二进制分析的时候经常遇到经过混淆的函数,所以一直想自己学习实现一个简单的指令乱序demo,也不需要太复杂(其实就是自己菜而已)。能阻止IDA F5党(就是我)就可以了(能去混淆的师傅除外),常见的指令乱序是把一段代码根据jcc指令划分成若干基本块jcc指令通俗来说就是常见的跳转指令诸如jz,jnz,jmp....此类。基本块的概念参考IDA截图,像这种loc_xxx就能看作基本块。

更直观一点就是下面这张图,代码被划分成块,执行流程被分析的明明白白

划分完基本块之后再打乱或者隐藏各个基本块之间的直接联系,使静态反编译工具无法分析执行流程。
更无法通过F5看伪代码。
最简单最原始的做法就是增加新的代码块A,找出所有jcc指令,修改该指令跳转到A,
再通过A跳转到正确的代码块,代码块A可以根据数学公式实现一些运算,动态计算出跳转地址,模糊控制流。
这种做法也被大牛们叫做控制流程平坦化,代码块A也叫做控制分发器,负责分发指令跳转。
当然这只是最简单最基本的控制流程平坦化,去混淆也很容易,几乎可以静态将代码打回原形。
我没有采用上面的方法,我的基本想法是以函数为单位进行混淆,比如有函数F,抽取出F函数的所有指令,
申请一个新的空间将每条指令随机乱序放置在新的空间,再增加指令保证两条指令的执行顺序和原始函数一致,
可以采用上面说的复杂算法计算出下一条指令的地址也可以使用直观的跳转指令进行链接。
实现每条指令空间顺序上的随机乱序,但是执行顺序不变,空间上相邻的两条指令之间也可以生成一些大小随机的花指令进行干扰。
最后修复跳转关系和重定位表。这样就完成了对一个函数的“粉碎”。
使用工具:自己撸的一个PE操作类,反汇编引擎使用的udis86,汇编引擎使用的asmjit
函数分析的意思是,给定一个代码块,识别出函数的起始地址和大小,类似IDA以sub_xxx标注出函数的功能
如图

正确识别出函数是很困难的事情,因为每个编译器生成的函数特征可能都不一样,比如某些函数以ret指令结尾,
有些函数根本没有ret指令,有些函数也不是以push xxx开头。所以只能尽可能加入较多的函数特征。
连IDA这种级别的反编译器都不可能百分百识别出代码和数据,有些编译器把部分数据和代码混合编译在一起,
比如delphi。或者编程者故意插入了导致某些反编译结果出错的花指令,这种情况是无法分析函数的。
参考了玩命的关于代码数据识别的文章,自己再总结了一些规则,得出能识别大部分函数的算法,
暂时没有加入识别某些delphi函数的规则,这类函数代码和数据混杂在了一起。
基本算法如下
1.jmp immediate(立即数)
- 反编译过程中记录遇到的所有jcc指令跳转目的地址,每次都和新遇到的jcc指令目的地址比较,记录下跳转目的地址最大的一个
### 2.ret结尾识别 - 遇到ret指令则比较前面保留的最大跳转地址和当前地址,如果当前地址大于跳转地址则函数结束,如果小于跳转目的址则从跳转地址开始继续分析
### 3.其他情况结尾判断 - 如果遇到向上跳转的无条件jmp指令则函数结束
- 如果找到nop (0x90)则函数结束
- 如果找到至少连续两个以上int3 (0xCC)则函数结束
- 如果找到add [eax], al (0x00,0x00....)则函数结束
- 函数第一条指令是无条件jmp则函数结束,并把jmp指令目标地址加入待分析函数地址集合
- 如果下一条指令是另一个函数的开始,(比如遇到指令push esp,mov ebp, esp) 则函数结束,并把下一条指令地址加入待分析函数地址集合
### 4.Call immediate(立即数) - 遇到call立即数指令则把目的地址加入待分析函数起始地址集合
### 5.其他 - 如果程序有调试信息也可以根据调试信息来区分指令数据和函数,这里的规则肯定代表全部,可以根据每个编译器的不同加入自定义规则
- 基本思路是从pe文件入口点开始使用上面的算法启发式分析,遇到函数调用就把调用目地地址加入待分析集合,重复以此
部分代码如下:
/*** * 指令流节点 */ typedef struct _Instr_Flow_Node { bool isJmpDown;//是否向下跳 DWORD64 jmpRange;//跳转范围大小 ud_mnemonic_code type;//指令类型 ud_type operatorType;// 操作数类型 1.跳转立即数 2.寄存器 3.内存地址 bool isJcc = false;//是否是jcc类型的指令 bool isCall = false;//是否是Call类型的指令 DWORD64 loadImageAddress;//当前指令虚拟内存 DWORD64 memoryFileAddress;//当前指令文件内存 DWORD64 jmpLoadImageAddress;//跳转目的地虚拟内存 DWORD64 jmpMemoryFileAddress;//跳转目的地文件内存 DWORD insnLen;//指令长度 //jcc立即数跳转类型的跳转偏移量 struct { union { int8_t sbyte; int16_t sword; int32_t sdword; }; } jmpOffset; bool operator < (const _Instr_Flow_Node & node) const { return this->memoryFileAddress < node.memoryFileAddress; // < 升序 } bool isInvalid() { return this->type == UD_Iinvalid; } } InstrFlowNode;
