0x0 前言
很久之前打比赛的遇到的一个点, 我当时以为这样的读取特性是跟php伪协议有关呢, 之前也看飘零师傅发过朋友圈,但是记忆比较模糊了,刚好最近放假有时间来调试一下才发现原来是curl的锅。
0x1 分析问题
引起我的好奇心是一个师傅分析POSCMS的文章的一个tips:

其实我个人觉得师傅这里解释不是很严谨,这个问题其实主要还是出在了curl请求上面,比如我们请求http://127.0.0.1/1.php?.jpg,那么我们访问的内容就是1.php,而不是名称为`1.php?.jpg`的文件,而`file_get_contents`刚好相反,至于为什么是这样,其实通俗来说原因是按照URL的定义来解析,那么1.php才是资源名,所以才会导致这样的结果, 但是下面我将从php底层来分析下这个原理,说明白下面两段代码的实现差异。
我们先从两段代码开始看起:
<?php $url = $_GET['url']; $file = $url . '.jpg'; var_dump($url); var_dump($file); echo file_get_contents($url); echo '</br>'; echo file_get_contents($file); ?>


<?php var_dump(ini_get('allow_url_fopen')); $url = $_POST['url']; $url = $url . '.jpg'; var_dump($url); // echo file_get_contents($url); if(function_exists('curl_init') && function_exists('curl_exec')){ $ch = curl_init($url); $data = ''; curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); $data = curl_exec($ch); curl_close($ch); var_dump($data); } ?>

我们经常在代码里面看到下载文件的时候,一般都会有这两种函数去读取文件内容(导致SSRF), 他们一般是先执行file_get_contents判断返回结果为False的则接着去执行curl_exec,否则直接return, 至于为什么这么写,估计是考虑了像我上面列举的情况?
下面我就主要来分析下php底层如何实现file_get_contents的功能。
0x2 从底层分析file_get_contents
0x2.0 debug环境构建
下载:
git clone https://github.com/php/php-src.git
cd php-src
git checkout remotes/origin/PHP-7.2.0
编译:
./buildconf ./configure --enable-debug --disable-all --prefix=/Users/xq17/Desktop/PHPCore/ make && make install
0x2.1 开始分析
关于StreamWrapper和protocols的关系: Supported Protocols and Wrappers
关于file://,wrapper.file
PHP流的的概念
我们都知道PHP中的文件操作函数可以打开文件、URL等资源然后返回一个句柄。那么PHP是如何做到使用一致的API对不同数据源进行操作的呢? 其实就得益于PHP在底层对各种操作进行了分装, 再上层将其统一看做成"流"对象,在底层在进行具体解析。
php7.1.8
file_get_contents函数的定义
/ext/standard/file.c 520 line

