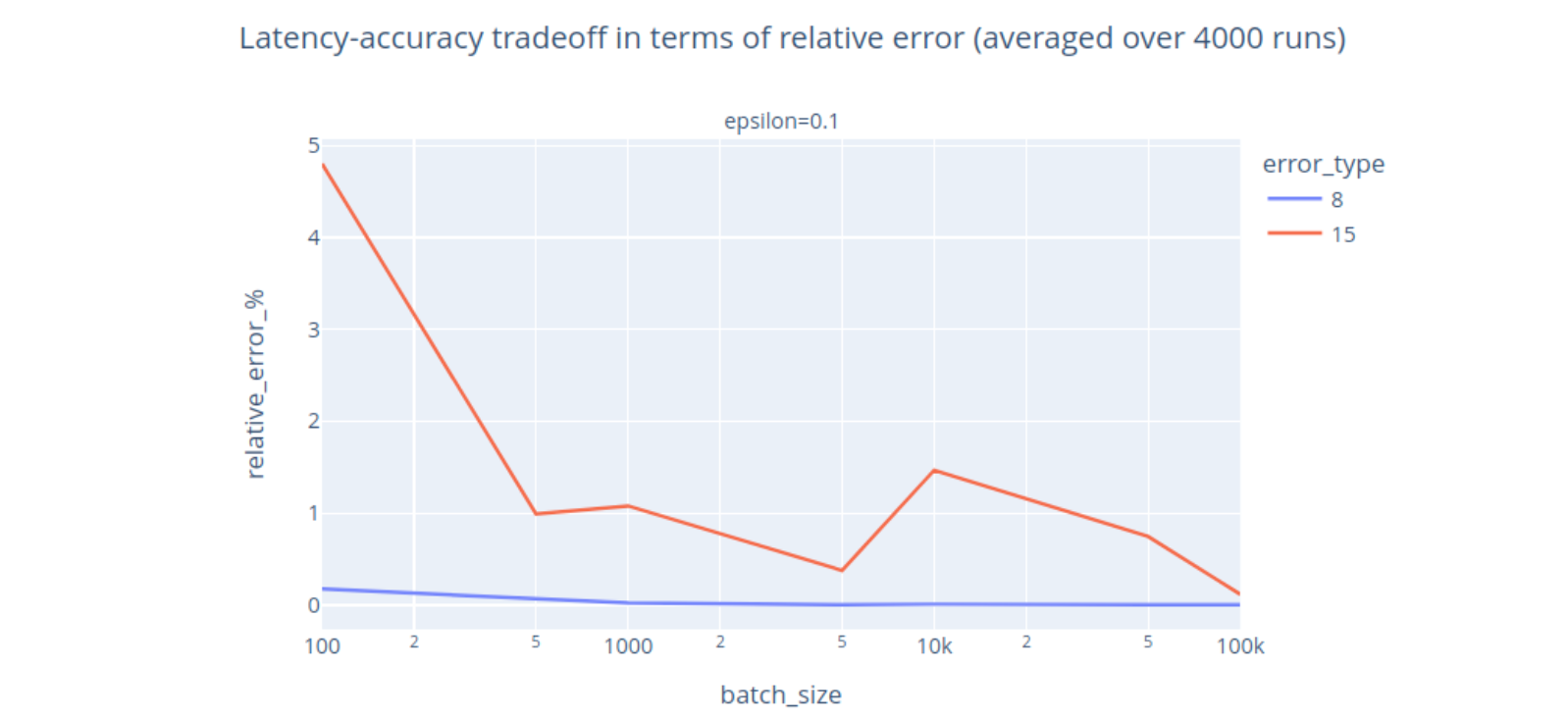
Intuitively, if we wait longer before computing an aggregate, we can get more accurate results for the same privacy level, because it is easier to mask a contribution if it is drowned in a large batch. As noted previously, we can set the privacy level upfront and adjust aggregation parameters later. If we try to collect an aggregate over a batch of size 1, the DP result will simply be close to random, and therefore protect the value of the single report in that batch. This graceful degradation – output useless results rather than breaking privacy on small batches – can be a problem in applications where accuracy is particularly important, but it can be controlled by choosing an 𝜖 that satisfies a comfortable accuracy-privacy tradeoff. It is always possible to get more accurate results, if we are willing to pay the privacy price for it.
Which brings us back to the question: what is a good value for 𝜖? Unfortunately, experts still haven’t reached a consensus on the right method to find 𝜖, as noted in this 2019 paper by Cynthia Dwork (one of the inventors of DP), Kohli and Mulligan. Indeed, some values of 𝜖 are suitable for certain deployments, algorithms, datasets or threat models, but not others. Unlike cryptographic applications that force attackers to guess a key that might have 2^128 values, 𝜖 has to be set to some non-negligible value in order to learn anything useful from the data. Ultimately, the notion of usefulness and what constitutes a privacy harm is dependent on the application.
Until we have a better understanding, a simple approach for non-experts is to search for the “standard” 𝜖 used in similar applications, and maximize accuracy under that privacy constraint. This method works if we have access to an “𝜖 Registry”, a detailed list of deployments for various use-cases and threat models. The US Census Bureau has an internal registry, but only some use cases are published so far. NIST gives some recommended ranges in this informal blog post (tldr: 0 < 𝜖 < 5 is strong, 5 < 𝜖 < 20 can be enough in practice). This blog post lists 𝜖s for deployments from Apple, Google and others.
There are additional strategies to set or evaluate the empirical guarantees of 𝜖. A complementary approach is to determine the maximum error you are willing to accept (e.g. 5% relative error on a count) and use simple properties of standard DP mechanisms to find the corresponding value of 𝜖 and check that it falls within an acceptable range.
Conclusion
As secure aggregation protocols such as DAP are increasingly deployed in real-world applications, it is important to remember that secure aggregation is not always enough to satisfy the users’ expectations of privacy. Differential privacy adds an extra layer of protection to these protocols. In short, secure aggregation protects the “how” (how to compute an aggregate from a set of reports), and DP protects the “what” (what kind of noisy aggregate we should release to avoid leaking too much information).
Thanks to the growing number of open-source implementations, applied research and standardization efforts for differential privacy and secure aggregation, there is now a clear path to integrate DP and DAP, thereby strengthening the privacy guarantees of practical measurement tasks. Interestingly, during our analysis we identified some parts of the DAP protocol that could pose problems with some forms of DP guarantees, such as the fact that Aggregators have access to the number of measurements or to the IP addresses of Clients. These findings, along with more thinking about the protocol logic, nourished debate around this and other topics at the IETF.
We also encountered many details that are often overlooked in the DP literature, such as modular arithmetic, API considerations, secure sampling or timing attacks. Overall, there is space for fruitful collaborations between cryptography and differential privacy experts, on protocols that can have a real impact.
If you're interested in getting hands on with differential privacy, DAP, or any of Cloudflare's other privacy-focused projects, consider applying for an internship on the Research team.
Acknowledgements
I’d like to thank my fantastic mentor Christopher Patton for guiding me during the summer – I learned many things from cryptographic details to IETF standards, and had a lot of fun along the way. Thanks to Josh Brown and Tanya Verma for our discussions, and to Avani Wildani and the rest of the Research team for their incredible support!
We protect entire corporate networks, help customers build Internet-scale applications efficiently, accelerate any website or Internet application, ward off DDoS attacks, keep hackers at bay, and can help you on your journey to Zero Trust.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you're looking for a new career direction, check out our open positions.