read file error: read notes: is a directory 2023-12-2 06:2:12 Author: 网络与安全实验室(查看原文) 阅读量:31 收藏
2023.11.27-2023.12.03
每周文章分享
标题:A Dual Weighting Label Assignment Scheme for Object Detection
期刊:2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 2022.
作者:Shuai Li, Chenhang He, Ruihuang Li, Lei Zhang
分享人:河海大学——朱远洋
研究背景
标签分配(LA)大致可以分为2类:硬标签分配(hard LA)和软便签分配(soft LA)。hard LA的划分规则可以进一步分为静态规则和动态规则。静态匹配策略忽略了具有不同大小和形状的对象的划分边界可能会有所不同的事实。静态和动态分配方法都忽略了这样一个事实,即样本并不同等重要。目标检测的评价指标表明,最优预测不仅应该具有较高的分类(cls)分数,还应该具有准确的定位,这意味着在训练中,cls头和回归(reg)头之间具有较高一致性的锚点(anchor)应更为重要。现有的方法主要集中于正样本(pos)加权函数的设计,而负样本(neg)权重仅由pos权重推导出来,由于neg权重提供的新监督信息很少,可能会限制检测器的学习能力。所以,这种耦合加权机制不能在更精细的水平上区分每个训练样本。
关键技术
为了向检测器提供更具区分度的监督信号,本文提出了一种新的LA方案,称为双重加权(DW),从不同角度指定正负权重,使其相互补充。具体来说,pos权重由置信度分数(从cls头获取)和reg分数(从reg头获取)的组合动态决定。每个anchor的否定权重分解为两个项:它是否定样本的概率和它作为否定样本的重要性。pos权重反映了cls头和reg头之间的一致性程度,它将推动一致性程度较高的anchor在anchor列表中向前移动,而neg权重则反映了不一致性程度,并将不一致的anchor推到列表的后面。这样,在推理过程中,cls分数较高、位置较精确的边框在非极大值抑制(NMS)之后会有更大的生存机会,而位置不精确的边框则会落在后面,被过滤掉。DW通过为四个不同的anchor分配不同的(pos、neg)权重对来区分它们,这可以为检测器提供更精细的监督训练信号。
算法介绍
A. 动机和框架
软标签分配(soft LA)通过加权损失以soft方式处理训练样本,旨在增强cls和reg头之间的一致性。对于软LA,anchor损失可以表示为
其中s是预测的cls分数,b和b‘分别是预测的边界框和GT框。通过将更大的w_pos和w_neg分配给一致性更高的anchor,可以缓解cls和reg头之间的不一致问题。现有工作通常将w_neg设置为w_pos,主要关注如何定义一致性并将其集成到损失权重中。表1总结了近期代表性方法的pos和neg权重。可以看出,当前的方法通常定义一个度量t来表示anchor在两个任务之间的一致性程度,然后将不一致性度量设计为1-t,通过添加比例因子((s-t)^2、s^2或t),将一致性和不一致性度量最终集成到pos和neg损失权重中。
表1 不同权重函数的比较
与上述方法中w_pos和w_neg高度相关不同,本文提出以预测感知的方式分别设置pos和neg。pos权重和neg权重都将预测的cls分数s和预测框与GT对象之间的IoU作为输入。通过估计cls和reg头之间的一致性程度来设置pos权重。neg权重表示为两项的乘积:anchor为负的概率,取决于anchor为负的重要性。因此具有相似pos权重的模糊anchor可以接收具有不同neg权重的更细粒度监督信息。
图1 DW框架的流程
B. Pos权重函数
样本的pos权重应反映其在分类和定位中准确检测目标的重要性。作者分析目标检测的评估指标,首先,一个类别的所有预测按照排名标准(cls分数或cls分数与预测IoU的组合)进行排名。只有预测列表中IoU大于θ的第一个边界框将被定义为pos检测,而所有其他边界框应被视为相同GT的误报。所以,高排名分数和高IoU都是pos预测的充分必要条件。pos权重wpos应该与IoU和排名分数,即w_pos∝IoU和w_pos∝s,定义一个一致性度量t测量两个条件之间的对齐度:
