11/21/2023
7 min read
This post is also available in Deutsch, Français and Nederlands.

Today we’re excited to announce that we’ve added the Mistral-7B-v0.1-instruct to Workers AI. Mistral 7B is a 7.3 billion parameter language model with a number of unique advantages. With some help from the founders of Mistral AI, we’ll look at some of the highlights of the Mistral 7B model, and use the opportunity to dive deeper into “attention” and its variations such as multi-query attention and grouped-query attention.
Mistral 7B tl;dr:
Mistral 7B is a 7.3 billion parameter model that puts up impressive numbers on benchmarks. The model:
- Outperforms comparable 13B model on all benchmarks
- Outperforms comparable 34B on many benchmarks,
- Approaches CodeLlama 7B performance on code, while remaining good at English tasks, and
- The chat fine-tuned version we’ve deployed outperforms comparable 2 13B chat in the benchmarks provided by Mistral.
Here’s an example of using streaming with the REST API:
curl -X POST \
“https://api.cloudflare.com/client/v4/accounts/{account-id}/ai/run/@cf/mistral/mistral-7b-instruct-v0.1” \
-H “Authorization: Bearer {api-token}” \
-H “Content-Type:application/json” \
-d '{ “prompt”: “What is grouped query attention”, “stream”: true }'
API Response: { response: “Grouped query attention is a technique used in natural language processing (NLP) and machine learning to improve the performance of models…” }
And here’s an example using a Worker script:
import { Ai } from '@cloudflare/ai';
export default {
async fetch(request, env) {
const ai = new Ai(env.AI);
const stream = await ai.run('@cf/mistral/mistral-7b-instruct-v0.1', {
prompt: 'What is grouped query attention',
stream: true
});
return Response.json(stream, { headers: { “content-type”: “text/event-stream” } });
}
}
Mistral takes advantage of grouped-query attention for faster inference. This recently-developed technique improves the speed of inference without compromising output quality. For 7 billion parameter models, we can generate close to 4x as many tokens per second with Mistral as we can with Llama, thanks to Grouped-Query attention.
You don’t need any information beyond this to start using Mistral-7B, you can test it out today ai.cloudflare.com. To learn more about attention and Grouped-Query attention, read on!
So what is “attention” anyway?
The basic mechanism of attention, specifically “Scaled Dot-Product Attention” as introduced in the landmark paper Attention Is All You Need, is fairly simple:
We call our particular attention “Scale Dot-Product Attention”. The input consists of query and keys of dimension d_k, and values of dimension d_v. We compute the dot products of the query with all the keys, divide each by sqrt(d_k) and apply a softmax function to obtain the weights on the values.
