read file error: read notes: is a directory 2023-11-25 06:0:56 Author: 网络与安全实验室(查看原文) 阅读量:77 收藏
2023.11.20-2023.11.26
每周文章分享
标题: Joint Optimization of Trajectory and User Association via Reinforcement Learning for UAV-Aided Data Collection in Wireless Networks
期刊: IEEE Transactions on Wireless Communications, vol. 22, no. 5, pp. 3128- 3143, May 2023.
作者: Gong Chen, Xiangping Bryce Zhai, Congduan Li.
分享人: 河海大学——胡雅新
研究背景
由地面用户(GUs)构建的无线网络平台受到能量供应和数据存储量有限的约束,需要传输数据到控制中心进行进一步处理。由于在某些复杂环境下,网络平台与固定基站建立数据连接变得不切实际,需要借助无人机对GUs进行数据采集。为了避免任意分布的GUs受到其他同信道或相邻用户的干扰,提高系统的公平性能和GU的吞吐量,需要对多个合作无人机的轨迹进行管理;此外,GUs不会共享调度信息,但GUs之间存在合作竞争和离散关联,每个GU独立选择一架无人机或多个GU选择同一个无人机进行数据传输都会降低网络传输速率。为了共同优化无人机的飞行轨迹和GUs关联,本文将长期优化问题表述为分散的部分可观察马尔可夫决策过程(DEC-POMDP),并推导出一种结合联盟形成博弈(CFG)和多智能体深度强化学习(MADRL)的方法。
关键技术
本文研究了多架无人机在没有中央控制器的情况下协同飞越异构地面用户(GUs)并收集数据的场景。在考虑信噪比(SINR)和用户公平性的前提下,共同优化无人机的飞行轨迹和GUs关联,以实现总吞吐量和能效的最大化。首先将离散关联调度问题表述为一个非合作的理论博弈,并使用CFG算法实现了收敛到纳什均衡(NE)的分散方案。然后提出了基于MARL的优化轨迹和能量消耗的技术EETD-CFG。
该方法的创新和贡献如下:
1)为了提高无人机辅助无线网络的公平性,在考虑能效、飞行速度、干扰管理和避碰的情况下,提出了一种联合优化多无人机轨迹和GUs关联的优化问题,并将该优化问题转化为一个分散的部分观察马尔可夫决策过程(DEC-POMDP)。
2)为了处理离散关联动作空间和GUs之间的竞争,首先将离散关联调度问题表述为一个非合作的理论博弈,并使用CFG算法实现一个收敛于纳什均衡(NE)的分散方案。同时对比了CFG算法和基于GUs信息共享的最优响应(BR)集中方案。
3)提出了一种基于MARL的方法,命名为结合CFG的节能轨迹设计(EETD-CFG),以分布式方式解决因为无人机之间的合作关系和GUs之间的竞争关系构成的复合动作空间这一问题,EETD-CFG可以在每架无人机上以分布式方式执行轨迹规划,而离散的CFG算法用于优化GUs关联。
算法介绍
1.系统模型
(1)网络模型
图1 多无人机辅助异构无线系统
图1是本文的多无人机辅助异构无线系统,在给定区域中随机分布有M个异构GU,其集合为M={GU_1,GU_2,…,GU_m},N架UAV,其集合为N={UAV_1,UAV_2,…,UAV_n},飞行高度为H,作为空中导航系统,对GUs进行数据采集。考虑信噪比阈值,第GU_m具有半径为r_m的盘状通信区域。因此,一旦无人机飞入该区域,就可以收集数据,并且无人机在飞越其公共区域时可以与多个GUs通信。假设系统以时隙方式持续工作时间为T,该时隙δ足够小。GU_m在三维直角坐标系中的位置近似表示为g_m(t),UAV_n的位置近似表示为u_n(t)=[x_n(t), y_n(t), H], t ∈Ґ={1, 2,…,K},K = T/δ,极限飞行速度为v_max,最大速度比例为d_n(t) ∈[0,1],偏航角为θ_n(t)∈[0,2п]。
(2)空对地(A2G)通信模型
假设每架无人机都被分配了一个带宽均匀B_n的正交专用信道,因此不同无人机之间的干扰可忽略。但当无人机在飞越公共区域时可以同时为多个异源GU提供服务,使得每个 GU受到其他 GUs的干扰。采用a_n,m来表示UAVs和GUs之间的关联,其约束条件如下:
a_n,m(t)=1时,也就是UAV_n为GU_m服务。基于上述,得出UAV_n的吞吐量:
其中R_n,m为UAV_n,GU_m之间的数据传输速率。
(3)UAVs能耗模型
