随着大数据时代的到来,带了很多的便利,但是也带来了更多的风险,作为一名安全行业工作者,对于这种变革更是体会深刻,笔者从事的是金融行业的安全工作,在此从数据安全工作落地的角度来聊一聊数据安全治理及具体工作中碰到的问题。
18 年 5 月《银行业金融机构数据治理指引》正式发布,于此同时数据安全治理工作也同步开始,一直持续至今,在进行数据治理工作的同时也参考了很多国内外的标准:
1.GDPR
2.DSMM
3.ISO27701
4.《银行业金融机构数据治理指引》
5.《个人信息安全规范》
DSMM,数据能力成熟度评估模型,以此为方向,围绕数据生命周期,延伸出具体需要管控的点,及落实的工作

依据数据的生命周期,我理了下在数据治理过程中需要注意的点及需要做的工作:
当然不止上面这些,比如终端安全、DLP 等都需要进行严格控制,这些都是基于内部的数据安全控制措施,还有对于外部的威胁监控,比如敏感信息泄漏、业务方面的风险情报等也是我们需要关注的重点,不过在此不做详细介绍,仅列出一些在数据治理方面已经落地的点来做一下描述:
0X01 如何做好数据的分类分级标准
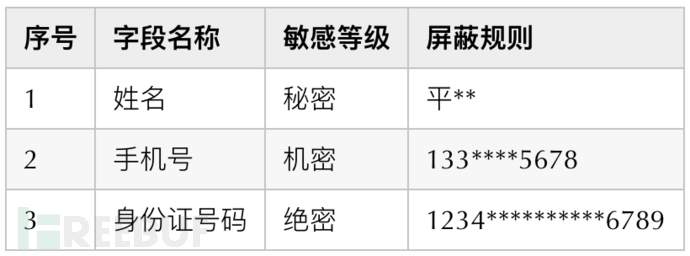
1. 敏感等级的划分
2. 字段标准的确定及敏感等级确定
3. 屏蔽展示规则-脱敏要求
首先我们在做敏感等级的划分时一定不要定太多的等级,比如有这样定的 S1、S2、S3、S4 四级标准,也有这样定的四级标准:绝密、机密、秘密、非保密,当然也有定的绝密、机密、秘密、内部、公开五级标准,也有人提到定了 7 级的,具体如何做,这个纯属看自己选择,在此则要提醒一下:不要定太多等级,落地比较困难,会给自己挖坑的,个人建议四级比较合适,比如:绝密、机密、秘密、非保密。
其次,我们在制定数据标准的时候一定要考虑准确性和通用性,这两者之间其实是有点矛盾的,笔者在此就碰到过问题,我们有一个比较通用标准(手机号、姓名、性别、身份证号码……),也有一个很详细的业务标准(个人中文名称、个人手机号、亲属手机号、代理人手机号……),这两套标准在我们数据打标落地的时候自然而然的就出现冲突,不过可以通过合理定位来解决这种冲突,通用字段标准用来做敏感数据打标,也是敏感数据识别的规则编写依据,而业务标准字段名称则作为业务使用是参考的一个数据标准。也可以将通用字段标准作为一个标签打在业务字段标准上,如下:
最后,为了保证敏感信息不被泄漏则需要遵从最小化原则的基础上,对业务所需名字段进行脱敏,数据的使用一类是具体的业务需求确实需要个人的对应字段信息,对于这类需求我们则需要在满足业务必要性的前提下对字段进行屏蔽或者替换。比如,在应用系统中对敏感字段进行关键部位屏蔽,或者查看敏感信息时进行二次身份认证,这种一般是在数据属主查看自己敏感信息时可以用到,对于企业进行数据分析时用到的大量的客户数据则不能通过这种方法,因为会存在数据聚合场景下的信息泄漏的风险,通过关联性分析可以匹配出对应的客户敏感数据,所以在制定敏感数据屏蔽规则的时候一定要对其应用场景进行分析,比如应用系统的敏感信息可以通过屏蔽实现,那么数据分析分析时则更好的方式是通过不可逆加密来实现,比如之前了解到的阿里的一个产品蚂蚁摩斯,通过一个中间平台,双方吧自己的数据各自加密,然后再通过平台二次加密从而匹配出需要的分析结果,这样就避免了
0X02 敏感数据识别
在我们确定好分级标准及字段标准后我们接下来要做的工作就是敏感数据的识别,对于敏感数据识别,我将其分为两部分:
1. 敏感数据扫描,上面我们已经制定了数据字段标准和敏感数据字段标准,在此基础上我们可以字段名称来制定识别规则,常用的匹配方式就是关键字和正则,关键字用来匹配名称,正则来识别字段的值
2. 敏感数据打标,为了维护好我们们的基础数据标准,还要对我们识别出的敏感数据进行打标,可以将敏感等级标签打在数据库字段上,也可以在元数据管理上给字段打上安全等级标签。
对于敏感数据的识别及打标最好还是有独立的平台来实现,考虑涉及的技术难度不大,建议自建平台,这样的话也可以根据己方实际的业务情况更加合理的编写识别规则,当然也可以采购一些已有的产品来实现,一些产品已经能够通过机器学习来实现智能化的数据打标,这样覆盖的字段也将更加全面,在建设敏感数据识别打标平台的同时也要注意下多元化的信息存储格式,比如关系数据库、面向对象数据库、数据仓库、文本数据源、多媒体数据库、空间数据库、时态数据库、异质数据库等,在此可以借鉴下美团鹏飞大佬的扫描器设计图,也可以通过此传送门学习下互联网公司的经验「传送门」。
0X03 隐私保护
围绕数据生命周期的安全过程,我将其分为两部分,数据安全和隐私保护,数据采集有内外之分,对于外部的数据采集需要数据属主的授权,在内部进行的数据采集则需要在不违背数据授权范围下进行,同时还要考虑数据的用途及业务合理性,但是我们再企业内部也经常会需要依托大量的用户数据进行一些分析统计,在此则不可避免的需要使用到用户的数据信息,那么我们又如何能够做到既不违背隐私保护的原则又满足自身的数据分析行为?对于隐私保护的方法及标准是否适用于我们业务诉求的场景,这个也是我们需要重点关注的点:
数据匿名化的方法主要有去标识化、K-匿名、L-多样性、差分隐私,但是这些方法并不是适用于我们所有的业务交互的场景。在此我们则需要引入《个人信息安全规范》中的解释,匿名化主要是指个人信息在通过技术处理后,无法被识破或还原;去标识化指在我们应用系统中展示敏感信息的时候我们可能会做一些屏蔽处理,可以通过屏蔽关键位置来进行掩码;双方进行数据匹配碰撞的时候则可以通过对唯一标示性字段进行不可逆的算法处理,比如 sha256、sm3 这种摘要算法,进行碰撞然后再将结果与自己数据的映射关系进行比对从而获取想要的结果,K-匿名的应用其实也是有很大的限制,多用于统计分析类的场景,因为不需要具体匹配到某个人,只是做一个统计分析的结果。然而差分隐私则是应用于解决差分攻击的方案,主要适用于统计聚合数据,比如连续的值、离散的数值。当然对于隐私保护也可以参考下 GRC 方法论,从治理、风险管理、合规三个领域来进行系统化综合评估才更加的严谨。
*本文作者:HH@平安银行应用安全团队,转载请注明来自FreeBuf.COM
如有侵权请联系:admin#unsafe.sh