More concretely, this looks like this:
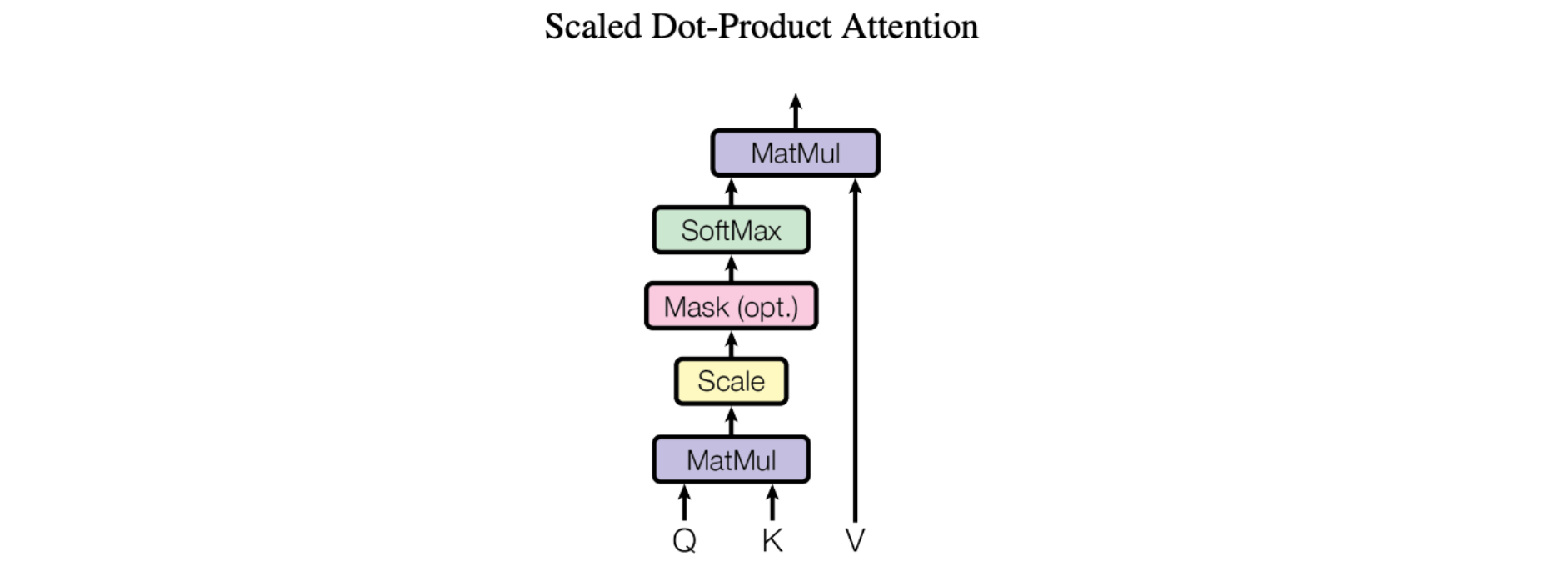
In simpler terms, this allows models to focus on important parts of the input. Imagine you are reading a sentence and trying to understand it. Scaled dot product attention enables you to pay more attention to certain words based on their relevance. It works by calculating the similarity between each word (K) in the sentence and a query (Q). Then, it scales the similarity scores by dividing them by the square root of the dimension of the query. This scaling helps to avoid very small or very large values. Finally, using these scaled similarity scores, we can determine how much attention or importance each word should receive. This attention mechanism helps models identify crucial information (V) and improve their understanding and translation capabilities.
Easy, right? To get from this simple mechanism to an AI that can write a “Seinfeld episode in which Jerry learns the bubble sort algorithm,” we’ll need to make it more complex. In fact, everything we’ve just covered doesn’t even have any learned parameters — constant values learned during model training that customize the output of the attention block!
Attention blocks in the style of Attention is All You Need add mainly three types of complexity:
Learned parameters
Learned parameters refer to values or weights that are adjusted during the training process of a model to improve its performance. These parameters are used to control the flow of information or attention within the model, allowing it to focus on the most relevant parts of the input data. In simpler terms, learned parameters are like adjustable knobs on a machine that can be turned to optimize its operation.
Vertical stacking - layered attention blocks
Vertical layered stacking is a way to stack multiple attention mechanisms on top of each other, with each layer building on the output of the previous layer. This allows the model to focus on different parts of the input data at different levels of abstraction, which can lead to better performance on certain tasks.
Horizontal stacking - aka Multi-Head Attention
The figure from the paper displays the full multi-head attention module. Multiple attention operations are carried out in parallel, with the Q-K-V input for each generated by a unique linear projection of the same input data (defined by a unique set of learned parameters). These parallel attention blocks are referred to as “attention heads”. The weighted-sum outputs of all attention heads are concatenated into a single vector and passed through another parameterized linear transformation to get the final output.