其中β用于平衡两个条件。为了增强pos权重方差,在其中添加指数调制因子:
其中µ是超参数,用于控制不同pos权重的相对间隙。最后,pos权重通过每个实例候选包中pos权重的总和进行归一化。
C. Neg权重函数
图2 DW方法与现有标签分配方法之间差异的说明
pos权重强制一致性anchor具有较高的cls分数和较大的IoU,但不一致性anchor的重要性无法通过pos权重来区分。图2中D的位置更精细,但cls分数较低,而B位置较粗糙,但cls分数较高。它们可能具有相同的一致性程度t,因此单纯的pos权重不能反映它们的差异。为了给检测器提供更具辨别力的监督信息,本文通过给样本分配不同的负权重(定义为以下两项的乘法)来放映它们的重要性:neg样本的概率和neg样本的重要性。
neg样本的概率:根据COCO的评估指标,小于θ的IoU是错误预测的充分条件。即IoU是确定负样本概率的唯一因素,用P_neg表示。由于COCO采用从0.5到0.95的IoU区间来估计AP,因此边界框的概率P_neg应满足以下规则:
在区间[0.5, 0.95]内定义的任何单调递减函数都适用于P_neg。为了简单起见,将P_neg实例化为以下函数:
函数通过点(0.5, 1)和(0.95, 0)。一旦γ_1被确定,参数k和b可以通过待定系数法获得。
成为负样本的重要性:推理时,排名列表中的neg预测不会影响recall,但是减小precision。因此,neg边界框要尽可能排名靠后,即排名分数越小越好。基于此,作为网络优化的难例,大的排名分数的neg预测比小排名分数的预测更重要。因此,neg样本的重要性(I_neg)应该是排名分数的函数。表示如下:
γ_2表示neg样本的重要性调制因子。最后,neg权重w_neg=P_neg×I_neg表示为:
该权重与IoU负相关与s正相关。可以看出,对于相同pos权重的anchor,具有较小IoU的anchor有较大的neg权重。因此W_neg可以区分具有相同pos权重的歧义anchors。
D. 边界框细化
图3 边界框细化操作示意图
Pos和neg权重函数都将IoU作为输入,高质量IoU表示高质量样本以利于强健特征的学习。本文提出一种框细化操作。基于物体边界点预测更准确定位。如图3所示,首先预测(i, j)点的粗边界框(橘色框),表示为{Δl, Δt, Δr, Δb},四个边界点表示为
其中{Δ_l^x, Δ_l^y, Δ_t^x, Δ_t^y, Δ_r^x, Δ_r^y, Δ_b^x, Δ_b^y}为细化模块的输出。最后的细化偏移量O表示为:
E. 损失函数
本文采用FCOS实现DW。如图1所示整体网络架构由主干,FPN和检测头组成。最后的cls分数为centerness分支和分类分支的输出相乘。网络的最终的loss为:
其中β是平衡因子。分类loss和回归loss分别是:
其中N和M分别是候选包内和外的anchor数量。FL是focal loss,GIoU是回归loss,s是预测cls分数,b和b‘分别是预测框和GT的位置。
实验分析
数据集和评价指标:MSCOCO数据集,115k、5k和20k分别用于训练,验证和测试。COCO AP作为性能测试指标。
实现细节:γ_1, γ_2, β, μ分别设为2,2,5,5。
A. 消融实验
Pos权重的超参:pos权重的两个超参:β和μ,β用于平一致性指标t中的cls分数和IoU。β增大,IoU贡献度增大。μ控制pos权重的相对尺度,μ使最最一致的样本有相对更大的pos权重。表2展示β从3到7,μ从3到8变化时DW的性能。当二者都是5时取得最佳性能。
表2 在w_pos中设置不同超参数时的检测性能
Neg权重的超参:γ_1, γ_2是neg权重的调制因子。如表3所示,随着超参的变化AP并不敏感,最后选择γ_1=2, γ_2=2。
表3 在w_neg中设置不同的γ1和γ2值时的检测性能
