简介Telegraf是一个基于插件的开源指标采集工具。本身是为InfluxDB(一款时序数据库)量身打造的数据收集器,但是它过于优秀,能够将抓取的数据写到很多地方,尤其在时序数据库领域,很多时序数据库 2023-11-29 11:11:30 Author: 运维帮(查看原文) 阅读量:25 收藏
简介
Telegraf是一个基于插件的开源指标采集工具。本身是为InfluxDB(一款时序数据库)量身打造的数据收集器,但是它过于优秀,能够将抓取的数据写到很多地方,尤其在时序数据库领域,很多时序数据库都能够与它配合使用。通常,它每隔一段时间抓取一批指标数据(比如机器的CPU使用情况,磁盘的IO,网络情况,MySQL服务端的的会话数等等)并将他们发送到时序数据库、消息队列中或者自定义导出到某个地方。供下游的应用处理(比如报警)。Telegraf也能够对外提供一个服务,等待客户端推送数据。
它与logstash类似,只不过logstash是收集日志的。telegraf是收集指标的。
官方提供了大量可选的插件,另外Telegraf是易于拓展的,如果官方的插件无法满足你的需求,你可以在Telegraf的基础上写出自己的插件。
Telegraf 包括4中类型的插件: Input, Output, Processor, Aggregator。
1、Input
Telegraf 输入插件从系统、服务和第三方 API 收集度量数据。
2、Output
处理器插件在发送之前对度量数据进行转换、装饰和过滤,允许您在数据到达时对其进行清理。
3、Aggregator
聚合器插件创建聚合度量数据,例如从您收集和处理的度量数据中计算出的平均值、最小值和最大值。
4、Output
输出插件可以写入多种数据存储、服务和消息队列,如 InfluxDB、Graphite、OpenTSDB、Datadog、Kafka、MQTT、NSQ 等。
插件目录
Telegraf官网有一个插件目录,可以进行快速的查看检索
这个地址也有一下宝藏:https://github.com/influxdata/telegraf/tree/master/docs
安装参考
https://docs.influxdata.com/telegraf/v1/install/
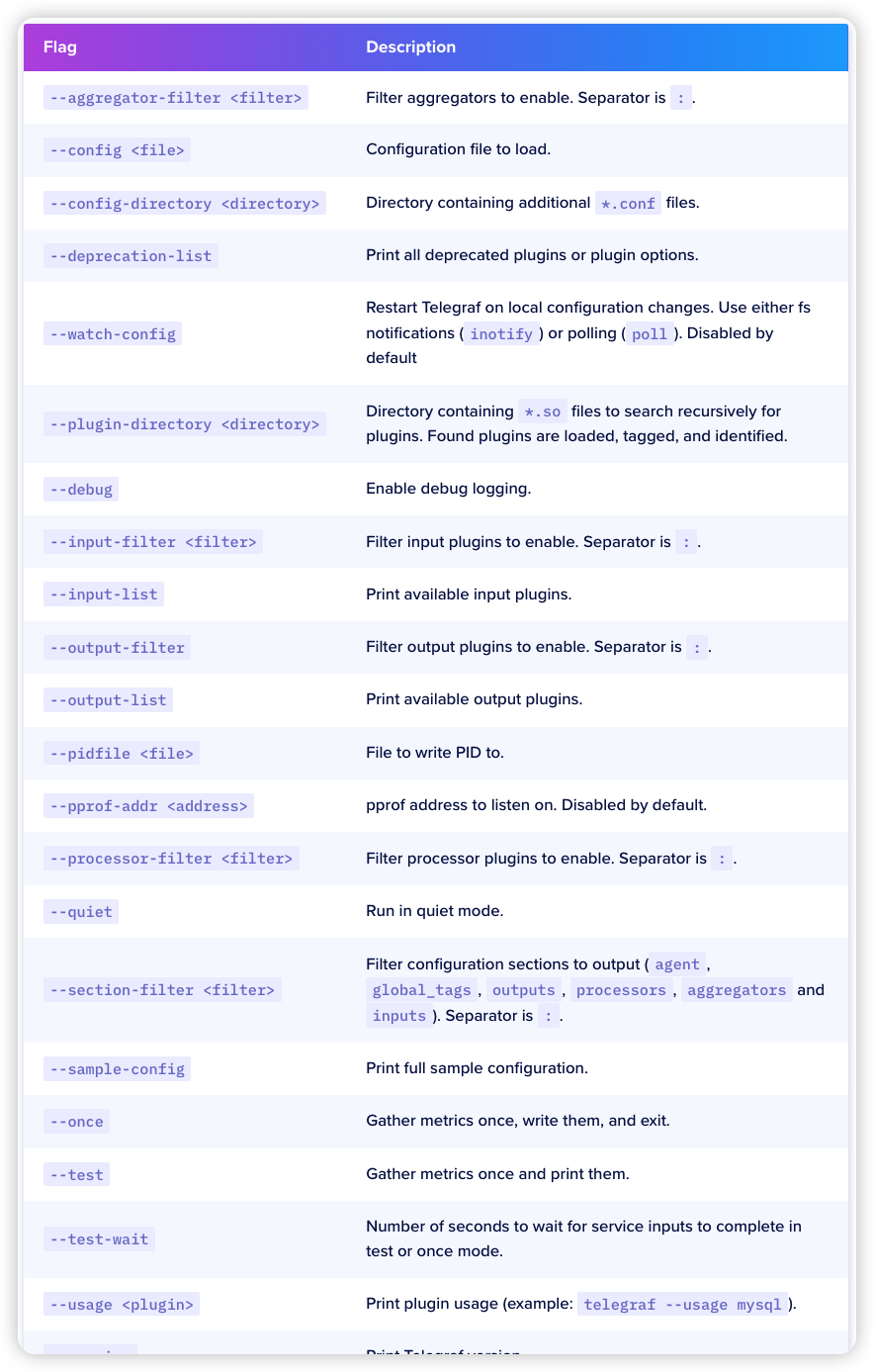
启动参数
例子:
创建一个默认input和output插件的配置文件
telegraf config > telegraf.conf启动程序
telegraf --config telegraf.conf测试模式
telegraf --config ./example03.conf --test目录结构
分享我的目录结构,大家参考
/etc/default/telegraf,默认环境变量文件
/opt/telegraf,安装目录
/opt/telegraf/telegraf.conf,默认配置文件
/opt/telegraf/scripts,自定义扩展插件目录
配置选项
你可以认为Telegraf玩的就是插件,Telegraf内置的操作系统的input插件已经很全了,但是有些应用插件可能还差点意思,这种情况建议在被监控的主机上自己写扩展脚本。
环境变量例子:
USER="alice"INFLUX_URL="https://us-west-2-1.aws.cloud2.influxdata.com"INFLUX_SKIP_DATABASE_CREATION="true"INFLUX_PASSWORD="monkey123"
配置文件例子:
[global_tags]user = "${USER}"[[inputs.mem]][[outputs.influxdb]]urls = ["${INFLUX_URL}"]skip_database_creation = ${INFLUX_SKIP_DATABASE_CREATION}password = "${INFLUX_PASSWORD}"
配套环境变量
[global_tags]user = "alice"[[outputs.influxdb]]urls = "https://us-west-2-1.aws.cloud2.influxdata.com"skip_database_creation = truepassword = "monkey123"
Global tags
在配置文件的 [global_tags] 部分可以以 key="value" 格式指定全球标签。Telegraf 将这些全球标签应用于此主机上收集的所有指标。
代理配置
[agent] 部分包含以下配置选项:
interval: 所有输入的默认数据收集间隔
round_interval: 将收集间隔四舍五入到 interval。例如,如果 interval 设置为 10s,则代理在 :00、:10、:20 等时间收集。
