2023-11-21 15:47:54 Author: blogs.sap.com(查看原文) 阅读量:7 收藏
Earlier this year, the “Scene Text” service was made available in AI Business Services and was part of the Q2 AI in BTP release highlights. Finally got some time to explore how the service works. The blog post below serves as a quick guide to those wishing to set this up on their BTP sub account. The developer guide for this service is not out yet, so there are a few parts that took me some trial and error to figure out. So if you are out exploring today, I hope this saves you that time. The material I found handy is referenced at the very bottom of the post.
Background
SAP AI Business Services provides pre-trained machine learning models tailored for business scenarios. The Document Information Extraction service, or DOX as it is typically referred to, uses machine learning for document processing for a wide range of document types. AI Business Services always had Large Language Models under the hood. Last month we announced the DOX Premium Edition, which includes the latest in Generative AI to jump past the need for annotations and even training.
What’s (not so) New
In Q2 this year, we included the functionality to extract text not just from documents like PDFs, but also images. The set up for this is similar to other DOX models, as in tutorial here. The difference being, that when you create a schema with the document type “Custom”, you can choose between two types of OCR engine – “Document” or “Scene Text”, depending on whether the text you wish to extract is in an image or not.
Business Use Cases
A few use cases & corresponding sample images where I found the Scene Text service could extract the information correctly.
i) Extracting Container Seal IDs on freight containers

ii) Extracting number plates from vehicles (detailed blog from a previous use case where a custom model was set up to work in collaboration with SAP Yard Logistics)

iii) Extracting digital meter readings for Utilities (detailed blog from a previous use case where a custom model was set up to work in collaboration with SAP S/4 HANA Utilities)

How to Set Up
Note: Steps 3 onwards can be done via API calls as well. This blog uses the GUI where possible.
1) In your BTP Sub Account – set up an instance & application
The tutorial here will guide you with setting up an instance & an application. Once done successfully, you should see an application something like below.

DOX Application / Subscription
You should also see an instance, something like below.

DOX Instance
Note: I found this a little confusing when I first started out, although to the initiated it may seem obvious. When you set up the Entitlements for Document Information Extraction, you will find the following service plans. You can set up Scene text only with the blocks_of_100 instance. For this blog post, I set up the application as well as I use the DOX UI application, but you can do without it if you prefer doing this entirely with API calls.
| # | Name | Type | Description |
| 1 | default | Instance | Service plan intended for personal exploration |
| 2 | blocks_of_100 | Instance | Service plan intended for productive usage |
| 3 | default (Application) | Application | Service plan intended for GUI based usage |
2) In your BTP Sub Account – Set up user roles
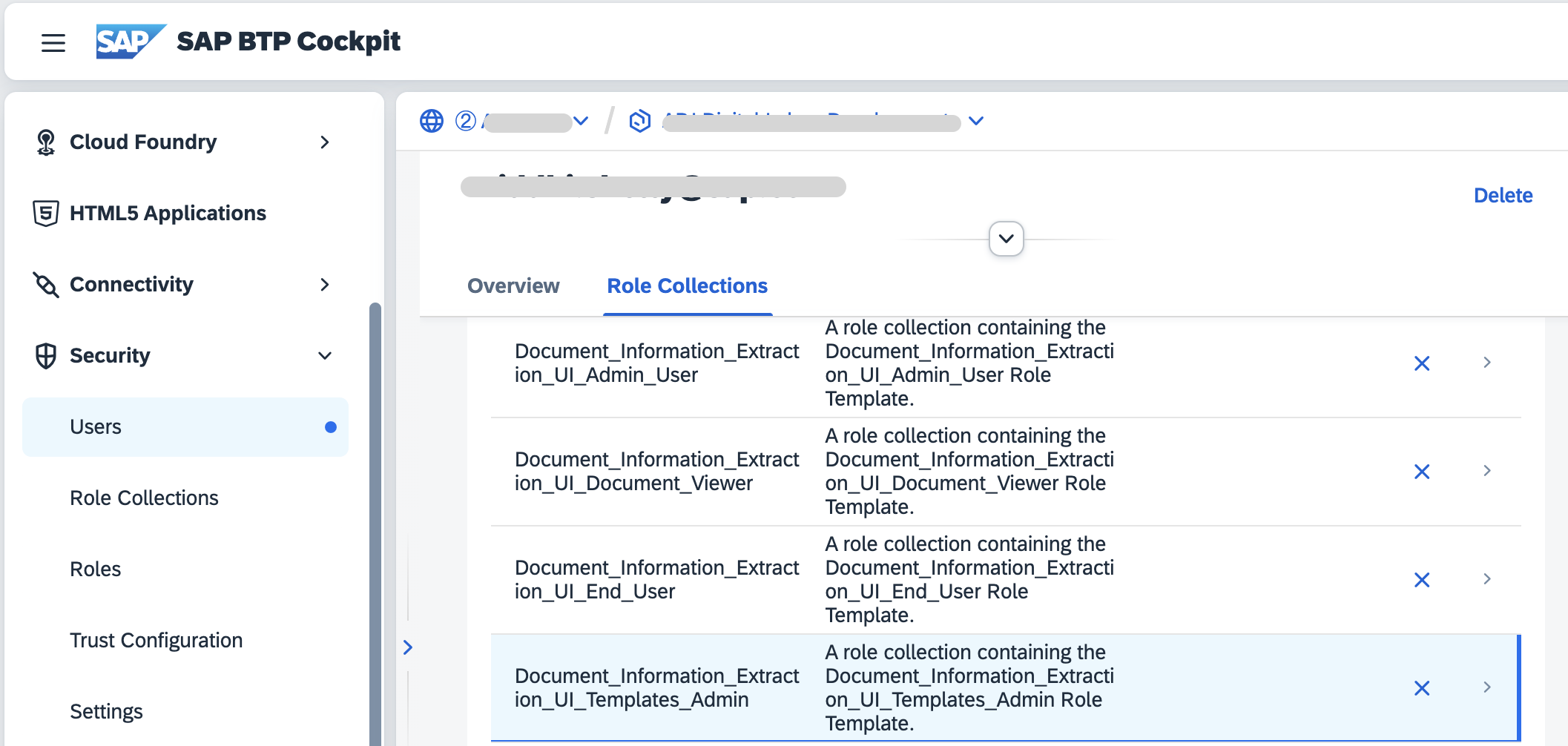
You will need the role “Document_Information_Extraction_UI_Templates_Admin” to be assigned to your user. This is a role required to manage the template and schema lifecycle, which you need in order to use the Scene Text feature. As you can tell, I have some other DOX roles assigned to myself as well.

