2023-12-12 03:59:53 Author: blogs.sap.com(查看原文) 阅读量:11 收藏
Starting with the QRC4 2023 release of SAP HANA Cloud, you can provision (aka deploy) and configure SAP HANA and HANA Data Lake (HDL) databases from Kubernetes environments, including the Kyma environment that is part of SAP Business Technology Platform (BTP).
This is the first of three posts on the topic. It’s an attempt to put this feature into context by taking a look at the different BTP environments (Kyma, Cloud Foundry) and how they fit into the bigger picture of BTP. The second post (coming soon) goes through the mechanics of provisioning and configuring HANA Cloud databases from Kyma, and the third (also coming soon) does the same thing for an external Kubernetes environment, which is pretty similar but with a bit more setup work.
We sometimes speak of provisioning HANA Cloud databases “in Kyma” or “in Kubernetes” in contrast to provisioning “in Cloud Foundry” or “in the subaccount”. Yet in each case the database is physically hosted in the same HANA Cloud landscape, which is not “in” any of these environments.
So what do we mean by “in”?
It may help to think about how command-line tools work in this context (we will talk about the graphics HANA Cloud tools later).
Until recently, “BTP runtime environment” was almost synonymous with Cloud Foundry (CF), which continues to be an important environment for running microservice applications. So cf was the main CLI for working with SAP HANA Cloud and other BTP services. To be clear: cf continues to be the appropriate tool to use for those who are working primarily with the CF environment (for example, if you are building CF applications or working with other BTP services that are available in CF). When you run “cf login” you are logging in specifically to a CF landscape, using CF credentials and with CF authorizations. Then, if you have the appropriate Developer role in a CF space, you can provision an instance with “cf create-service”, supplying an appropriate JSON file that describes the instance configuration as described in the documentation. Further management of this instance from a CLI must be done by the cf CLI governed by CF credentials.
In BTP Cockpit, the instance is listed as being in the Cloud Foundry environment, like the CF_TOM_HANA database below.

The CF_TOM_HANA database is provisioned in the Cloud Foundry environment
More recently, we have introduced support for provisioning using the btp CLI, which works with the service manager instance present (behind the scenes) for each BTP subaccount. When you run “btp login” you are logging in to the BTP subaccount with service manager credentials and authorizations. If you have the “subaccount service administrator” role collection then you can use the btp CLI to provision an instance with “btp create services/instance” and supplying the same JSON document as for the cf CLI. Further management of this instance from a CLI must be done by the btp CLI governed by service manager credentials.
In BTP Cockpit, the instance shows up as “Other Environments”, like the TOM_HANA instance below. (Why Other? While CF and Kyma are environments in which you can run microservice-based applications, this “environment” is simply a set of resources governed by a Service Manager instance in the subaccount.

The TOM_HANA database is provisioned in the OTHER environment, or subaccount
Now comes Kyma. For Kyma, you work with the standard Kubernetes CLI kubectl (or helm, but let’s ignore that for this post), which works with the Kubernetes cluster according to a KUBECONFIG file. You can use the kubectl CLI to provision an instance with “kubectl apply”, and it uses the SAP BTP Service Operator enabled with every Kyma environment, which talks to a dedicated Service Manager instance in the subaccount. Further management of this instance from a CLI must be done by kubectl or some other Kubernetes tool such as helm, and is governed by Kyma credentials.
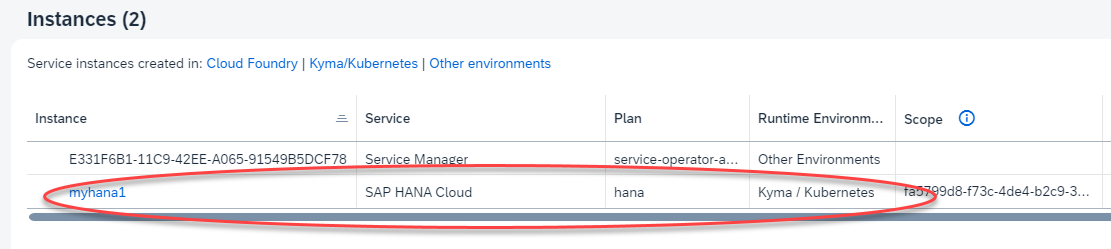
In BTP Cockpit the instance shows up as “Kyma / Kubernetes, like the myhana1 instance below”.