metric_batch_size: 将指标以最多
metric_batch_size 指标的批次发送到输出。
metric_buffer_limit: 为每个输出缓存
metric_buffer_limit 指标,并在成功写入时刷新此缓冲区。这应该是 metric_batch_size 的倍数,且不得小于 2 倍 metric_batch_size。
collection_jitter: 用于以随机量抖动收集。每个插件在收集前随机时间内睡眠,该时间在 jitter 内。这可用于避免许多插件同时查询诸如 sysfs 之类的内容,这对系统有可测量的影响。
flush_interval: 所有输出的默认数据刷新间隔。不要将其设置低于 interval。最大 flush_interval 是 flush_interval + flush_jitter
flush_jitter: 以随机量抖动刷新间隔。这主要是为了避免运行大量 Telegraf 实例的用户出现大的写入峰值。例如,flush_jitter 为 5s,flush_interval 为 10s,意味着每 10-15s 刷新一次。
precision: 收集的指标四舍五入到指定的精度,作为间隔(整数 + 单位,例如:1ns、1us、1ms 和 1s)。服务输入(如 logparser 和 statsd)不使用精度。
debug: 在调试模式下运行 Telegraf。
quiet: 在安静模式下运行 Telegraf(仅错误消息)。
logtarget: 控制日志的目的地,可以设置为 "file"、"stderr" 或在 Windows 上为 "eventlog"。当设置为 "file" 时,输出文件由 logfile 设置决定。
logfile: 如果 logtarget 设置为“file”,指定日志文件名称。如果设置为空字符串,则将日志写入 stderr。
logfile_rotation_interval: 在指定的时间间隔后旋转日志文件。设置为 0 时,不执行基于时间的旋转。
logfile_rotation_max_size: 当日志文件变大到指定大小时旋转日志文件。设置为 0 时,不执行基于大小的旋转。
logfile_rotation_max_archives: 保留的旋转存档的最大数量,任何较旧的日志都会被删除。如果设置为 -1,则不删除任何存档。
log_with_timezone: 设置用于日志记录的时区 - 例如,“America/Chicago”。要使用当地时间,请设置为“local”。请参阅时区选项和格式。
hostname: 覆盖默认主机名,如果为空则使用 os.Hostname()。
omit_hostname: 如果为 true,则不在 Telegraf 代理中设置 host 标签。
输出配置
以下是所有输出的配置参数:
alias: 为插件实例命名。
flush_interval: 刷新之间的最大时间间隔。使用此设置可以针对每个插件单独覆盖代理的 flush_interval。
flush_jitter: 抖动刷新间隔的时间量。使用此设置可以针对每个插件单独覆盖代理的 flush_jitter。
metric_batch_size: 一次发送的最大指标数量。使用此设置可以针对每个插件单独覆盖代理的 metric_batch_size。
metric_buffer_limit: 缓存未发送指标的最大数量。使用此设置可以针对每个插件单独覆盖代理的 metric_buffer_limit。
name_override: 覆盖测量的基本名称。(默认为输出的名称)。
name_prefix: 指定要附加到测量名称的前缀。
name_suffix: 指定要附加到测量名称的后缀。
聚合器配置
以下配置参数适用于所有聚合器:
alias: 为插件实例命名。
period: 刷新和清除每个聚合器的周期。所有在此周期之外的时间戳发送的指标都会被聚合器忽略。
delay: 每个聚合器刷新前的延迟。这用于控制聚合器在接收输入插件的指标前等待的时间,以防聚合器和输入在相同的间隔上刷新和收集。
grace: 即使指标超出聚合周期,插件也会聚合指标的持续时间。当代理预期接收到迟到的指标并可以将其纳入下一个聚合周期时,需要此设置。
drop_original: 如果为真,则聚合器会丢弃原始指标,不将其发送到输出插件。
name_override: 覆盖测量的基本名称。(默认为输入的名称)。
name_prefix: 指定要附加到测量名称的前缀。
name_suffix: 指定要附加到测量名称的后缀。
tags: 应用于特定输入测量的标签映射。
指标过滤
过滤器可以针对输入、输出、处理器或聚合器进行配置。