FunctionNode X86Analysis::AnalysisFunction(DWORD64 begin, DWORD bufferSize, map<DWORD64, FunctionNode>* functionMap, map<DWORD64, FunctionNode>* excludeMap, DWORD64 pc) { ud_t ud; ud_init(&ud); ud_set_mode(&ud, 32); ud_set_syntax(&ud, UD_SYN_INTEL); ud_set_input_buffer(&ud, (uint8_t*)begin, bufferSize); ud_set_pc(&ud, pc); InstrFlowNode jcc_max, jcc_flow; memset(&jcc_max, 0, sizeof(jcc_max)); while (ud_disassemble(&ud)) { jcc_flow = GetInstrNode(&ud); if (jcc_flow.isInvalid()) { //遇到无效指令(可能花指令),则停止分析该函数,返回前面分析完成的部分,可能函数长度为0 FunctionNode function; function.memoryFileAddress = begin; function.loadImageAddress = pc; function.size = begin - (jcc_flow.memoryFileAddress - jcc_flow.insnLen); return function; } if (jcc_flow.isJcc && (jcc_flow.operatorType == UD_OP_JIMM)) { if (jcc_flow.jmpMemoryFileAddress > jcc_max.jmpMemoryFileAddress) { //记录CFG流图中跳转目标地址最大的跳转指令 jcc_max = jcc_flow; } } switch (jcc_flow.type) { case UD_Ijmp: { //如果无条件跳转目标地址小于函数起始或者当前跳转指令是函数第一条指令则视为结束 //并把目标地址加入预分析函数节点 if (jcc_flow.operatorType == UD_OP_JIMM) { if ((jcc_flow.jmpMemoryFileAddress < begin) || (jcc_flow.memoryFileAddress == begin)) { if (functionMap != nullptr) { //如果排除map中不存在已经分析过的函数则插入节点 if ((excludeMap != nullptr) && (!excludeMap->empty())) { if (excludeMap->find(jcc_flow.jmpMemoryFileAddress) == excludeMap->end()) { FunctionNode node(jcc_flow.jmpMemoryFileAddress, jcc_flow.jmpLoadImageAddress); functionMap->operator[](node.memoryFileAddress) = node; } } else { FunctionNode node(jcc_flow.jmpMemoryFileAddress, jcc_flow.jmpLoadImageAddress); functionMap->operator[](node.memoryFileAddress) = node; } } return FunctionNode ( begin, pc, jcc_flow.memoryFileAddress + jcc_flow.insnLen - begin ); } } break; } case UD_Icall: { if (functionMap != nullptr) { if (jcc_flow.operatorType == UD_OP_JIMM) { if ((excludeMap != nullptr) && (!excludeMap->empty())) { //如果排除map中不存在已经分析过的函数则插入节点 if (excludeMap->find(jcc_flow.jmpMemoryFileAddress) == excludeMap->end()) { //4字节立即数call FunctionNode node(jcc_flow.jmpMemoryFileAddress, jcc_flow.jmpLoadImageAddress); functionMap->operator[](node.memoryFileAddress) = node; } } else { //4字节立即数call FunctionNode node(jcc_flow.jmpMemoryFileAddress, jcc_flow.jmpLoadImageAddress); functionMap->operator[](node.memoryFileAddress) = node; } } } break; } case