解析完参数之后,开始解析流,我们跟入php_stream_open_wrapper_ex
/main/streams/streams.c 2010 line

跟进php_stream_locate_url_wrapper 这个函数

解析协议类型,继续向下看

里面看到path[n+3]!='/'这就是为什么我们使用file协议需要:file:///的原因
也就是必须要用绝对路径。

这里就是根据协议找出对应的wrapper,没有就回退为plain_files_wrapper
<?php $url = 'file:///flag.php?#123'; file_get_contents($url); ?>
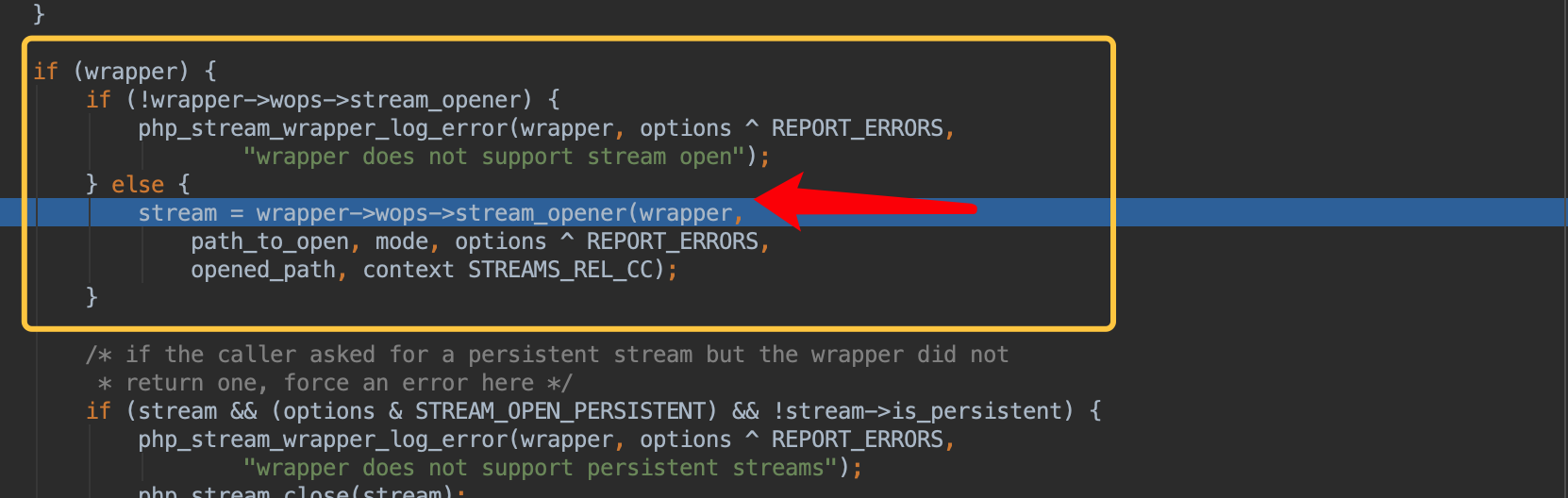
这里我们可以正确返回:file://的包装器,下面就是用相应包装器取打开流的操作了。


此时调用栈如下:


可以看到这里经过一些简单的操作就直接把flag.php?#123当作文件名传进去了,所以自然是failed to open stream
所以说file_get_contents对file协议的文件名倒没做什么处理, 不过读者有兴趣可以去研究下http://这个协议PHP是如何解析的。

感觉挺有意思的。
0x3 从底层分析php curl的流程
那么为什么curl处理file的时候会省略后面的? or #的内容呢?
MAC本机调试其实还是挺麻烦的
libcurl 与 curl 的关系
libcurl and curl 都可以利用多种多样的协议来传输文件
curl 是开源文件传输的命令行工具,是基于libcurl的基础上而来的。
libcurl 则是一个免费开源,客户端URL传输库。
本文说的PHP的curl其实说的就是libcurl
这里记录下MAC安装Libcurl的过程:
wget https://curl.haxx.se/download/curl-7.68.0.tar.gz tar -xzvf cd curl-7.68.0 ./configure --enable-debug --prefix=/usr/local/curl make && make install
然后我们编译下curl扩展,然后再开启
# 修改命令行的Path export PATH="/Users/xq17/Desktop/个人学习/php扩展学习/debugphp/php7/bin:$PATH" # 开始编译扩展 phpize ./configure --with-curl=/usr/local/curl make && make install
接着我们加载扩展,然后调用就好了。
因为php版本的问题导致我上面的操作失败了,所以后面我直接重新编译一下PHP7.2了
./configure --enable-debug --with-curl=/usr/local/curl --disable-all --prefix=/Users/xq17/Desktop/PHPCore/php7.2 make && make install
然后我们写一个调用的CURL的PHP文件即可。
<?php $url = 'file:///flag.php?123'; if(function_exists('curl_init') && function_exists('curl_exec')){ $ch = curl_init($url); $data = ''; curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); $data = curl_exec($ch); curl_close($ch); var_dump($data); } ?>
我们跟进下curl_init函数