Role Assignments for DOX
3) In the DOX UI – Set up a Schema
Launch your DOX UI application. If you have the role assignments as described above, you will be able to see the Schema Configuration and Change Instance under Settings (see bottom left of page).

Select Schema Configuration
Click on Change Instance to ensure the correct instance is selected.

Select instance
Click on Schema Configuration to create a new schema for Scene Text. Click on the Create button.

Create Schema
Enter details for the Schema as shown.

Enter Schema Details
Click on the newly created schema and click Activate. The status will change shortly from Passive to Active. This schema is now ready for use.

Activate Schema
4) In the DOX UI – Set up a Template
In the navigation bar, select Template and click on the “+” sign to the far right.

Create Template
Enter details for your template, linking the schema you created in the previous step.

Enter template details
Click activate to start using the template.

Activate template
5) In the DOX UI – Add the image
We can now start adding the images that we intend to extract the image from. I tried out several different kinds images and got decent responses. Click on Documents and on the “+” sign on far right to upload an image.

Add document
Select the document type & schema for Scene Text. Click on the “+” sign to upload an image.

Select image
Review your image & confirm upload.

Confirm image
The document will become ready shortly after and is now ready for external API’s to view extracted content.

Image ready (see use cases section for a closer view of picture)
6) In any API platform – Check the extracted response
I use Postman here. On our tutorials, we typically have steps using Swagger, so try that one out if you prefer Swagger.
Create a new Get request. Set up the URL as below:
<URL from BTP service key> + '/document-information-extraction/v1/document/jobs/' + <job ID per the DOX UI Application> + '/pages/text'You will find the job ID in the URL of your document in the DOX ui application. This is the alphanumeric code that appears to the end of the URL and that I’ve highlighted in blue below.

Set up the Authorisation as below:

Set up Authorisation
There is no body to this call, so you can leave it as none. Hit send and you will see the extracted characters along with the bounding box coordinates. The highlighted text here shows the Container Seal ID extracted correctly.

Call response
References:
Blog: What’s new – AI in BTP Q2
Help Doc: DOX Set up with Schema
Tutorial: Extract fields from documents
如有侵权请联系:admin#unsafe.sh