UAVs的能耗包括推进能耗和通信能耗,后者比前者小得多,可忽略。在收集任务中UAVs的状态有悬停和飞行,通过设置 v = 0 ,即可得到悬停的能耗,因此,UAVs的能耗与飞行速度有关,当UAV_n以速度v_n(t)持续工作T时间后能耗为:
(4)优化问题公式化
因为UAVs可能会习惯性地悬停或访问某些GUs,这导致一些GUs一直处于低容量的困扰。此外,不合理的GUs关联会导致严重的干扰和链路拥塞。为了解决这个问题,本文引入了Jain公平指数。通过考虑GUs与UAVs的关联a_n,m和无人机的轨迹u_n来最大化该系统的长期能源效率。因此,优化问题可以表述为:
其中f为Jain公平指数,作为定量衡量公平绩效的指标,E(t)为UAVs的能效。
2.分散的部分观察马尔可夫决策过程DEC-POMDP
首先将优化问题重新表述为一个分散的部分观察马尔可夫决策过程, 在时隙环境中,每个UAV从环境的全局状态空间接收私人观测值,并根据观测值和联合UAVs的动作空间获得奖励,且全局状态空间更新成新的状态。DEC-POMDP中各组成部分的详细描述如下:
(1)状态:根据所制定的优化问题,环境状态包括三个组成部分,即UAVs和GUs的位置,关联指标a_n,m(t)以及每个UAV在时隙的能耗E_n。
(2)观察:由于UAV之间没有信息交换。且每个GU不会交换关联策略,因此,UAV_n在从GU_m收集数据时,具有GU_m的关联a_n,m和位置信息。
(3)动作:各UAV在时隙t选择飞行偏航角和飞行速度,每架UAV最多可以收集M个GUs的数据,因此UAV_n与GUs的关联也包含在动作空间中。
(4)奖励:根据优化问题的公式,为了保证无人机之间保持安全距离以避免碰撞,需要满足安全距离约束d_min和轨迹边界约束,因此UAV_n的奖励可表示UAVs共同部分的奖励减去UAV_n违反约束时的惩罚。
3. 节能轨迹设计和关联调度
从 DEC-POMDP 观察到,无人机的动作空间是混合的,具有连续的无人机飞行控制和离散的 GUs 关联指标。为了解决这个问题,本文采用MARL的框架,并引入博弈论来处理离散关联问题,如图2所示。在MARL网络联合优化过程中,优化问题可以分为两个子问题,首先,通过博弈论的方法求解GUs关联子问题,通过对GUs的关联策略使系统总吞吐量最大化。其次每架无人机将根据奖励调整其位置。一旦轨迹被优化,它又会对关联产生影响。这两个子问题可以用迭代和分配的方式进行优化。
图2 本文方法的框架
(1) 基于博弈论的离散关联方法
本文目标是设计一种GUs关联算法,要知道博弈论会达到纳什均衡(NE)。首先本文提出了基于最佳响应的关联算法(BR),该算法具有GUs关联信息共享。但BR需要一个集中的控制中心来进行全局控制。考虑到数据安全性和额外的通信成本,本文最终提出了一种基于CFG的去中心化方法。
a) 纳什均衡
设关联策略为s = (s_1,s_2,…,s_m),s_i∈ N ,∀i∈M。当没有 GU 可以通过单方面改变分配来提高系统传输速率,即达到纳什均衡时关联策略为s*。因此GU关联子问题等效于在给定所有其他GUs关联的情况下最大化每个 GU 的传输速率即:
其中s_−m表示除第GU_m之外的GUs关联策略,U_m表示GU的数据传输速率。
b) CFG
在CFG中,游戏玩家是GUs,这些玩家独立选择无人机传输数据,玩家按照N个UAVs可以分为N个不相交联盟集合。为方便比较联盟优越性,可将其转化为比较联盟传输速率,每个GU遵循联盟切换规则或插入规则选择加入(或脱离)某一联盟。
(2) MARL框架
当UAVs已知位置时,按照分散的方式处理GU关联问题。如图2所示,一旦确定了GUs关联a_n,m,它就会反过来对轨迹产生影响。因此,UAVs轨迹优化子问题是如何最大化其能效,即:
为解决该问题,本文研究了多智能体近端策略优化(MAPPO),如图3所示,MAPPO采用集中训练和分散执行方式,也就是在集中式训练过程中,UAVs会增强有关其他UAVs的信息,例如其他UAVs的本地观测值和策略。完成训练过程后,可以将训练好的模型部署到每个UAV上,从而根据其局部观察结果做出决策。基于MAPPO和CFG算法,本文提出了一种名为EETD-CFG的MARL控制技术。
图3 基于MAPPO和CFG算法的MARL架构
MAPPO由无线网络和N架UAVs组成,该算法有两个独立的神经网络:带有参数μ_n的策略网络和带有参数φ_n的评论网络,设п={п_1,…,п_n}是策略集合;μ={μ_1,…,μ_n}的所有UAVs策略参数集合;s为全局状态o_n的集合;a为联合行为a_n的集合。