然后跟进php_curl_option_url

# 当前栈情况 frame #0: 0x00000001037ca1cf php`php_curl_option_str(ch=0x0000000104282000, option=10002, str="file:///flag.php?123", len=20, make_copy=0 '\0') at interface.c:194
这里就是调用了libcurl里面的curl_easy_setopt函数,我们跟进看看
函数的官方定义:curl_easy_setopt - set options for a curl easy handle
同理我们跟进curl_exec函数发现其最终调用的是:curl_easy_perform
其实PHP只不过对example做了一些小封装分别搞出了自己的函数.
EXAMPLE
CURL *curl = curl_easy_init(); if(curl) { CURLcode res; curl_easy_setopt(curl, CURLOPT_URL, "http://example.com"); res = curl_easy_perform(curl); curl_easy_cleanup(curl); }
所以下面我们主要分析下libcurl是怎么解析URL就行了。
/lib/setopt.c
#undef curl_easy_setopt CURLcode curl_easy_setopt(struct Curl_easy *data, CURLoption tag, ...) { va_list arg; CURLcode result; if(!data) return CURLE_BAD_FUNCTION_ARGUMENT; va_start(arg, tag); result = Curl_vsetopt(data, tag, arg); va_end(arg); return result; }
跟进下Curl_vsetopt,这个函数就是设置各种请求信息的,代码case多所以比较长。

这里我们结合上面分析可以确定就是发起的是URL请求。
case CURLOPT_URL: /* * The URL to fetch. */ if(data->change.url_alloc) { /* the already set URL is allocated, free it first! */ Curl_safefree(data->change.url); data->change.url_alloc = FALSE; } result = Curl_setstropt(&data->set.str[STRING_SET_URL], va_arg(param, char *)); data->change.url = data->set.str[STRING_SET_URL]; break;
CURLcode Curl_setstropt(char **charp, const char *s) { /* Release the previous storage at `charp' and replace by a dynamic storage copy of `s'. Return CURLE_OK or CURLE_OUT_OF_MEMORY. */ Curl_safefree(*charp); if(s) { char *str = strdup(s); if(str) { size_t len = strlen(str); if(len > CURL_MAX_INPUT_LENGTH) { free(str); return CURLE_BAD_FUNCTION_ARGUMENT; } } if(!str) return CURLE_OUT_OF_MEMORY; *charp = str; #这里就是值传递的点 } return CURLE_OK; }
这里URL的file:///flag.php?123给了data->set.str[STRING_SET_URL]
感觉还是没到点子上, 我们继续跟进看下是怎么发出请求的。

下面就是关键的处理URL函数了
lib/urlapi.c
curl_url_get line:1003
case CURLUPART_URL: { char *url; char *scheme; char *options = u->options; char *port = u->port; char *allochost = NULL; if(u->scheme && strcasecompare("file", u->scheme)) { url = aprintf("file://%s%s%s", u->path, u->fragment? "#": "", u->fragment? u->fragment : ""); }
这里可以看到这里拼接直接没有考虑query部分,最终结果就是file:///flag.php
继续跟下去到file协议的处理流程,file协议走的是文件处理函数file_connect
static CURLcode file_connect(struct connectdata *conn, bool *done) { struct Curl_easy *data = conn->data; char *real_path; struct FILEPROTO *file = data->req.protop; int fd = -1; #ifdef DOS_FILESYSTEM size_t i; char *actual_path; #endif size_t real_path_len; CURLcode result = Curl_urldecode(data, data->state.up.path, 0, &real_path, &real_path_len, FALSE);
real_path最终处理file的时候拼接的路径值就是data->state.up.path,也就是资源部分,其他不管,这点刚好和php上面不一样。
0x4 总结
libcurl的处理过程显然是比php处理过程更细腻, 毕竟两者方向不一样, 不过正好说明了一个问题,越完善的功能往往暴露出的攻击点显然会更多。哎,之前一直卡在wupco师傅的那个phppwn的题目导致我落下了很多知识的学习,正确这几天把坑补完吧。
0x5 参考链接
PHP:file_get_contents获取微信头像缓慢问题定位
Docker环境下编译安装PHP7.1.4 Nginx1.12.0
如有侵权请联系:admin#unsafe.sh