候选集的构建:soft标签分配应用于候选集内的anchor。本文测试三种候选集构建的方式,都基于anchor点到GT中心的距离r。第一种方式选择小于固定阈值的anchor。第二种方式选择FPN每层top-k最近的anchor。第三种方式是为每个anchor提供一个软中心权重e^(-r^2)并将其与pos权重相乘。表4可以看出,AP性能在41.1和41.5之间波动,这表明DW对候选集的选择具有鲁棒性。
表4 不同候选袋选择方法的比较
Neg权重函数的设计:如表5所示,验证引入负权重的重要性。仅使用pos权重会将性能降低到39.5,这表明对于一些低质量的anchor,仅为其分配较小的正权重不足以降低其排名分数。在不使用I_neg或P_neg的情况下,分别获得了40.5 AP和40.0 AP,这验证了这两项都是必要的。参考现有方法,用1-w_pos替换w_neg,性能达到40.7 AP,比标准DW低0.8个点。该实验证明neg权重函数设计的必要性。
表5 不同w_neg计算方法的比较
Box细化:在没有框细化的情况下,DW达到了41.5 AP,这是第一种在COCO上使用FCOS-ResNet-50实现超过41 AP的性能,而不增加任何参数和的培训成本。通过边界框细化,DW可以达到42.2 AP,如表6所示。表7还显示,框优化可以持续提高具有不同主干的DW的性能。
表6 LA不同加权策略的比较
不同权重策略比较:将DW与其他权重策略对比,表6中前五行是硬LA方法,其他是软LA方法。硬LA方法中OTA基于最优传输理论取得最佳性能40.7AP,但是训练时间增加。GFLv2利用定位概率分布分支估计定位质量,在软LA方法种取得第二性能41.1 AP。与将权重分配给损失的主流方法不同,Autoassign将权重分配给cls分数,并在训练期间根据其梯度进行更新。本文尝试在Autoassign中分离权重并将其分配给loss,但仅分别获得39.8和36.6 AP,比原始性能低0.6和3.8分。Autoassign中的权重机制无法在主流实践中工作。
B. Sota对比:
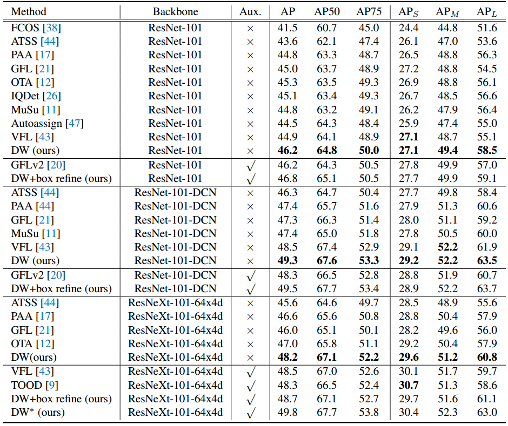
表7报告coco test-dev上单模型单尺度测试的结果对比。表中区分不同方法是否增加辅助模块,在不使用辅助模块,本文的标签分配策略取得最佳性能。
表7 在COCO 2017 test-dev数据集上与最先进的密集检测器的性能比较。
C. 分析讨论
DW的可视化:在图4中展示了DW的cls得分、IoU、pos和neg权重的可视化map以及两种代表性方法GFL和VFL。可以看出,DW中的pos和neg权重主要集中在GT的中心区域,GFL和VFL在更宽的区域分配权重。这种差异意味着DW可以更多地关注重要样本,并减少简单样本的贡献,例如对象边界附近的样本。这就是为什么DW对候选包的选择更为稳健。中心区域的anchor在DW中有不同的(pos,neg)重量对。相反,在GFL和VFL中,负权重与pos权重高度相关。橙色圆圈突出显示的anchor在GFL和VFL中具有几乎相同的pos权重和neg权重,而DW可以通过为它们分配不同的权重来区分它们,从而提供网络更高的学习能力。
图4 cls分数、IoU、pos和neg权重的可视化
DW的局限性:虽然DW可以很好地区分不同anchor对对象的重要性,但它将同时减少训练样本的数量,如图4所示。这可能会影响小物体的训练效果。如表7所示,小对象上的DW改善程度没有大对象上的高。为了缓解这个问题,本文提出可以根据对象大小动态设置w_pos的不同超参数,以平衡大小对象之间的训练样本。
总结
本文提出了一种称为双重加权(DW)的自适应标签分配方案来训练精确的密集目标检测器。DW打破了以往密集检测器中的耦合加权惯例,通过从不同方面估计一致性和不一致性度量,为每个anchor动态分配单独的pos和neg权重。还开发了一种新的框优化操作,用于直接优化回归图上的框。DW与评估指标高度兼容。在MS-COCO基准上的实验验证了DW在不同主干下的有效性。使用和不使用box优化,使用ResNet-50的DW分别达到41.5 AP和42.2 AP,创下了最新水平。DW作为一种新的标签分配策略,对不同的检测头也表现出良好的泛化性能。
END
==河海大学网络与安全实验室==
微信搜索:Hohai_Network
联系QQ:1084561742
责任编辑:何宇
如有侵权请联系:admin#unsafe.sh