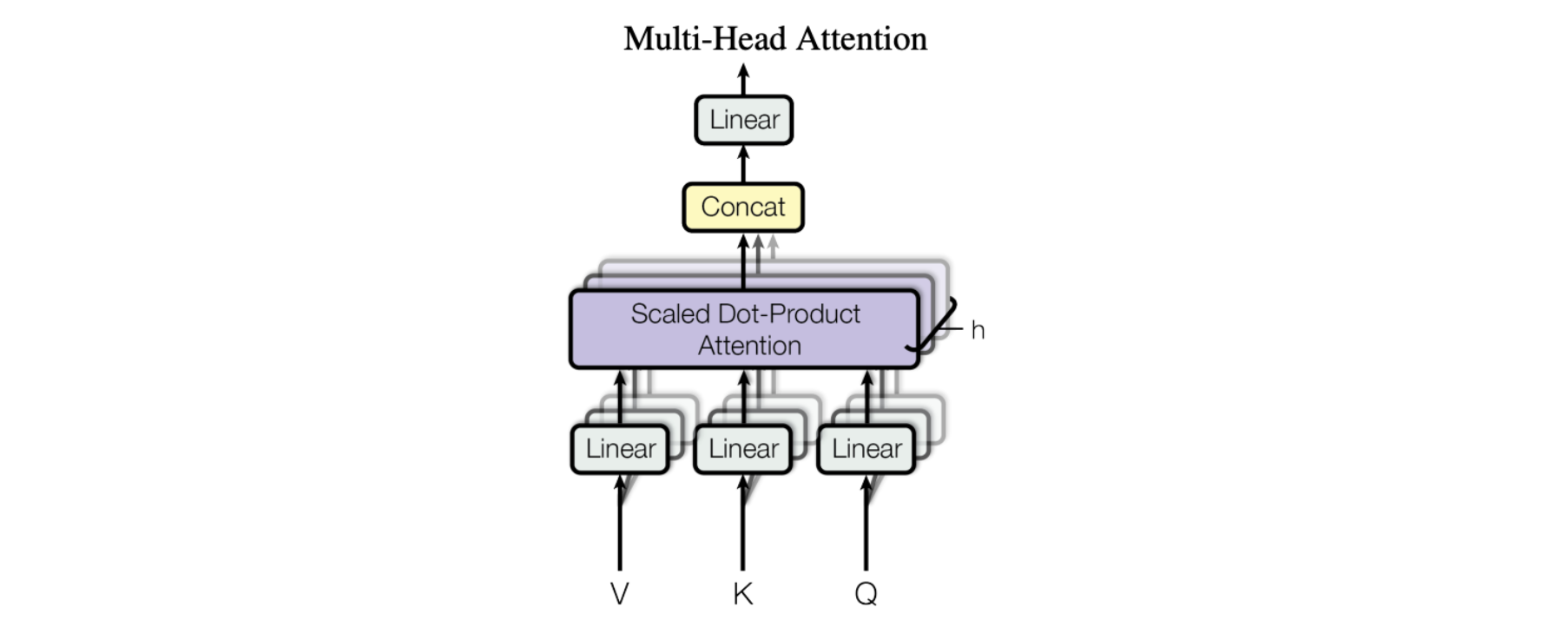
This mechanism allows a model to focus on different parts of the input data concurrently. Imagine you are trying to understand a complex piece of information, like a sentence or a paragraph. In order to understand it, you need to pay attention to different parts of it at the same time. For example, you might need to pay attention to the subject of the sentence, the verb, and the object, all simultaneously, in order to understand the meaning of the sentence. Multi-headed attention works similarly. It allows a model to pay attention to different parts of the input data at the same time, by using multiple "heads" of attention. Each head of attention focuses on a different aspect of the input data, and the outputs of all the heads are combined to produce the final output of the model.
Styles of attention
There are three common arrangements of attention blocks used by large language models developed in recent years: multi-head attention, grouped-query attention and multi-query attention. They differ in the number of K and V vectors relative to the number of query vectors. Multi-head attention uses the same number of K and V vectors as Q vectors, denoted by “N” in the table below. Multi-query attention uses only a single K and V vector. Grouped-query attention, the type used in the Mistral 7B model, divides the Q vectors evenly into groups containing “G” vectors each, then uses a single K and V vector for each group for a total of N divided by G sets of K and V vectors. This summarizes the differences, and we’ll dive into the implications of these below.