在 MAPPO 的训练过程中,本文将UAVs与环境的交互表示为固定长度的轨迹τ,其中包含所有智能体的观察、动作和奖励的历史记录,并在Replay Buffer 中收集一组轨迹,记为В。然后,MAPPO 中的UAV_n 通过随机梯度上升来最大化代理函数以实现策略更新。
本文使用集中式评论网络来计算优势函数的估计值,该函数可以更新策略网络和参数φ_n。φ_n的更新是通过回归均方误差函数来最小化损失。
实验分析
1.实验设置
本文设置了8 个异源GUs随机分布在 400 × 400m^2 的给定区域中。所有GU都具有相同的圆形通信区域,半径r_m = 100m。UAVs以H = 100m的固定高度飞行,最大飞行速度为v_max = 20m / s,并在城市环境中收集数据,如图4(a)。在EETD-CFG方法中,使用的神经网络有两个隐藏层,并利用RELU和tanh作为激活函数。每个隐藏层中的神经元数量设置为 400。
2.实验结果
(1)博弈论方法的收敛行为
图4 基于博弈论提出的方法的收敛性
图4(b)为所有实验曲线均为100个独立试验的平均值。结果表明最优算法能够达到最佳性能,BR和CFG都可以快速实现接近最优的解决方案,并收敛到稳定状态。而Greedy算法实现的最大传输最低。初始时BR 的性能优于 CFG,这是因为CFG 使用随机状态进行初始化,可以降低计算复杂程度。此外,CFG相比BR是一种去中心化的方法,它不需要全局信息来调整GU之间的关联,每个GU以分布式方式执行CFG,提高网络效率。
(2)训练绩效
图5 不同学习速率下的EETD-CFG奖励
如图5所示,与不同学习率相关的总奖励随着学习集数的增加而增加,从而产生更好的策略和行动价值。当学习率α=1×10^−3时,平均集奖励在训练过程中波动剧烈。相反,在较小的学习速率下EETD-CFG在很小的范围内波动。尽管它们具有相同的性能,但较小的学习率意味着更多的梯度更新步骤。因此,考虑到需要更少的训练时间,本文选择α=5×10^−5作为EETD-CFG的超参数。
图6 培训阶段的公平指数和能源效率
图6显示了学习率在α = 5×10^−5时EETD-CFG的平均公平指数和能源效率的训练曲线。大约在2000集之后,无人机开始学习合理的移动策略,为GU提供公平的数据收集服务,提高能源效率。在训练过程结束时,图6 (a)中的公平指数最终收敛到接近0.9,然后在一个小范围内波动。类似地,在图6 (b)中能源效率不断提高,并最终收敛。
(3)EETD-CFG与基线的比较
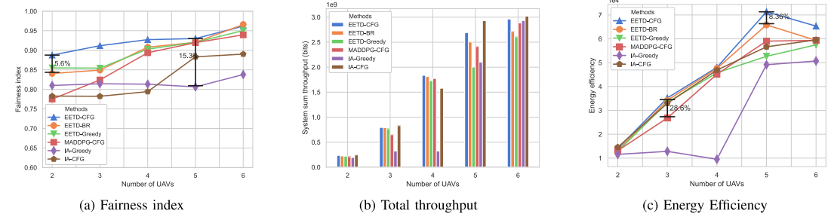
图7 不同无人机数目的(a)公平性指数、(b)能效和(c)总吞吐量比较
图7说明了不同算法在无人机数量变化的实验设置下的公平性指数、能效和系统吞吐量方面的比较,GUs数量固定在8个。从图7 (a)和图7 (b)可以看出,无论使用哪种方法,公平指数和总吞吐量都会单调增加,且EETD-CFG在不同条件下的表现始终优于其他所有五个基线。从图7 (b)可以看出EETD-CFG实现了比EETD-BR方案更高的吞吐量,尤其是在无人机更多的情况下。这种性能评估了去中心化关联算法的有效性和必要性。7 (c)显示了不同方法的能效随着无人机数量的增加而增加,在达到峰值后下降。这是因为更多的无人机将从GU收集更多的数据,从而提高能源效率。但如果继续增加无人机数量会导致一些无人机可能无法在某些时间段内从GU收集数据,而总能耗快速增长,进而降低能效。
图8 不同方法下的平均学习集数的奖励
图8是在简单场景下用2架UAVs和 8 个GUs进行了实验。可以观察到,经过4000次训练,EETD-CFG达到稳定,并实现了更平滑的训练曲线。在训练过程中,EETD-BR表现比EETD-Greedy差,这是因为EETD-BR利用集中关联方法,该方法需要更多迭代才能实现稳定的解决方案,结果表明了去中心化关联策略在快速实现互利方面的有效性和必要性。然而,MADDPG-CFG在大约2000集的时间内实现了与EETD-CFG相同的性能,但随着训练集的增加,结果变得受损。
总结
本文研究了无人机辅助异构无线网络的轨迹优化和用户关联,通过考虑干扰管理、GU 关联和避免碰撞来提高系统的公平性并提高长期能源效率。首先将优化问题表述为DEC-POMDP,然后利用博弈论应对MARL中的离散动作空间,针对不同情况提出中心化BR和去中心化CFG算法;其次,对于连续轨迹和能量优化,利用MAPPO基于集中训练和分散执行框架来控制无人机。仿真实验表明本文提出的算法在分布式方式下开展具有更好的性能。
END
==河海大学网络与安全实验室==
微信搜索:Hohai_Network
联系QQ:1084561742
责任编辑:何宇
如有侵权请联系:admin#unsafe.sh