namepass: 一组 glob 模式字符串的数组。仅传输其测量名称与此列表中的模式匹配的点。namedrop: namepass 的反向操作。丢弃其测量名称与列表中的模式匹配的点。此测试适用于通过了 namepass 测试的点。fieldpass: 一组 glob 模式字符串的数组。仅传输其字段键与列表中的模式匹配的字段。fielddrop: fieldpass 的反向操作。丢弃字段键与模式之一匹配的字段。tagpass: 将标签键映射到 glob 模式字符串数组的表。仅传输包含表中标签键的点,并且标签值与相关模式之一匹配。tagdrop: tagpass 的反向操作。丢弃包含表中标签键的点,并且标签值与相关模式之一匹配。此测试适用于通过了 tagpass 测试的点。taginclude: 一组 glob 模式字符串的数组。仅传输与模式之一匹配的标签键的标签。与 tagpass 相比,tagpass 如果一个标签通过测试,则传输整个点,而 taginclude 则从点中删除所有不匹配的标签。此过滤器可用于输入和输出,但在输入时使用更为高效(在摄取过程中过滤标签更有效)。tagexclude: taginclude 的反向操作。从点中丢弃与模式之一匹配的标签键的标签。
注意:由于 TOML 解析方式,tagpass 和 tagdrop 参数必须定义在插件定义的末尾,否则随后的插件配置选项将被解释为 tagpass 和 tagdrop 表的一部分。
过滤例子:
input配置例子
[global_tags]dc = "denver-1"[agent]interval = "10s"# OUTPUTS[[outputs.influxdb]]url = "http://192.168.59.103:8086" # required.database = "telegraf" # required.precision = "1s"# INPUTS[[inputs.cpu]]percpu = truetotalcpu = false# filter all fields beginning with 'time_'fielddrop = ["time_*"]
input配置:tagpass和tagdrop
[[inputs.cpu]]percpu = truetotalcpu = falsefielddrop = ["cpu_time"]# Don't collect CPU data for cpu6 & cpu7[inputs.cpu.tagdrop]cpu = [ "cpu6", "cpu7" ][[inputs.disk]][inputs.disk.tagpass]# tagpass conditions are OR, not AND.# If the (filesystem is ext4 or xfs) OR (the path is /opt or /home)# then the metric passesfstype = [ "ext4", "xfs" ]# Globs can also be used on the tag valuespath = [ "/opt", "/home*" ]
input配置:fieldpass和fielddrop
# Drop all metrics for guest & steal CPU usage[[inputs.cpu]]percpu = falsetotalcpu = truefielddrop = ["usage_guest", "usage_steal"]# Only store inode related metrics for disks[[inputs.disk]]fieldpass = ["inodes*"]
input配置:namepass和namedrop
# Drop all metrics about containers for kubelet[[inputs.prometheus]]urls = ["http://kube-node-1:4194/metrics"]namedrop = ["container_*"]# Only store rest client related metrics for kubelet[[inputs.prometheus]]urls = ["http://kube-node-1:4194/metrics"]namepass = ["rest_client_*"]
input配置:taginclude和tagexclude
# Only include the "cpu" tag in the measurements for the cpu plugin.[[inputs.cpu]]percpu = truetotalcpu = truetaginclude = ["cpu"]# Exclude the `fstype` tag from the measurements for the disk plugin.[[inputs.disk]]tagexclude = ["fstype"]
input配置:prefix,suffix和override