UD_Iret: { if (jcc_max.jmpMemoryFileAddress > jcc_flow.memoryFileAddress) { //ret之后还有CFG流 DWORD skip_bytes = jcc_max.jmpLoadImageAddress - ud.pc; ud_input_skip(&ud, skip_bytes); ud_set_pc(&ud, jcc_max.jmpLoadImageAddress); } else { return FunctionNode ( begin, pc, jcc_flow.memoryFileAddress + jcc_flow.insnLen - begin ); } break; } case UD_Inop: case UD_Iint3: { if (ud_insn_mnemonic(&ud) == UD_Iint3) { //必须至少出现连续两个CC指令才说明识别到函数末尾 if (*((ud_insn_ptr(&ud) + 1)) != 0xCC) { break; } } return FunctionNode ( begin, pc, jcc_flow.memoryFileAddress - begin ); } case UD_Iadd: { if (!memcmp(ud_insn_hex(&ud), "0000", 4)) { return FunctionNode ( begin, pc, jcc_flow.memoryFileAddress - begin ); } break; } default: { } } //如果接下来的代码是函数的开始特征 DWORD64 ptr = jcc_flow.memoryFileAddress + jcc_flow.insnLen; if (LookNextBegin(ptr)) { //如果排除map中不存在已经分析过的函数则插入节点 if ((excludeMap != nullptr) && (!excludeMap->empty())) { if (excludeMap->find(ptr) == excludeMap->end()) { FunctionNode node(ptr, jcc_flow.loadImageAddress + jcc_flow.insnLen); functionMap->operator[](ptr) = node; } } else { FunctionNode node(ptr, jcc_flow.loadImageAddress + jcc_flow.insnLen); functionMap->operator[](ptr) = node; } return FunctionNode ( begin, pc, jcc_flow.memoryFileAddress + jcc_flow.insnLen - begin ); } } return FunctionNode ( begin, pc, bufferSize ); }
分析procmon.exe的winmain函数和IDA对比的效果如图


根据IDA的识别计算一下函数大小0x0045E6B4-0x0045D840=3700,和自己程序的识别结果一致

有了上面得到的信息就能进行粉碎了,用前面讲的方法将函数进行混淆得到新的代码块,
再找到reloc段的前面一个段,向下合并reloc段,创建一个新的text段,把混淆代码放进去,
最后在新text段后面创建reloc段,修复重定位信息。
混淆之前必须先扫描记录当前函数的所有重定位信息,混淆过程中将原始重定位信息和新的重定位信息联系在一起,以便后面进行重定位修复。
部分代码实现:
char* x86PEObfuscate::BrokenFunction(FunctionNode function,DWORD *obfucodeSize, vector<RelocFixer> &relocFixBox,DWORD64 VirtulAddress) { //解析指令流 vector<InstrFlowNode> instrbox = this->m_Analysis.InstrExtract(function.memoryFileAddress, function.size, function.loadImageAddress); if (instrbox.empty()) { return nullptr; } //获取PE重定位表 map<DWORD, vector<WORD>> relocTable; vector<RelocInstr>relocInstrBox; bool hasReloc = this->m_pefile.getRelocTable(relocTable); if (hasReloc) { //得到指令集合中的重定位信息 checkReloc(instrbox, relocTable, relocInstrBox); } class ObfuscateInstr { public: ObfuscateInstr() {}; ObfuscateInstr(const ObfuscateInstr&o) { this->memoryAddress = o.memoryAddress; this->virtulAddress = o.virtulAddress; this->prexCodeSize = o.prexCodeSize; this->size = o.size; this->code = new char[this->size]; memcpy(this->code, o.code, this->size); } ~ObfuscateInstr() { if (code != nullptr) { delete[] code; } } //该混淆指令块被随机分配到内存中的地址,以便后面指令修复寻找地址 //随机方式将chunkbox集合中的指令块分配到内存 //修复的时候顺序遍历chunkbox集合,根据相邻元素的memoryAddress链接相邻的指令块 //遍历chunkbox的时候根据下标找到instrbox中的原始指令元素,判断当前是否是jcc指令 //是则根据以原始指令内存地址为key,在orign_chunk_map中找到目标指令块地址,计算修复当前指令 DWORD64 memoryAddress = 0;// 该混淆块被写入新空间的地址 DWORD64 virtulAddress = 0;// 该混淆块的 VA DWORD prexCodeSize = 0; //混淆块中原始功能指令前面的指令长度=原始功能指令在该指令块的偏移 char *code = nullptr;//混淆块 DWORD size = 0; }; //对每条指令预进行预处理混淆 vector<ObfuscateInstr> chunkbox; x86::Gp registers[] = { x86::eax,x86::ebx,x86::ecx,x86::edx,x86::esi,x86::edi }; bool first = true; //true 代表处理指令流的第一条指令 pop reg int index; for (auto instr : instrbox) { CodeHolder code; code.init(CodeInfo(ArchInfo::kIdX86)); x86::Assembler assember(&code); //原始功能指令前面 if (!first) { assember.pop(registers[index]); assember.popfd();//保护标志位 } else { first = false; } DWORD prexCodeSize = code.sectionById(0)->buffer().size(); //前缀指令的长度 //处理原始功能指令 int insn_len; if ((instr.isJcc||instr.isCall)&&(instr.operatorType == UD_OP_JIMM)) { char *new_jcc = new char[6]; DWORD jcc_padding = 0xAAAAAAAA;//jcc跳转偏移填充 WORD jcc_opcode = this->jcc_long_opcode[instr.type]; if ((instr.type == UD_Icall) || (instr.type == UD_Ijmp)) { //如果原始指令是call或者jmp 这两种指令opcode和jx类指令的长度不一致 单独处理 0xE8 0xE9 memcpy(new_jcc, (char*)&jcc_opcode, 1); memcpy(new_jcc + 1, &jcc_padding, 4);//0xAAAAAAAA占位,必须修复 insn_len = 5; } else { memcpy(new_jcc, (char*)&jcc_opcode, 2); //0F 80 .... memcpy(new_jcc + 2, &jcc_padding, 4);//0xAAAAAAAA占位,必须修复 insn_len = 6; } assember.embed(new_jcc, insn_len); delete[] new_jcc; } else { insn_len = instr.insnLen; assember.embed((char*)instr.memoryFileAddress, instr.insnLen);// 目标指令 非jcc指令 直接写入内存 } //原始功能指令后面 assember.pushfd();//保护标志位 index = this->GetRandomKey() % sizeof(registers) / sizeof(x86::Gp); //随机选择寄存器 assember.mov(x86::dword_ptr(x86::esp, -4), registers[index]); assember.add(x86::esp, -4); Label label = assember.newLabel(); assember.call(label); assember.bind(label); assember.pop(registers[index]); int num = -(13 + prexCodeSize + insn_len);//12+1 assember.add(registers[index], num); //得到本混淆指令块开始地址 assember.add(registers[index], 0xdeadbeaf); //0xdeadbeaf占位,必须修复 assember.push(registers[index]); assember.ret(); CodeBuffer& buffer = code.sectionById(0)->buffer(); ObfuscateInstr instrchunk; instrchunk.code = new char[buffer.size()]; ::memcpy(instrchunk.code, buffer.data(), buffer.size()); instrchunk.size = buffer.size(); instrchunk.prexCodeSize = prexCodeSize; chunkbox.push_back(instrchunk); } //将指令块随机乱序分配到新空间 DWORD buffer_index = 0; DWORD buffer_size = function.size * 100; char * buffer = new char[buffer_size]; //申请100倍原始函数空间的大小 map<DWORD64, DWORD64> orign_chunk_map; //修复跳转指令 key是原始指令内存地址,value是被混淆过后的指令被随机分配后的地址 vector <int> indexTable; //chunkbox的索引表 for (int i = 0; i < chunkbox.size(); i++) { indexTable.push_back(i);//保存chunkbox的索引表 } while (!indexTable.empty()) { //随机选择指令块到新内存 int key = this->GetRandomKey() % indexTable.size(); int index = indexTable[key]; memcpy(buffer + buffer_index, chunkbox[index].code, chunkbox[index].size); DWORD64 addr = (DWORD64)buffer + buffer_index; DWORD64 va = VirtulAddress + (addr - (DWORD64)buffer); chunkbox[index].memoryAddress = addr; //随机放置的地址 chunkbox[index].virtulAddress = va; //该指令块的va orign_chunk_map.insert(pair<DWORD64, DWORD64>(instrbox[index].memoryFileAddress, addr)); buffer_index += chunkbox[index].size; //随机产生5-20字节垃圾数据 int junk_size = this->GetRandomKey() % 16 + 6; this->GetRandomBytes(buffer + buffer_index, junk_size); buffer_index += junk_size; //从tmpchunk中删除当前指令元素 auto iter = indexTable.begin(); iter += key; indexTable.erase(iter); } //修复指令间执行顺序和jcc跳转目的地址 注意最后一条指令的处理 DWORD offset_flag = 0xdeadbeaf; DWORD jcc_flag = 0xAAAAAAAA; for (int i = 0; i < chunkbox.size(); i++) { char *begin = (char*)chunkbox[i].memoryAddress; char *end = (char*)chunkbox[i].memoryAddress + chunkbox[i].size; DWORD offset; if (i < chunkbox.size() - 1) { offset = chunkbox[i + 1].memoryAddress - chunkbox[i].memoryAddress; } else { //如果是函数最后一条指令,则随机跳到前面任意一条原始指令混淆之后的块(不会执行) int k = this->GetRandomKey() % (chunkbox.size() - 1); offset = chunkbox[k].memoryAddress - chunkbox[i].memoryAddress; } //修复相邻指令执行顺序 char* ptr = this->SearchBytes(begin, end, (char*)&offset_flag, sizeof(DWORD)); memcpy(ptr, &offset, 4); if ((instrbox[i].isJcc|| instrbox[i].isCall) && (instrbox[i].operatorType == UD_OP_JIMM)) { //修复jcc指令跳转偏移 char* ptr = this->SearchBytes(begin, end, (char*)&jcc_flag, sizeof(DWORD)); DWORD64 addr = 0; if ((instrbox[i].type == UD_Icall)||(orign_chunk_map.count(instrbox[i].jmpMemoryFileAddress)<=0)) { //混淆是以函数为单位 //如果当前指令是call或者“伪call”(某种jmp),或者map中没有跳转目的指令的记录 //总的来说,也就是说明当前指令的目的地址不在本函数空间中 //这里不完善(其实也不用处理畸形程序) //jmpLoadImageAddress是加载地址,可能会因为地址随机化而改变 //但是相对va地址不会变 //chunkbox[i].memoryAddress=begin - (DWORD64)buffer是该指令块相对于起始块的偏移 //加上VirtulAddress就是加载地址va addr = instrbox[i].jmpLoadImageAddress; DWORD64 va = VirtulAddress + ((DWORD64)begin + chunkbox[i].prexCodeSize - (DWORD64)buffer); offset = addr - va - 5;//e9:jmp imm e8:call imm 指令长度是5 } else { addr = orign_chunk_map[instrbox[i].jmpMemoryFileAddress] + chunkbox[i].prexCodeSize; if (instrbox[i].type == UD_Ijmp) //e9:jmp imm e8:call imm 指令长度是5 { offset = addr - ((DWORD64)begin + chunkbox[i].prexCodeSize) - 5;//目标-当前-当前指令长度 } else { offset = addr - ((DWORD64)begin + chunkbox[i].prexCodeSize) - 6;//目标-当前-当前指令长度 } } memcpy(ptr, &offset, 4); } } //保存新的重定位项 for (auto relocInstr : relocInstrBox) { DWORD index = relocInstr.index; DWORD64 relocVa = chunkbox[index].virtulAddress + chunkbox[index].prexCodeSize + relocInstr.off; DWORD rva = relocVa - this->m_pefile.getOptionHeader()->ImageBase; DWORD orignRva = instrbox[index].loadImageAddress + relocInstr.off - this->m_pefile.getOptionHeader()->ImageBase; WORD typeOffset = rva % 0x1000; //新的typeOffset DWORD newPage = rva - typeOffset; typeOffset |= ((WORD)(relocInstr.type << 12)); RelocFixer fixer; fixer.orignRva = orignRva; fixer.newPage = newPage; fixer.typeOffset = typeOffset; relocFixBox.push_back(fixer); } //修改原函数入口代码 //原始函数剩余空间填充代码 char *begin = (char*)function.memoryFileAddress; char opcode[] = { 0xe9,00,00,00,00,0xc3 }; //jmp imm DWORD64 firstCodeVa = VirtulAddress + (chunkbox[0].memoryAddress - (DWORD64)buffer);//代码块的首指令va DWORD jmpoffset = firstCodeVa - function.loadImageAddress - 5; memcpy(opcode + 1, &jmpoffset, 4); memcpy(begin, opcode, 6); begin += 6; this->GetRandomBytes(begin, function.size - 6); char *obfucode = new char[buffer_index]; memcpy(obfucode, buffer, buffer_index); *obfucodeSize = buffer_index; delete[] buffer; return obfucode; }
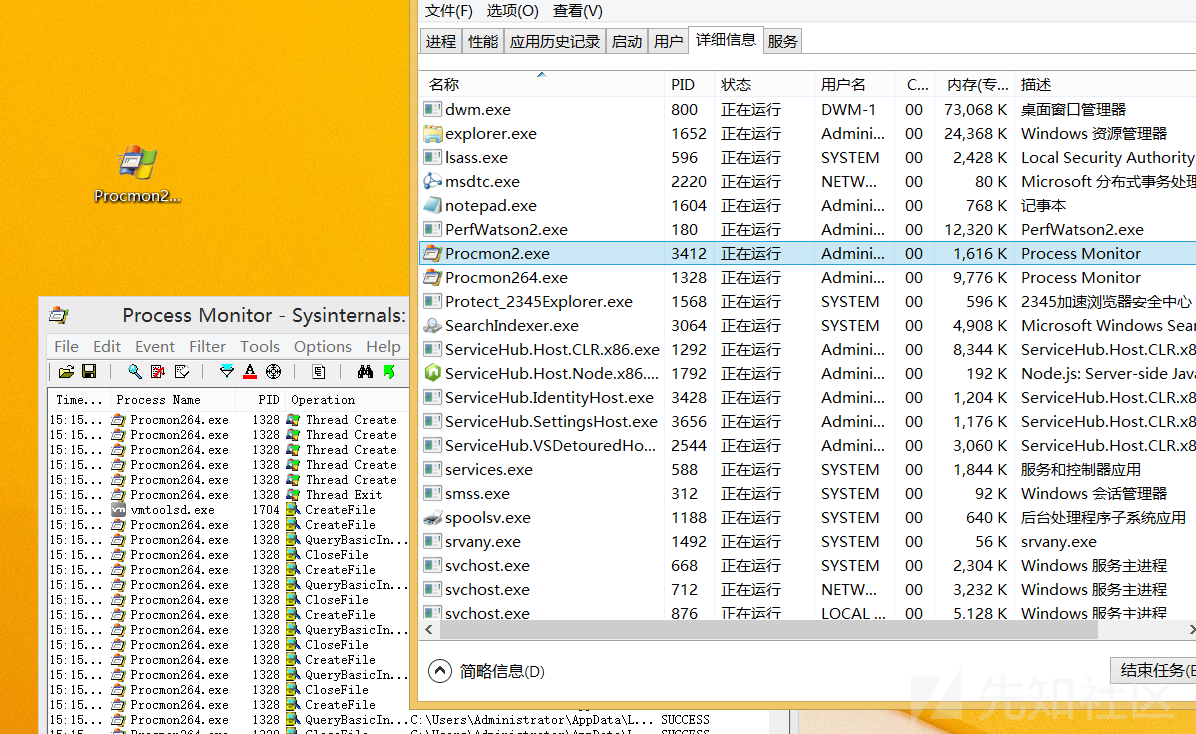
对procmon.exe的winmain函数进行粉碎生成procmon2.exe

procmon2.exe正常运行

混淆前:


混淆后:




原理很简单,只实现了乱序粉碎的功能,而且是很简单的函数粉碎,只作为学习的一个玩具demo参考
代码变形,常量隐藏,导入表加密等等功能都没有加入。没什么技术含量,代码很垃圾,大佬轻喷
发个demo bin玩玩,把Obfuscater.exe和procmon.exe放在同一目录,运行即可生procmon.obf.exe
Obfuscater.exe处理的exe和函数我都写死了,想用的大佬可以自行逆向patch一下

如有侵权请联系:admin#unsafe.sh