|
Number of Key/Value Blocks |
Quality |
Memory Usage |
|
|
Multi-head attention (MHA) |
N |
Best |
Most |
|
Grouped-query attention (GQA) |
N / G |
Better |
Less |
|
Multi-query attention (MQA) |
1 |
Good |
Least |
Summary of attention styles
And this diagram helps illustrate the difference between the three styles:
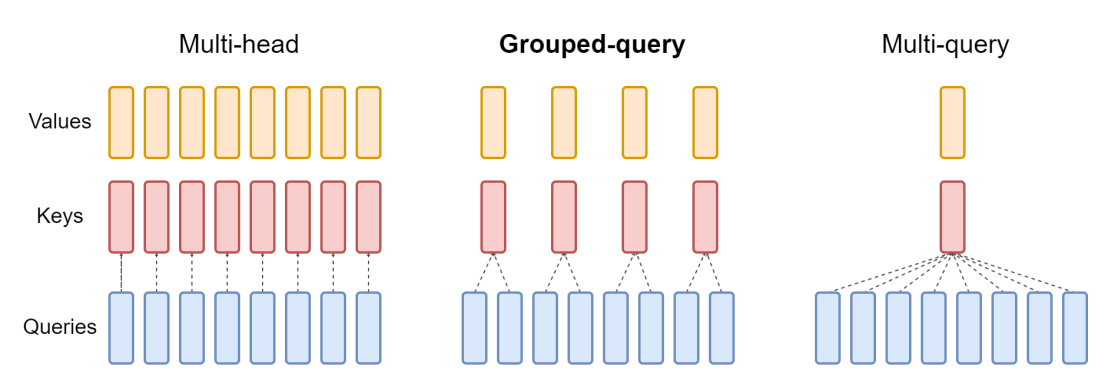
Multi-Query Attention
Multi-query attention was described in 2019 in the paper from Google: Fast Transformer Decoding: One Write-Head is All You Need. The idea is that instead of creating separate K and V entries for every Q vector in the attention mechanism, as in multi-head attention above, only a single K and V vector is used for the entire set of Q vectors. Thus the name, multiple queries combined into a single attention mechanism. In the paper, this was benchmarked on a translation task and showed performance equal to multi-head attention on the benchmark task.
Originally the idea was to reduce the total size of memory that is accessed when performing inference for the model. Since then, as generalized models have emerged and grown in number of parameters, the GPU memory needed is often the bottleneck which is the strength of multi-query attention, as it requires the least accelerator memory of the three types of attention. However, as models grew in size and generality, performance of multi-query attention fell relative to multi-head attention.
Grouped-Query Attention
The newest of the bunch — and the one used by Mistral — is grouped-query attention, as described in the paper GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints that was published on arxiv.org in May 2023. Grouped-query attention combines the best of both worlds: the quality of multi-headed attention with the speed and low memory usage of multi-query attention. Instead of either a single set of K and V vectors or one set for every Q vector, a fixed ratio of 1 set of K and V vectors for every Q vector is used, reducing memory usage but retaining high performance on many tasks.
Often choosing a model for a production task is not just about picking the best model available because we must consider tradeoffs between performance, memory usage, batch size, and available hardware (or cloud costs). Understanding these three styles of attention can help guide those decisions and understand when we might choose a particular model given our circumstances.
Enter Mistral — try it today
Being one of the first large language models to leverage grouped-query attention and combining it with sliding window attention, Mistral seems to have hit the goldilocks zone — it’s low latency, high-throughput, and it performs really well on benchmarks even when compared to bigger models (13B). All this to say is that it packs a punch for its size, and we couldn't be more excited to make it available to all developers today, via Workers AI.
Head over to our developer docs to get started, and if you need help, want to give feedback, or want to share what you’re building just pop into our Developer Discord!
The Workers AI team is also expanding and hiring; check our jobs page for open roles if you’re passionate about AI engineering and want to help us build and evolve our global, serverless GPU-powered inference platform.
We protect entire corporate networks, help customers build Internet-scale applications efficiently, accelerate any website or Internet application, ward off DDoS attacks, keep hackers at bay, and can help you on your journey to Zero Trust.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you're looking for a new career direction, check out our open positions.