The myhana1 database is provisioned in the Kyma environment
As I said above, each of these databases is running in the same physical landscape: an SAP HANA Cloud landscape attached to the data center where the subaccount is running. And for SQL connectivity, each has a SQL endpoint (host:port) and accepts database users in the same way. But for tooling, CLI, or API access, each needs a different authorization to handle requests. To modify or delete the CF_TOM_HANA instance you must login through Cloud Foundry (for example, with the cf CLI); to modify or delete the TOM_HANA instance you must login through service manager (for example, with the btp CLI), and to modify or delete the myhana1 instance you must login from kubectl. That is, each environment is to some extent self contained: it has its own authentication and authorization scheme, and you manage the database from that environment.
This may seem a bit confusing to those who have thought of CF and BTP as synonymous. And CF does have a closer integration with, for example, the BTP Cockpit, that blurs the boundary between BTP itself and the runtime environment.
For Kubernetes and Kyma users, we hope that the distinction is more clear. Kubernetes has become a widely-used system for managing containers and services in a cloud environment, and many of SAP’s customers are using it in their own cloud landscapes outside SAP BTP to host and manage their own applications. Other customers are taking advantage of the BTP integration and hyperscaler-independence that the SAP Kyma environment provides on top of standard Kubernetes.
If you are already running in one of these environments and want to take advantage of SAP HANA Cloud database as a managed service, even though the database itself will not be running on your own landscape, it makes sense to include the operation of HANA Cloud databases as part of your overall landscape management system, rather than having to adopt a separate approach for them. The Kyma and Kubernetes support means you can do just this: manage HANA Cloud databases using kubectl and yaml configuration files, or using helm and helm charts, along with the resources in your landscape that may rely on HANA Cloud databases as data sources or data stores.
The other interface to provisioning and managing SAP HANA Cloud instances is, of course, the HANA Cloud Tools: HANA Cockpit, the Database Explorer, and the HANA Cloud Central application that increasingly includes features of both. There are currently two editions of these: one (the original) that runs in the Cloud Foundry environment and the other (called the multi-environment tools) that runs in the HANA Cloud landscape.
You can access the CF Tools from a CF space in BTP Cockpit:

The CF HANA Cloud tools are available from a CF space
You access the multi-environment tools from the “Instances and Subscriptions” list in a subaccount.

The multi-environment tools are available from the Instances and Subscriptions list in a subaccount.
Currently there are limits to what you can do with databases in a CF space from the multi-environment tools, and that has been a reason for some people to stay with the CF tools. Specifically, you cannot provision a database into a CF space or delete a database that is in a CF space. In the near future we plan to remove this restriction so that, with a secondary login to Cloud Foundry, you will be able to fully manage CF databases from the multi-environment tools and the need for the CF tools will go away.
There are technical and practical reasons why managing Kyma/Kubernetes databases entirely from the HANA Cloud Tools is often not possible or permitted.
The user authorization systems of Kubernetes and BTP are very different, and for an external Kubernetes cluster, the HANA Cloud tools would have no way to be authorized through Kubernetes credentials. Also: the nature of Kubernetes is that the configuration files maintain the state of the system (rather than a set of instructions). Making changes from elsewhere would create inconsistencies between the state definition in the Kubernetes configuration files and the internal state definition maintained by HANA Cloud. So the best approach is usually going to be to do all the resource management and lifecycle management (resizing, deleting) from Kubernetes or Kyma, rather than from the HANA Cloud tools. Monitoring and operations “within” the database are safe to do from the HANA Cloud tools.
This separation probably fits most use cases. Those running HANA Cloud as a resource for an external Kubernetes landscape will probably want to manage their entire landscape centrally from Kubernetes — now you can do this. And for those running Kyma, the same applies.
In among this confusing-but-flexible set of subaccounts, spaces, and environments there is another wrinkle. Database administrators, particularly those running instances that host many HDI Containers or schemas in a multi-tenant manner, may wish to have each tenant running in a separate subaccount or in a separate CF space or in a separate Kyma namespace, depending on your application landscape.
For this scenario, a single HANA Cloud instance (typically in the subaccount, provisioned using btp CLI or HANA Cloud multi-environment edition) can be “mapped” into a CF space or Kyma namespace. A single database can be mapped into many different spaces / namespaces, as long as they are in the same region (aka data center). Then an HDI Container can be deployed into the database from each space / namespace to provide isolation among the tenants. I mention this here for completeness, but database mapping is a separate topic.
Next up (soon): the mechanics of provisioning a HANA Cloud database from Kyma.
如有侵权请联系:admin#unsafe.sh