[[inputs.cpu]]name_suffix = "_total"percpu = falsetotalcpu = true
[[inputs.cpu]]name_override = "foobar"percpu = falsetotalcpu = true
input配置:tags
下面的例子给指标增加2个tags
[[inputs.cpu]]percpu = falsetotalcpu = true[inputs.cpu.tags]tag1 = "foo"tag2 = "bar"
同类型的多个输入 通过在配置文件中定义这些实例,可以指定同类型的额外输入(或输出)。为避免测量冲突,请使用 name_override、name_prefix 或 name_suffix 配置选项
[[inputs.cpu]]percpu = falsetotalcpu = true[[inputs.cpu]]percpu = truetotalcpu = falsename_override = "percpu_usage"fielddrop = ["cpu_time*"]
Output配置例子:
[[outputs.influxdb]]urls = [ "https://us-west-2-1.aws.cloud2.influxdata.com" ]database = "telegraf"precision = "1s"# Drop all measurements that start with "aerospike"namedrop = ["aerospike*"][[outputs.influxdb]]urls = [ "https://us-west-2-1.aws.cloud2.influxdata.com" ]database = "telegraf-aerospike-data"precision = "1s"# Only accept aerospike data:namepass = ["aerospike*"][[outputs.influxdb]]urls = [ "https://us-west-2-1.aws.cloud2.influxdata.com" ]database = "telegraf-cpu0-data"precision = "1s"# Only store measurements where the tag "cpu" matches the value "cpu0"[outputs.influxdb.tagpass]cpu = ["cpu0"]
聚合配置例子:
这将每 30 秒收集并发出系统 load1 指标的最小值/最大值,并丢弃原始数据。
[[inputs.system]]fieldpass = ["load1"] # collects system load1 metric.[[aggregators.minmax]]period = "30s" # send & clear the aggregate every 30s.drop_original = true # drop the original metrics.[[outputs.file]]files = ["stdout"]
这将每 30 秒收集并发出交换(swap)指标的最小值/最大值,并丢弃原始数据。
[[inputs.swap]][[inputs.system]]fieldpass = ["load1"] # collects system load1 metric.[[aggregators.minmax]]period = "30s" # send & clear the aggregate every 30s.drop_original = true # drop the original metrics.namepass = ["swap"] # only "pass" swap metrics through the aggregator.[[outputs.file]]files = ["stdout"]
自定义扩展插件
用什么语言写都可以,只要按照固定格式输出就可以,格式参考
mysql,tag1=value1,tag2=value2 field1=xx,field2=xx这个格式输出的最终指标是:mysql_field1和mysql_field2,由最开始的指标类型mysql和最后的字段名field拼合,这点注意一下。
参考:https://docs.influxdata.com/telegraf/v1/
如有侵权请联系:admin#unsafe.sh