This blog is part of a blog series from SAP Datasphere product management with the focus on t 2023-11-17 00:10:18 Author: blogs.sap.com(查看原文) 阅读量:19 收藏
This blog is part of a blog series from SAP Datasphere product management with the focus on the Replication Flow capabilities in SAP Datasphere:
- Replication Flow Blog Series Part 1 – Overview | SAP Blogs
- Replication Flow Blog Series Part 2 – Premium Outbound Integration | SAP Blogs
In the first detailed blog, you learned how to setup a replication within Replication Flow and got some more details about the different settings and monitoring.
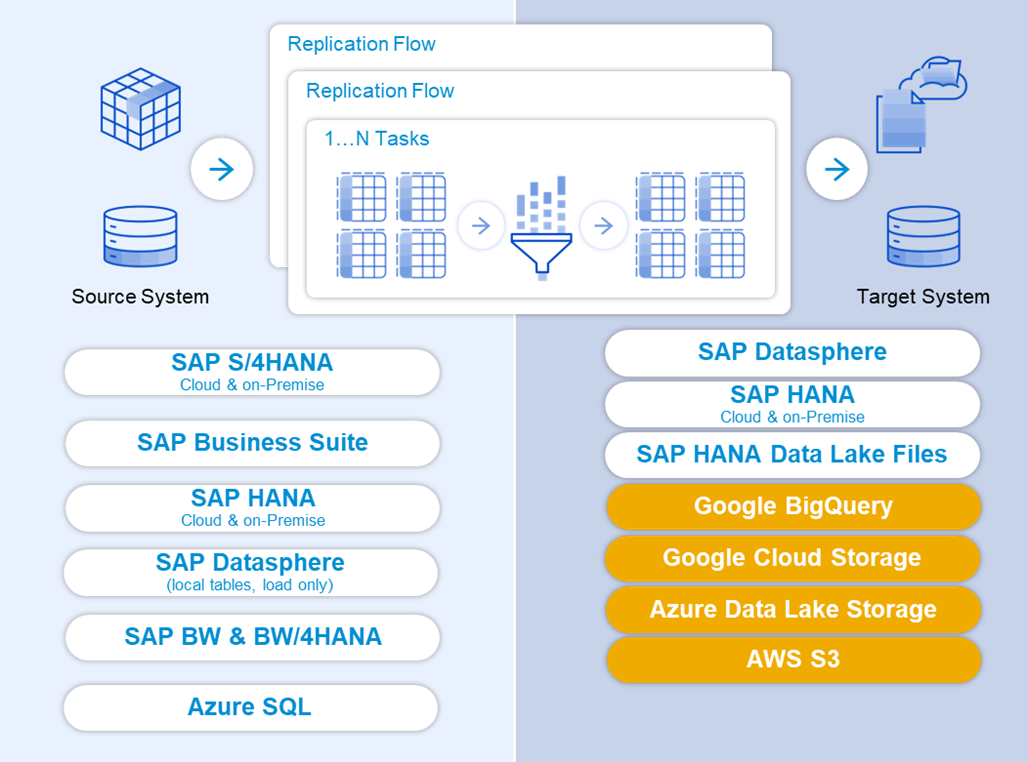
With the mid-November release of SAP Datasphere, some new target connectivity types are made available. With the clear focus to strengthen integrated customer scenarios we named any external connectivity “premium outbound integration” to outline the data integration to external parties. It allows the data movement into objects stores from the main providers as well as BigQuery as part of the SAP-Google Analytics Partnership. The following connectivity options are now available:
- Google BigQuery as part of the endorsed partnership
- Google GCS
- Azure Data Lake Storage Gen 2
- Amazon Simple Storage Service (AWS S3)

Connectivity Overview November 2023
With this new enhancement customer can start spreading their use cases and add integration to object stores into their scenarios. SAP Datasphere as business data fabric enables the communication between the SAP centric business data “world” and data assets stored externally. Premium Outbound Integration is the recommended way to move data out of any SAP system to external targets.
To highlight one of the most wanted replication scenarios, we want to show you a step-by-step explanation of a Replication Flow from SAP S/4HANA to BigQuery.
For this blog we assume the Google BigQuery connection has already been created in the space by following the step by step guide in the SAP Datasphere documentation: BigQuery Docu @ help.sap.com
Specify Replication Flow
In our scenario we defined as a source connection an SAP S/4HANA system, and we want to replicate the following CDS views:
- Z_CDS_EPM_BUPA
- Z_CDS_EPM_PD
- Z_CDS_EPM_SO
As Load Type we selected: Initial and Delta

Source system and selected CDS views
In the next step we define our pre-defined connection to Google BigQuery as target system.

Target system BigQuery
Afterwards we need to select the target dataset by navigating to the container selection.

Select target dataset
In this example we choose the dataset GOOGLE_DEMO that already exists in BigQuery.
Note: In Google Big Query language the container selection in your Replication Flow corresponds to the datasets that are available in your Google BigQuery system. Therefore, will use the terminology dataset in the upcoming paragraphs when we talk about the target container in this sample scenario.

Target dataset
The target dataset GOOGLE_DEMO is set and now we can use the basic filter and mapping functionality you know from Replication Flow.
Let us have a quick look at the default settings by navigating to the projection screen.

Navigate to Projections
After navigating to the Mapping tab, you will see the derived structure which can be adjusted.

Structure Mapping
In addition, you will see also three fields that cannot be changed:
- operation_flag: indicates the executed operation on the source record (insert, update, delete etc.).
- recordstamp: timestamp when the change happened.
- Is_deleted: indicated if a record was deleted in the source,
These three fields will be automatically created in the target structure and will be filled by the systems and can be used depending on the information you require in a certain use case.
Beside the standard adjustments that can be made to structures, there are some special target settings that can be made after navigating to the settings icon back on the main screen.

BigQuery target settings
The Write Mode is in this mode by default on Append. In this release Append API from Google BigQuery is used. Further APIs will be considered depending on the availability.
Depending on the length, Decimals can be clamped by activating the Clamp Decimals setting. This can also be activated for all objects in the Replication Flow.
You find a comprehensive explanation in our product documentation: help.sap.com
Deploy and run data replication
As the next step the Replication Flow can be deployed and afterwards we will start it.

Run Replication Flow
This will start the replication process which can be monitored in the monitoring environment of SAP Datasphere. This was illustrated in our first blog, so we will directly jump to the BigQuery environment and have a look at the moved data.
Big Query Explorer using Google Cloud Console
After navigating to our dataset GOOGLE_DEMO we find our automatically created tables and select Z_CDS_EPM_BUPA to have a look at the structure.

Dataset structure in BigQuery
The data can be displayed via selecting Preview.

Preview replicated data
Within this blog you got all insights into the new premium outbound integration functionality offered by SAP Datasphere as the recommended way to move data out of the SAP environment.
Extending the connectivity to object stores and BigQuery will give you significantly new opportunities.
You can also find some more information about the usage of Google BigQuery in Replication Flows in our product documentation: help.sap.com
Always check our official roadmap for planned connectivity and functionality: SAP Datasphere Roadmap Explorer
Thanks to my co-author Daniel Ingenhaag and the rest of the SAP Datasphere product team.
如有侵权请联系:admin#unsafe.sh