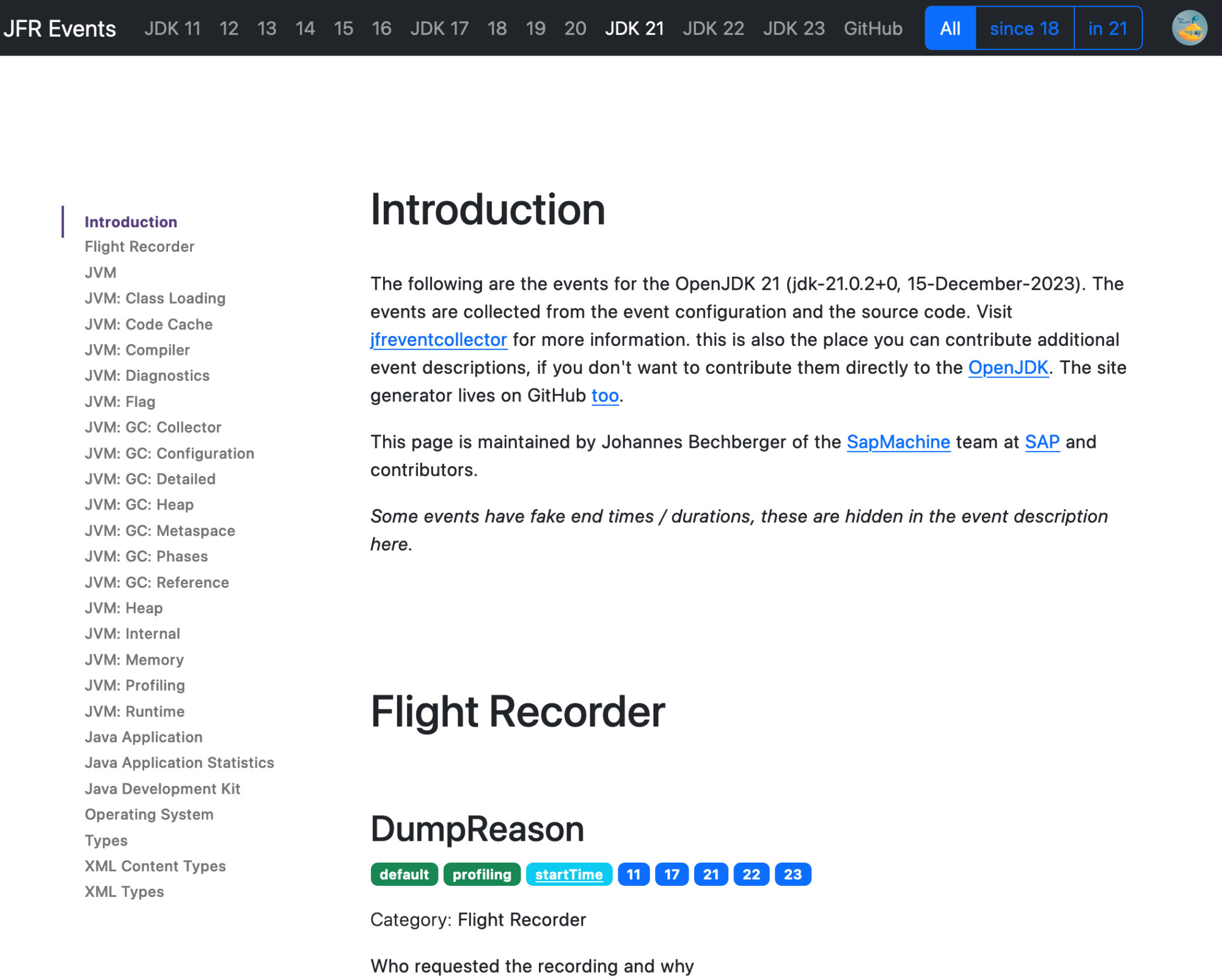
JFR (JDK Flight Recorder) is the default profiler for OpenJDK (see my other blog posts for more information). What makes JFR stand out from the other profilers is the ability to log many, many different events that contain lots of information, like information on class loading, JIT compilation, and garbage collection. You can see a list of all available events on my JFR Event Collection website:

This website gives an overview of the events, with descriptions from the OpenJDK, their properties, examples, configurations, and the JDK versions in which every event is present. However, few descriptions are available, and the available texts are mostly single sentences.
TL:DR: I used GPT3.5 to create a description for every event by giving it the part of the OpenJDK source code that creates the event.
For most events, I state the lack of a description, coupled with a request that the knowledgeable reader might contribute one:

But as you can see, there is not really any progress in creating documentation. So, I have two options left:
- Ask knowledgeable JDK developers to add descriptions: It’s time-consuming, and it would only be added in the next release
- Write the descriptions myself directly for the website: This is pretty time-consuming, with over 150 events per JDK version.
- Task AI to interpret the code that creates each event in the JDK source code.
With 1. and 2. infeasible, I started working on the AI approach, implementing it in my JFR event collector tool that collects the information displayed on the website.
I tried to use local AI models for this project but failed, so I started using GPT3.5-turbo and testing it on the OpenAI ChatGPT website. The main structure of my endeavor is as follows:

For every event, I first collect all usages and creations in the OpenJDK source, and then I construct a prompt of the following form that includes the surrounding context of the source locations:
Explain the JFR event <event> concisely so that the reader, proficient in JFR, knows the meaning and relevance of the event to profiling and its fields, without giving code snippets or referencing the code directly, take the following code as the context of its usage and keep it short and structured
(and in markdown format, so format it properly to make it readable, using bullet points for field lists, but nothing else):
<context>Now some information about the event:
Fields:
<fields>
It is <flags: experimental, internal>Don’t mention implementation details, like methods, but explain the meaning of the event and how to use it for profiling.
Keep field names lowercase and in backticks.
Don’t use headings.
Don’t repeat yourself.
Keep it short.
For example, I asked ChatGPT the following for the ReservedStackActivation event:
Explain the JFR event ReservedStackActivation […]:
file:
src/hotspot/share/runtime/sharedRuntime.cppframe SharedRuntime::look_for_reserved_stack_annotated_method(JavaThread* current, frame fr) {
ResourceMark rm(current);
warning(“Potentially dangerous stack overflow in “
“ReservedStackAccess annotated method %s [%d]”,
method->name_and_sig_as_C_string(), count++);
EventReservedStackActivation event;
if (event.should_commit()) {
event.set_method(method);
The code context is from the JDK repository on GitHub.
I then pass this prompt to GPT-3.5 and obtain the result:
The
ReservedStackActivationevent in JFR signifies a potentially dangerous stack overflow in a Java method that has been annotated withReservedStackAccess. It is used for profiling purposes to identify methods that may be causing stack overflows.The relevant field for this event is:
method: Represents the Java method where the potential stack overflow occurred.
My prompt and the code used to find the usage contexts, simple regular expressions without C++ parsing, is quite simplistic, but the results are somewhat usable.
But this event has also a description:
Activation of Reserved Stack Area caused by stack overflow with ReservedStackAccess annotated method in call stack
Why did I choose this event, then? Because it allows you to compare the LLM generated and the OpenJDK developer’s written description. Keep in mind that the LLM did not get passed the event description. The generated version is similar, yet more text.
You can find my implementation on GitHub (GPLv2.0 licensed) and the generated documentation on the JFR Event Collection:

Conclusion
I’m unsure whether I like or dislike the results of this experiment: It’s, on the one hand, great to generate descriptions for events that didn’t have any, using the code as the source of truth. But does it really give new insights, or is it just bloated text? I honestly don’t know whether the website needs it. Therefore, I am currently just generating it for JDK 21 and might remove the feature in the future. The AI can’t replace the insights you get by reading articles on specific events, like Gunnar Morling’s recent post on the NativeMemory events.
Do you have any opinions on this? Feel free to use the usual channels to voice your opinion, and consider improving the JFR documentation if you can.
See you next week with a blog post on something completely different yet slightly related to Panama and the reason for my work behind last week’s From C to Java Code using Panama article. Consider this as my Christmas present to my readers.
This article is part of my work in the SapMachine team at SAP, making profiling and debugging easier for everyone. Thanks to Vedran Lerenc for helping me with the LLM part of this project.
如有侵权请联系:admin#unsafe.sh